
A mai adatvezérelt világban a kézi adatgyűjtés hagyományos módszere elavult. Egy internetkapcsolattal rendelkező számítógép minden asztalon hatalmas adatforrássá tette az internetet. Így a hatékonyabb és időtakarékosabb korszerű adatgyűjtési módszer a webkaparás. És ami a webkaparást illeti, a Pythonnak van egy Beautiful Soup nevű eszköze. Ebben a bejegyzésben végigvezetem a Beautiful Soup telepítési lépésein, hogy elkezdhesse a webkaparást.
A Beautiful Soup telepítése és használata előtt nézzük meg, miért érdemes ezt választania.
Tartalomjegyzék
Mi az a szép leves?
Tegyük fel, hogy „a COVID hatása az emberek egészségére” témakört kutatja, és talált néhány releváns adatokat tartalmazó weboldalt. De mi van akkor, ha nem kínálnak egyetlen kattintással letölthető lehetőséget az adatok kölcsönzésére? Itt jön játékba a Szép leves.
A Beautiful Soup a Python-könyvtárak indexe közé tartozik, hogy kivonja az adatokat a megcélzott webhelyekről. Kényelmesebb az adatok lekérése HTML vagy XML oldalakról.
Leonard Richardson 2004-ben hozta napvilágra a Beautiful Soup ötletét az internet kaparására. A projekthez való hozzájárulása azonban ma is folytatódik. Büszkén frissíti a Beautiful Soup minden új kiadását Twitter-fiókjában.
Bár a Beautiful Soup for web scraping a Python 3.8 segítségével lett kifejlesztve, tökéletesen működik a Python 3 és a Python 2.4 verziókkal is.
A webhelyek gyakran használnak captcha védelmet, hogy megmentsék adataikat az AI-eszközökből. Ebben az esetben a Beautiful Soup „user-agent” fejlécének néhány módosítása vagy a Captcha-megoldó API-k használata megbízható böngészőt utánozhat, és becsaphatja az észlelőeszközt.
Ha azonban nincs ideje a Beautiful Soup felfedezésére, vagy azt szeretné, hogy a kaparás hatékonyan és egyszerűen történjen, akkor ne hagyja ki a webkaparó API-t, ahol megadhat egy URL-t, és letöltheti az adatokat. a kezeid.
Ha már programozó, a Beautiful Soup használata a kaparáshoz nem lesz ijesztő, mert egyszerű szintaxisa van a weboldalakon való navigálásban és a kívánt adatok feltételes elemzésen alapuló kinyerésében. Ugyanakkor újoncbarát is.
Bár a Beautiful Soup nem speciális kaparásra való, a legjobban akkor működik, ha jelölőnyelven írt fájlokból kaparja ki az adatokat.
A világos és részletes dokumentáció egy másik brownie-pont, amelyet a Beautiful Soup becsomagolt.
Találjunk egy egyszerű módot arra, hogy gyönyörű levest töltsön a gépébe.
Hogyan telepítsünk gyönyörű levest a webkaparáshoz?
Pip – A 2008-ban kifejlesztett, könnyed Python-csomagkezelő ma már a fejlesztők szokásos eszköze a Python-könyvtárak vagy függőségek telepítéséhez.
A Pip alapértelmezés szerint a legújabb Python-verziók telepítésével érkezik. Így, ha bármilyen legújabb Python-verziót telepített a rendszerére, akkor készen áll.
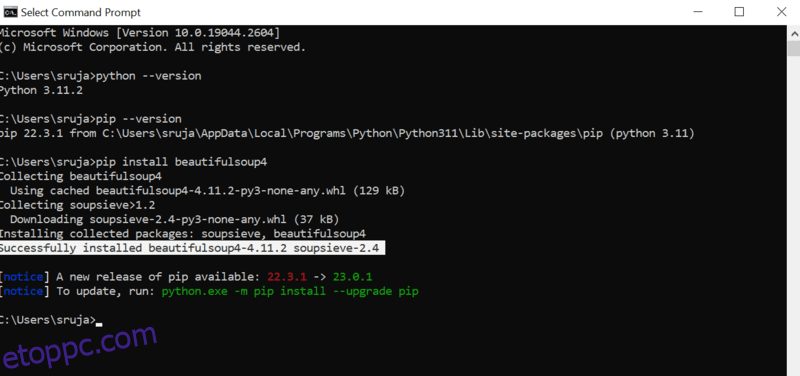
Nyissa meg a parancssort, és írja be a következő pip parancsot a gyönyörű leves azonnali telepítéséhez.
pip install beautifulsoup4
A következő képernyőképhez hasonlót fog látni a kijelzőjén.
A gyakori hibák elkerülése érdekében győződjön meg arról, hogy a PIP telepítőt a legújabb verzióra frissítette.
A pip telepítőt a legújabb verzióra frissítő parancs a következő:
pip install --upgrade pip
Ebben a bejegyzésben sikeresen lefedtük a fél terepet.
Most már telepítve van a gépeden a Beautiful Soup, szóval vessünk egy pillantást a webkaparás használatára.
Hogyan importálhatunk és dolgozhatunk a gyönyörű levessel a webkaparáshoz?
Írja be a következő parancsot a python IDE-be, hogy gyönyörű levest importáljon az aktuális python szkriptbe.
from bs4 import BeautifulSoup
A Beautiful Soup most a Python-fájlban található, és használható a kaparáshoz.
Nézzünk meg egy kódpéldát, hogy megtanuljuk, hogyan lehet kinyerni a kívánt adatokat a gyönyörű levessel.
Megmondhatjuk a Beautiful Soup-nak, hogy keressen meghatározott HTML-címkéket a forráswebhelyen, és kaparja ki a címkékben lévő adatokat.
Ebben a darabban a marketwatch.com-ot fogom használni, amely különböző cégek valós idejű részvényárfolyamait frissíti. Vegyünk néhány adatot erről a webhelyről, hogy megismerkedjen a Szép leves könyvtárral.
Importálja a „requests” csomagot, amely lehetővé teszi számunkra a HTTP-kérések fogadását és megválaszolását, valamint az „urllib”-et, hogy betöltse a weboldalt az URL-jéről.
from urllib.request import urlopen import requests
Mentse el a weboldal hivatkozását egy változóba, hogy később könnyen elérhesse.
url="https://www.marketwatch.com/investing/stock/amzn"
A következő az lenne, hogy az „urllib” könyvtár „urlopen” metódusát használjuk a HTML-oldal változóban való tárolására. Adja át az URL-t az „urlopen” függvénynek, és mentse el az eredményt egy változóba.
page = urlopen(url)
Hozzon létre egy Beautiful Soup objektumot, és elemezze a kívánt weboldalt a „html.parser” segítségével.
soup_obj = BeautifulSoup(page, 'html.parser')
Most a megcélzott weboldal teljes HTML-szkriptje a ‘soup_obj’ változóban van tárolva.
Mielőtt továbblépne, nézzük meg a megcélzott oldal forráskódját, hogy többet tudjunk meg a HTML-szkriptről és a címkékről.
Kattintson a jobb gombbal a weboldal bármely pontjára az egérrel. Ezután talál egy ellenőrzési lehetőséget, amint az alább látható.
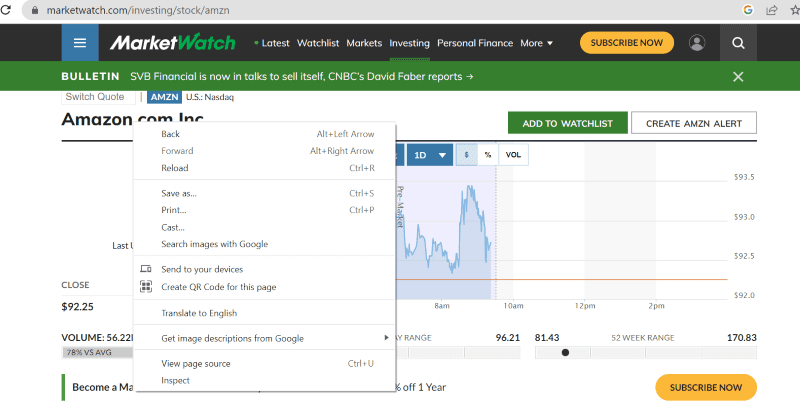
Kattintson az Inspect gombra a forráskód megtekintéséhez.
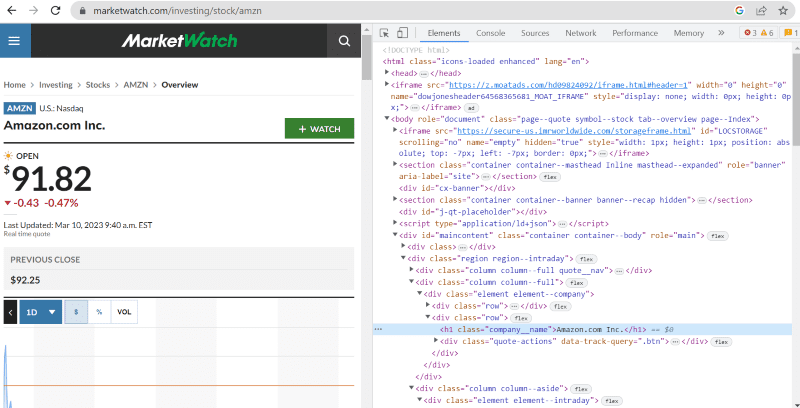
A fenti forráskódban a weboldal felületén látható minden elemről címkéket, osztályokat és konkrétabb információkat találhat.
A „find” metódus a gyönyörű levesben lehetővé teszi, hogy megkeressük a kért HTML-címkéket, és lekérjük az adatokat. Ehhez adjuk meg az osztály nevét és a címkéket a metódusnak, amely konkrét adatokat kinyer.
Például: „Amazon.com Inc.” A weboldalon látható osztály neve: ‘company__name’ a ‘h1’ címkével van ellátva. Ezt az információt beírhatjuk a „find” metódusba, hogy a releváns HTML-részletet egy változóba bontsa ki.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Írjuk ki a „name” változóban tárolt HTML szkriptet és a szükséges szöveget a képernyőn.
print(name) print(name.text)

Tanúja lehet a kinyert adatoknak a képernyőre nyomtatva.
Web Kaparja le az IMDb webhelyet
Sokan közülünk filmbesorolást keresünk az IMBb webhelyén, mielőtt megnéznénk egy filmet. Ez a bemutató bemutatja a legjobban értékelt filmek listáját, és segít megszokni a gyönyörű, webkaparás levesét.
1. lépés: Importálja a gyönyörű levest és a kérések könyvtárait.
from bs4 import BeautifulSoup import requests
2. lépés: Rendeljük hozzá a lemásolni kívánt URL-t egy ‘url’ nevű változóhoz a kódban való egyszerű eléréshez.
A „requests” csomag a HTML-oldal lekérésére szolgál az URL-ből.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
3. lépés: A következő kódrészletben elemezni fogjuk az aktuális URL HTML-oldalát, hogy egy gyönyörű leves tárgyat hozzunk létre.
soup_obj = BeautifulSoup(url.text, 'html.parser')
A „soup_obj” változó most a kívánt weboldal teljes HTML-szkriptjét tartalmazza, mint a következő képen.
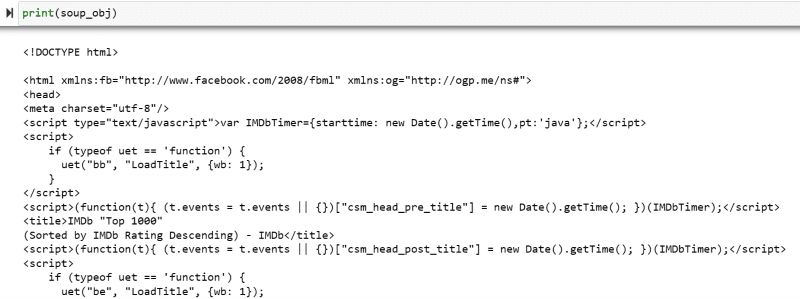
Vizsgáljuk meg a weboldal forráskódját, hogy megtaláljuk a kikaparni kívánt adatok HTML-szkriptjét.
Vigye a kurzort a kibontani kívánt weboldalelem fölé. Ezután kattintson rá a jobb gombbal, és válassza az Inspect opciót az adott elem forráskódjának megtekintéséhez. A következő látványelemek jobban elvezetik Önt.
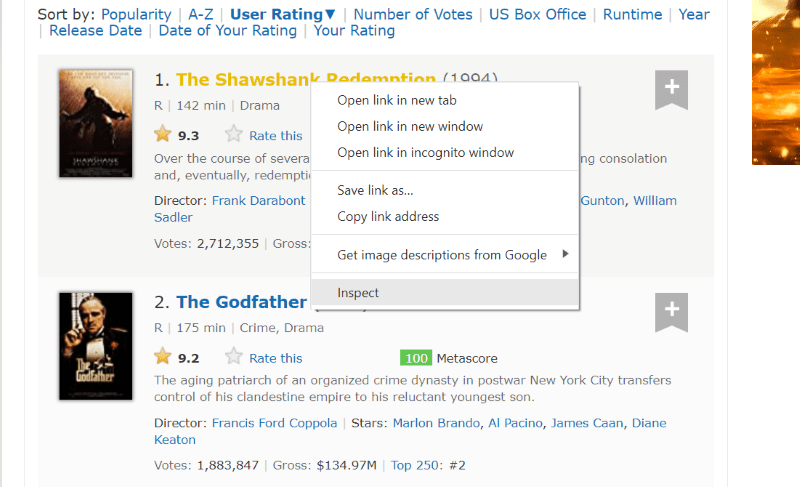
A „lister-list” osztály tartalmazza az összes legjobb értékelésű filmmel kapcsolatos adatot alosztályokként egymást követő div címkékben.
Minden filmkártya HTML-szkriptjében, az osztály „lister-item mode-advanced” alatt van egy „h3” címkénk, amely tárolja a film nevét, rangját és megjelenési évét, amint az az alábbi képen látható.
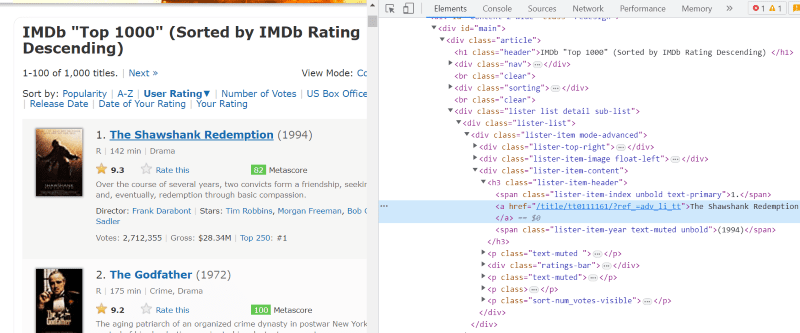
Megjegyzés: A szép leves „find” metódusa megkeresi az első címkét, amely megfelel a neki adott bemeneti névnek. A „find”-től eltérően a „find_all” metódus minden olyan címkét keres, amely megfelel az adott bemenetnek.
4. lépés: A „find” és a „find_all” metódusokkal elmentheti minden film nevének, rangjának és évének HTML-szkriptjét egy listaváltozóba.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
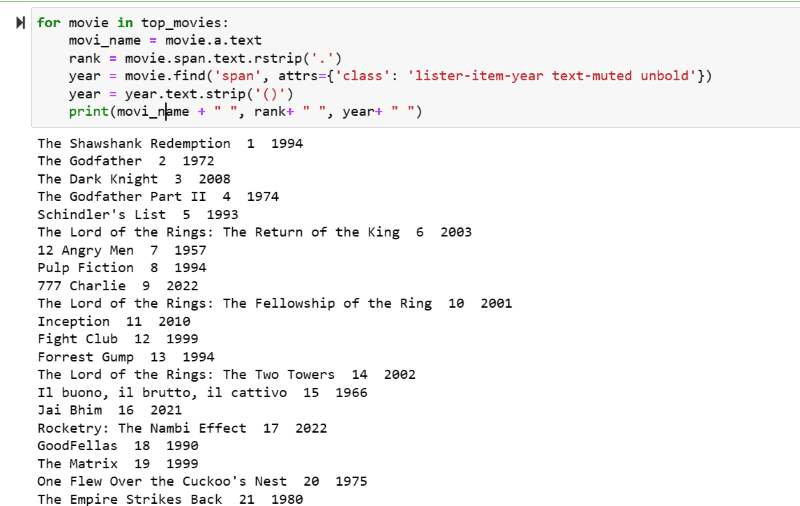
5. lépés: Keresse át a „top_movies” változóban tárolt filmek listáját, és az alábbi kód segítségével bontsa ki az egyes filmek nevét, rangját és évszámát szöveges formátumban a HTML-szkriptből.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
A kimeneti képernyőképen láthatja a filmek listáját nevükkel, rangjukkal és a megjelenés évével.
Könnyedén áthelyezheti a kinyomtatott adatokat egy python kóddal rendelkező Excel-lapba, és felhasználhatja elemzéséhez.
Végső szavak
Ez a bejegyzés elvezeti Önt a gyönyörű leves telepítéséhez a webkaparáshoz. Ezenkívül az általam bemutatott kaparási példák segíthetnek a Beautiful Soup használatának megkezdésében.
Mivel érdekli a Beautiful Soup webkaparáshoz való telepítése, erősen ajánlom, hogy tekintse meg ezt az érthető útmutatót, hogy többet megtudjon a Python használatával történő webkaparásról.