

A Pandas a Python legnépszerűbb adatelemző könyvtára. Adatelemzők, adattudósok és gépi tanulási mérnökök széles körben használják.
A NumPy mellett ez az egyik kötelező könyvtár és eszköz mindenkinek, aki adatokkal és mesterséges intelligenciával dolgozik.
Ebben a cikkben megvizsgáljuk a pandákat és azokat a funkciókat, amelyek annyira népszerűvé teszik őket az adatökoszisztémában.
Tartalomjegyzék
Mi az a Pandas?
A Pandas egy adatelemző könyvtár a Python számára. Ez azt jelenti, hogy a Python-kódon belüli adatok kezelésére és kezelésére használják. A Pandákkal hatékonyan olvashat, kezelhet, vizualizálhat, elemezhet és tárolhat adatokat.
A „pandák” elnevezés a Panel Data szavak összekapcsolásából származik, egy ökonometriai kifejezés, amely több egyed időbeli megfigyeléséből származó adatokra utal. A Pandákat eredetileg 2008 januárjában adta ki Wes Kinney, és azóta a legnépszerűbb könyvtárrá nőtte ki magát.
A Pandas középpontjában két alapvető adatstruktúra áll, amelyeket ismernie kell, a Dataframes és a Series. Amikor létrehoz vagy betölt egy adatkészletet a Pandasban, az a két adatstruktúra valamelyikeként jelenik meg.
A következő részben megvizsgáljuk, mik ezek, miben különböznek egymástól, és mikor ideális valamelyikük használata.
Kulcsfontosságú adatstruktúrák
Amint azt korábban említettük, a Pandas összes adata két adatstruktúra egyikével van ábrázolva, egy adatkerettel vagy egy sorozattal. Ezt a két adatszerkezetet az alábbiakban részletesen ismertetjük.
Dataframe
Ez a példa adatkeret a szakasz alján található kódrészlet felhasználásával készült
A Pandas Dataframe egy kétdimenziós adatstruktúra oszlopokkal és sorokkal. Hasonló a táblázatkezelő alkalmazásban lévő táblázathoz vagy egy relációs adatbázisban lévő táblázathoz.
Oszlopokból áll, és minden oszlop egy attribútumot vagy jellemzőt képvisel az adatkészletben. Ezek az oszlopok ezután egyedi értékekből állnak. Ez az egyedi értékek listája vagy sorozata sorozat objektumként jelenik meg. A sorozat adatstruktúráját a cikk későbbi részében részletesebben tárgyaljuk.
Az adatkeret oszlopainak leíró neveik lehetnek, így megkülönböztethetők egymástól. Ezeket a neveket a rendszer az adatkeret létrehozásakor vagy betöltésekor rendeli hozzá, de bármikor könnyen átnevezhetők.
Az oszlopokban lévő értékeknek azonos adattípusúaknak kell lenniük, bár az oszlopoknak nem kell azonos típusú adatokat tartalmazniuk. Ez azt jelenti, hogy az adatkészletben lévő név oszlop kizárólag karakterláncokat tárol. De ugyanabban az adatkészletben lehetnek más oszlopok is, például az életkor, amelyek az int-eket tárolják.
Az adatkeretek tartalmaznak egy indexet is, amely a sorokra hivatkozik. A különböző oszlopokban lévő, de azonos indexű értékek egy sort alkotnak. Alapértelmezés szerint az indexek számozottak, de átrendelhetők az adatkészletnek megfelelően. A példában (fenti képen, alul kódolva) az index oszlopot a ‘hónapok’ oszlopra állítottuk.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
print(sales_df)
Sorozat
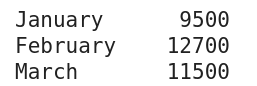 Ez a példasorozat a szakasz alján található kóddal készült
Ez a példasorozat a szakasz alján található kóddal készült
Amint azt korábban tárgyaltuk, egy sorozatot használnak egy adatoszlop ábrázolására a Pandákban. A sorozat tehát egydimenziós adatstruktúra. Ez ellentétben áll a kétdimenziós adatkerettel.
Bár egy sorozatot általában oszlopként használnak egy adatkeretben, önmagában is reprezentálhat egy teljes adatkészletet, feltéve, hogy az adatkészletnek csak egy attribútuma van egyetlen oszlopban rögzítve. Vagy inkább az adatkészlet egyszerűen értékek listája.
Mivel a sorozat egyszerűen egy oszlop, nem kell nevet adnia. A sorozat értékei azonban indexelve vannak. A Dataframe indexéhez hasonlóan a sorozatok adatkerete is módosítható az alapértelmezett számozáshoz képest.
A példában (a fenti képen, alább kódolva) az index különböző hónapokra lett beállítva egy Pandas Series objektum set_axis metódusával.
import pandas as pd total_sales = pd.Series([9500, 12700, 11500]) months = ['January', 'February', 'March'] total_sales = total_sales.set_axis(months) print(total_sales)
A pandák jellemzői
Most, hogy már van egy jó ötlete a Pandákról és az általa használt kulcsfontosságú adatstruktúrákról, elkezdhetjük megvitatni azokat a funkciókat, amelyek a Pandákat olyan hatékony adatelemző könyvtárgá teszik, és ennek eredményeként hihetetlenül népszerűvé teszik az adattudomány és a gépi tanulás területén. Ökoszisztémák.
#1. Adatmanipuláció
A Dataframe és Series objektumok változtathatók. Szükség szerint hozzáadhat vagy eltávolíthat oszlopokat. Ezenkívül a Pandas lehetővé teszi sorok hozzáadását, sőt adatkészletek egyesítését is.
Végezhet numerikus számításokat, például normalizálhatja az adatokat és logikai összehasonlításokat végezhet elemenként. A Pandas ezenkívül lehetővé teszi az adatok csoportosítását és összesített függvények alkalmazását, például átlag, átlag, max és min. Ez megkönnyíti az adatokkal való munkát a Pandasban.
#2. Adattisztítás
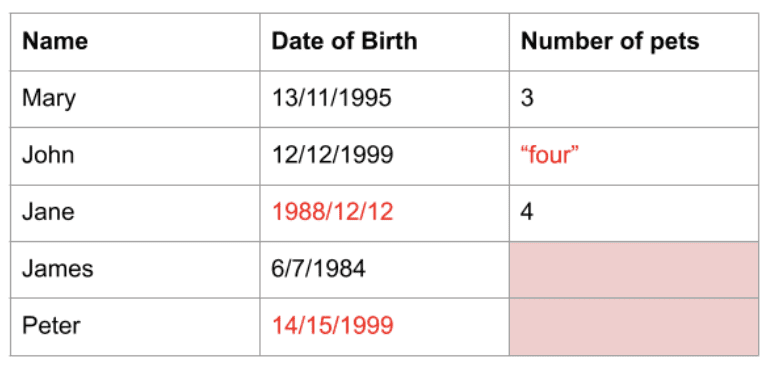
A valós világból nyert adatok gyakran olyan értékeket tartalmaznak, amelyek megnehezítik a munkát, vagy nem ideálisak az elemzéshez vagy a gépi tanulási modellekben való felhasználáshoz. Az adatok rossz adattípusúak, rossz formátumúak, vagy egyszerűen hiányozhatnak. Akárhogy is, ezeket az adatokat előzetesen meg kell tisztítani, mielőtt felhasználnák őket.
A Pandas olyan funkciókkal rendelkezik, amelyek segítenek megtisztítani adatait. Például a Pandas programban törölheti az ismétlődő sorokat, eldobhatja az oszlopokat vagy a hiányzó adatokat tartalmazó sorokat, és lecserélheti az értékeket alapértelmezett értékekkel vagy más értékekkel, például az oszlop átlagával. Több olyan funkció és könyvtár is működik a Pandákkal, amelyek lehetővé teszik az adatok további tisztítását.
#3. Adatvizualizáció
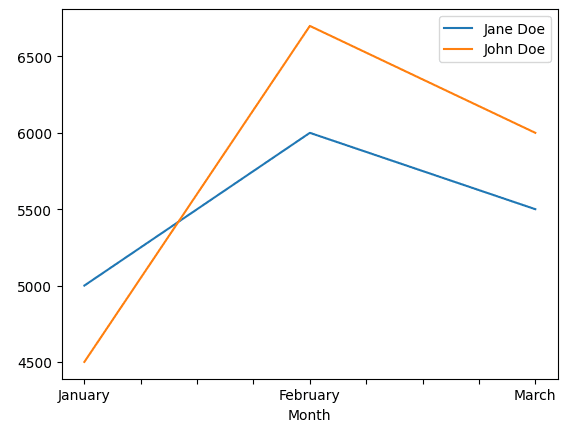 Ez a grafikon a szakasz alatti kóddal készült
Ez a grafikon a szakasz alatti kóddal készült
Bár ez nem egy vizualizációs könyvtár, mint a Matplotlib, a Pandas alapvető adatvizualizációk létrehozására szolgáló funkciókkal rendelkezik. És bár alapvetőek, a legtöbb esetben mégis elvégzik a munkát.
A Pandas segítségével könnyedén megrajzolhat oszlopdiagramokat, hisztogramokat, szórómátrixokat és más különböző típusú diagramokat. Kombinálja ezt a Pythonban elvégezhető adatkezeléssel, és még bonyolultabb vizualizációkat hozhat létre az adatok jobb megértése érdekében.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
sales_df.plot.line()
#4. Idősor elemzés
A Pandas támogatja az időbélyegzett adatokkal való munkát is. Amikor a Pandas felismeri, hogy egy oszlop dátum-idő értékekkel rendelkezik, számos olyan műveletet hajthat végre ugyanazon az oszlopon, amelyek hasznosak az idősoros adatokkal való munka során.
Ezek közé tartozik a megfigyelések csoportosítása időszak szerint, és aggregált függvények alkalmazása rájuk, például összeg vagy átlag, vagy a legkorábbi vagy legfrissebb megfigyelések lekérése a min és max használatával. Természetesen sok más dolgot is megtehet az idősorok adataival a Pandákban.
#5. Bemenet/kimenet Pandákban
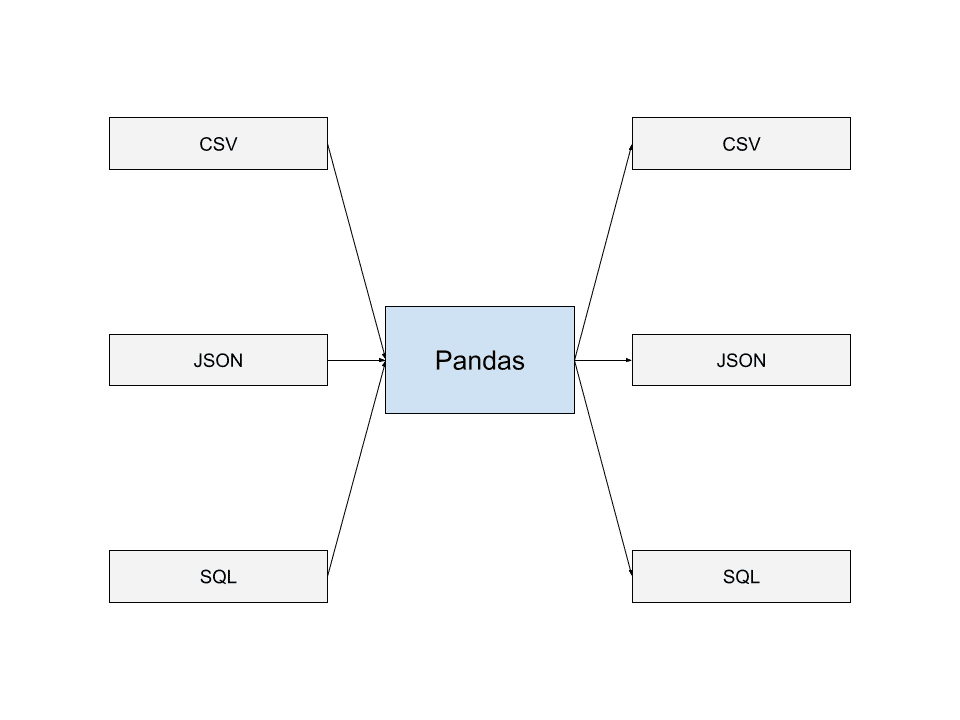
A Pandák a legelterjedtebb adattárolási formátumokból képesek adatokat olvasni. Ezek közé tartozik a JSON, az SQL Dumps és a CSV-k. Ezen formátumok közül sok fájlba is írhat adatokat.
Ez a különféle adatfájlformátumokból történő olvasási és írási képesség lehetővé teszi a Pandáknak, hogy zökkenőmentesen együttműködjenek más alkalmazásokkal, és olyan adatfolyamokat építsenek ki, amelyek jól integrálhatók a Pandákkal. Ez az egyik oka annak, hogy a Pandákat sok fejlesztő széles körben használja.
#6. Integráció más könyvtárakkal
A Pandas eszközök és könyvtárak gazdag ökoszisztémájával is rendelkezik, amelyek kiegészítik a funkcionalitást. Ettől még erősebb és hasznosabb könyvtár.
A Pandas ökoszisztémán belüli eszközök javítják annak funkcionalitását különböző területeken, beleértve az adattisztítást, a vizualizációt, a gépi tanulást, a bemenetet/kimenetet és a párhuzamosítást. A Pandák az ilyen eszközökről nyilvántartást vezetnek a dokumentációjukban.
Teljesítmény és hatékonyság szempontjai a pandákban
Míg a Pandák a legtöbb műveletben ragyognak, hírhedten lassúak lehetnek. A jó oldala az, hogy optimalizálhatja kódját és javíthatja sebességét. Ehhez meg kell értened, hogyan épül fel a Panda.
A Pandas a NumPy-ra épül, amely egy népszerű Python-könyvtár numerikus és tudományos számításokhoz. Ezért a NumPy-hoz hasonlóan a Pandák is hatékonyabban működnek, ha a műveletek vektorizáltak, nem pedig az egyes cellák vagy sorok hurkok segítségével történő kijelölése.
A vektorizálás a párhuzamosítás egyik formája, ahol ugyanazt a műveletet egyszerre több adatpontra alkalmazzák. Ezt SIMD-nek nevezik – egyetlen utasítás, több adat. A vektorizált műveletek kihasználása drámaian javítja a Pandák sebességét és teljesítményét.
Mivel a burkolat alatt NumPy tömböket használnak, a DataFrame és Series adatstruktúrák gyorsabbak, mint az alternatív szótárak és listák.
Az alapértelmezett Pandas implementáció csak egy CPU magon fut. A kód felgyorsításának másik módja olyan könyvtárak használata, amelyek lehetővé teszik a Pandáknak, hogy az összes elérhető CPU magot kihasználják. Ezek közé tartozik a Dask, a Vaex, a Modin és az IPython.
Közösség és források
A legnépszerűbb programozási nyelv népszerű könyvtáraként a Pandas felhasználók és közreműködők nagy közösségével rendelkezik. Ennek eredményeként rengeteg erőforrás áll rendelkezésre a használat megtanulásához. Ezek közé tartozik a hivatalos Panda dokumentáció. De számtalan tanfolyam, oktatóanyag és könyv is található, amelyekből tanulni lehet.
Olyan platformokon is vannak online közösségek, mint a Reddit az r/Pythonban és az r/Data Science alredditek, ahol kérdéseket tehetnek fel és válaszokat kaphatnak. Nyílt forráskódú könyvtárként jelentheti a problémákat a GitHubon, és akár kódot is adhat hozzá.
Végső szavak
A Pandas hihetetlenül hasznos és hatékony adattudományi könyvtárként. Ebben a cikkben megpróbáltam elmagyarázni a népszerűségét azáltal, hogy feltártam azokat a funkciókat, amelyek az adattudósok és programozók számára elérhető eszközzé teszik.
Ezután nézze meg, hogyan hozhat létre Pandas DataFrame-et.