
Ahogy a vállalatok egyre több adatot állítanak elő, az adattárház hagyományos megközelítésének fenntartása egyre nehezebbé és költségesebbé válik. A Data Vault, az adattárház viszonylag új megközelítése, megoldást kínál erre a problémára azáltal, hogy méretezhető, agilis és költséghatékony módszert kínál nagy mennyiségű adat kezelésére.
Ebben a bejegyzésben megvizsgáljuk, hogyan jelentik a Data Vaults az adattárház jövőjét, és miért alkalmazza egyre több vállalat ezt a megközelítést. Tanulási segédanyagokat is biztosítunk azoknak, akik mélyebben szeretnének elmerülni a témában!
Tartalomjegyzék
Mi az a Data Vault?
A Data Vault egy adattárház-modellezési technika, amely különösen alkalmas az agilis adattárházakhoz. Nagyfokú rugalmasságot kínál a bővítésekhez, az adatok teljes egységnyi időbeli historizálását, és lehetővé teszi az adatbetöltési folyamatok erős párhuzamosítását. Dan Linstedt az 1990-es években fejlesztette ki a Data Vault modellezést.
A 2000-es első publikáció után 2002-ben cikksorozattal kapott nagyobb figyelmet. 2007-ben Linstedt elnyerte Bill Inmon támogatását, aki a Data Vault 2.0 architektúrája számára „optimális választásnak” nevezte.
Bárki, aki foglalkozik az agilis adattárház kifejezéssel, gyorsan a Data Vaulthoz jut. A technológia különlegessége, hogy a vállalatok igényeire fókuszál, mert rugalmas, kis ráfordítást igénylő beállítást tesz lehetővé egy adattárházban.
A Data Vault 2.0 figyelembe veszi a teljes fejlesztési folyamatot és az architektúrát, és a komponensek módszeréből (implementáció), architektúrából és modellből áll. Előnye, hogy ez a megközelítés az üzleti intelligencia minden aspektusát figyelembe veszi a mögöttes adattárházzal a fejlesztés során.
A Data Vault modell modern megoldást kínál a hagyományos adatmodellezési megközelítések korlátainak leküzdésére. Skálázhatóságával, rugalmasságával és agilitásával szilárd alapot biztosít egy olyan adatplatform felépítéséhez, amely képes alkalmazkodni a modern adatkörnyezetek összetettségéhez és sokféleségéhez.
A Data Vault hub-and-spoke architektúrája, valamint az entitások és attribútumok szétválasztása lehetővé teszi az adatok integrálását és harmonizálását több rendszer és tartomány között, megkönnyítve a növekményes és agilis fejlesztést.
A Data Vault kulcsfontosságú szerepe az adatplatform felépítésében, hogy egyetlen igazságforrást hozzon létre minden adat számára. Az adatok egységes nézete, valamint a múltbeli adatok változásainak műholdtáblákon keresztüli rögzítésének és nyomon követésének támogatása lehetővé teszi a megfelelőségi, auditálási, szabályozási követelmények teljesítését, valamint átfogó elemzést és jelentéskészítést.
A Data Vault közel valós idejű adatintegrációs képességei a delta betöltésen keresztül megkönnyítik a nagy mennyiségű adat kezelését gyorsan változó környezetekben, például Big Data és IoT alkalmazásokban.
Data Vault kontra hagyományos adattárház-modellek
A Third-Normal-Form (3NF) az egyik legismertebb hagyományos adattárház-modell, amelyet gyakran előnyben részesítenek számos nagy megvalósításban. Ez egyébként Bill Inmon, az adattárház-koncepció egyik „ősatyja” elképzeléseinek felel meg.
Az Inmon architektúra a relációs adatbázis-modellre épül, és kiküszöböli az adatredundanciát azáltal, hogy az adatforrásokat kisebb táblákra bontja, amelyeket adatpiacokon tárolnak, és elsődleges és idegen kulcsok segítségével kapcsolnak össze. A hivatkozási integritási szabályok betartatásával biztosítja, hogy az adatok konzisztensek és pontosak legyenek.
A normál űrlap célja egy átfogó, az egész vállalatra kiterjedő adatmodell felépítése volt az alapvető adattárházhoz; azonban méretezhetőségi és rugalmassági problémái vannak az erősen csatolt adathálózatok, a közel valós idejű módban jelentkező betöltési nehézségek, a fáradságos kérések, valamint a felülről lefelé irányuló tervezés és megvalósítás miatt.
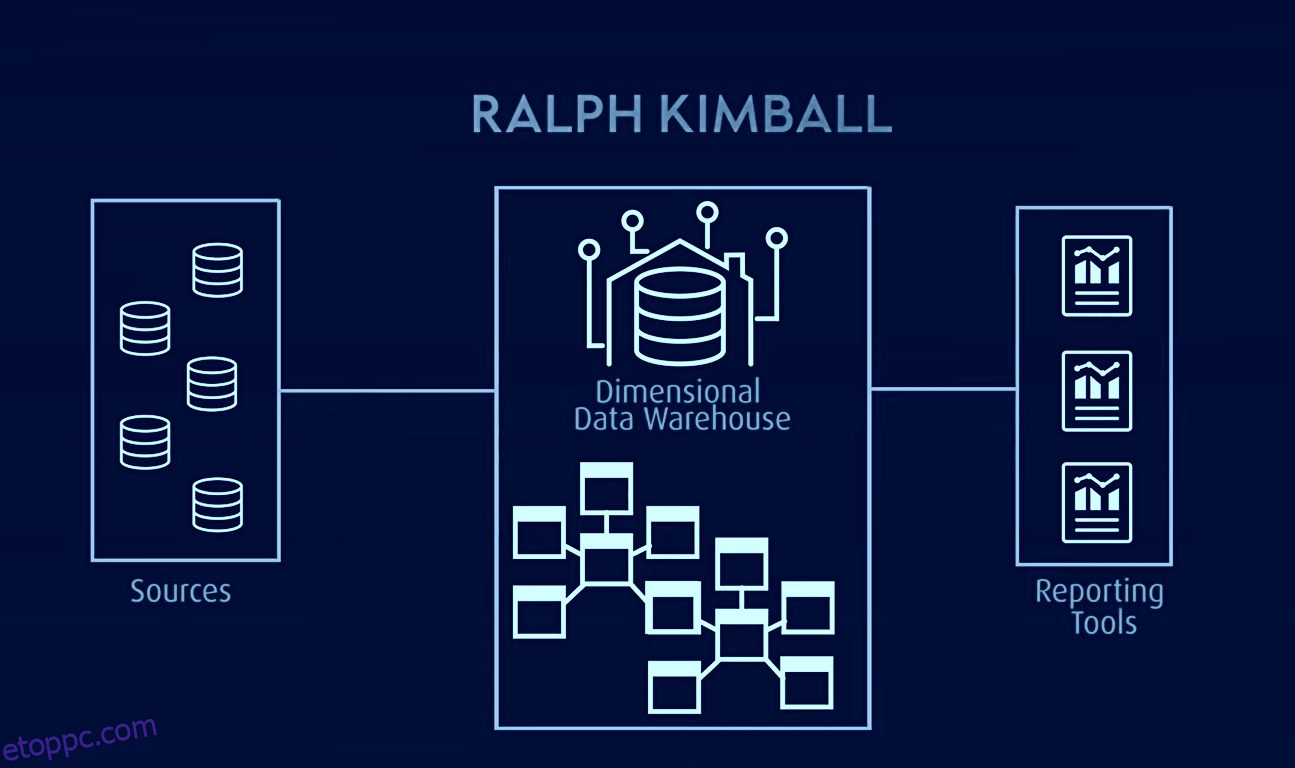
Az OLAP-hoz (online analitikai feldolgozáshoz) és adatpiacokhoz használt Kimbal-modell egy másik híres adattárház-modell, amelyben a ténytáblák összesített adatokat tartalmaznak, a dimenziótáblák pedig csillagsémában vagy hópehelyséma-tervben írják le a tárolt adatokat. Ebben az architektúrában az adatok tény- és dimenziótáblákba vannak rendezve, amelyek denormalizáltak a lekérdezés és elemzés egyszerűsítése érdekében.
A Kimbal egy dimenziós modellen alapul, amely lekérdezésre és jelentéskészítésre van optimalizálva, így ideális üzleti intelligencia alkalmazásokhoz. Mindazonáltal problémái voltak a tárgyorientált információk elkülönítésével, az adatredundanciával, az inkompatibilis lekérdezési struktúrákkal, a méretezhetőségi nehézségekkel, a ténytáblázatok inkonzisztens részletességével, a szinkronizálási problémákkal, valamint a felülről lefelé irányuló tervezés szükségességével, alulról felfelé építkező megvalósítással.
Ezzel szemben a Data Vault architektúra egy hibrid megközelítés, amely egyesíti a 3NF és a Kimball architektúrák szempontjait. Ez egy relációs elveken, adatnormalizáláson és redundancia matematikán alapuló modell, amely eltérően ábrázolja az entitások közötti kapcsolatokat, és eltérően strukturálja a táblamezőket és az időbélyegeket.
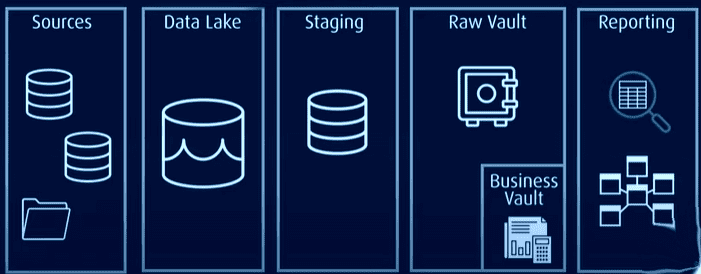
Ebben az architektúrában az összes adatot egy nyers adattárolóban vagy adattóban tárolják, míg az általánosan használt adatokat normalizált formátumban tárolják egy üzleti tárolóban, amely a jelentéskészítéshez felhasználható előzmény- és kontextus-specifikus adatokat tartalmaz.
A Data Vault hatékonyabb, skálázható és rugalmasabb megoldással kezeli a hagyományos modellek problémáit. Közel valós idejű betöltést, jobb adatintegritást és egyszerű bővítést tesz lehetővé a meglévő struktúrák befolyásolása nélkül. A modell a meglévő táblák áttelepítése nélkül is bővíthető.
Modellezési megközelítésAdatstruktúra-tervezési megközelítés3NF modellezési táblázatok a 3NFBottom-upKimbal ModelingStar-sémában vagy Snowflake-sémábanFentről-lefelé Data VaultHub-and-SpokeBottom-up
A Data Vault architektúrája
A Data Vault hub-and-spoke architektúrájú, és lényegében három rétegből áll:
Átmeneti réteg: Összegyűjti a nyers adatokat a forrásrendszerekből, például a CRM-ből vagy az ERP-ből
Adattárház-réteg: Data Vault-modellként modellezve ez a réteg a következőket tartalmazza:
- Raw Data Vault: a nyers adatokat tárolja.
- Business Data Vault: az üzleti szabályok alapján harmonizált és átalakított adatokat tartalmaz (opcionális).
- Metrics Vault: futásidejű információkat tárol (opcionális).
- Operational Vault: tárolja azokat az adatokat, amelyek közvetlenül az operációs rendszerekből áramlanak az adattárházba (opcionális).
Data Mart Layer: Ez a réteg csillagsémaként és/vagy egyéb modellezési technikákként modellezi az adatokat. Információkat ad az elemzéshez és a jelentéskészítéshez.
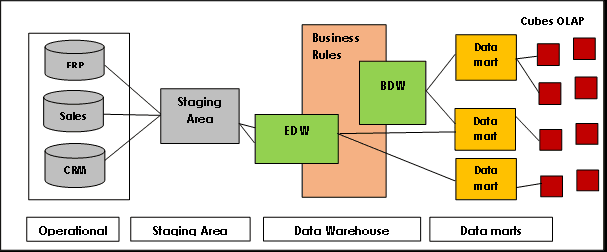 Kép forrása: Lamia Yessad
Kép forrása: Lamia Yessad
A Data Vault nem igényel újbóli felépítést. A Data Vault koncepcióival és módszereivel párhuzamosan új funkciók közvetlenül is építhetők, és a meglévő komponensek nem vesznek el. A keretrendszerek jelentősen megkönnyíthetik a munkát: réteget hoznak létre az adattárház és a fejlesztő között, és így csökkentik a megvalósítás bonyolultságát.
A Data Vault összetevői
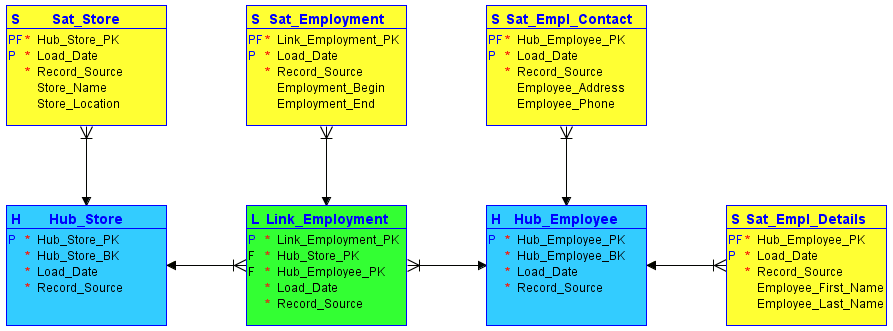
A Data Vault a modellezés során az objektumhoz tartozó összes információt három kategóriába sorolja – ellentétben a klasszikus harmadik normálforma modellezéssel. Ezt az információt azután egymástól szigorúan elkülönítve tárolják. A funkcionális területek leképezhetők a Data Vaultban úgynevezett hubokban, linkekben és műholdakban:
#1. Hubok
A központok képezik az alapvető üzleti koncepció szívét, mint például az ügyfél, az eladó, az értékesítés vagy a termék. A hub-tábla az üzleti kulcs (üzletnév vagy hely) körül jön létre, amikor az üzleti kulcs új példánya először kerül be az adattárházba.
A hub nem tartalmaz leíró információkat és nem tartalmaz FK-kat. Csak az üzleti kulcsból áll, egy raktár által generált azonosító- vagy hash-kulcssorozattal, betöltési dátum/időbélyegzővel és rekordforrással.
#2. Linkek
A hivatkozások kapcsolatokat hoznak létre az üzleti kulcsok között. A hivatkozás minden bejegyzése tetszőleges számú hub nm-es kapcsolatait modellezi. Lehetővé teszi, hogy az adattár rugalmasan reagáljon a forrásrendszerek üzleti logikájában bekövetkezett változásokra, például a kapcsolatok szívélyességében bekövetkezett változásokra. A hubhoz hasonlóan a link sem tartalmaz leíró információt. A hivatkozott hubok sorozatazonosítóiból, a raktár által generált sorozatazonosítóból, a betöltési dátum/időbélyegzőből és a rekordforrásból áll.
#3. Műholdak
A műholdak a központban tárolt üzleti kulcshoz vagy egy hivatkozásban tárolt kapcsolathoz tartalmazzák a leíró információkat (kontextust). A műholdak „csak beszúrásként” működnek, ami azt jelenti, hogy a teljes adatelőzményeket a műhold tárolja. Több műhold is leírhat egyetlen üzleti kulcsot (vagy kapcsolatot). Egy műhold azonban csak egy kulcsot (hub vagy link) tud leírni.
 Kép forrása: Carbidfischer
Kép forrása: Carbidfischer
Hogyan készítsünk Data Vault modellt
A Data Vault modell felépítése több lépésből áll, amelyek mindegyike kritikus fontosságú annak biztosításához, hogy a modell méretezhető, rugalmas legyen, és megfeleljen a vállalkozás igényeinek:
#1. Az entitások és attribútumok azonosítása
Azonosítsa az üzleti entitásokat és a hozzájuk tartozó attribútumokat. Ez magában foglalja az üzleti érdekelt felekkel való szoros együttműködést annak érdekében, hogy megértsék követelményeiket és a rögzítendő adatokat. Miután azonosította ezeket az entitásokat és attribútumokat, válassza szét őket hubokra, linkekre és műholdakra.
#2. Entitáskapcsolatok meghatározása és hivatkozások létrehozása
Az entitások és attribútumok azonosítása után az entitások közötti kapcsolatok meghatározásra kerülnek, és létrejönnek a hivatkozások, amelyek ezeket a kapcsolatokat képviselik. Minden hivatkozáshoz hozzá van rendelve egy üzleti kulcs, amely azonosítja az entitások közötti kapcsolatot. A műholdak ezután hozzáadódnak, hogy rögzítsék az entitások attribútumait és kapcsolatait.
#3. Szabályok és szabványok felállítása
A hivatkozások létrehozása után szabályokat és adattároló-modellezési szabványokat kell létrehozni annak érdekében, hogy a modell rugalmas legyen, és képes legyen kezelni az idő múlásával kapcsolatos változásokat. Ezeket a szabályokat és szabványokat rendszeresen felül kell vizsgálni és frissíteni kell annak biztosítása érdekében, hogy relevánsak maradjanak, és összhangban legyenek az üzleti igényekkel.
#4. Töltse fel a modellt
A modell létrehozása után növekményes betöltési módszerrel kell feltölteni adatokkal. Ez magában foglalja az adatok betöltését a központokba, kapcsolatokba és műholdakra, delta terhelések segítségével. A delta betöltése biztosítja, hogy csak az adatokon végrehajtott módosítások kerüljenek betöltésre, csökkentve az adatintegrációhoz szükséges időt és erőforrásokat.
#5. Tesztelje és érvényesítse a modellt
Végül a modellt tesztelni és érvényesíteni kell, hogy megbizonyosodjon arról, hogy megfelel az üzleti követelményeknek, és elég skálázható és rugalmas a jövőbeli változások kezelésére. Rendszeres karbantartást és frissítést kell végezni annak biztosítása érdekében, hogy a modell összhangban maradjon az üzleti igényekkel, és továbbra is egységes képet adjon az adatokról.
Data Vault tanulási források
A Data Vault elsajátítása olyan értékes készségeket és ismereteket biztosíthat, amelyek nagyon keresettek a mai adatközpontú iparágakban. Íme egy átfogó lista azokról a forrásokról, köztük tanfolyamokról és könyvekről, amelyek segíthetnek a Data Vault fortélyainak megismerésében:
#1. Data Warehouse modellezése Data Vault 2.0-val

Ez az Udemy-tanfolyam egy átfogó bevezetés a Data Vault 2.0 modellezési megközelítésébe, az agilis projektmenedzsmentbe és a Big Data integrációjába. A tanfolyam lefedi a Data Vault 2.0 alapjait és alapjait, beleértve annak architektúráját és rétegeit, az üzleti és információs tárolókat, valamint a fejlett modellezési technikákat.
Megtanítja Önnek, hogyan tervezzen meg egy Data Vault modellt a semmiből, hogyan konvertálja át a hagyományos modelleket, például a 3NF-et és a dimenziós modelleket Data Vaulttá, és hogyan tudja megérteni a Data Vault dimenziós modellezésének alapelveit. A tanfolyam alapismereteket igényel az adatbázisokról és az SQL alapjairól.
Magas, 5-ből 4,4-es értékelésével és több mint 1700 értékelésével ez a legkelendőbb kurzus mindenki számára megfelelő, aki szilárd alapot szeretne építeni a Data Vault 2.0 és a Big Data integráció terén.
#2. Data Vault Modeling Explained with Use Case

Ennek az Udemy-tanfolyamnak az a célja, hogy gyakorlati üzleti példán keresztül eligazítson egy Data Vault modell felépítésében. Kezdő útmutatóként szolgál a Data Vault modellezéshez, amely olyan kulcsfontosságú fogalmakat tartalmaz, mint a Data Vault modellek használatának megfelelő forgatókönyvei, a hagyományos OLAP modellezés korlátai és a Data Vault modell felépítésének szisztematikus megközelítése. A tanfolyam minimális adatbázis-ismerettel rendelkező személyek számára elérhető.
#3. A Data Vault Guru: pragmatikus útmutató
Patrick Cuba úr által készített Data Vault Guru egy átfogó útmutató az adattároló módszertanához, amely egyedülálló lehetőséget kínál a vállalati adattárház modellezésére a szoftverszállításban használt automatizálási elvekhez hasonló módon.
A könyv áttekintést ad a modern architektúráról, majd alapos útmutatót ad a rugalmas adatmodell elkészítéséhez, amely alkalmazkodik a vállalat, az adattároló változásaihoz.
Ezenkívül a könyv kibővíti az adattároló módszertanát azáltal, hogy automatizált idővonal-javítást, ellenőrzési nyomvonalakat, metaadat-ellenőrzést és agilis kézbesítési eszközökkel való integrációt biztosít.
#4. Skálázható adattárház építése a Data Vault 2.0-val
Ez a könyv átfogó útmutatót nyújt az olvasóknak egy méretezhető adattárház létrehozásához az elejétől a végéig a Data Vault 2.0 módszertan használatával.
Ez a könyv lefedi a méretezhető adattárház felépítésének minden lényeges szempontját, beleértve a Data Vault modellezési technikát, amely a tipikus adattárházi hibák megelőzésére szolgál.
A könyv számos példát tartalmaz, amelyek segítik az olvasókat a fogalmak világos megértésében. Gyakorlati meglátásaival és valós példáival ez a könyv nélkülözhetetlen forrás minden adattárház iránt érdeklődő számára.
#5. Az elefánt a hűtőben: Irányított lépések a Data Vault sikeréhez
John Giles Elefánt a hűtőben című könyve egy gyakorlati útmutató, amelynek célja, hogy segítse az olvasókat a Data Vault sikereinek elérésében, az üzlettől kezdve és a vállalkozással befejezve.
A könyv a vállalati ontológia és az üzleti koncepciók modellezésének fontosságára összpontosít, és lépésről lépésre útmutatást ad ezeknek a fogalmaknak a szilárd adatmodell létrehozásához.
Gyakorlati tanácsokon és mintamintákon keresztül a szerző világos és egyszerű magyarázatot kínál bonyolult témákra, így a könyv kiváló útmutatóvá válik azok számára, akik most ismerkednek az Adattárral.
Végső szavak
A Data Vault az adattárház jövőjét képviseli, jelentős előnyöket kínálva a vállalatoknak az agilitás, a méretezhetőség és a hatékonyság tekintetében. Különösen alkalmas azoknak a vállalkozásoknak, amelyeknek nagy mennyiségű adatot kell gyorsan betölteniük, valamint azoknak, amelyek üzleti intelligencia alkalmazásaikat agilis módon szeretnék fejleszteni.
Ezen túlmenően a meglévő silóarchitektúrával rendelkező vállalatok nagy hasznot húzhatnak a Data Vault segítségével egy upstream alapvető adattárház megvalósításából.
Érdekelheti az adatvonal megismerése is.