

A gráf adatbázisok szorosan összekapcsolt, sűrű adatokat tárolnak, és hatékonyan dolgozzák fel a lekérdezéseket. De tudod, hogy mikor melyik gráf adatbázist kell használni? További információért olvassa el.
„Az adatok az új olaj.” Minden szervezet növekedése azon múlik, hogy hogyan tárolják és használják fel hatékonyan az adatokat. Naponta 2,5 kvintimillió bájt adat keletkezik. Tehát szükségünk van hibatűrő rendszerekre és raktárakra, ahol az adatok hatékonyan tárolhatók és kezelhetők. Kezdetben relációs adatbázisokat használtak.
De ahogy telt az idő, az adatok mennyisége és típusa gyorsan változott. Ezért szükség volt videó, hang, képek stb. tárolására. Ez volt a kiváltó pont az SQL, NoSQL adatbázisok, Hadoop, gráf adatbázisok stb. fejlesztéséhez. Mindegyiknek megvannak a saját használati esetei, és különböző adatformátumokkal foglalkoznak. A gráf adatbázisokat az adatokkal kapcsolatos műveletek egyszerűsítésére és a hatékony tárolásra fejlesztették ki.
Tartalomjegyzék
Grafikon adatbázisok
A gráf csomópontok és élek formájában ábrázolt adatstruktúra. Az adatbázis táblák gyűjteménye, amely adatokat és az adatok közötti kapcsolatokat tárolja. A gráfadatbázis olyan adatbázis, amely az adatokat csomópontokban és az adatokon belüli kapcsolatokat élek formájában tárolja. A gráf-adatbázisok segítenek a valós idejű lekérdezések kezelésében és az entitások közötti sok-sok kapcsolatok hatékony kezelésében.
A népszerű grafikon adatmodellek közé tartoznak a tulajdonsággráfok és az RDF grafikonok. Az elemzés és a lekérdezés többnyire tulajdondiagramok segítségével történik. Az adatok integrációja RDF grafikonok segítségével történik. A Tulajdonság és az RDF gráfok közötti különbség az, hogy az RDF gráfok hármasok, azaz alany, predikátum és objektum formájában vannak ábrázolva.
A gráf adatbázisok az adatokat a csomópontokban tárolják, az adatok közötti kapcsolatot pedig a csomópontok közötti élek formájában. A gráf élei lehetnek irányítottak (egyirányúak) vagy irányítatlanok (kétirányúak).
A lekérdezés feldolgozása a grafikonon való bejárással történik. A lekérdezések hatékony megválaszolására olyan gráfbejárási algoritmusokat használnak, amelyek segítenek megtalálni az egyik csomóponttól a másikig vezető utat, a csomópontok közötti távolságot, megtalálni a mintákat, a gráfon belüli hurkokat, valamint a klaszterek kialakításának lehetőségét stb.
Grafikus adatbázisok alkalmazásai
A grafikonos adatbázisokat a csalások felderítésére használják. A csomópontok/entitások lehetnek személyek neve, címe, születési dátuma stb., valamint néhány hamis IP-cím, eszközszám stb. Ha egy csaló csomópont interakcióba lép egy nem csalárd csomóponttal, kapcsolatok jönnek létre közöttük, és a következőként vannak megjelölve. gyanús.
A közösségi média webhelyek grafikonos adatbázisokat használnak, hogy megjelenítsék azon személyek ajánlásait, akikkel esetleg kapcsolatba lépnénk, és milyen tartalmat szeretnénk megtekinteni. Ezt az adatbázisban található gráfbejárások segítségével teszi.
A hálózatleképezés és az infrastruktúra-kezelés, a konfigurációs elemek stb. szintén hatékonyan tárolhatók és kezelhetők gráfadatbázisok segítségével.
Graph Database vs. Relational Database
A gráf adatbázisban a sorokat és oszlopokat tartalmazó táblázatok csomópontokra és élekre cserélődnek. Az adatok közötti kapcsolatokat a gráf adatbázis élei tárolják.
A relációs adatbázis az idegen kulcsokat használó táblák és más táblák közötti kapcsolatokat tárolja. Az adatok kinyerése vagy lekérdezése egyszerű, és nem igényel bonyolult összekapcsolásokat egy gráfadatbázisban, de ez nem így van a relációs adatbázisoknál.
A relációs adatbázisok a legmegfelelőbbek olyan felhasználási esetekre, amelyek tranzakciókat tartalmaznak, míg a gráf adatbázisok a kapcsolat- és adatintenzív alkalmazásokhoz.
A gráf adatbázisok támogatják a strukturált, félig strukturált és strukturálatlan adatokat, míg a relációs adatbázisoknak rögzített sémával kell rendelkezniük.
A gráf adatbázisok kielégítik a dinamikus követelményeket, míg a relációs adatbázisokat általában ismert és statikus problémákra használják.
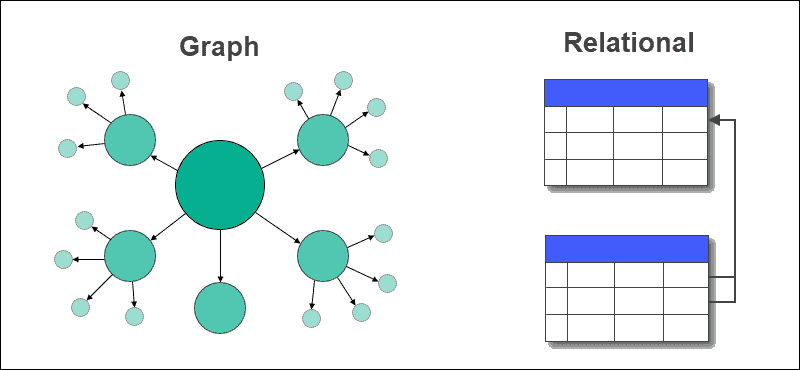 Grafikon vs. relációs adatbázisok
Grafikon vs. relációs adatbázisok
Nézzük most a legjobb gráf adatbázis-megoldásokat.
Cayley
A Cayley egy nyílt forráskódú gráf adatbázis, amelyet az Apache 2.0 fejlesztett ki. A Go használatával készült, és kapcsolt adatokon működik. A Cayley az az adatbázis, amelyet a Google Freebase és tudásgráfjának felépítéséhez használnak. Több lekérdezési nyelvet támogat, például az MQL-t és a Javascriptet egy Gremlin-alapú gráfobjektummal.
Könnyen használható, gyors és moduláris felépítésű. Integrálható és kölcsönhatásba léphet a különféle háttértárolókkal, mint például a LevelDB, a MongoDB és a Bolt. Támogatja a különböző harmadik féltől származó API-kat, amelyek több nyelven íródnak, például Java, .NET, Rust, Haskell, Ruby, PHP, Javascript és Clojure. Dockerben és Kubernetesben telepíthető. A Cayley használatának kulcsfontosságú területei az információs technológia, a számítógépes szoftverek és a pénzügyi szolgáltatások.
Amazon Neptunusz
Az Amazon Neptune arról ismert, hogy kiemelkedően jól teljesít a szorosan összekapcsolt adatkészleteken. Megbízható, biztonságos, teljesen felügyelt, és támogatja a nyílt gráf API-kat. Kapcsolatok milliárdjait és lekérdezési adatokat képes tárolni rendkívül alacsony, néhány ezredmásodperces késleltetéssel.
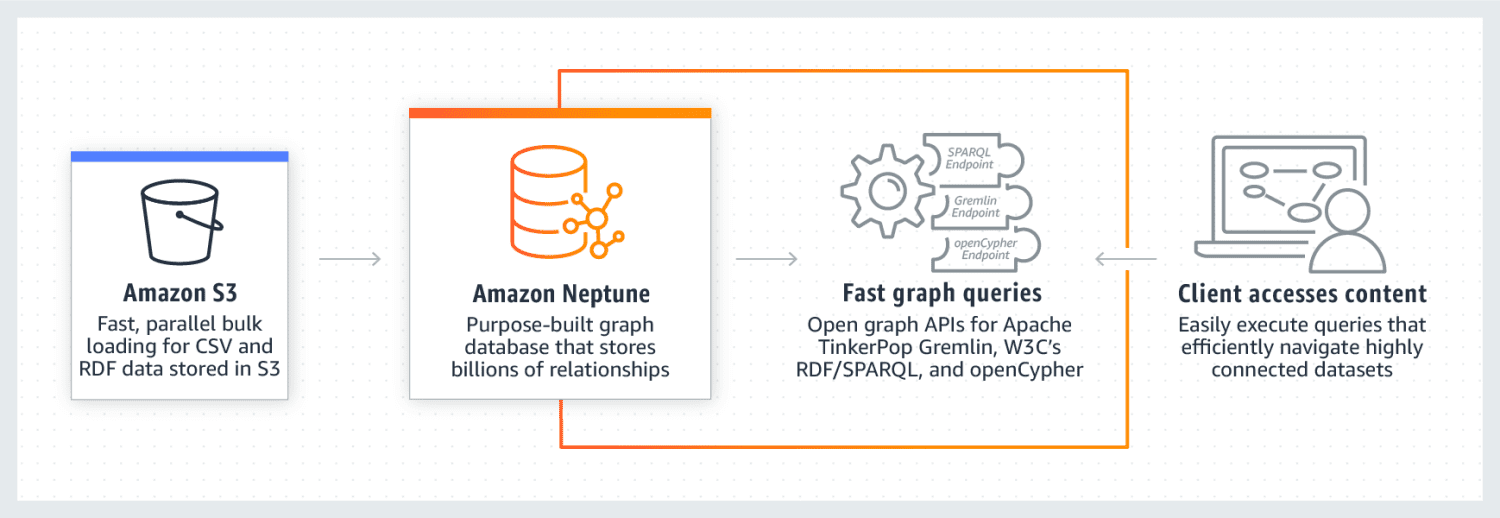
A Neptunusz gráf adatmodell 4 pozícióból áll, nevezetesen alanyból (S), predikátumból (P), objektumból (O) és gráfból (G). Ezen pozíciók mindegyike a forráscsomópont, a célcsomópont pozíciójának, a köztük lévő kapcsolatnak és tulajdonságaik tárolására szolgál.
Gyorsítótárat is használ, amely felgyorsítja az olvasási lekérdezések végrehajtását. Az adatok tárolása DB-klaszterek formájában történik. Minden fürt egy elsődleges DB-példányból és DB-példányok olvasási replikáiból áll. A Neptune rendkívül biztonságos, mivel IAM-hitelesítést, SSL-tanúsítványt és naplófigyelést használ. Ezenkívül könnyen migrálhat más forrásokból származó adatokat az Amazon Neptune-ba. Replikák és időszakos biztonsági mentések létrehozásával is biztosítja a rugalmasságot. Egyes Neptune-t használó cégek közé tartozik a Herren, a Onedot, a Juncture és a Hi Platform.
Neo4j
A Neo4j egy méretezhető, biztonságos, igény szerinti és megbízható gráf adatbázis. A Neo4j Java használatával készült, lekérdezési nyelvként a Cypher használatával. A Bolt protokollt használja, és minden tranzakció HTTP-végponton keresztül történik. Más relációs adatbázisokhoz képest sokkal gyorsabban válaszol a lekérdezésekre. Nincs benne az összetett összekapcsolások többletterhelése, és az optimalizálás jól működik, ha az adatkészlet mérete nagy és erősen összekapcsolt. A relációs adatbázis ACID tulajdonságai mellett a gráftárolás előnyét kínálja.

A Neo4j különféle nyelveket támogat, mint például a Java, a .NET, a Node.js, a Ruby, a Python stb., illesztőprogramok segítségével. A grafikon adatok tudományában, az analitikában és a gépi tanulási munkafolyamatokban is használatos. A Neo4j Aura DB egy hibatűrő és teljes körűen felügyelt felhőgrafikon adatbázis. Az olyan cégek, mint a Microsoft, a Cisco, az Adobe, az eBay, az IBM, a Samsung stb. használják a Neo4j-t.
ArangoDB
Az ArangoDB egy nyílt forráskódú, több modellből álló adatbázis. A többmodelles megközelítés lehetővé teszi a felhasználók számára az adatok lekérdezését az általuk választott tetszőleges lekérdezési nyelven. Az ArangoDB csomópontjai és élei JSON-dokumentumok. Minden dokumentumnak egyedi azonosítója van. A két csomópont közötti kapcsolatokat élek formájában jelzik, és egyedi azonosítóikat tárolják. Jó teljesítményét a hash index jelenlétének köszönheti.

Az adatbázisokban való bejárások, csatlakozások és keresések továbbfejlesztettek. Segít a tervezésben, a méretezésben és a különféle architektúrákhoz való alkalmazkodásban. Fontos szerepet játszik az olyan összetett adattudományi feladatokban, mint a funkciók kinyerése és a speciális keresés.
Az ArrangoDB felhő alapú környezetben is futhat, és kompatibilis a Mac Os, Linux és Windows rendszerekkel. Az LDAP-hitelesítés, az adatmaszkolás és a titkosítási algoritmusok biztosítják az adatbázis biztonságát. Kockázatkezelésben, IAM-ben, csalásészlelésben, hálózati infrastruktúrában, ajánlómotorokban stb. használják. Az Accenture, a Cisco, a Dish és a VMware néhány ArangoDB-t használó szervezet.
DataStax
A DataStax egy NoSQL felhőalapú adatbázis-szolgáltatás, amely Apache Cassandra-ra épül. Nagyon skálázható, és felhőalapú architektúrát használ. Megbízható és biztonságos. Minden DataStax-ban tárolt dokumentum rendelkezik egy indexszel, amely segíti az egyszerű keresést és az adatok gyors visszakeresését. Az indexelt adatok felett szilánkok jönnek létre. Különféle adatforrások használhatók alkalmazások létrehozásához a Datastax Enterprise eszközökkel, a Kafka és a Docker segítségével.
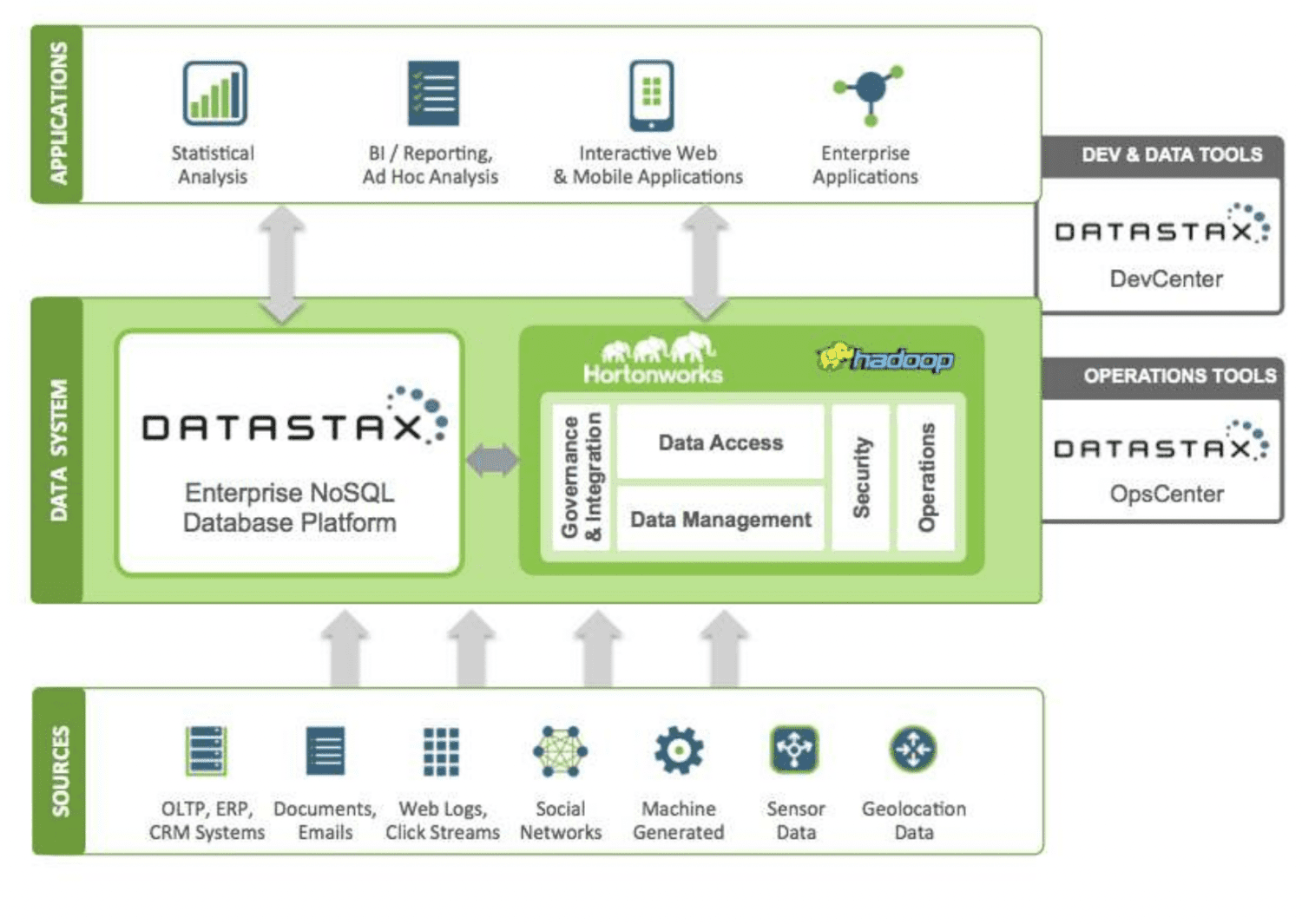
A forrásokból gyűjtött adatokat egy Hadoop-ökoszisztéma és DataStax küldi. A Hadoop a DataStax-szal együttműködve kezeli a biztonságot, a műveleteket, az adathozzáférést és -kezelést. Az adatok finomítása a Datastax fejlesztői és üzemeltetési eszközeivel történik.
Az elemzett információkat ezután statisztikai elemzésekhez, vállalati alkalmazásokhoz, jelentéskészítéshez stb. használják fel. Mivel felhő alapú, az ügyfelek fizetnek azért, amit használnak, és az ár ésszerű. A Verizon, a CapitalOne, a TMobile és az Overstock néhány olyan vállalat, amely DataStax-ot használ.
Orient DB
Az OrientDB egy gráf adatbázis, amely hatékonyan kezeli az adatokat, és segít vizuális megjelenítések létrehozásában az adatok bemutatásához. Ez egy több modellből álló gráf adatbázis, és Java használatával készült. Az adatokat kulcs-érték párok, dokumentumok, objektummodellek stb. formájában tárolja. 3 jelentős komponensből áll: grafikonszerkesztő, stúdió lekérdezés és parancssori konzol.
Grafikonszerkesztőt használnak az adatok megjelenítésére és interakciójára. A Studio lekérdezési felület a lekérdezések végrehajtására és a kimenet azonnali megjelenítésére szolgál kép és táblázatos formátumban. A parancssori konzol az OrientDB-ből származó adatok lekérdezésére szolgál. Elosztott architektúrája több szerverrel rendelkezik, amelyek olvasási és írási műveleteket hajtanak végre. A replikaszerverek olvasási és lekérdezési műveletek végrehajtására szolgálnak. Támogatja az indexelést és ACID-kompatibilis is. Az OrientDB-t használó vállalatok közül néhány a Comcast Corporation és a Blackfriars Group.
Dgraph
A Dgraph egy felhőalapú gráf adatbázis, amely támogatja a GraphQL-t. Go segítségével készült. Minimalizálja a hálózati hívásokat és csökkenti a késleltetést az egyidejű lekérdezés feldolgozás maximalizálásával. A Dgraph és a GraphQL zökkenőmentes integrációja elősegíti a GraphQL háttéralkalmazások egyszerű fejlesztését.

A GraphQL mutációt egy Lambda függvényen keresztül vezetik át, amely kölcsönhatásba lép az adatbázissal és az adatfolyamattal. Ez leegyszerűsíti a lekérdezések feldolgozását. Vízszintesen skálázható, ami azt jelenti, hogy az erőforrások száma a növekvő lekérdezések és adatok növekedésével nő. Különféle szolgáltatásokat kínál, például JWT-alapú engedélyezést, adatvizualizálót, felhőalapú hitelesítést, adatmentéseket stb. A Dgraph-ot használó egyes szervezetek közé tartozik az Intuit, az Intel és a Factset.
Tigrisgráf
A Tigergraph egy tulajdonsággráf adatbázis, amelyet C++ használatával fejlesztettek ki. Nagyon skálázható, és fejlett elemzést végez a szorosan összekapcsolt adatokon. Natív gráfstruktúrát használ az adatok tárolására és egy gráffeldolgozó motort az adatok feldolgozására. Az adatbázis a lemezen és a memóriában van tárolva, és CPU gyorsítótárat is használ a gyors visszakereséshez. A párhuzamos adatfeldolgozáshoz a Map Reduce funkciót használja.
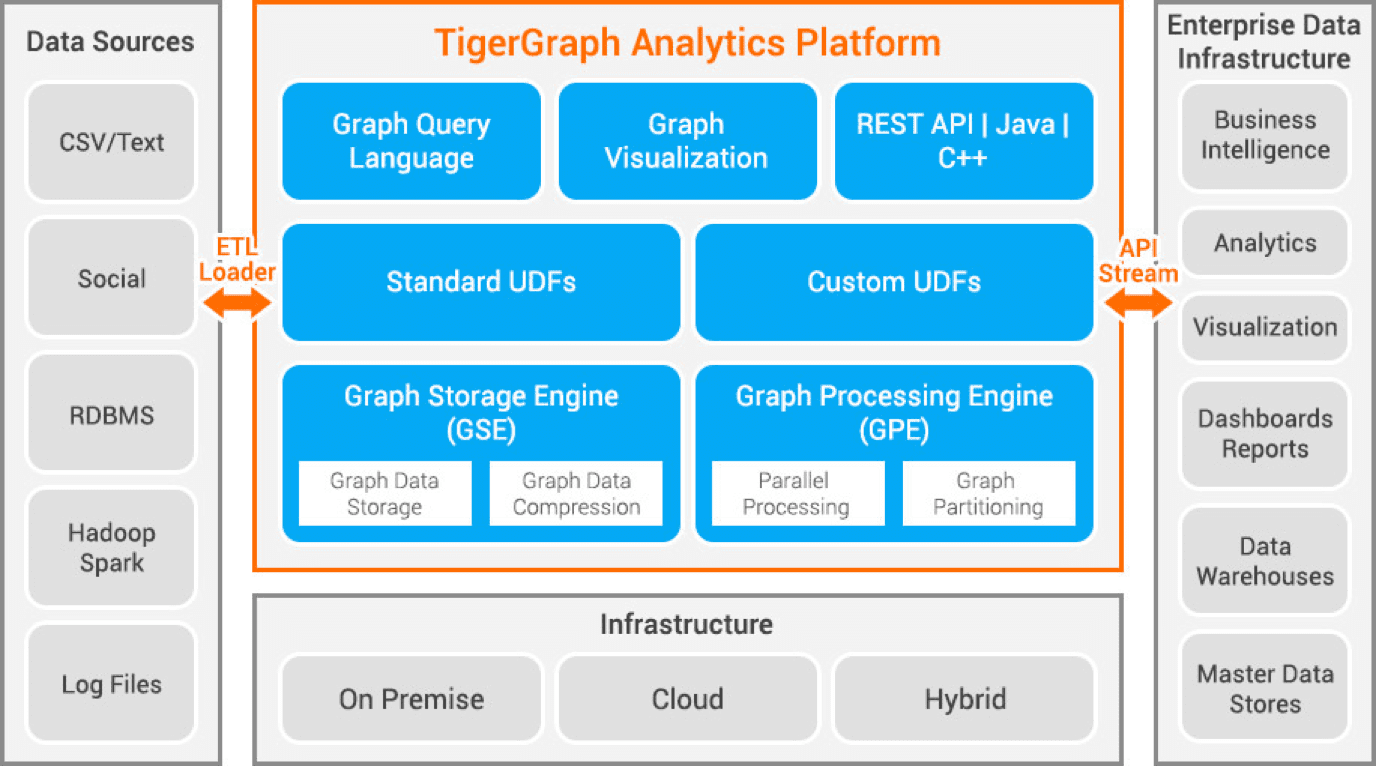
Rendkívül gyors és skálázható. Párhuzamos számításokat végez, és valós idejű frissítéseket biztosít. Adattömörítési technikákat használ, és 10-szeresére tömöríti az adatokat. Automatikusan felosztja az adatokat a szerverek között, így időt és energiát takarít meg a felhasználónak az adatok kézi szilánkolásához. A csalások felderítésére a háztartásokban, az ellátási lánc kezelésére és az egészségügyi ellátás javítására használják. A JPMorgan Chase, az Intuit és a United Health Group néhány szervezet használja a Tigergraph-ot.
AllegroGraph
Az AllegroGraph entitás-esemény tudásgráf technológiát használ, hogy elemzéseket és döntéseket hajtson végre szorosan összekapcsolt, összetett és sűrű adatokon. Az adatok JSON és JSON-LD formátumban kerülnek tárolásra a grafikon csomópontjaiban. A REST protokoll architektúrát használja. Rendkívül nagy adathalmazokkal is foglalkozik azáltal, hogy meghatározott kritériumok alapján felosztja az adatokat, és több tudásbázis-tárban szétosztja.
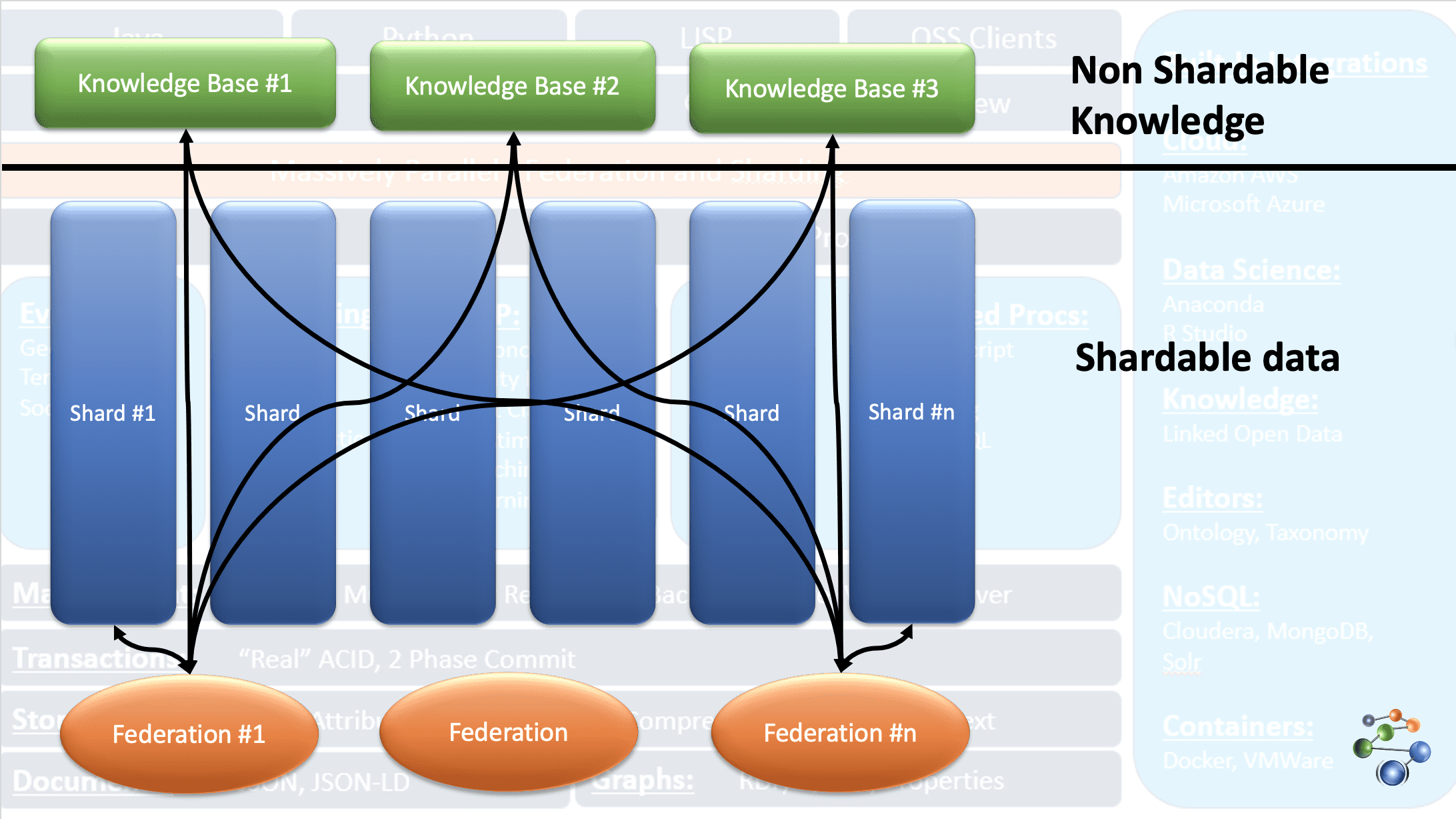
Ez az AllegroGraph adatbázis FedShard szolgáltatása miatt lehetséges. A lekérdezések végrehajtása az összevonások tudásbázis-tárolókkal való kombinálásával történik. Támogatja az XML sématípusokat, és hármas indexeket használ. Térinformatikai adatokat, például szélességi és hosszúsági fokokat, valamint időbeli adatokat, például dátumot, időbélyeget stb. tárol. Windows, Mac és Linux rendszerrel is kompatibilis. Csalások felderítésében, egészségügyi ellátásban, entitásazonosításban, kockázat-előrejelzésben stb. használják.
Stardog
A Stardog egy gráfadatbázis, amely a grafikonadatok virtualizációját hajtja végre, és összekapcsolja az adattárházakból és adattavakból származó adatokat anélkül, hogy az adatokat fizikailag új tárolóhelyre másolná. A Stardog RDF nyílt szabványokra épül. Támogatja a strukturált, félig strukturált és strukturálatlan adatokat. Ez a Stardog által végzett materializálás rugalmasságot kínál. Ez az egyetlen gráf adatbázis, amely egyesíti a tudásgráfokat és a virtualizációt.
A Stardog mesterséges intelligencia által hajtott következtetési motort használ a lekérdezési kimenetek hatékony feldolgozásához és biztosításához. Ez egy ACID-kompatibilis gráf adatbázis. Az egyidejű olvasás és írás támogatott. A „korszerű” architektúrának köszönhetően könnyedén kezeli az összetett lekérdezéseket. Az IT Asset Management, adatkezelés és elemzés területén használják, és magas rendelkezésre állást biztosít. Néhány Stardogot használó cég a Cisco, az eBay, a NASA és a Finra.
Utolsó szavak
A gráfadatbázisok segítségével egyszerűen lekérdezhetők a sok-sok kapcsolatok, és hatékonyan tárolhatók az adatok. Skálázhatóak, biztonságosak, és számos harmadik féltől származó eszközzel, API-val és nyelvvel integrálhatók. Az elmúlt években integrálták őket a felhőbe, és a legjobb teljesítményt nyújtják.
Leegyszerűsítik az összetett csatlakozásokat egyszerű lekérdezésekké, így a fejlesztők számára egyszerű feladat. Az olyan adatigényes feladatok, mint az IoT és a Big Data, szintén gráfadatbázisok. Ezek folyamatosan fejlődnek, és a jövőben minden bizonnyal más felhasználási esetekre is kiterjednek majd.