
Az Apache Parquet számos előnnyel rendelkezik az adattárolás és -visszakeresés terén a hagyományos módszerekhez, például a CSV-hez képest.
A parketta formátumot összetett típusok gyorsabb adatfeldolgozására tervezték. Ebben a cikkben arról beszélünk, hogy a Parquet formátum hogyan felel meg napjaink folyamatosan növekvő adatigényeinek.
Mielőtt belemélyednénk a Parquet formátum részleteibe, ismerjük meg, mi a CSV-adat, és milyen kihívásokat jelent az adattárolás számára.
Tartalomjegyzék
Mi az a CSV-tárhely?
Mindannyian sokat hallottunk a CSV-ről (vesszővel elválasztott értékek) – ez az adatok rendszerezésének és formázásának egyik leggyakoribb módja. A CSV adattárolás soralapú. A CSV-fájlok tárolása .csv kiterjesztéssel történik. A CSV-adatokat Excel, Google Táblázatok vagy bármilyen szövegszerkesztő segítségével tárolhatjuk és nyithatjuk meg. Az adatok a fájl megnyitása után könnyen megtekinthetők.
Nos, ez nem jó – adatbázis-formátumhoz biztosan nem.
Továbbá, ahogy az adatmennyiség növekszik, nehezebbé válik a lekérdezés, a kezelés és a visszakeresés.
Íme egy példa a .CSV-fájlban tárolt adatokra:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Ha Excelben nézzük, az alábbi sor-oszlop szerkezetet láthatjuk:
Kihívások a CSV-tárral kapcsolatban
A soralapú tárolók, mint például a CSV, alkalmasak a létrehozási, frissítési és törlési műveletekre.
Mi van akkor a Read in CRUD-ban?
Képzelj el egy millió sort a fenti .csv fájlban. Ésszerű időbe telne a fájl megnyitása és a keresett adatok megkeresése. Nem olyan menő. A legtöbb felhőszolgáltató, például az AWS, a beolvasott vagy tárolt adatok mennyisége alapján számít fel díjat a cégeknek – ismét a CSV-fájlok sok helyet foglalnak el.
A CSV-tárhely nem rendelkezik kizárólagos lehetőséggel a metaadatok tárolására, így az adatok beolvasása unalmas feladat.
Tehát mi a költséghatékony és optimális megoldás az összes CRUD-művelet végrehajtására? Hadd fedezzük fel.
Mi az a parketta adattárolás?
Parkett egy nyílt forráskódú tárolási formátum az adatok tárolására. Széles körben használják a Hadoop és a Spark ökoszisztémákban. A parkettafájlok .parquet kiterjesztéssel kerülnek tárolásra.
A parketta erősen strukturált forma. Használható az adattókban tömegesen jelenlévő összetett nyers adatok optimalizálására is. Ez jelentősen csökkentheti a lekérdezési időt.
A parketta a sor- és oszlopalapú (hibrid) tárolási formátumok keveredésének köszönhetően hatékonyabbá és gyorsabbá teszi az adattárolást és a visszakeresést. Ebben a formátumban az adatok vízszintesen és függőlegesen is particionálva vannak. A parketta formátum nagymértékben kiküszöböli az elemzési költségeket is.
A formátum korlátozza az I/O műveletek számát és végső soron a költségeket.
A Parquet tárolja a metaadatokat is, amelyek információkat tárolnak olyan adatokról, mint az adatséma, az értékek száma, az oszlopok helye, a minimális érték, a sorcsoportok maximális értéke, a kódolás típusa stb. A metaadatok a fájl különböző szintjein tárolódnak. , ami gyorsabbá teszi az adatok elérését.
A soralapú hozzáférésben, például a CSV-ben, az adatok lekérése időt vesz igénybe, mivel a lekérdezésnek végig kell navigálnia az egyes sorokon, és meg kell kapnia az adott oszlopértékeket. A parkettatárolóval az összes szükséges oszlop egyszerre elérhető.
Összefoglalva,
- A parketta az adattárolás oszlopos szerkezetére épül
- Ez egy optimalizált adatformátum összetett adatok tömeges tárolására tárolórendszerekben
- A parketta formátum különféle módszereket tartalmaz az adatok tömörítésére és kódolására
- Jelentősen csökkenti az adatbeolvasási és lekérdezési időt, és kevesebb lemezterületet foglal más tárolási formátumokhoz, például a CSV-hez képest
- Minimalizálja az IO-műveletek számát, csökkenti a tárolás és a lekérdezés-végrehajtás költségeit
- Metaadatokat tartalmaz, amelyek megkönnyítik az adatok megtalálását
- Nyílt forráskódú támogatást nyújt
Parketta adatformátum
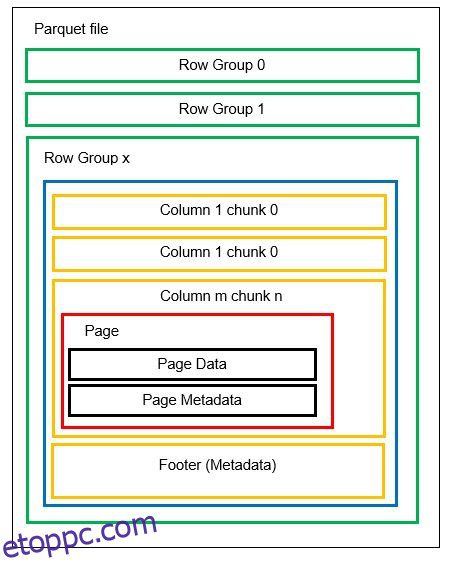
Mielőtt belemennénk egy példába, nézzük meg részletesebben, hogyan tárolódnak az adatok parketta formátumban:
Egy fájlban több vízszintes partíció, sorcsoportként ismert. Minden sorcsoporton belül függőleges particionálás kerül alkalmazásra. Az oszlopok több oszlopra vannak osztva. Az adatokat oldalakként tárolják az oszlopdarabokon belül. Minden oldal tartalmazza a kódolt adatértékeket és metaadatokat. Ahogy korábban említettük, a teljes fájl metaadatai szintén a fájl láblécében vannak tárolva a sorcsoport szintjén.
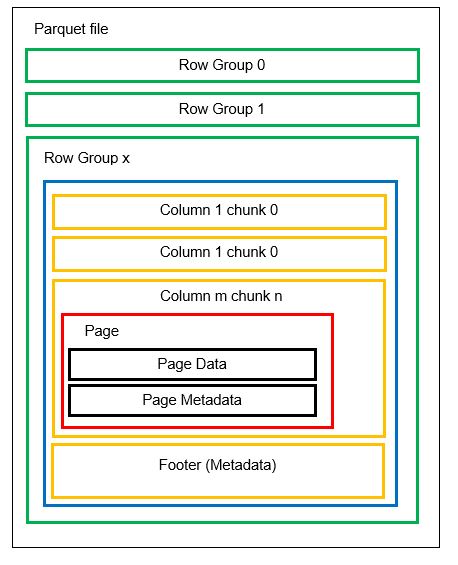
Mivel az adatok oszlopdarabokra vannak osztva, az új adatok hozzáadása az új értékek új darabba és fájlba kódolásával szintén egyszerű. A metaadatok ezután frissülnek az érintett fájlokhoz és sorcsoportokhoz. Így elmondhatjuk, hogy a parketta rugalmas formátum.
A Parquet natívan támogatja az adatok tömörítését oldaltömörítési és szótári kódolási technikákkal. Lássunk egy egyszerű példát a szótártömörítésre:
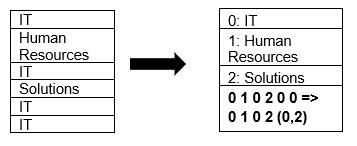
Vegye figyelembe, hogy a fenti példában az IT-felosztást 4-szer látjuk. Tehát a szótárban való tárolás során a formátum egy másik könnyen tárolható értékkel (0,1,2…) kódolja az adatokat, valamint a folyamatos ismétlődések számát – IT, IT 0,2-re változik a mentéshez. több hely. A tömörített adatok lekérdezése kevesebb időt vesz igénybe.
Fej-fej összehasonlítás
Most, hogy van egy tisztességes elképzelésünk arról, hogyan néznek ki a CSV és a Parquet formátumok, ideje néhány statisztikai adatnak összehasonlítani a két formátumot:
CSV
Parkett
Soralapú tárolási formátum.
Soralapú és oszlopalapú tárolási formátumok hibridje.
Sok helyet foglal, mivel nem áll rendelkezésre alapértelmezett tömörítési lehetőség. Például egy 1 TB-os fájl ugyanazt a helyet foglalja el, ha Amazon S3-on vagy bármely más felhőn tárolja.
Tárolás közben tömöríti az adatokat, így kevesebb helyet foglal el. Egy 1 TB-os, Parquet formátumban tárolt fájl mindössze 130 GB helyet foglal el.
A lekérdezés futási ideje lassú a soralapú keresés miatt. Minden oszlophoz minden adatsort le kell kérni.
A lekérdezési idő körülbelül 34-szer gyorsabb az oszlopalapú tárolás és a metaadatok jelenléte miatt.
Lekérdezésenként több adatot kell beolvasni.
Körülbelül 99%-kal kevesebb adatot vizsgálnak meg a lekérdezés végrehajtásához, így optimalizálva a teljesítményt.
A legtöbb tárolóeszköz a tárhely alapján töltődik, így a CSV formátum magas tárolási költséget jelent.
Alacsonyabb tárolási költség, mivel az adatokat tömörített, kódolt formátumban tárolják.
A fájlsémát vagy kikövetkeztetni kell (hibához vezet), vagy meg kell adni (unalmas).
A fájlsémát a metaadatok tárolják.
A formátum egyszerű adattípusokhoz alkalmas.
A parketta még olyan összetett típusokhoz is alkalmas, mint a beágyazott sémák, tömbök, szótárak.
Következtetés 👩💻
Példákon keresztül láthattuk, hogy a Parquet költség, rugalmasság és teljesítmény tekintetében hatékonyabb, mint a CSV. Ez egy hatékony mechanizmus az adatok tárolására és visszakeresésére, különösen akkor, ha az egész világ a felhőalapú tárolás és a helyoptimalizálás felé halad. Minden nagyobb platform, például az Azure, AWS és a BigQuery támogatja a Parquet formátumot.