

Ha megtanult néhány számítógépes programozási nyelvet, valószínűleg hallotta a szövegelemzés kifejezést. Ez a fájl összetett adatértékeinek egyszerűsítésére szolgál. A cikk segít abban, hogy megtudja, hogyan kell szöveget elemezni a nyelv használatával. Ezen túlmenően, ha hibába ütközött az x elemző szövegben, tudni fogja, hogyan javítsa ki az elemzési hibát a cikkben.

Tartalomjegyzék
Szöveg elemzése
Ebben a cikkben bemutattunk egy teljes útmutatót a szöveg különböző módokon történő elemzéséhez, valamint röviden bemutattuk a szöveg elemzését.
Mi az a szövegelemzés?
Mielőtt belevágna, tanulja meg a szövegelemzés fogalmait bármilyen kóddal. Fontos tudni a nyelv és a kódolás alapjait.
NLP vagy természetes nyelvi feldolgozás
A szöveg elemzéséhez a természetes nyelvi feldolgozást vagy az NLP-t használják, amely a mesterséges intelligencia tartomány egyik almezője. A Python nyelv, amely a kategóriába tartozó nyelvek egyike, a szöveg elemzésére szolgál.
Az NLP kódok lehetővé teszik a számítógépek számára, hogy megértsék és feldolgozzák az emberi nyelveket, hogy alkalmassá tegyék azokat különféle alkalmazásokhoz. Az ML vagy Machine Learning technikák nyelvre történő alkalmazásához a strukturálatlan szöveges adatokat strukturált táblázatos adatokká kell konvertálni. Az elemzési tevékenység befejezéséhez a Python nyelvet használják a programkódok megváltoztatására.
Mi az a szövegelemzés?
A szöveg elemzése egyszerűen az adatok egyik formátumból egy másik formátumba való konvertálását jelenti. A fájl mentési formátumát elemezni kell, vagy más formátumú fájllá kell konvertálni, hogy a felhasználó különféle alkalmazásokban felhasználhassa.
- Más szavakkal, a folyamat azt jelenti, hogy elemzi a karakterláncot vagy egy szöveget, és a fájl formátumának megváltoztatásával logikai komponensekké alakítja.
- A Python nyelv bizonyos szabályait használják ennek a közös programozási feladatnak a végrehajtására. Szövegelemzés közben az adott szövegsorozat kisebb komponensekre bomlik.
Mi az oka a szöveg elemzésének?
A szöveg elemzésének okait ebben a részben ismertetjük, és ez egy előfeltétel a szövegelemzés ismerete előtt.
- Az összes számítógépes adat nem azonos formátumú, és a különböző alkalmazásoktól függően eltérő lehet.
- Az adatformátumok különböző alkalmazásokban változnak, és egy inkompatibilis kód ezt a hibát eredményezi.
- Nincs egyedi univerzális számítógépes program az összes adatformátum adatainak kiválasztására.
1. módszer: DataFrame osztályon keresztül
A Python nyelv DataFrame osztálya rendelkezik a szöveg elemzéséhez szükséges összes funkcióval. Ez a beépített könyvtár tartalmazza a szükséges kódokat, hogy bármilyen formátumú adatokat más formátumba elemezhessen.
A DataFrame osztály rövid bemutatása
A DataFrame Class egy funkciókban gazdag adatstruktúra, amelyet adatelemző eszközként használnak. Ez egy hatékony adatelemző eszköz, amellyel minimális erőfeszítéssel elemezhetők az adatok.
- A kód beolvasásra kerül a pandas DataFrame-be, hogy Python nyelven végezze el az elemzést.
- Az osztály számos, a pandák által biztosított csomaggal érkezik, amelyeket a Python adatelemzői használnak.
- Ennek az osztálynak a jellemzője a NumPy könyvtár absztrakciója, egy olyan kód, amelyben a függvény belső funkcionalitása el van rejtve a felhasználók elől. A NumPy könyvtár egy python könyvtár, amely magában foglalja a tömbökkel végzett munka parancsait és függvényeit.
- A DataFrame osztály használható több soros és oszlopos indexű kétdimenziós tömb megjelenítésére. Ezek az indexek segítenek a többdimenziós adatok tárolásában, ezért MultiIndexnek hívják őket. Ezeket módosítani kell, hogy tudjuk, hogyan lehet javítani az elemzési hibát.
A Python nyelv pandái segítenek az SQL vagy adatbázis-stílusú műveletek maximális tökéletesítésében, hogy elkerüljék az x szövegelemzési hibákat. Néhány IO-eszközt is tartalmaz, amelyek segítenek a CSV, MS Excel, JSON, HDF5 és más adatformátumok fájlok elemzésében.
Szöveg elemzési folyamata DataFrame osztály használatával
A szöveg elemzésének megismeréséhez használhatja az ebben a részben megadott DataFrame osztályt használó szabványos folyamatot.
- Megfejteni a bemeneti adatok adatformátumát.
- Határozza meg az adatok kimeneti adatait, például a CSV-fájlt vagy a vesszővel tagolt értékeket.
- Írjon a kódra egy primitív adattípust, például listát vagy diktátumot.
Megjegyzés: A kód üres DataFrame-re írása fárasztó és bonyolult lehet. A pandák lehetővé teszik a DataFrame osztály adatainak létrehozását ezekből az adattípusokból. Így a primitív adattípusban lévő adatok könnyen elemezhetők a kívánt adatformátumba.
- Elemezze az adatokat a pandas DataFrame adatelemző eszközzel, majd nyomtassa ki az eredményt.
I. lehetőség: Szabványos formátum
Itt ismertetjük a szabványos módszert, amellyel bármilyen fájlt formázhatunk bizonyos adatformátummal, például CSV-vel.
- Mentse el a fájlt az adatértékekkel helyileg a számítógépére. Például elnevezheti a fájlt data.txt.
- Importálja a fájlt a pandákban meghatározott névvel, és importálja az adatokat egy másik változóba. Például a nyelv pandáit a megadott kódban a pd névbe importálják.
- Az importálásnak tartalmaznia kell egy teljes kódot, amely tartalmazza a bemeneti fájl nevét, a függvényt és a bemeneti fájl formátumát.
Megjegyzés: Itt a res nevű változó a data.txt fájlban lévő adatok olvasási funkcióját használja a pd-ben importált pandákkal. A beviteli szöveg adatformátuma a CSV formátumban van megadva.
- Hívja meg a megnevezett fájltípust, és elemezze az elemzett szöveget a nyomtatott eredményen. Például a parancssori végrehajtás utáni res parancs segít az elemzett szöveg kinyomtatásában.
Az alábbiakban egy példakód található a fent ismertetett folyamathoz, amely segít megérteni a szöveg elemzését.
import pandas as pd res = pd.read_csv(‘data.txt’) res
Ebben az esetben, ha beírja az adatértékeket a data.txt fájlba, mint pl [1,2,3]elemre kerül, és 1 2 3-ként jelenik meg.
II. lehetőség: String módszer
Ha a kódhoz adott szöveg csak karakterláncokat vagy alfa karaktereket tartalmaz, akkor a karakterláncban lévő speciális karakterek, például vessző, szóköz stb. használhatók a szöveg elválasztására és elemzésére. A folyamat hasonló a szokásos belső karakterlánc-műveletekhez. Az elemzési hiba kijavításának megtudásához kövesse a szöveg ezzel az opcióval történő elemzésének folyamatát, amelyet alább ismertetünk.
- A rendszer kivonja az adatokat a karakterláncból, és feljegyzi a szöveget elválasztó összes speciális karaktert.
Például az alább megadott kódban a my_string karakterlánc speciális karaktereit azonosítja, amelyek a következők: ‘,’ és ‘:’. Ezt a folyamatot óvatosan kell végrehajtani, hogy elkerüljük az x elemző szöveg hibáit.
- A karakterláncban lévő szöveg az értékek és a speciális karakterek helyzete alapján egyedileg felosztásra kerül.
Például a karakterlánc szöveges adatértékekre van felosztva a split paranccsal azonosított speciális karakterek alapján.
- A karakterlánc adatértékei egyedül kerülnek kinyomtatásra elemzett szövegként. Itt a print utasítás a szöveg elemzett adatértékének kinyomtatására szolgál.
A fent ismertetett folyamat mintakódja az alábbiakban található.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
Ebben az esetben az elemzett karakterlánc eredménye az alábbiak szerint jelenik meg.
Names: [‘Tech’, ‘computer’]
A jobb áttekinthetőség és a szöveg elemzésének megismerése érdekében a karakterlánc-szöveg használata közben a for ciklust használjuk, és a kódot az alábbiak szerint módosítjuk.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
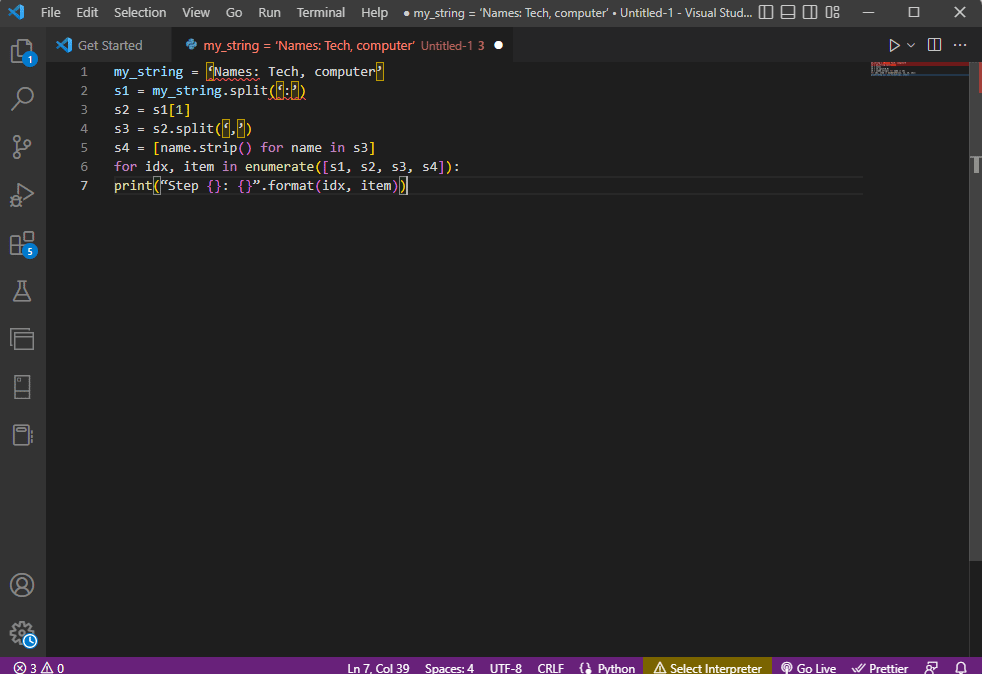
Az egyes lépések elemzett szövegének eredménye az alábbiak szerint jelenik meg. Megjegyzendő, hogy a 0. lépésben a karakterlánc a speciális karakter alapján lesz elválasztva: a szöveges adatértékek pedig a karakter alapján a további lépésekben.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
III. lehetőség: Komplex fájl elemzése
A legtöbb esetben az elemezni kívánt fájladatok különböző adattípusokat és adatértékeket tartalmaznak. Ebben az esetben nehéz lehet a fájl elemzése a korábban ismertetett módszerekkel.
A fájlban található összetett adatok elemzésének funkciója az, hogy az adatértékek táblázatos formátumban jelenjenek meg.
- Az értékek címe vagy metaadatai a fájl tetejére kerülnek kinyomtatásra,
- A változók és a mezők táblázatos formában kerülnek kinyomtatásra a kimenetben, ill
- Az adatértékek összetett kulcsot alkotnak.
Mielőtt belevágna a szövegelemzés megtanulásába ezzel a módszerrel, meg kell tanulnia néhány alapfogalmat. Az adatértékek elemzése reguláris kifejezések vagy Regex alapján történik.
Regex minták
Az elemzési hiba kijavításához meg kell győződnie arról, hogy a kifejezésekben a regex minták megfelelőek. A karakterláncok adatértékeinek elemzésére szolgáló kód az ebben a szakaszban alább felsorolt általános Regex-mintákat tartalmazná.
-
‘d’: megegyezik a karakterlánc tizedes számjegyével,
-
‘s’: megfelel a szóköz karakternek,
-
‘w’: megfelel az alfanumerikus karakternek,
-
‘+’ vagy ‘*’ : mohó egyezést hajt végre a karakterláncok egy vagy több karakterének egyeztetésével,
-
‘a-z’ : megfelel a kisbetűs csoportoknak a szöveges adatértékekben,
-
‘A-Z’ vagy ‘a-z’ : megfelel a karakterlánc nagy- és kisbetűs csoportjának, és
-
‘0-9’ : megfelel a számértékeknek.
Reguláris kifejezések
A Python nyelvben a reguláris kifejezés modulok a pandas csomag fő részét képezik, és a rossz re hibához vezethet az x szövegelemzésben. Ez egy apró nyelv, amely a Pythonba van beágyazva, hogy megtalálja a karakterlánc-mintát a kifejezésben. A reguláris kifejezések vagy a reguláris kifejezések speciális szintaxisú karakterláncok. Lehetővé teszi a felhasználó számára, hogy a karakterláncok értékei alapján más karakterláncok mintáit illessze.
A Regex az adattípus és a karakterláncban lévő kifejezés követelményei alapján jön létre, például „String = (.*)n. A regex minden kifejezésben a minta előtt használatos. A reguláris kifejezésekben használt szimbólumok az alábbiakban találhatók, és segítenek a szöveg elemzésének megismerésében.
-
. : bármilyen karakter lekéréséhez az adatokból,
-
* : nulla vagy több adatot használjon az előző kifejezésből,
-
(.*) : a reguláris kifejezés egy részének zárójelek közé történő csoportosítása,
-
n : Hozzon létre egy új sorkaraktert a sor végén a kódban,
-
d : hozzon létre egy rövid integrál értéket a 0 és 9 közötti tartományban,
-
+ : használjon egy vagy több adatot az előző kifejezésből, és
-
| : hozzon létre egy logikai utasítást; vagy kifejezésekre használják.
RegexObjects
A RegexObject a fordítási függvény visszatérési értéke, és egy MatchObject visszaadására szolgál, ha a kifejezés megegyezik az egyezési értékkel.
1. MatchObject
Mivel a MatchObject logikai értéke mindig True, használhat egy if utasítást az objektum pozitív egyezéseinek azonosítására. Az if utasítás használata esetén az index által hivatkozott csoportot használjuk a kifejezésben szereplő objektum egyezésének kiderítésére.
-
a group() egy vagy több egyezési alcsoportot ad vissza,
-
group(0) a teljes meccset adja vissza,
-
A group(1) az első zárójelben szereplő alcsoportot adja vissza, és
- Ha több csoportra hivatkozunk, python-specifikus kiterjesztést kell használnunk. Ez a kiterjesztés annak a csoportnak a nevének megadására szolgál, amelyben az egyezést meg kell találni. A konkrét kiterjesztést a zárójelben lévő csoport tartalmazza. Például a (?P
regex1) kifejezés a csoport1 nevű adott csoportra hivatkozik, és ellenőrzi az egyezést a reguláris kifejezésben, a regex1. Az elemzési hiba javításának megismeréséhez ellenőriznie kell, hogy a csoport megfelelően van-e rámutatva.
2. A MatchObject módszerei
A szöveg elemzése során fontos tudni, hogy a MatchObject két alapvető módszerrel rendelkezik az alábbiak szerint. Ha a MatchObject megtalálható a megadott kifejezésben, akkor a példányát adja vissza, ellenkező esetben a None-t.
- A match(string) metódus a reguláris kifejezés elején lévő karakterlánc egyezéseinek megkeresésére szolgál, és
- A search(string) metódus a karakterlánc átvizsgálására szolgál, hogy megtalálja az egyezés helyét a reguláris kifejezésben.
Reguláris kifejezés függvények
A reguláris függvények olyan kódsorok, amelyek egy bizonyos funkció végrehajtására szolgálnak a felhasználó által a beszerzett adatértékek halmazából.
Megjegyzés: A függvények írásához nyers karakterláncokat használnak a reguláris kifejezésekhez, hogy elkerüljék a hibákat az x elemző szövegben. Ez úgy történik, hogy a kifejezés minden mintája elé hozzáadja az r alsó indexet.
A kifejezésekben használt gyakori függvények magyarázata az alábbiakban található.
1. re.findall()
Ez a függvény visszaadja a karakterlánc összes mintáját, ha egyezés található, és egy üres listát ad vissza, ha nem található egyezés. Például a string = re.findall(‘[aeiou]’, regex_fájlnév) a magánhangzó előfordulásának megkeresésére szolgál a fájlnévben.
2. re.split()
Ez a funkció a karakterlánc felosztására szolgál, ha egy megadott karakterrel, például szóközzel talál egyezést. Ha nem található egyezés, üres karakterláncot ad vissza.
3. re.sub()
A függvény az egyező szöveget a megadott helyettesítő változó tartalmával helyettesíti. Más függvényekkel ellentétben, ha nem található minta, a rendszer az eredeti karakterláncot adja vissza.
4. re.search()
Az egyik alapvető funkció, amely segít a szövegelemzés megtanulásában, a keresési funkció. Segít a minta keresésében a karakterláncban és a megfelelő objektum visszaadásában. Ha a keresés sikertelen az egyezés azonosításában, nem ad vissza értéket.
5. újra.fordítás(minta)
Ezt a funkciót arra használják, hogy reguláris kifejezési mintákat fordítsanak RegexObject-be, amiről korábban volt szó.
Egyéb követelmények
A felsorolt követelmények a haladó programozók által az adatelemzés során használt kiegészítő szolgáltatás.
- A reguláris kifejezés megjelenítéséhez a regexpert és a
- A reguláris kifejezés teszteléséhez a regex101-et használjuk.
A szöveg elemzésének folyamata
Az alábbiakban ismertetjük a szöveg elemzésének módszerét ebben az összetett beállításban.
- A legelső lépés a beviteli formátum megértése a fájl tartalmának elolvasásával. Például a with open és read() függvények a sample nevű fájl tartalmának megnyitására és olvasására szolgálnak. A mintafájl a file.txt fájl tartalmát tartalmazza; az elemzési hiba javításának megtanulásához a fájlt teljesen el kell olvasni.
- A fájl tartalmát a rendszer kinyomtatja az adatok manuális elemzéséhez, hogy megtudja az értékek metaadatait. Itt a print() függvény a mintafájl tartalmának kinyomtatására szolgál.
- A szöveg elemzéséhez szükséges adatcsomagok importálódnak a kódba, és az osztály nevet kap a további kódoláshoz. Itt a rendszer importálja a reguláris kifejezéseket és a pandákat.
- A kódhoz szükséges reguláris kifejezések a fájlban a regex minta és a reguláris kifejezés szerepeltetésével vannak meghatározva. Ez lehetővé teszi, hogy a szöveges objektum vagy korpusz átvegye a kódot az adatok elemzéséhez.
- A szöveg elemzésének megismeréséhez tekintse meg az itt megadott példakódot. A compile() függvény arra szolgál, hogy lefordítsa a karakterláncot a fájlnév fájlnév1 csoportból. A regexben található egyezések ellenőrzésére szolgáló függvényt az ief_parse_line(line) parancs használja,
- A kód sorelemzője a def_parse_file(filepath) segítségével íródik, amelyben a definiált függvény minden reguláris kifejezést ellenőrzi a megadott függvényben. Itt a regex search() metódus megkeresi az rx kulcsot a fájlnévben, és visszaadja az első egyező regex kulcsát és egyezését. A lépéssel kapcsolatos bármilyen probléma hibához vezethet az x szövegelemzésben.
- A következő lépés egy fájlelemző írása a fájlelemző függvény használatával, ami a def_parse_file(filepath). Egy üres lista jön létre a kód adatainak összegyűjtésére, mint adat = []az egyezést minden sorban ellenőrzi a match = _parse_line(line), és az adattípus alapján a pontos értékadatokat adja vissza.
- A tábla számának és értékének kinyeréséhez a parancssor.strip().split(‘,’) parancsot kell használni. A sor{} paranccsal szótárt hozhatunk létre az adatsorral. A data.append(row) parancs az adatok megértésére és táblázatos formátumba történő elemzésére szolgál.
A data = pd.DataFrame(data) parancs egy pandas DataFrame létrehozására szolgál a diktált értékekből. Alternatív megoldásként használhatja a következő parancsokat a megfelelő célra, az alábbiak szerint.
-
data.set_index([‘string’, ‘integer’]inplace=True) a táblázat indexének beállításához.
-
data = data.groupby(level=data.index.names).first() a nans konszolidálásához és eltávolításához.
-
data = data.apply(pd.to_numeric, errors=’ignore’) a pontszám lebegtetésről egész értékre való frissítéséhez.
Az utolsó lépés a szöveg elemzésének megismeréséhez az, hogy teszteljük az elemzőt az if utasítással úgy, hogy hozzárendeljük az értékeket egy változó adathoz, és kinyomtatjuk a print(data) paranccsal.
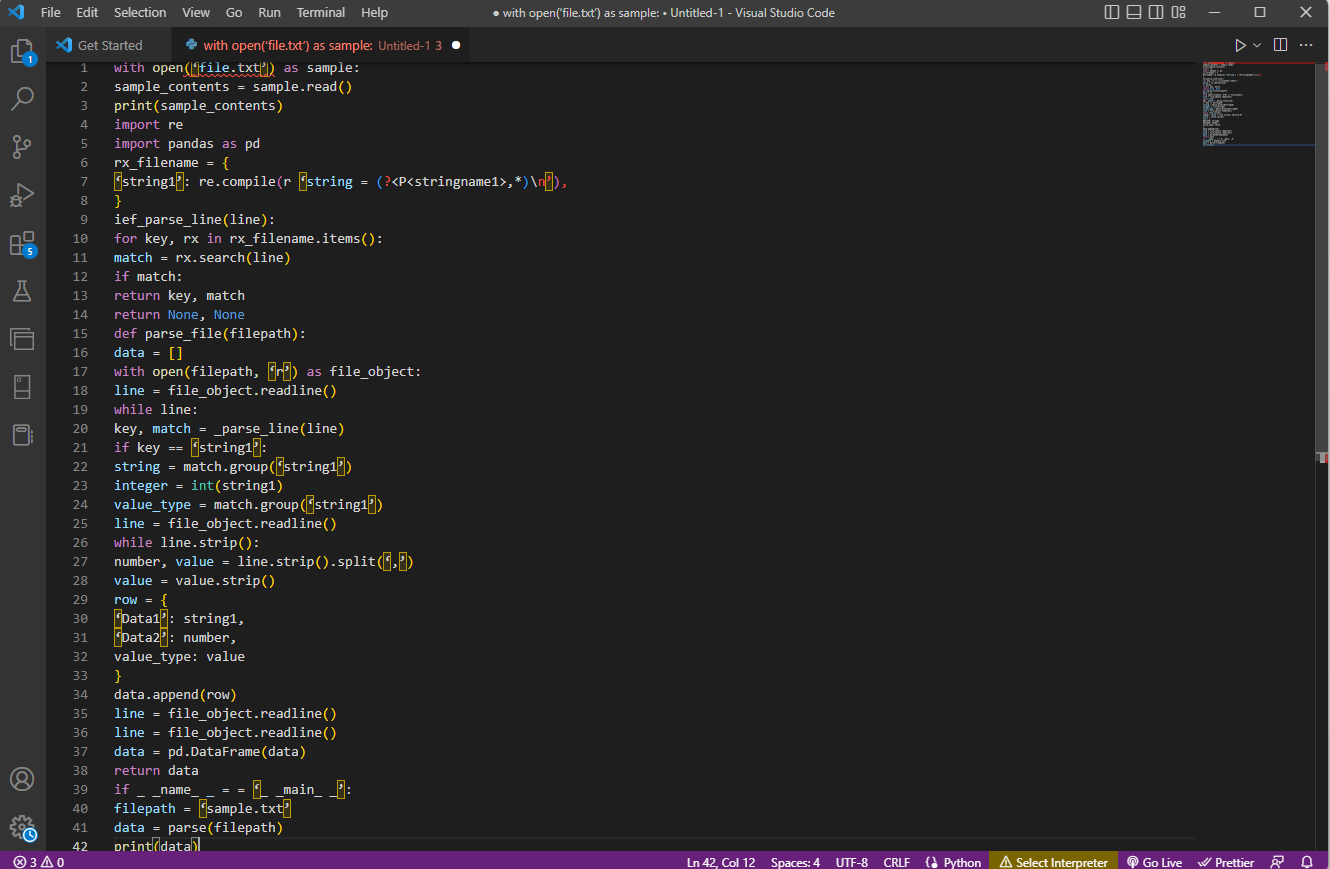
A fenti magyarázat példakódja itt található.
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
2. módszer: Word Tokenization segítségével
Azt a folyamatot, amelynek során egy szöveget vagy korpuszt tokenekké vagy kisebb darabokká alakítanak át bizonyos szabályok alapján, tokenizálásnak nevezik. Az elemzési hiba kijavításának megismeréséhez fontos elemezni a kódban található szó tokenizációs parancsokat. A regexhez hasonlóan ezzel a módszerrel is lehet saját szabályokat létrehozni, és segítséget nyújt a szöveg-előkészítési feladatokban, például a beszédrészek leképezésében. Ezzel a módszerrel olyan tevékenységeket is végrehajtanak, mint a gyakori szavak keresése és egyeztetése, a szöveg tisztítása és az adatok előkészítése a fejlett szövegelemzési technikákhoz, például a hangulatelemzéshez. Ha a tokenizálás nem megfelelő, hiba léphet fel az x elemző szövegben.
Ntlk könyvtár
A folyamat az nltk nevű népszerű nyelvi eszköztárat veszi igénybe, amely számos NLP-feladat végrehajtásához gazdag funkciókészlettel rendelkezik. Ezeket a Pip vagy Pip Telepítési csomagokon keresztül lehet letölteni. A szöveg elemzésének megismeréséhez használhatja az Anaconda disztribúció alapcsomagját, amely alapértelmezés szerint tartalmazza a könyvtárat.
A tokenizálás formái
Ennek a módszernek a gyakori formái a szó tokenizálás és a mondat tokenizálás. A szószintű tokennek köszönhetően az előbbi csak egyszer, míg az utóbbi mondatszinten írja ki a szót.
A szöveg elemzésének folyamata
- A program importálja az ntlk eszköztárat, és importálja a tokenizációs űrlapokat a könyvtárból.
- A rendszer egy karakterláncot ad, és a tokenizálás végrehajtásához szükséges parancsokat.
- Amíg a karakterlánc ki van nyomtatva, a kimenet a számítógép a szó.
- A szó tokenizálása vagy a word_tokenize() esetén a mondat minden szava külön-külön kerül kinyomtatásra a ”-en belül, és vesszővel választja el őket. A parancs kimenete a következő lenne: „számítógép”, „is”, „a”, „szó”, „.”
- Mondattokenizálás vagy send_tokenize() esetén az egyes mondatok a ”-en belülre kerülnek, és a szóismétlés megengedett. A parancs kimenete a „számítógép a szó” lenne.
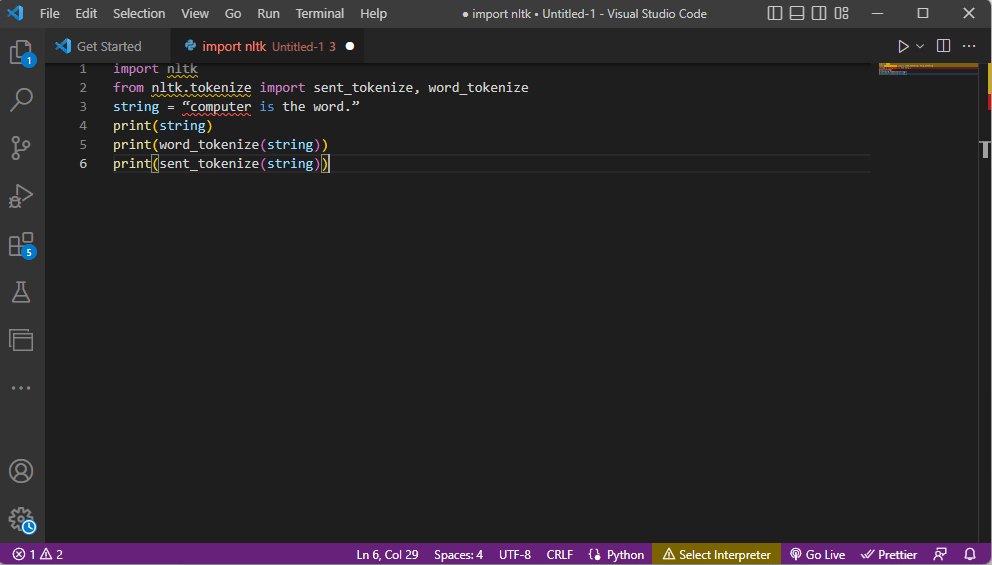
A fenti tokenizálás lépéseit magyarázó kód itt található.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
3. módszer: DocParser osztályon keresztül
A DataFrame osztályhoz hasonlóan a Class DocParser is használható a kód szövegének elemzésére. Az osztály lehetővé teszi a parse függvény meghívását a fájl elérési útjával.
A szöveg elemzésének folyamata
Ha tudni szeretné, hogyan kell szöveget elemezni a DocParser osztály használatával, kövesse az alábbi utasításokat.
- A get_format(filename) függvény a fájl kiterjesztésének kibontására, a függvény beállított változójára való visszaállítására és a következő függvénynek való átadására szolgál. Például a p1 = get_format(fájlnév) kibontja a fájlnév kiterjesztését, beállítja a p1 változóra, és átadja a következő függvénynek.
- Az if-elif-else utasítások és függvények felhasználásával egy logikai struktúra más függvényekkel készül.
- Ha a fájl kiterjesztése érvényes és a szerkezet logikus, akkor a get_parser függvény segítségével elemzi a fájl elérési útjában lévő adatokat, és visszaadja a karakterlánc objektumot a felhasználónak.
Megjegyzés: Az elemzési hiba kijavításához ezt a funkciót helyesen kell végrehajtani.
- Az adatértékek elemzése a fájl kiterjesztésével történik. Az osztály konkrét implementációja, amelyek a parse_txt vagy parse_docx, az adott fájltípus részeiből string objektumok generálására szolgálnak.
- Az elemzés más olvasható kiterjesztésű fájloknál is elvégezhető, mint például a parse_pdf, parse_html és parse_pptx.
- Az adatértékek és a felület importálási utasításokkal importálhatók alkalmazásokba, és példányosíthatók egy DocParser objektum. Ezt megteheti a Python nyelvű fájlok, például a parse_file.py elemzésével. Ezt a műveletet óvatosan kell végrehajtani, hogy elkerüljük az x elemző szöveg hibáit.
4. módszer: Szövegelemző eszközzel
A Szövegelemzés eszközzel meghatározott adatok kinyerhetők a változókból, és leképezhetők más változókra. Ez független a feladatban használt egyéb eszközöktől, és a BPA Platform eszközt használják a változók fogyasztására és kiadására. Az itt található link segítségével elérheti a Szövegelemzési eszköz online és használja a korábban adott válaszokat a szöveg elemzéséhez.
5. módszer: TextFieldParser (Visual Basic) segítségével
A TextFieldParser objektumokat használt a nagyon nagy, strukturált és elhatárolt fájlok elemzésére és feldolgozására. Ebben a módszerben a szöveg szélessége és oszlopa, például naplófájlok vagy örökölt adatbázis-információk használhatók. Az elemzési módszer hasonló a kód szövegfájlon történő iterálásához, és főként a karakterlánc-manipulációs módszerekhez hasonló szövegmezők kinyerésére szolgál. Ez az elválasztott karakterláncok és különböző szélességű mezők tokenizálására szolgál a meghatározott határolóval, például vesszővel vagy tabulátorral.
Szöveg elemzésére szolgáló függvények
A következő függvények használhatók a szöveg elemzésére ebben a módszerben.
- A határoló meghatározásához a SetDelimiters használható. Például a testReader.SetDelimiters (vbTab) paranccsal a tabulátorterületet lehet határolóként beállítani.
- Ha a mező szélességét pozitív egész értékre szeretné beállítani a szövegfájlok rögzített mezőszélességére, használja a testReader.SetFieldWidths (egész szám) parancsot.
- A szöveg mezőtípusának teszteléséhez használja a következő parancsot: testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Módszerek a MatchObject megkeresésére
Két alapvető módszer létezik a MatchObject megtalálására a kódban vagy az elemzett szövegben.
- Az első módszer a formátum definiálása és a fájlban való végigjátszás a ReadFields módszerrel. Ez a módszer segít a kód minden sorának feldolgozásában.
- A PeekChars módszerrel minden egyes mezőt külön-külön ellenőriznek, mielőtt elolvasnák azokat, több formátumot határozhat meg, és reagálhat.
Mindkét esetben, ha egy mező nem egyezik a megadott formátummal az elemzés végrehajtása vagy a szöveg elemzési módjának keresése közben, a rendszer egy MalformedLineException kivételt ad vissza.
Profi tipp: Szöveg elemzése MS Excel segítségével
A szöveg elemzésének végső és egyszerű módszereként használhatja a MS Excel alkalmazás elemzőként tabulátorral tagolt és vesszővel tagolt fájlok létrehozásához. Ez segít az elemzési eredmény összehasonlításában, és segít megtalálni az elemzési hiba kijavítását.
1. Válassza ki az adatértékeket a forrásfájlban, és nyomja le együtt a Ctrl + C billentyűket a fájl másolásához.
2. Nyissa meg az Excel alkalmazást a Windows keresősávjával.
3. Kattintson az A1 cellára, és egyszerre nyomja meg a Ctrl + V billentyűket a másolt szöveg beillesztéséhez.
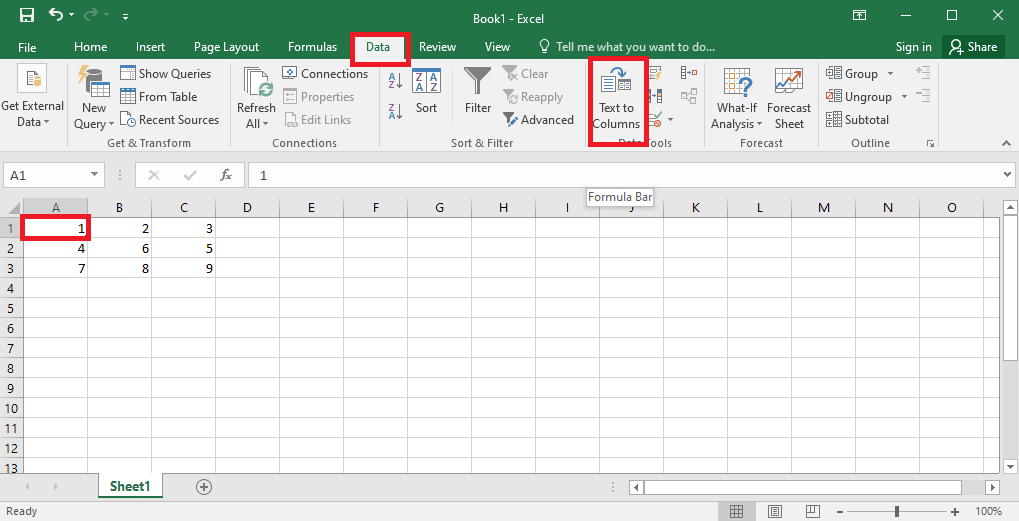
4. Válassza ki az A1 cellát, lépjen az Adatok fülre, és kattintson a Szöveg oszlopokba opcióra az Adateszközök részben.
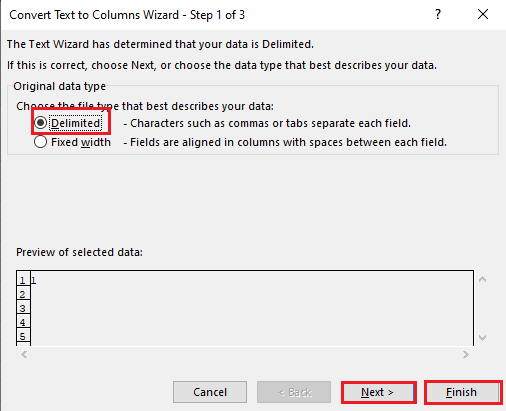
5A. Válassza a Határozott lehetőséget, ha vesszőt vagy tabulátort használ elválasztóként, majd kattintson a Tovább és a Befejezés gombra.
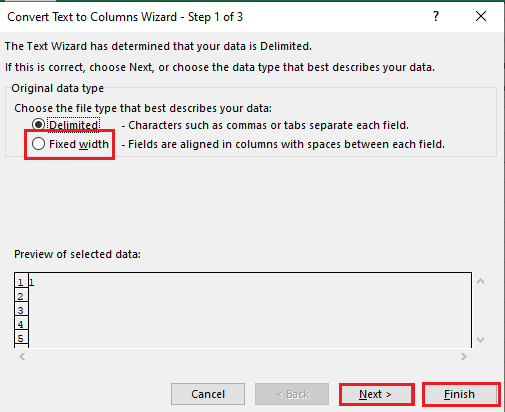
5B. Válassza a Rögzített szélesség opciót, rendeljen értéket az elválasztóhoz, majd kattintson a Tovább és a Befejezés gombra.
Az elemzési hiba javítása
Az x szövegelemzési hiba előfordulhat Android-eszközökön: Elemzési hiba: Hiba történt a csomag elemzése során. Ez általában akkor fordul elő, ha az alkalmazást nem sikerül telepíteni a Google Play Áruházból, vagy ha harmadik féltől származó alkalmazást futtat.
Az x hibaszöveg akkor fordulhat elő, ha a karaktervektorok listája hurkolt, és más függvények lineáris modellt alkotnak az adatértékek kiszámításához. A hibaüzenet: Error in parse(text = x, keep.source = FALSE):
Elolvashatja az elemzési hiba Android rendszeren kijavításáról szóló cikket, hogy megismerje a hiba okait és módszereit.
Az útmutatóban szereplő megoldásokon kívül a következő javításokat is kipróbálhatja.
- Az .apk fájl újbóli letöltése vagy a fájl nevének visszaállítása.
- Az Androidmanifest.xml fájl módosításainak visszaállítása, ha rendelkezik szakértői szintű programozási ismeretekkel.
***
A cikk segít a szöveg elemzésének és az elemzési hiba javításának megtanulásában. Tudassa velünk, hogy melyik módszer segített kijavítani a hibát az x elemző szövegben, és melyik elemzési módszert részesítjük előnyben. Kérjük, ossza meg javaslatait és kérdéseit az alábbi megjegyzések részben.