
Ha még nem ismeri a nagy adatelemzést, akkor az apache eszközök sokasága lehet a radaron; azonban a különféle eszközök puszta zavaróvá és időnként elsöprővé válhatnak.
Ez a bejegyzés feloldja ezt a zavart, és elmagyarázza, mi az Apache Hive és az Impala, és miben különböznek egymástól!
Tartalomjegyzék
Apache Hive
Az Apache Hive egy SQL adathozzáférési felület az Apache Hadoop platformhoz. A Hive lehetővé teszi az adatok lekérdezését, összesítését és elemzését SQL szintaxis használatával.
A HDFS fájlrendszerben lévő adatokhoz olvasási hozzáférési sémát használnak, amely lehetővé teszi, hogy az adatokat úgy kezelje, mint egy közönséges táblában vagy relációs DBMS-ben. A MapReduce-feladatokhoz a HiveQL-lekérdezéseket Java kódra fordítják.
A Hive-lekérdezések a HiveQL lekérdezési nyelven íródnak, amely az SQL nyelven alapul, de nem támogatja teljes mértékben az SQL-92 szabványt.
Ez a nyelv azonban lehetővé teszi a programozók számára, hogy lekérdezéseiket akkor használják, amikor a HiveQL szolgáltatásainak használata kényelmetlen vagy nem hatékony. A HiveQL bővíthető felhasználó által definiált skaláris függvényekkel (UDF), aggregációkkal (UDAF kódok) és táblázatfüggvényekkel (UDTF).
Hogyan működik az Apache Hive
Az Apache Hive lefordítja a HiveQL nyelven (az SQL-hez közeli) írt programokat egy vagy több MapReduce, Apache Tez vagy Apache Spark feladattá. Ez három végrehajtó motor, amelyek elindíthatók a Hadoopon. Ezután az Apache Hive egy tömbbe rendezi az adatokat a Hadoop Distributed File System (HDFS) fájl számára, hogy a feladatokat egy fürtön futtassa válasz létrehozása érdekében.
Az Apache Hive táblái hasonlóak a relációs adatbázisokhoz, és az adategységek a legjelentősebb egységtől a legszemcsésebbig vannak rendezve. Az adatbázisok partíciókból álló tömbök, amelyek ismét „vödrökre” bonthatók.
Az adatok a HiveQL-en keresztül érhetők el. Az egyes adatbázisokon belül az adatok számozva vannak, és minden tábla egy HDFS-könyvtárnak felel meg.
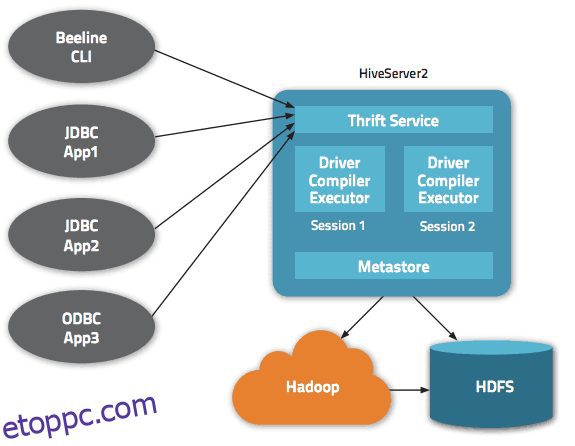
Az Apache Hive architektúrán belül több interfész is elérhető, például webes felület, CLI vagy külső kliensek.
Valójában az „Apache Hive Thrift” szerver lehetővé teszi a távoli ügyfelek számára, hogy parancsokat és kéréseket küldjenek be az Apache Hive-nak különféle programozási nyelvek használatával. Az Apache Hive központi könyvtára egy „metastore”, amely minden információt tartalmaz.
A Hive-t működő motort „vezetőnek” nevezik. Összekapcsol egy fordítót és egy optimalizálót az optimális végrehajtási terv meghatározásához.
Végül a biztonságot a Hadoop biztosítja. Ezért a Kerberosra támaszkodik a kliens és a szerver közötti kölcsönös hitelesítéshez. Az Apache Hive-ban újonnan létrehozott fájlok engedélyét a HDFS határozza meg, amely lehetővé teszi a felhasználók, csoportok vagy más módon történő engedélyezést.
A Hive jellemzői
- Támogatja a Hadoop és a Spark számítástechnikai motorját
- HDFS-t használ, és adattárházként működik.
- MapReduce-t használ és támogatja az ETL-t
- A HDFS-nek köszönhetően a Hadoophoz hasonló hibatűréssel rendelkezik
Apache Hive: Előnyök
Az Apache Hive ideális megoldás lekérdezésekhez és adatelemzésekhez. Lehetővé teszi a minőségi betekintést, versenyelőnyt biztosítva és elősegítve a piaci keresletre való reagálást.
Az Apache Hive fő előnyei között megemlíthetjük az „SQL-barát” nyelvhez kapcsolódó könnyű használhatóságot. Ezenkívül felgyorsítja az adatok kezdeti beillesztését, mivel az adatokat nem kell leolvasni vagy számozni a belső adatbázis formátumában lévő lemezről.
Annak tudatában, hogy az adatokat HDFS-ben tárolják, nagy adatkészletek, akár több száz petabájtnyi adat tárolása lehetséges az Apache Hive-on. Ez a megoldás sokkal skálázhatóbb, mint egy hagyományos adatbázis. Tudva, hogy felhőszolgáltatásról van szó, az Apache Hive lehetővé teszi a felhasználók számára a virtuális szerverek gyors elindítását a munkaterhelés (azaz a feladatok) ingadozása alapján.
A biztonság egy olyan szempont is, ahol a Hive jobban teljesít, mivel probléma esetén képes megismételni a helyreállítás szempontjából kritikus munkaterheléseket. Végül pedig a munkaképesség páratlan, hiszen óránként akár 100 000 kérést is képes teljesíteni.
Apache Impala
Az Apache Impala egy masszívan párhuzamos SQL lekérdező motor SQL lekérdezések interaktív végrehajtására az Apache Hadoopban tárolt adatokon, C++ nyelven írták és Apache 2.0 licenc alatt terjesztik.
Az Impala-t MPP (Massively Parallel Processing) motornak, elosztott DBMS-nek, sőt SQL-on-Hadoop verem-adatbázisnak is nevezik.

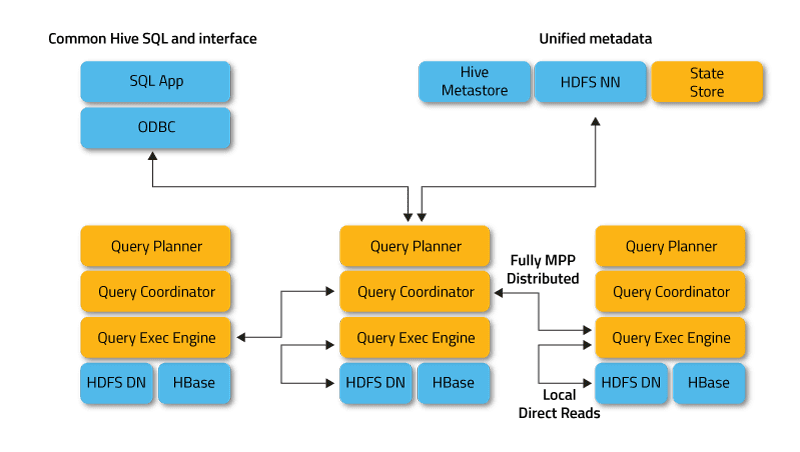
Az Impala elosztott módban működik, ahol a folyamatpéldányok különböző fürtcsomópontokon futnak, fogadva, ütemezve és koordinálva az ügyfelek kéréseit. Ebben az esetben az SQL lekérdezés töredékeinek párhuzamos végrehajtása lehetséges.
Az ügyfelek olyan felhasználók és alkalmazások, amelyek SQL-lekérdezéseket küldenek az Apache Hadoopban (HBase és HDFS) vagy az Amazon S3-ban tárolt adatokra. Az Impalával való interakció a HUE (Hadoop User Experience) webes felületen, az ODBC-n, a JDBC-n és az Impala Shell parancssori rendszerhéjon keresztül történik.
Az Impala infrastrukturálisan egy másik népszerű SQL-on-Hadoop eszköztől, az Apache Hive-tól függ, amely metaadattárát használja. Különösen a Hive Metastore tájékoztatja az Impalát az adatbázisok elérhetőségéről és szerkezetéről.
Amikor sémaobjektumokat hoz létre, módosít és töröl, vagy adatokat tölt be táblákba SQL-utasításokon keresztül, a megfelelő metaadat-módosítások automatikusan továbbításra kerülnek az összes Impala csomópontra egy speciális címtárszolgáltatás segítségével.
Az Impala legfontosabb összetevői a következő végrehajtható fájlok:
- Az Impalad vagy Impala démon egy olyan rendszerszolgáltatás, amely ütemezi és végrehajtja a HDFS, HBase és Amazon S3 adatok lekérdezését. Egy impalad folyamat fut minden fürtcsomóponton.
- A Statestore egy elnevezési szolgáltatás, amely nyomon követi a fürtben lévő összes impalad-példány helyét és állapotát. Ennek a rendszerszolgáltatásnak egy példánya fut minden csomóponton és a fő kiszolgálón (Name Node).
- A katalógus egy metaadat-koordinációs szolgáltatás, amely az Impala DDL- és DML-utasítások változásait továbbítja az összes érintett Impala-csomópontra, így az új táblák vagy az újonnan betöltött adatok azonnal láthatóak a fürt bármely csomópontja számára. Javasoljuk, hogy a katalógus egy példánya ugyanazon a fürt gazdagépen fusson, mint a Statestored démon.
Hogyan működik az Apache Impala
Az Impala az Apache Hive-hez hasonlóan egy hasonló deklaratív lekérdezési nyelvet, a Hive Query Language-t (HiveQL) használ, amely az SQL92 részhalmaza az SQL helyett.
A kérés tényleges végrehajtása Impalában a következő:
Az ügyfélalkalmazás SQL-lekérdezést küld bármely impaladhoz szabványos ODBC vagy JDBC illesztőprogram-interfészeken keresztül történő csatlakozással. A csatlakoztatott impalad lesz az aktuális kérés koordinátora.
A rendszer elemzi az SQL-lekérdezést, hogy meghatározza a fürt impalad-példányainak feladatait; majd az optimális lekérdezés-végrehajtási terv készül.
Az Impalad közvetlenül éri el a HDFS-t és a HBase-t a rendszerszolgáltatások helyi példányai segítségével adatszolgáltatás céljából. Az Apache Hive-val ellentétben az ilyen közvetlen interakció jelentősen megtakarítja a lekérdezés végrehajtási idejét, mivel a köztes eredmények nem kerülnek mentésre.
Válaszul minden démon visszaküldi az adatokat a koordináló impaladnak, és az eredményeket visszaküldi az ügyfélnek.
Az Impala jellemzői
- Támogatja a valós idejű memórián belüli feldolgozást
- SQL-barát
- Támogatja az olyan tárolórendszereket, mint a HDFS, az Apache HBase és az Amazon S3
- Támogatja az olyan BI-eszközökkel való integrációt, mint a Pentaho és a Tableau
- HiveQL szintaxist használ
Apache Impala: Előnyök
Az Impala elkerüli az esetleges indítási költségeket, mivel az összes rendszerdémon folyamat közvetlenül a rendszerindításkor indul el. Jelentősen megtakarítja a lekérdezés végrehajtási idejét. Az Impala sebességének további növekedése az, hogy ez a Hadoop SQL-eszköz, ellentétben a Hive-vel, nem tárol köztes eredményeket, és közvetlenül éri el a HDFS-t vagy a HBase-t.
Ezenkívül az Impala a programkódot futás közben állítja elő, nem pedig fordításkor, ahogy a Hive teszi. Az Impala nagy sebességű teljesítményének mellékhatása azonban a megbízhatóság csökkenése.
Különösen, ha az adatcsomópont leáll egy SQL-lekérdezés végrehajtása során, az Impala példány újraindul, és a Hive továbbra is kapcsolatot tart az adatforrással, biztosítva a hibatűrést.
Az Impala további előnyei közé tartozik a Kerberos biztonságos hálózati hitelesítési protokoll beépített támogatása, a prioritások meghatározása, a kérések sorának kezelése, valamint a népszerű Big Data formátumok, például az LZO, Avro, RCFile, Parquet és Sequence támogatása.
Hive vs Impala: Hasonlóságok
A Hive és az Impala az Apache Software Foundation licence alatt szabadon terjeszthető, és a Hadoop-fürtben tárolt adatokkal való munkavégzésre szolgáló SQL-eszközökre hivatkozik. Emellett a HDFS elosztott fájlrendszert is használják.
Az Impala és a Hive különböző feladatokat valósít meg, közösen az Apache Hadoop-fürtben tárolt nagy adatok SQL-feldolgozására összpontosítva. Az Impala SQL-szerű felületet biztosít, amely lehetővé teszi Hive-táblázatok olvasását és írását, így lehetővé teszi az egyszerű adatcserét.
Ugyanakkor az Impala meglehetősen gyors és hatékony SQL-műveleteket tesz lehetővé a Hadoopon, lehetővé téve ennek a DBMS-nek a használatát a Big Data elemzési kutatási projektekben. Amikor csak lehetséges, az Impala egy meglévő Apache Hive infrastruktúrával dolgozik, amelyet már használtak a hosszan futó SQL kötegelt lekérdezések végrehajtására.
Ezenkívül az Impala a tábladefinícióit egy metastore-ban, egy hagyományos MySQL vagy PostgreSQL adatbázisban tárolja, azaz ugyanott, ahol a Hive hasonló adatokat tárol. Lehetővé teszi, hogy az Impala hozzáférjen a Hive-táblákhoz, amennyiben minden oszlop az Impala által támogatott adattípusokat, fájlformátumokat és tömörítési kodekeket használja.
Hive vs Impala: Különbségek

Programozási nyelv
A Hive Java nyelven, míg az Impala C++ nyelven íródott. Az Impala azonban néhány Java-alapú Hive UDF-et is használ.
Használati esetek
Az adatmérnökök a Hive-ot használják az ETL-folyamatokban (kivonás, átalakítás, betöltés), például nagy adathalmazokon, például utazási aggregátorokban és repülőtéri információs rendszerekben végzett, hosszan tartó kötegelt feladatokhoz. Az Impala viszont főként elemzőknek és adattudósoknak készült, és főként olyan feladatokra használják, mint az üzleti intelligencia.
Teljesítmény
Az Impala valós időben hajtja végre az SQL lekérdezéseket, míg a Hive-re alacsony adatfeldolgozási sebesség jellemző. Egyszerű SQL lekérdezésekkel az Impala 6-69-szer gyorsabban fut, mint a Hive. A Hive azonban jobban kezeli az összetett lekérdezéseket.
Késés/áteresztőképesség
A Hive áteresztőképessége lényegesen nagyobb, mint az Impaláé. Az LLAP (Live Long and Process) funkció, amely lehetővé teszi a lekérdezések gyorsítótárazását a memóriában, jó alacsony szintű teljesítményt biztosít a Hive számára.
Az LLAP hosszú távú rendszerszolgáltatásokat (démonokat) tartalmaz, amelyek lehetővé teszik a HDFS-adatcsomópontokkal való közvetlen interakciót, és leváltják a szorosan integrált DAG lekérdezési struktúrát (Directed acyclic graph) – a Big Data számítástechnikában aktívan használt gráfmodellt.
Hibatűrés
A Hive egy hibatűrő rendszer, amely megőrzi az összes köztes eredményt. Ez szintén pozitívan befolyásolja a méretezhetőséget, de az adatfeldolgozási sebesség csökkenéséhez vezet. Az Impala viszont nem nevezhető hibatűrő platformnak, mert inkább memória kötött.
Kód konvertálása
A Hive lekérdezési kifejezéseket állít elő fordítási időben, míg az Impala futás közben. A Hive-t „hidegindítási” probléma jellemzi az alkalmazás első indításakor; a lekérdezések lassan konvertálódnak, mivel kapcsolatot kell létesíteni az adatforrással.
Az Impalának nincs ilyen indítási költsége. Az SQL lekérdezések feldolgozásához szükséges rendszerszolgáltatások (démonok) rendszerindításkor elindulnak, ami felgyorsítja a munkát.
Tárolási támogatás
Az Impala támogatja az LZO, Avro és Parquet formátumokat, míg a Hive egyszerű szöveggel és ORC-vel működik. Mindkettő támogatja azonban az RCFIle és a Sequence formátumot.
Apache HiveApache ImpalaLanguage JavaC++ Használati esetekAdatmérnöki Elemzés és elemzésTeljesítményMagas egyszerű lekérdezésekhez Viszonylag alacsony késleltetés Több késleltetés a gyorsítótárazás miatt Kevesebb látens hibatűrésToleránsabb a MapReduceLess miatt toleráns, ACLain konverziótűrés az MPC-konverzió miatt, ACLain támogatás a hidegindítás miattSORt
Végső szavak
Hive és Impala nem versengenek egymással, hanem hatékonyan kiegészítik egymást. Annak ellenére, hogy jelentős különbségek vannak a kettő között, nagyon sok a közös is, és az egyik a másikkal szembeni választása az adatoktól és a projekt konkrét követelményeitől függ.
Fedezheti a Hadoop és a Spark közötti közvetlen összehasonlításokat is.
.