
Egy automatizált szoftverrendszer felépítése azt jelentette, hogy több szervert kellett felállítani dedikált CPU-konfigurációval, memóriával, tárolással és egyéb erőforrásokkal sok éven át. Ezt követően egy rendszergazdákból álló csapatot hoztak létre e rendszerek kezelésére. Ezután a fejlesztőcsapat átvette az infrastruktúrát, és elkezdték létrehozni a szervereket összekötő folyamatokat.
Ez a folyamat bonyolult lehet, mert sok különböző csoportot foglal magában, amelyek együtt dolgoznak egy közös cél érdekében. Ezek az összeférhetetlenségek aztán problémát jelenthetnek.
Ez is meglehetősen költséges lehet. Ehhez adminisztrátoroknak kell szerepelniük a bérjegyzékében. A folyamatosan működő szerverek annak ellenére fogyasztják az erőforrásokat, hogy nem használják őket.
A legjobb teljesítmény idővel fenntartásához szükség van egy automatikus skálázási megoldásra, amely automatikusan skálázza a kiszolgáló erőforrásait.
A felhőplatformnak van egy előnye: lehetővé teszi a végpontok közötti architektúra létrehozását anélkül, hogy kiszolgálófürt-beállításra lenne szükség. Adminisztrációs szempontból nincs mit fenntartani.
Ez egy költséghatékony lehetőség az induló vállalkozások és a projektek minimális életképes termék (MVP) szakaszában. Jó kiindulópont, ha nehéz megjósolni a jövőbeli termelési terhelést és a felhasználói aktivitást. Ez az a hely, ahol kihívást jelenthet a fürtkiszolgálók konfigurációjának meghatározása.
A szerver nélküli felhőszolgáltatásokon keresztüli folyamatok automatizálása teszi kiemelkedővé a szerver nélküli architektúrát. Összekapcsolja a szolgáltatásokat, és a hagyományos fürtkiszolgálókhoz hasonló eredményeket produkál.
Ez egy példa egy ilyen architektúra csak natív AWS-szolgáltatások felhasználásával történő felépítésére.
Tartalomjegyzék
A szolgáltatások kiszolgáló nélküli folyamatának felvétele
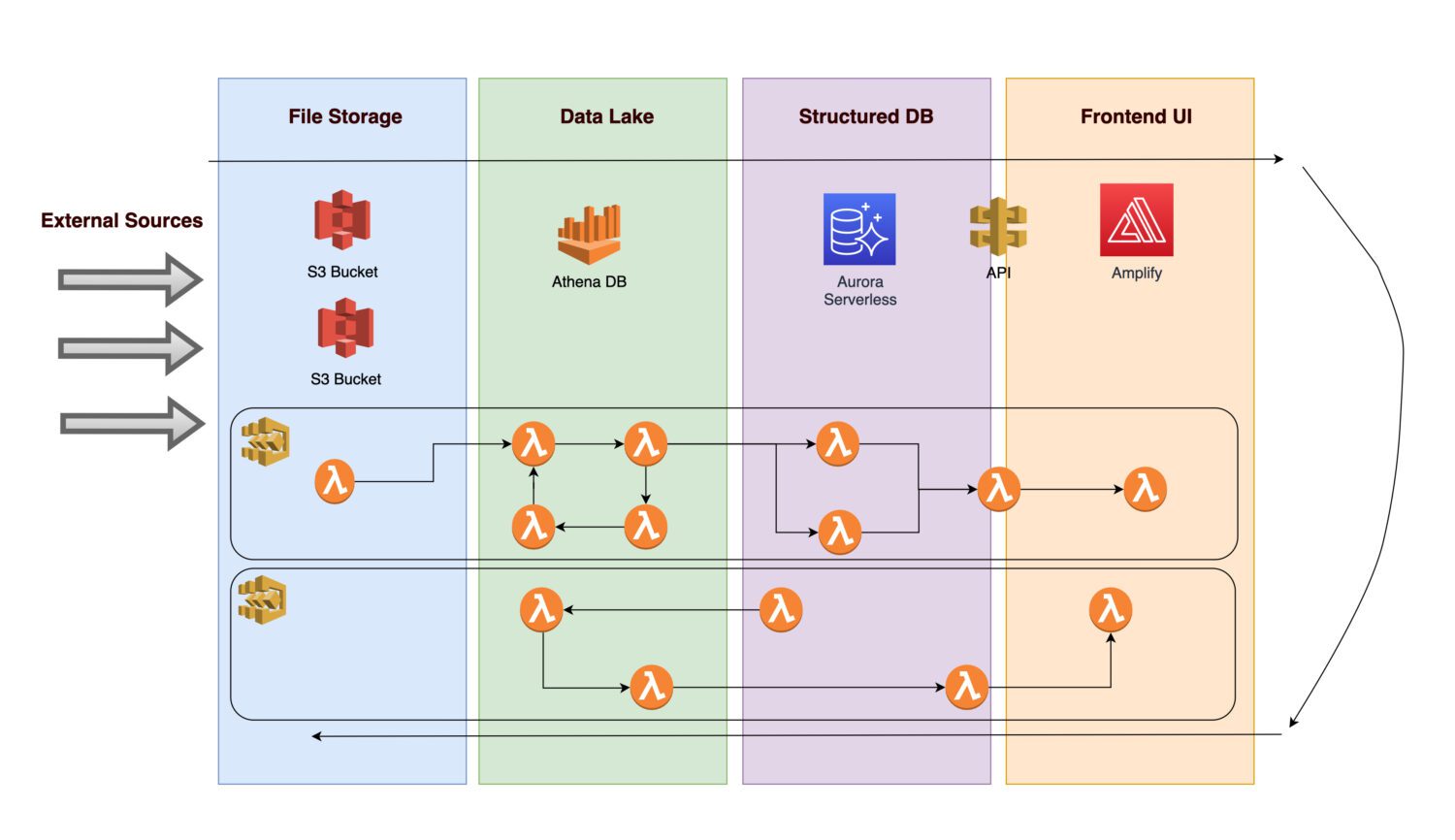
Képzelje el, hogy szeretne létrehozni egy platformot különböző adatok és képek (vagy fényképek) összegyűjtésére bizonyos konkrét eszközök infrastruktúrájáról (ez lehet bármilyen gyártási vagy közüzemi eszköz).
- A jövőbeli elemzések lehetővé tétele érdekében először szükséges a bejövő adatok feldolgozása.
- Az üzleti szabályok alkalmazása után egy háttéreljárás normalizált információként menti a számított kimeneteket egy relációs adatbázisban.
- A normalizált tiszta adatokat megjelenítő alkalmazásfelület lehetővé teszi a felhasználók számára az eredmények megtekintését.
Vizsgáljuk meg, mely összetevőket tartalmazhat az architektúra.
AWS S3 kanalak
 Forrás: aws.amazon.com
Forrás: aws.amazon.com
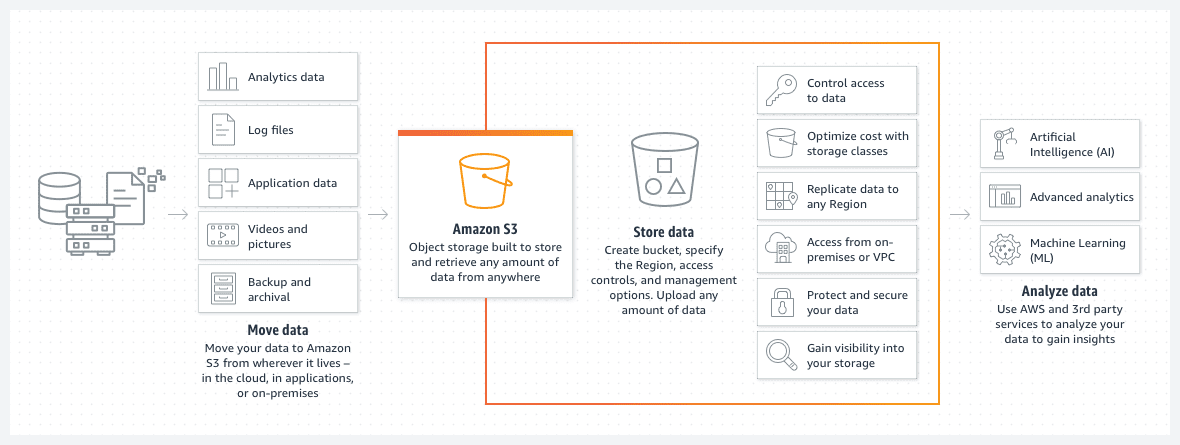
Az Amazon S3 tárolók nagyszerű lehetőséget kínálnak a fájlok vagy képek AWS felhőben való tárolására. Az S3 kanál tároló ára feltűnően alacsony. Sőt, az S3 kanál életciklusra vonatkozó irányelvének bevezetése tovább csökkenti ezt az árat.
Az ilyen házirend automatikusan áthelyezi a régebbi fájlokat az S3 tárolók különböző osztályaiba, mint például az archívum vagy a mélyarchívum hozzáférés. Az osztályok ekkor a hozzáférési idő sebességében is különböznek, de a régi adatoknál ez kevésbé lesz gond. Elsősorban az archivált adatokhoz való hozzáférést szolgálja sürgős esemény esetén, nem pedig a szokásos működési igényekhez.
- Adatait almappákba rendezheti.
- Megfelelő engedélykorlátozásokat kell beállítania.
- Adjon hozzá címkéket a gyűjtőzónákhoz, hogy könnyen azonosíthatók legyenek, és hogy a dinamikus S3 gyűjtőzónákon belül használhatók legyenek.
- A vödör kiszolgáló nélküli kialakítású. Ez egyszerűen egy tárhely az adatok számára.
Az S3 vödör kiszolgáló nélküli kialakítású. Ez egyszerűen egy tárhely az adatok számára.
AWS Athena adatbázis
 Forrás: aws.amazon.com
Forrás: aws.amazon.com
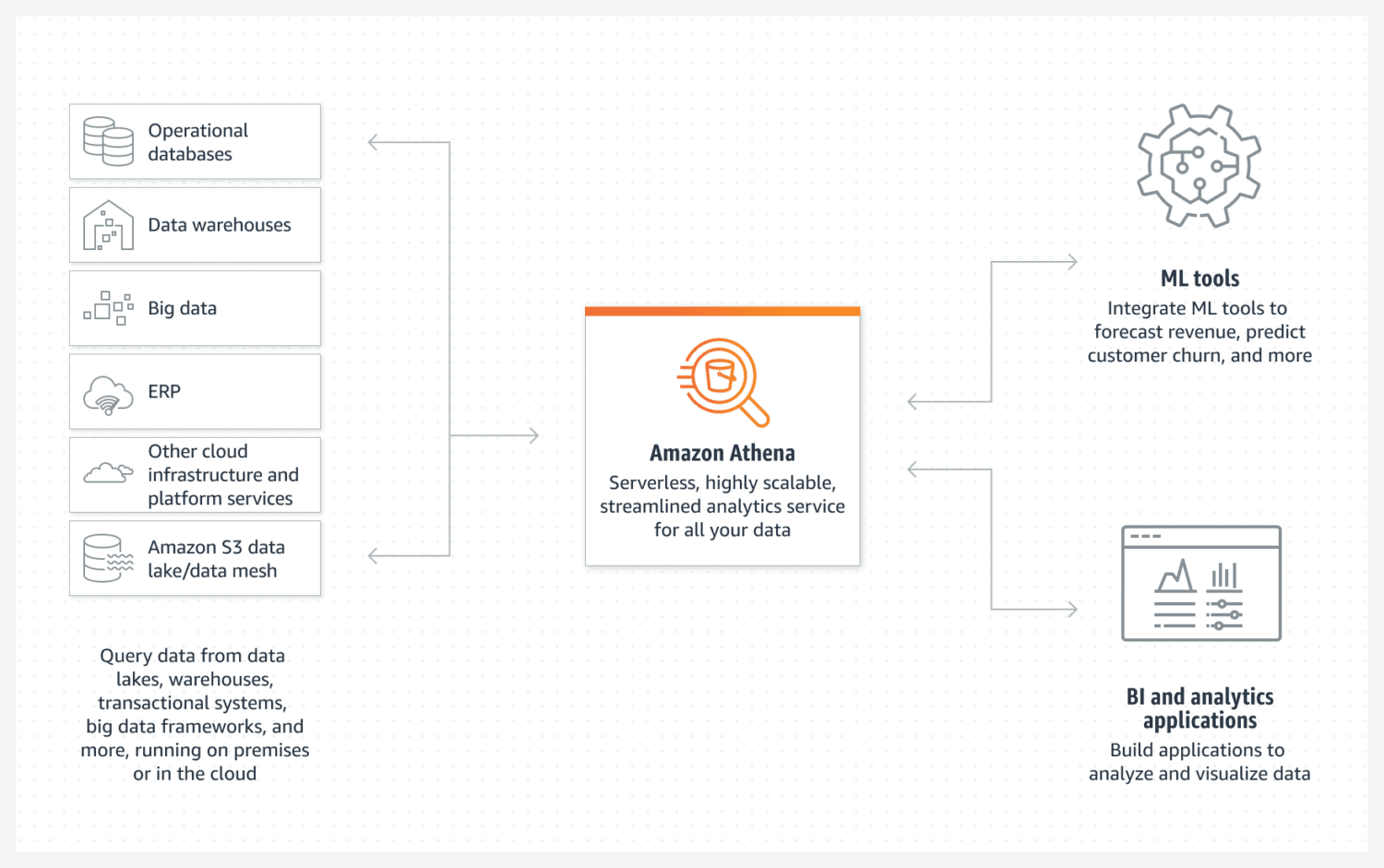
Az Athena megkönnyíti az AWS alapadat-tó létrehozását. Ez egy szerver nélküli adatbázis, amely egy S3 tárolót használ az adatok tárolására. Az adatok rendszerezését strukturált fájlformátumok, például parketta vagy vesszővel tagolt érték (CSV) fájlok tartják fenn. Az S3 vödör tartalmazza a fájlokat, és az Athena hivatkozik rájuk, amikor a folyamatok kiválasztják az adatokat az adatbázisból.
Ne feledje, hogy az Athena nem támogat különféle, egyébként szabványnak tekintett funkciókat, például a frissítési utasításokat. Ezért kell az Athénát egy nagyon egyszerű lehetőségnek tekinteni.
Azonban támogatja az indexelést és a particionálást. Vízszintesen is könnyen skálázható, mivel ez olyan bonyolult, mint új vödrök hozzáadása az infrastruktúrához. Az egyszerű, de működőképes adattó létrehozásához ez a legtöbb esetben még elegendő lehet.
A jó teljesítmény érdekében elengedhetetlen a legjobb adatterv kiválasztása a jövőbeni felhasználásra összpontosítva. Nagyon fontos, hogy világosan lássunk az adatok kiválasztásának módjáról. A táblák későbbi újbóli létrehozása, ha már léteznek és sok adattal vannak feltöltve, nehéz.
Az Athena DB nagyszerű választás, és jól illeszkedik a céljaihoz, ha egyszerű és megváltoztathatatlan adatkészletet szeretne létrehozni, amely idővel vízszintesen könnyen méretezhető.
AWS Aurora adatbázis
 Forrás: aws.amazon.com
Forrás: aws.amazon.com
Az Athena DB kiválóan alkalmas a nem kurzorált adatok tárolására. Így szeretné tárolni az eredeti tartalmat, hogy maximalizálja későbbi újrafelhasználását. Azonban lassú a kiválasztott eredmények biztosítása egy előtérbeli alkalmazás számára.
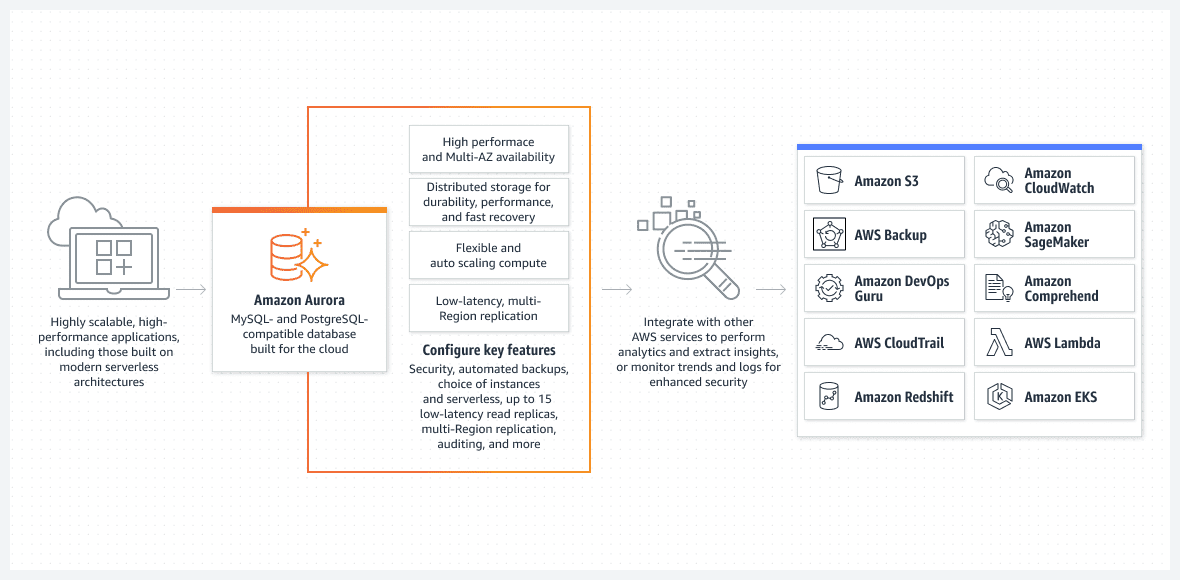
Az egyik legjobb lehetőség, főleg a könnyen végrehajtható telepítés szempontjából, a szerver nélküli módban futó Aurora adatbázis.
Az Aurora messze nem egy alapvető adatbázis. Ez az egyik legfejlettebb natív relációs adatbázis-megoldás az AWS-ben. Ez egy rendkívül összetett natív relációs adatbázis-megoldás is, amely minden kiadással javul.
Az Aurora egyedülálló, mert szerver nélküli módban is futhat, így kiemelkedik a többi relációs szolgáltatás közül. A mód így működik:
- Az Aurora-fürt konfigurálásához használja az AWS konzolt. Meg kell adnia a szabványos CPU és RAM szinteket, valamint az automatikus skálázási funkciók maximális intervallumát. Ez hatással lesz az Aurora-fürt dinamikusan hozzáadható vagy eltávolítható teljesítményére. Az adatbázis jelenlegi kihasználtsága alapján az AWS úgy dönt, hogy felfelé vagy lefelé léptet.
- Az Aurora-fürt csak akkor indul el, ha a felhasználó vagy a folyamat valódi kérést kezdeményez. Például amikor az ütemezett kötegelt feldolgozás elindul. Vagy ha az alkalmazás egy háttér API-hívást hajt végre az adatok adatbázisból való lekéréséhez. Az adatbázis automatikusan megnyílik, és a kérési folyamatok befejezése után előre meghatározott ideig aktív marad.
- Az Aurora-fürt automatikusan leáll, ha nincs több munka az adatbázisban.
Hogy még egyszer hangsúlyozzuk, a szerver nélküli Aurora DB csak akkor fut, ha valódi munkát kell végeznie. Az automatikusan induló fürt ismét leáll, ha nem dolgoz fel semmilyen munkát. A tényleges munka az, amiért fizet, és nem a tétlenség.
A kiszolgáló nélküli Aurorát teljes mértékben az AWS felügyeli, és nem igényel rendszergazdát.
AWS Amplify
Az Amplify szerver nélküli platformot kínál a JavaScript és React könyvtárakkal készült front-end alkalmazások gyors telepítéséhez. Nincs szükség fürtkiszolgálók beállítására. Használja az AWS-konzolt a kód közvetlen üzembe helyezéséhez, vagy használjon automatizált DevOps-folyamatot.
Hívhat háttér API-kat az adatbázisokban tárolt adatok eléréséhez. Ezek a hívások lehetővé teszik a tényleges adatok elérését a front-end alkalmazásban. A háttér teljesítményének fő optimalizálását a csapatnak kell elvégeznie. Még tovább csökkentheti a lassú válaszadás lehetőségét a felhasználói felületen, ha hatékony kiválasztási utasításokat tervez közvetlenül az API-hívásokon belül.
AWS lépésfunkciók
 Forrás: aws.amazon.com
Forrás: aws.amazon.com
Annak ellenére, hogy a rendszer minden fő összetevője kiszolgáló nélküli, ez nem garantálja a teljesen kiszolgáló nélküli architektúrát. Ez csak akkor lehetséges, ha az összetevők közötti összes kötegelt folyamat kiszolgáló nélküli.
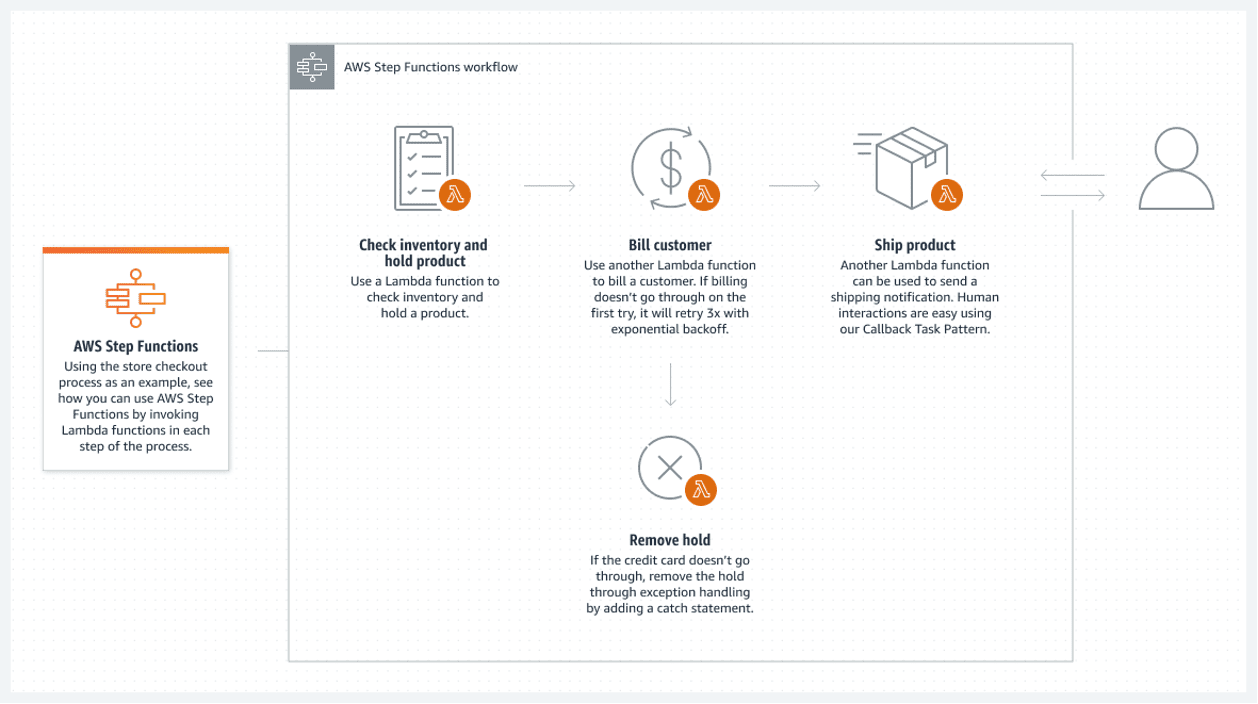
Az AWS Step funkciók a legjobb megoldást nyújtják az AWS felhőben. Az AWS Lambda funkcióinak összekapcsolt listája alkotja a lépés funkciót. Ezek a függvények folyamatábrát hoznak létre, amely világos kezdési és befejezési állapotokkal rendelkezik. A lambda függvény, amelyet általában Python vagy Node JS nyelven írnak, egy végrehajtható kódrészlet, amely bármit feldolgoz, amire szükség van.
A következő egy példa arra, hogyan hajthat végre egy lépéses függvényt:
Ennek a szerver nélküli folyamnak van egy nagy hátránya: minden lambda funkció legfeljebb 15 percig futhat. Ezért az áramlás kisebb lambda-függvényekre osztása ezt kevésbé problematikussá teheti.
Lehetőség van több lambda függvény egyidejű meghívására egy lépésben, ami alapvetően egy lépés párhuzamosítását jelenti több egyidejűleg végrehajtott lambdával. Csak várja meg, amíg az összes párhuzamos lambda-feldolgozás befejeződik, mielőtt folytatná. Ezután folytassa a következő lambda-feldolgozással.
Végső szavak
A szerver nélküli architektúra egyedülálló lehetőséget kínál a teljes rendszerkörnyezetet lefedő felhőplatform létrehozására. Ez a platform vízszintesen méretezhető, és alacsony üzemeltetési költséggel rendelkezik.
Tökéletes megoldás szűkös költségvetésű projektekhez. Kiváló feltárási lehetőség, jellemzően olyan esetekben, amikor senki sem ismeri a termelési terhelés valóságát. Ez különösen fontos azután, hogy az összes felhasználót sikeresen bekapcsolta. A projektcsapatok továbbra is átfogó képet kaphatnak a rendszer működéséről. Mindezeket az előnyöket élvezheti, és még mindig nem kell kompromisszumokat elfogadnia.
Ez a lefedettség nem lesz megfelelő minden esetben, különösen a magas CPU-használat esetén. Az AWS felhő azonban folyamatosan fejlődik a szerver nélküli használati esetek tekintetében. Általában célszerű alapos kutatást végezni, mielőtt a következő AWS felhőprojekt kiszolgáló nélküli opcióját választaná.
Ezután nézze meg a legjobb kiszolgáló nélküli adatbázisokat a modern alkalmazásokhoz.