
Nos, a Forbes statisztikái szerint a világszervezetek akár 90%-a Big Data elemzést használ befektetési jelentései elkészítéséhez.
A Big Data növekvő népszerűsége következtében a Hadoop álláslehetőségei a korábbinál nagyobb mértékben növekednek.
Ezért a Hadoop-szakértői szerep elnyeréséhez felhasználhatja ezeket az interjúkérdéseket és válaszokat, amelyeket ebben a cikkben gyűjtöttünk össze Önnek, hogy segítsen átvészelni az interjút.
Lehet, hogy az olyan tények ismerete, mint például a fizetési tartomány, amelyek jövedelmezővé teszik a Hadoop és a Big Data szerepkörét, motiválni fogja Önt az interjú letételére, igaz? 🤔
- Az indeed.com szerint egy amerikai székhelyű Big Data Hadoop fejlesztő átlagosan 144 000 dollárt keres.
- Az itjobswatch.co.uk szerint egy Big Data Hadoop fejlesztő átlagos fizetése 66 750 GBP.
- Indiában az indeed.com forrása azt állítja, hogy átlagosan 16 00 000 ₹ fizetést keresnének.
Jövedelmező, nem gondolod? Most pedig ugorjunk a Hadoop megismeréséhez.
Tartalomjegyzék
Mi az a Hadoop?
A Hadoop egy népszerű Java nyelven írt keretrendszer, amely programozási modelleket használ nagy adathalmazok feldolgozására, tárolására és elemzésére.
Alapértelmezés szerint a kialakítása lehetővé teszi a méretezést egyetlen szerverről több gépre, amelyek helyi számítást és tárolást kínálnak. Ezen túlmenően, az alkalmazásréteg-hibák észlelésére és kezelésére való képessége, amely magas rendelkezésre állású szolgáltatásokat eredményez, meglehetősen megbízhatóvá teszi a Hadoopot.
Ugorjunk közvetlenül a Hadoop interjú gyakran feltett kérdéseire és a rájuk adott helyes válaszokra.
A Hadoop interjú kérdései és válaszai
Mi az a tárolóegység a Hadoopban?
Válasz: A Hadoop tárolóegységének neve Hadoop Distributed File System (HDFS).
Miben különbözik a hálózathoz csatlakoztatott tároló a Hadoop elosztott fájlrendszertől?
Válasz: A HDFS, amely a Hadoop elsődleges tárolója, egy elosztott fájlrendszer, amely nagy mennyiségű fájlokat tárol árucikk hardver segítségével. Másrészt a NAS egy fájlszintű számítógépes adattároló szerver, amely heterogén ügyfélcsoportok számára biztosít hozzáférést az adatokhoz.
Míg a NAS-ban az adattárolás dedikált hardveren történik, a HDFS elosztja az adatblokkokat a Hadoop-fürtön belüli összes gép között.
A NAS csúcskategóriás tárolóeszközöket használ, ami meglehetősen költséges, míg a HDFS-ben használt árucikk hardver költséghatékony.
A NAS külön tárolja a számításokból származó adatokat, így alkalmatlan a MapReduce számára. Éppen ellenkezőleg, a HDFS kialakítása lehetővé teszi a MapReduce keretrendszerrel való együttműködést. A számítások a MapReduce keretrendszerben lévő adatokra költöznek, nem pedig az adatokra.
Magyarázza el a MapReduce-t a Hadoopban és a Shufflingben
Válasz: A MapReduce két különálló feladatra utal, amelyeket a Hadoop-programok hajtanak végre, hogy nagymértékben méretezhetőek legyenek a Hadoop-fürtön belüli több száz és több ezer szerver között. A keverés viszont átviszi a térképkimenetet a Mappersből a szükséges reduktorba a MapReduce-ban.
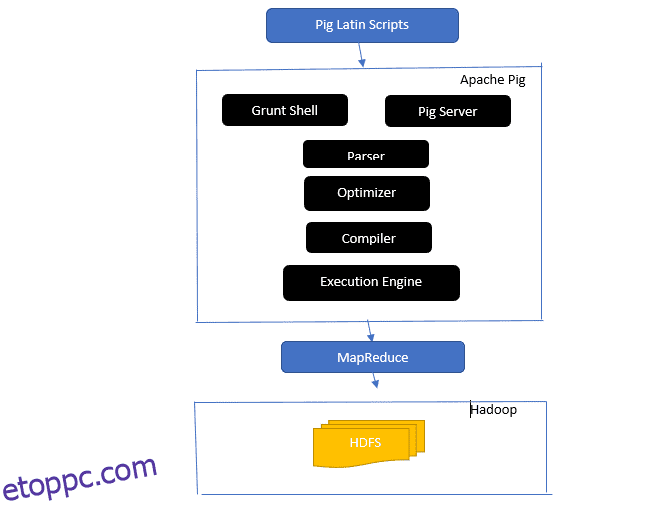
Vessen egy pillantást az Apache Pig építészetébe
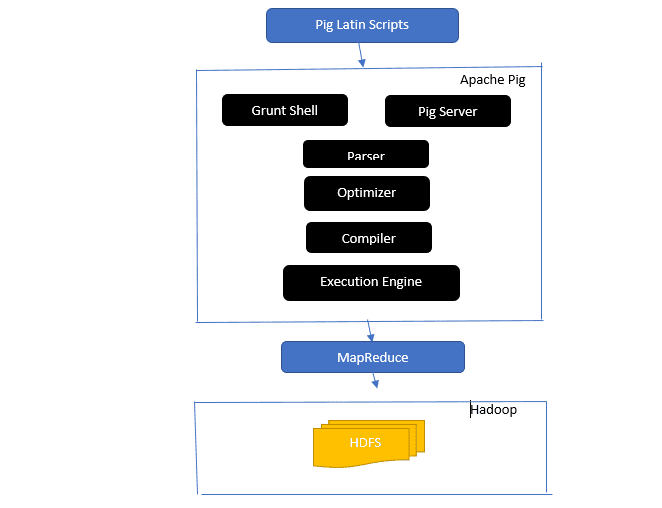 Az Apache Pig építészet
Az Apache Pig építészet
Válasz: Az Apache Pig architektúra rendelkezik egy Pig Latin értelmezővel, amely nagy adatkészleteket dolgoz fel és elemzi Pig Latin szkriptek segítségével.
Az Apache pig adatkészletek készleteiből is áll, amelyeken olyan adatműveleteket hajtanak végre, mint a csatlakozás, a betöltés, a szűrés, a rendezés és a csoportosítás.
A Pig Latin nyelv végrehajtási mechanizmusokat használ, például Grant-héjakat, UDF-eket és beágyazott Pig-szkriptek írásához, amelyek elvégzik a szükséges feladatokat.
A Pig megkönnyíti a programozók munkáját azáltal, hogy ezeket az írott szkripteket Map-Reduce jobs sorozatokká konvertálja.
Az Apache Pig architektúra összetevői a következők:
- Elemző – A Pig Scripteket úgy kezeli, hogy ellenőrzi a szkript szintaxisát és típusellenőrzést végez. Az elemző kimenete a Pig Latin utasításait és logikai operátorait reprezentálja, és DAG-nak (irányított aciklikus gráfnak) hívják.
- Optimizer – Az optimalizáló logikai optimalizálásokat valósít meg, mint például a vetítés és a lenyomás a DAG-n.
- Fordító – Lefordítja az optimalizált logikai tervet az optimalizálóból MapReduce-feladatok sorozatává.
- Végrehajtási motor – Itt történik a MapReduce-feladatok végső végrehajtása a kívánt kimenetre.
- Végrehajtási mód – Az Apache pig végrehajtási módjai főként a helyi és a Map Reduce-t tartalmazzák.
Válasz: A helyi metastore-beli Metastore szolgáltatás ugyanabban a JVM-ben fut, mint a Hive, de csatlakozik egy külön folyamatban futó adatbázishoz ugyanazon vagy egy távoli gépen. Másrészt a távoli metastore-ben található Metastore a Hive szolgáltatás JVM-től különálló JVM-jében fut.
Mi a Big Data öt V-je?
Válasz: Ez az öt V a Big Data fő jellemzőit jelenti. Tartalmazzák:
- Érték: A Big Data jelentős előnyöket kíván nyújtani a magas befektetésarányos megtérülésből (ROI) egy olyan szervezet számára, amely nagy adatforgalmat használ adatkezelései során. A Big Data ezt az értéket az insight felfedezéséből és a mintafelismeréséből eredezteti, ami többek között erősebb ügyfélkapcsolatokat és hatékonyabb működést eredményez.
- Változatosság: Ez az összegyűjtött adattípusok heterogenitását jelzi. A különböző formátumok közé tartozik a CSV, videók, hang stb.
- Kötet: Ez határozza meg a szervezet által kezelt és elemzett adatok jelentős mennyiségét és méretét. Ez az adat exponenciális növekedést mutat.
- Sebesség: Ez az adatnövekedés exponenciális sebessége.
- Valóság: A hitelesség arra utal, hogy a rendelkezésre álló adatok mennyire „bizonytalanok” vagy „pontatlanok” abból adódóan, hogy az adatok hiányosak vagy következetlenek.
Magyarázza el a sertés latin különböző adattípusait.
Válasz: A Pig latin nyelvű adattípusok atomi adattípusokat és összetett adattípusokat tartalmaznak.
Az Atomic adattípusok minden más nyelvben használt alapvető adattípusok. Ezek a következők:
- Int – Ez az adattípus egy előjeles, 32 bites egész számot határoz meg. Példa: 13
- Long – Hosszú egy 64 bites egész számot definiál. Példa: 10 liter
- Float – Előjeles 32 bites lebegőpontot határoz meg. Példa: 2,5F
- Double – Előjeles 64 bites lebegőpontot határoz meg. Példa: 23.4
- Boolean – Logikai értéket határoz meg. Tartalmazza: igaz/hamis
- Datetime – Dátum-idő értéket határoz meg. Példa: 1980-01-01T00:00.00.000+00:00
Az összetett adattípusok a következők:
- Map- A Map egy kulcs-érték pár halmazra utal. Példa: [‘color’#’yellow’, ‘number’#3]
- Bag – Ez egy sor sor gyűjteménye, és a „{}” szimbólumot használja. Példa: {(Henry, 32), (Kiti, 47)}
- Tuple – A sor mezők rendezett halmazát határozza meg. Példa: (életkor, 33)
Mi az Apache Oozie és az Apache ZooKeeper?
Válasz: Az Apache Oozie egy Hadoop-ütemező, aki a Hadoop-feladatok ütemezéséért és egyetlen logikai munkaként való összekapcsolásáért felelős.
Az Apache Zookeeper viszont elosztott környezetben koordinál különféle szolgáltatásokat. Időt takarít meg a fejlesztőknek azáltal, hogy egyszerűen elérhetővé teszi az olyan egyszerű szolgáltatásokat, mint a szinkronizálás, csoportosítás, konfiguráció karbantartása és elnevezése. Az Apache Zookeeper készen álló támogatást is nyújt a sorban álláshoz és a vezetőválasztáshoz.
Mi a Combiner, RecordReader és Partitioner szerepe a MapReduce műveletben?
Válasz: A kombináló úgy működik, mint egy mini reduktor. Fogadja és dolgozza fel a térképfeladatokból származó adatokat, majd átadja az adatok kimenetét a redukciós fázisnak.
A RecordHeader kommunikál az InputSplittel, és az adatokat kulcs-érték párokká alakítja, hogy a leképező megfelelően olvashassa.
A particionáló felelős az adatok összegzéséhez szükséges csökkentett feladatok számának eldöntéséért és annak megerősítéséért, hogy a kombináló kimenetei hogyan kerülnek a reduktorba. A particionáló vezérli a közbenső leképezési kimenetek kulcsparticionálását is.
Említse meg a Hadoop különböző szállítóspecifikus disztribúcióit.
Válasz: A Hadoop képességeit kiterjesztő különféle szállítók a következők:
- IBM nyílt platform.
- Cloudera CDH Hadoop disztribúció
- MapR Hadoop Distribution
- Amazon Elastic MapReduce
- Hortonworks Data Platform (HDP)
- Pivotal Big Data Suite
- Datastax Enterprise Analytics
- A Microsoft Azure HDInsight – felhőalapú Hadoop disztribúciója.
Miért a HDFS hibatűrő?
Válasz: A HDFS különböző DataNode-okon replikálja az adatokat, így hibatűrővé teszi. Az adatok különböző csomópontokban való tárolása lehetővé teszi a visszakeresést más csomópontokból, amikor az egyik mód összeomlik.
Tegyen különbséget a szövetség és a magas rendelkezésre állás között.
Válasz: A HDFS Federation hibatűrést kínál, amely lehetővé teszi a folyamatos adatáramlást az egyik csomópontban, amikor egy másik összeomlik. Másrészt a magas rendelkezésre álláshoz két külön gépre lesz szükség, amelyek külön konfigurálják az aktív NameNode-ot és a másodlagos NameNode-ot az első és a második gépen.
Az összevonás korlátlan számú független NameNode-ot tartalmazhat, míg a Magas rendelkezésre állásban csak két kapcsolódó NameNode érhető el, az aktív és a készenléti, amelyek folyamatosan működnek.
Az összevonásban lévő NameNode-ok egy metaadatkészletet osztanak meg, és minden NameNode-nak megvan a saját dedikált készlete. Magas rendelkezésre állás esetén azonban az aktív NameNode-ok egyenként futnak, miközben a készenléti NameNode-ok tétlenek maradnak, és csak alkalmanként frissítik metaadataikat.
Hogyan lehet megtalálni a blokkok állapotát és a fájlrendszer állapotát?
Válasz: Használja a hdfs fsck / parancsot a gyökér felhasználói szinten és egy egyedi könyvtárban is a HDFS fájlrendszer állapotának ellenőrzésére.
HDFS fsck parancs használatban:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
A parancs leírása:
- -files: Az ellenőrzött fájlok kinyomtatása.
- –locations: Ellenőrzés közben kinyomtatja az összes blokk helyét.
Parancs a blokkok állapotának ellenőrzéséhez:
hdfs fsck <path> -files -blocks
- <útvonal>: Az ellenőrzéseket az itt átadott útvonaltól kezdi.
- – blokkok: Az ellenőrzés során kiírja a fájlblokkokat
Mikor használja az rmadmin-refreshNodes és dfsadmin-refreshNodes parancsokat?
Válasz: Ez a két parancs hasznos a csomóponti információk frissítésében akár az üzembe helyezés során, akár a csomópont üzembe helyezése után.
A dfsadmin-refreshNodes parancs futtatja a HDFS-ügyfelet, és frissíti a NameNode csomópont-konfigurációját. Az rmadmin-refreshNodes parancs viszont végrehajtja a ResourceManager adminisztrációs feladatait.
Mi az a Checkpoint?
Válasz: A Checkpoint egy olyan művelet, amely egyesíti a fájlrendszer utolsó módosításait a legutóbbi FSImage-gel, így a szerkesztési naplófájlok elég kicsik maradnak ahhoz, hogy felgyorsítsák a NameNode elindításának folyamatát. Az ellenőrzőpont a másodlagos névcsomópontban található.
Miért használunk HDFS-t nagy adatkészletekkel rendelkező alkalmazásokhoz?
Válasz: A HDFS DataNode és NameNode architektúrát biztosít, amely elosztott fájlrendszert valósít meg.
Ez a két architektúra nagy teljesítményű hozzáférést biztosít az adatokhoz a Hadoop nagymértékben méretezhető fürtjein keresztül. A NameNode a fájlrendszer metaadatait a RAM-ban tárolja, ami azt eredményezi, hogy a memória mennyisége korlátozza a HDFS fájlrendszer fájlok számát.
Mit csinál a „jps” parancs?
Válasz: A Java Virtual Machine Process Status (JPS) parancs ellenőrzi, hogy bizonyos Hadoop-démonok, köztük a NodeManager, a DataNode, a NameNode és a ResourceManager futnak-e vagy sem. Ezt a parancsot a gyökérből kell futtatni a gazdagép működési csomópontjainak ellenőrzéséhez.
Mi az a „spekulatív végrehajtás” a Hadoopban?
Válasz: Ez egy olyan folyamat, amelyben a Hadoop fő csomópontja az észlelt lassú feladatok kijavítása helyett ugyanannak a feladatnak egy másik példányát indítja el biztonsági mentési feladatként (spekulatív feladatként) egy másik csomóponton. A spekulatív végrehajtás sok időt takarít meg, különösen intenzív munkaterhelésű környezetben.
Nevezze meg a három módot, amelyben a Hadoop futhat.
Válasz: A három elsődleges csomópont, amelyen a Hadoop fut, a következők:
- A Standalone Node az alapértelmezett mód, amely a Hadoop-szolgáltatásokat a helyi fájlrendszer és egyetlen Java-folyamat használatával futtatja.
- Az ál-elosztott csomópont az összes Hadoop-szolgáltatást egyetlen óda Hadoop-telepítéssel hajtja végre.
- A teljesen elosztott csomópont külön csomópontok használatával futtatja a Hadoop fő- és szolgaszolgáltatásokat.
Mi az UDF?
Válasz: Az UDF (User Defined Functions) lehetővé teszi egyéni függvények kódolását, amelyek segítségével az Impala lekérdezés során feldolgozhatja az oszlopértékeket.
Mi az a DistCp?
Válasz: A DistCp vagy a Distributed Copy, röviden, egy hasznos eszköz az adatok nagyméretű, fürtön belüli másolásához. A MapReduce használatával a DistCp hatékonyan valósítja meg nagy mennyiségű adat elosztott másolatát, többek között olyan feladatok mellett, mint a hibakezelés, a helyreállítás és a jelentéskészítés.
Válasz: A Hive metastore egy olyan szolgáltatás, amely egy relációs adatbázisban, például a MySQL-ben tárolja a Hive-táblák Apache Hive metaadatait. Ez biztosítja a metastore szolgáltatás API-t, amely centiméteres hozzáférést tesz lehetővé a metaadatokhoz.
Határozza meg az RDD-t.
Válasz: Az RDD, amely a Resilient Distributed Datasets rövidítése, a Spark adatszerkezete és az adatelemek megváltoztathatatlan elosztott gyűjteménye, amely a különböző fürtcsomópontokon számol.
Hogyan vehetők fel a natív könyvtárak a YARN állásokba?
Válasz: Ezt a -Djava.library használatával megvalósíthatja. path opciót a parancsban, vagy az LD+LIBRARY_PATH beállításával a .bashrc fájlban a következő formátumban:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Magyarázza el a „WAL” szót a HBase-ben.
Válasz: A Write Ahead Log (WAL) egy helyreállítási protokoll, amely rögzíti a MemStore adatok változásait a HBase-ben a fájlalapú tárolóban. A WAL helyreállítja ezeket az adatokat, ha a RegionalServer összeomlik, vagy a MemStore kiürítése előtt.
A YARN helyettesíti a Hadoop MapReduce-t?
Válasz: Nem, a YARN nem a Hadoop MapReduce helyettesítője. Ehelyett a Hadoop 2.0 vagy a MapReduce 2 nevű hatékony technológia támogatja a MapReduce-t.
Mi a különbség a ORDER BY és a SORT BY között a HIVE-ben?
Válasz: Bár mindkét parancs rendezett módon kéri le az adatokat a Hive-ben, a SORT BY használatából származó eredmények csak részben rendezhetők.
Ezenkívül a SORT BY funkcióhoz szűkítő szükséges a sorok rendezéséhez. A végső kimenethez szükséges reduktorok többszörösek is lehetnek. Ebben az esetben a végső kimenet részben megrendelhető.
Másrészt az ORDER BY csak egy szűkítőt igényel a teljes rendelési mennyiséghez. Használhatja a LIMIT kulcsszót is, amely csökkenti a teljes rendezési időt.
Mi a különbség a Spark és a Hadoop között?
Válasz: Bár a Hadoop és a Spark is elosztott feldolgozási keretrendszer, a legfontosabb különbség a feldolgozásukban van. Ahol a Hadoop hatékony a kötegelt feldolgozáshoz, a Spark hatékony a valós idejű adatfeldolgozáshoz.
Ezenkívül a Hadoop főleg HDFS-re olvas és ír fájlokat, míg a Spark a Resilient Distributed Dataset koncepciót használja a RAM-ban lévő adatok feldolgozásához.
A késleltetésük alapján a Hadoop egy nagy késleltetésű számítási keretrendszer, amely nem rendelkezik interaktív móddal az adatok feldolgozásához, míg a Spark egy alacsony késleltetésű számítási keretrendszer, amely interaktívan dolgozza fel az adatokat.
Hasonlítsa össze a Sqoop-ot és a Flume-ot.
Válasz: A Sqoop és a Flume a Hadoop eszközök, amelyek különböző forrásokból gyűjtött adatokat gyűjtenek, és betöltik az adatokat a HDFS-be.
- A Sqoop (SQL-to-Hadoop) strukturált adatokat nyer ki adatbázisokból, beleértve a Teradatát, a MySQL-t, az Oracle-t stb., míg a Flume hasznos a strukturálatlan adatok kinyerésére adatbázis-forrásokból és HDFS-be való betöltésére.
- A vezérelt események tekintetében a Flume eseményvezérelt, míg a Sqoop nem az események által vezérelt.
- A Sqoop összekötő alapú architektúrát használ, ahol az összekötők tudják, hogyan csatlakozhatnak egy másik adatforráshoz. A Flume ügynök-alapú architektúrát használ, és a megírt kód az adatok lekéréséért felelős ügynök.
- A Flume elosztott természete miatt könnyen gyűjthet és összesíthet adatokat. A Sqoop hasznos a párhuzamos adatátvitelhez, ami azt eredményezi, hogy a kimenet több fájlban lesz.
Magyarázza el a BloomMapFile-t.
Válasz: A BloomMapFile egy olyan osztály, amely kiterjeszti a MapFile osztályt, és dinamikus virágzási szűrőket használ, amelyek gyors tagsági tesztet biztosítanak a kulcsokhoz.
Sorolja fel a különbséget a HiveQL és a PigLatin között.
Válasz: Míg a HiveQL az SQL-hez hasonló deklaratív nyelv, a PigLatin egy magas szintű eljárási adatfolyam-nyelv.
Mi az az adattisztítás?
Válasz: Az adattisztítás kulcsfontosságú folyamat az azonosított adathibák eltávolításában vagy kijavításában, amelyek magukban foglalják az adatkészleten belüli helytelen, hiányos, sérült, duplikált és helytelenül formázott adatokat.
Ennek a folyamatnak az a célja, hogy javítsa az adatok minőségét, és pontosabb, konzisztensebb és megbízhatóbb információkat biztosítson a szervezeten belüli hatékony döntéshozatalhoz.
Következtetés 💃
A Big Data és a Hadoop álláslehetőségeinek jelenlegi felfutása miatt érdemes lehet növelni az esélyeit a bejutásra. Ebben a cikkben a Hadoop-interjúkra vonatkozó kérdések és válaszok segítenek a közelgő interjúban.
Ezután megtekintheti a jó forrásokat a Big Data és a Hadoop megtanulásához.
Sok szerencsét! 👍