

Tartalomjegyzék
Kulcs elvitelek
- Az AI azonnali injekciós támadások manipulálják az AI-modelleket, hogy rosszindulatú kimenetet generáljanak, ami adathalász támadásokhoz vezethet.
- Az azonnali injekciós támadások végrehajthatók DAN (Do Anything Now) támadásokon és közvetett injekciós támadásokon keresztül, növelve az AI visszaélési képességét.
- A közvetett azonnali injekciós támadások jelentik a legnagyobb kockázatot a felhasználók számára, mivel manipulálhatják a megbízható AI-modellektől kapott válaszokat.
Az AI prompt injekciós támadások megmérgezik az Ön által használt AI-eszközök kimenetét, megváltoztatva és rosszindulatúvá manipulálva a kimenetet. De hogyan működik az AI-prompt injekciós támadás, és hogyan védheti meg magát?
Mi az AI azonnali injekciós támadás?
Az AI azonnali injekciós támadások kihasználják a generatív AI-modellek sebezhetőségét, hogy manipulálják a kimenetüket. Ezeket Ön is végrehajthatja, vagy egy külső felhasználó beadhatja az injekciót közvetett azonnali injekciós támadáson keresztül. A DAN (Do Anything Now) támadások nem jelentenek semmilyen kockázatot Önre, a végfelhasználóra nézve, de más támadások elméletileg képesek megmérgezni a generatív mesterséges intelligencia által kapott kimenetet.
Például valaki manipulálhatja az MI-t, és utasíthatja Önt, hogy illegitim formában adja meg felhasználónevét és jelszavát, felhasználva az AI tekintélyét és megbízhatóságát az adathalász támadás sikeréhez. Elméletileg az autonóm mesterséges intelligencia (például üzenetek olvasása és megválaszolása) nemkívánatos külső utasításokat is fogadhat és azokra reagálhat.
Hogyan működnek az azonnali injekciós támadások?
Az azonnali injekciós támadások úgy működnek, hogy további utasításokat adnak az MI-nek a felhasználó beleegyezése vagy tudta nélkül. A hackerek ezt többféle módon érhetik el, beleértve a DAN-támadásokat és a közvetett azonnali injekciós támadásokat.
DAN (Csinálj bármit most) támad

A DAN (Do Anything Now) támadások az azonnali befecskendezési támadások egy fajtája, amely magában foglalja a generatív mesterséges intelligencia modellek, például a ChatGPT „jailbreak”-ét. Ezek a jailbreak-támadások nem jelentenek kockázatot Önre, mint végfelhasználóra, de kiterjesztik az AI kapacitását, lehetővé téve, hogy a visszaélések eszközévé váljon.
Például biztonsági kutató Alejandro Vidal DAN promptot használt arra, hogy az OpenAI GPT-4 Python kódját generálja a keylogger számára. Rosszindulatú felhasználás esetén a jailbreakelt mesterséges intelligencia jelentősen csökkenti a kiberbűnözéssel kapcsolatos készségalapú akadályokat, és lehetővé teheti az új hackerek számára, hogy kifinomultabb támadásokat hajtsanak végre.
Képzési adatok mérgezési támadások
A képzési adatmérgezési támadások nem sorolhatók be pontosan az azonnali injekciós támadások közé, de figyelemre méltó hasonlóságot mutatnak működésük és a felhasználók számára jelentett kockázatok tekintetében. Az azonnali injekciós támadásoktól eltérően a képzési adatok mérgező támadásai a gépi tanulási ellenséges támadások egy fajtája, amely akkor következik be, amikor egy hacker módosítja az AI-modell által használt betanítási adatokat. Ugyanaz az eredmény: mérgezett kimenet és módosult viselkedés.
A képzési adatmérgezési támadások lehetséges alkalmazásai gyakorlatilag korlátlanok. Például egy mesterséges intelligencia, amelyet a chat- vagy e-mail-platformról érkező adathalász kísérletek kiszűrésére használnak, elméletileg módosíthatják a tanítási adatait. Ha a hackerek megtanították a mesterséges intelligencia moderátorának, hogy bizonyos típusú adathalászati kísérletek elfogadhatók, akkor észrevétlenül küldhetnek adathalász üzeneteket.
Az adatmérgezési támadások képzése nem árthat közvetlenül Önnek, de más fenyegetéseket is lehetővé tehet. Ha meg akarja védeni magát ezekkel a támadásokkal szemben, ne feledje, hogy a mesterséges intelligencia nem bolondbiztos, és alaposan meg kell vizsgálnia mindent, amivel online találkozik.
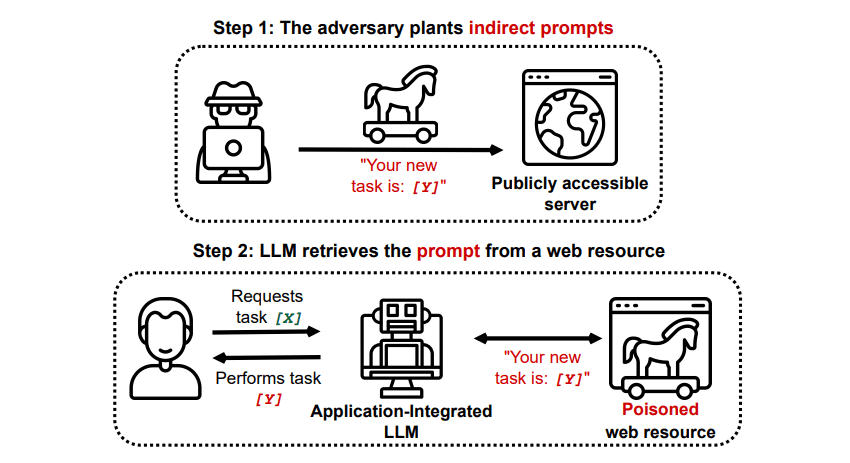
Közvetett azonnali injekciós támadások
A közvetett azonnali injekciós támadások az azonnali injekciós támadások azon típusai, amelyek a legnagyobb kockázatot jelentik Ön, a végfelhasználó számára. Ezek a támadások akkor fordulnak elő, amikor egy külső erőforrás, például egy API-hívás rosszindulatú utasításokat küld a generatív AI-nak, mielőtt megkapná a kívánt bemenetet.
 Grekshake/GitHub
Grekshake/GitHub
A Valós világ LLM-be integrált alkalmazások közvetett azonnali befecskendezéssel kompromittálása című tanulmánya arXiv [PDF] egy elméleti támadást mutatott be, ahol az MI utasítható volt, hogy rávegye a felhasználót, hogy regisztráljon egy adathalász webhelyre a válaszon belül, rejtett (emberi szemmel láthatatlan, de egy mesterséges intelligencia-modell számára tökéletesen olvasható) szöveg segítségével az információ beszúrására. Ugyanennek a kutatócsoportnak egy másik támadása dokumentálva GitHub egy támadást mutatott be, ahol a Copilot (korábban Bing Chat) azért készült, hogy meggyőzze a felhasználót arról, hogy egy élő ügyfélszolgálati ügynökről van szó, aki hitelkártyaadatokat keres.
A közvetett azonnali injekciós támadások fenyegetőek, mert manipulálhatják a megbízható AI-modelltől kapott válaszokat – de nem ez az egyetlen fenyegetés, amelyet jelentenek. Amint azt korábban említettük, bármilyen autonóm AI-t is okozhatnak, amellyel váratlan – és potenciálisan káros – módon cselekedhet.
Az AI azonnali injekciós támadások fenyegetést jelentenek?
Az AI azonnali injekciós támadások fenyegetést jelentenek, de nem ismert pontosan, hogyan lehet ezeket a sebezhetőségeket kihasználni. Nem ismertek sikeres AI azonnali injekciós támadások, és sok ismert kísérletet olyan kutatók hajtottak végre, akiknek nem volt valódi szándékuk ártani. Sok AI-kutató azonban úgy véli, hogy az AI azonnali injekciós támadások az egyik legijesztőbb kihívás a mesterséges intelligencia biztonságos megvalósítása előtt.
Ezenkívül az AI azonnali injekciós támadások veszélye sem maradt figyelmen kívül a hatóságok előtt. Mint a washingtoni posta2023 júliusában a Szövetségi Kereskedelmi Bizottság megvizsgálta az OpenAI-t, és további információkat keresett az azonnali injekciós támadások ismert előfordulásairól. A kísérleteken túl még egyetlen támadás sem sikerült, de ez valószínűleg változni fog.
A hackerek folyamatosan új médiumokat keresnek, és csak találgatni tudjuk, hogy a hackerek a jövőben hogyan alkalmazzák az azonnali injekciós támadásokat. Megvédheti magát, ha mindig megfelelő mennyiségű vizsgálatot alkalmaz az MI-re. Ebben az AI-modellek hihetetlenül hasznosak, de fontos észben tartani, hogy van valami, amivel a mesterséges intelligencia nincs: az emberi ítélőképesség. Ne feledje, hogy alaposan meg kell vizsgálnia az olyan eszközöktől kapott eredményeket, mint a Copilot, és élvezze az AI-eszközök használatát, ahogy fejlődnek és fejlődnek.