
Tanuljon meg mindent, amit tudnia kell a feltáró adatelemzésről, egy kritikus folyamatról, amellyel trendeket és mintákat fedezhetünk fel, valamint statisztikai összefoglalók és grafikus ábrázolások segítségével összegezhetjük az adatkészleteket.
Mint minden projekt, az adattudományi projekt is hosszú folyamat, amely időt, jó szervezést és több lépés alapos tiszteletét igényli. A feltáró adatelemzés (EDA) ennek a folyamatnak az egyik legfontosabb lépése.
Ezért ebben a cikkben röviden megvizsgáljuk, mi az a feltáró adatelemzés, és hogyan végezheti el az R-vel!
Tartalomjegyzék
Mi az a feltáró adatelemzés?
A feltáró adatelemzés egy adathalmaz jellemzőit vizsgálja és tanulmányozza még azelőtt, hogy az alkalmazásba kerülne, legyen az kizárólag üzleti, statisztikai vagy gépi tanulás.
Az információ természetének és főbb sajátosságainak összefoglalása általában vizuális módszerekkel, például grafikus ábrázolással és táblázatokkal történik. A gyakorlatot előre pontosan azért végezzük, hogy felmérjük ezekben az adatokban rejlő lehetőségeket, amelyek a jövőben összetettebb kezelésben részesülnek.
Az EDA ezért lehetővé teszi:
- Állítson fel hipotéziseket ezen információk felhasználására;
- Fedezze fel az adatszerkezet rejtett részleteit;
- A hiányzó értékek, kiugró értékek vagy abnormális viselkedések azonosítása;
- Fedezze fel a trendeket és a releváns változókat összességében;
- Dobja el az irreleváns vagy másokkal korrelált változókat;
- Határozza meg a használandó formális modellezést!
Mi a különbség a leíró és a feltáró adatelemzés között?
Kétféle adatelemzés létezik, a leíró elemzés és a feltáró adatelemzés, amelyek kéz a kézben járnak, annak ellenére, hogy eltérő céljaik vannak.
Míg az első a változók viselkedésének leírására összpontosít, például átlag, medián, mód stb.
A feltáró elemzés célja, hogy azonosítsa a változók közötti kapcsolatokat, előzetes betekintést nyerjen, és a modellezést a leggyakoribb gépi tanulási paradigmákra irányítsa: osztályozás, regresszió és klaszterezés.
Általában mindkettő foglalkozhat grafikus ábrázolással; azonban csak a feltáró elemzés igyekszik cselekvőképes, vagyis a döntéshozót cselekvésre késztető meglátásokat hozni.
Végül, míg a feltáró adatelemzés a problémák megoldására törekszik, és olyan megoldásokat hoz, amelyek irányítják a modellezési lépéseket, a leíró elemzés, ahogy a neve is sugallja, csak a kérdéses adatkészlet részletes leírását célozza.
Leíró elemzés Feltáró adatelemzés Elemzi a viselkedést Elemzi a viselkedést és a kapcsolatokat Összefoglalást ad Specifikációhoz és műveletekhez vezet Adatokat táblázatokba és grafikonokba rendezi Adatokat táblázatokba és grafikonokba rendeziNincs jelentős magyarázó ereje Jelentős magyarázó ereje van
Az EDA néhány gyakorlati felhasználási esete
#1. Digitális marketing
A digitális marketing kreatív folyamatból adatvezérelt folyamattá fejlődött. A marketingszervezetek feltáró adatelemzést használnak a kampányok vagy erőfeszítések eredményeinek meghatározására, valamint a fogyasztói befektetési és célzási döntések irányítására.
A demográfiai tanulmányok, az ügyfelek szegmentálása és más technikák lehetővé teszik a marketingesek számára, hogy nagy mennyiségű fogyasztói vásárlási, felmérési és paneladatokat használjanak fel a stratégiai marketing megértéséhez és kommunikálásához.
A webes felfedező elemzés lehetővé teszi a marketingszakemberek számára, hogy munkamenet-szintű információkat gyűjtsenek a webhelyen zajló interakciókról. A Google Analytics egy példa a marketingesek erre a célra használt ingyenes és népszerű elemzőeszközére.
A marketingben gyakran használt feltáró technikák közé tartozik a marketingmix modellezése, az árképzés és promóció elemzése, az értékesítés optimalizálása és a feltáró ügyfélelemzés, például a szegmentálás.
#2. Feltáró portfólióelemzés
A feltáró adatelemzés gyakori alkalmazása a feltáró portfólióelemzés. Egy bank vagy hitelező ügynökség különböző értékű és kockázatú számlagyűjteménnyel rendelkezik.
A számlák eltérőek lehetnek a tulajdonos társadalmi státuszától (gazdag, középosztály, szegény stb.), földrajzi elhelyezkedésétől, nettó vagyonától és sok más tényezőtől függően. A hitelezőnek egyensúlyban kell tartania a kölcsön hozamát a nemteljesítés kockázatával minden egyes kölcsön esetében. A kérdés ezután az, hogy hogyan értékeljük a portfólió egészét.
Lehet, hogy a legalacsonyabb kockázatú hitel nagyon gazdag embereknek szól, de nagyon korlátozott számban vannak gazdagok. Másrészt sok szegény ember kölcsönözhet, de nagyobb kockázattal.
A feltáró adatelemzési megoldás kombinálhatja az idősoros elemzést sok más problémával annak eldöntésére, hogy mikor adjunk kölcsönt a hitelfelvevők különböző szegmenseinek, vagy milyen arányban kell kölcsönözni. A portfóliószegmens tagjait kamatot számítják fel az adott szegmens tagjai közötti veszteségek fedezésére.
#3. Feltáró kockázatelemzés
A banki szektorban előrejelző modelleket fejlesztenek ki, hogy bizonyosságot nyújtsanak az egyes ügyfelek kockázati pontszámairól. A kreditpontszámokat arra tervezték, hogy előre jelezzék az egyén bűnözői magatartását, és széles körben használják az egyes kérelmezők hitelképességének felmérésére.
Emellett kockázatelemzést végeznek a tudományos világban és a biztosítási ágazatban. A pénzintézetekben, például az online fizetési átjáró cégeknél is széles körben használják annak elemzésére, hogy egy tranzakció valódi-e vagy csalárd.
Erre a célra az ügyfél tranzakciós előzményeit használják fel. Gyakrabban használják hitelkártyás vásárlásoknál; Amikor hirtelen megugrik az ügyfél tranzakciós volumene, az ügyfél visszaigazoló hívást kap, ha ő kezdeményezte a tranzakciót. Segít csökkenteni az ilyen körülmények miatti veszteségeket is.
Feltáró adatelemzés R-vel
Az első dolog, amit az EDA-val végrehajtani kell, az R base és az R Studio (IDE) letöltése, majd a következő csomagok telepítése és betöltése:
#Installing Packages
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Loading Packages
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
Ebben az oktatóanyagban egy közgazdasági adatkészletet fogunk használni, amely az R-be van beépítve, és éves gazdasági mutatóadatokat biztosít az Egyesült Államok gazdaságáról, és az egyszerűség kedvéért megváltoztatjuk a nevét econ-ra:
econ <- ggplot2::economics
A leíró elemzés elvégzéséhez a skimr csomagot használjuk, amely ezeket a statisztikákat egyszerűen és jól bemutatott módon számítja ki:
#Descriptive Analysis skimr::skim(econ)

Az összefoglaló függvényt leíró elemzéshez is használhatja:
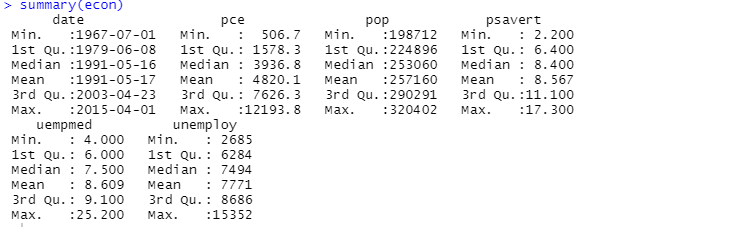
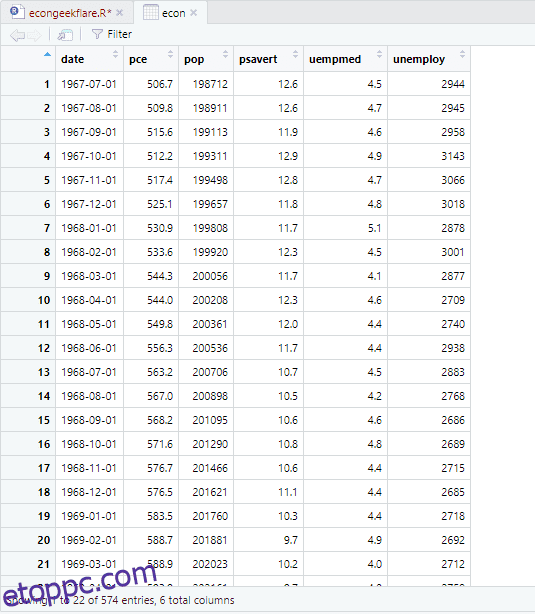
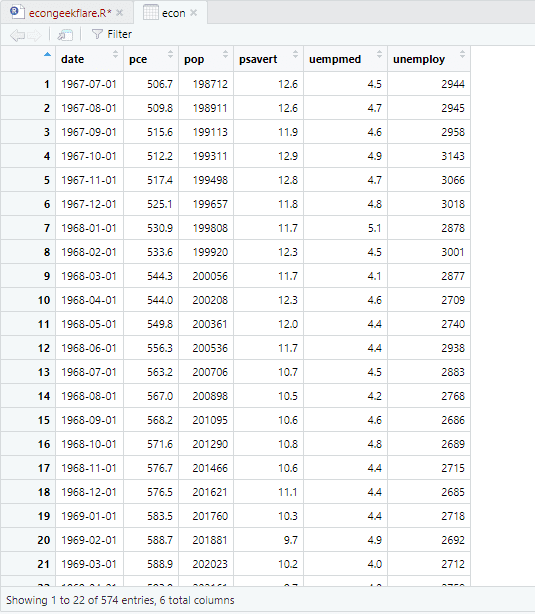
Itt a leíró elemzés 547 sort és 6 oszlopot mutat az adatkészletben. A minimális érték 1967-07-01, a maximum pedig 2015-04-01. Hasonlóképpen mutatja az átlagértéket és a szórást is.
Most már van egy alapötlete arról, hogy mi van az econ adatkészletben. Ábrázoljuk az uempmed változó hisztogramját, hogy jobban megnézhessük az adatokat:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
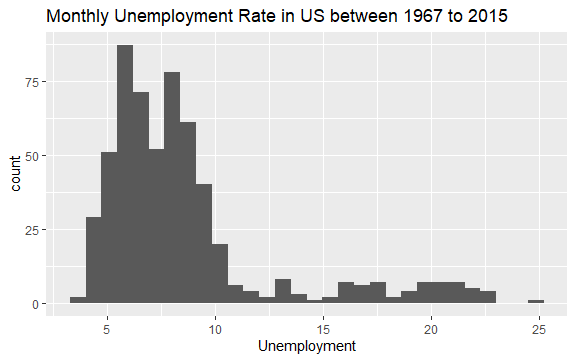
A hisztogram eloszlása azt mutatja, hogy a jobb oldalon megnyúlt farka van; vagyis esetleg van néhány megfigyelés erről a változóról, amelyeknek több „extrém” értéke van. Felmerül a kérdés: melyik időszakban történtek ezek az értékek, és mi a változó trendje?
A legközvetlenebb módja egy változó trendjének azonosításának egy vonaldiagramon keresztül. Az alábbiakban létrehozunk egy vonaldiagramot, és hozzáadunk egy simító vonalat:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
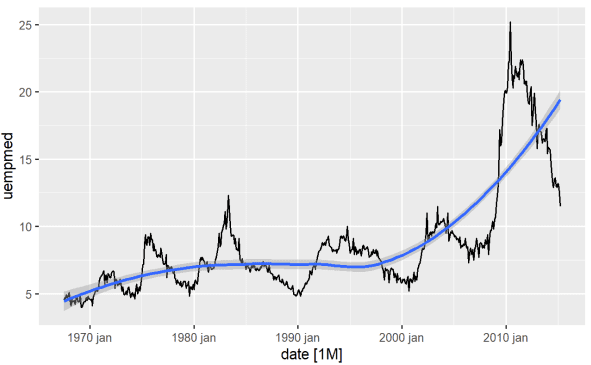
Ezen a grafikonon beazonosítható, hogy a legutóbbi időszakban, az utolsó, 2010-es megfigyelésekben a munkanélküliség növekedési tendenciája mutatkozik, meghaladja a korábbi évtizedekben megfigyelhető múltat.
Egy másik fontos szempont, különösen ökonometriai modellezési összefüggésekben, a sorozat stacionaritása; vagyis az átlag és a szórás időben állandó-e?
Ha ezek a feltevések nem igazak egy változóban, akkor azt mondjuk, hogy a sorozatnak egységgyöke (nem stacionárius) van, így a változót elszenvedő sokkok állandó hatást generálnak.
Úgy tűnik, ez volt a helyzet a kérdéses változó, a munkanélküliség időtartama esetében. Láttuk, hogy a változó ingadozása jelentősen megváltozott, aminek erős következményei vannak a ciklusokkal foglalkozó közgazdasági elméletekkel kapcsolatban. De az elmélettől eltérve, hogyan ellenőrizzük a gyakorlatban, hogy a változó stacionárius-e?
Az előrejelzési csomag kiváló funkcióval rendelkezik, amely lehetővé teszi olyan tesztek alkalmazását, mint például az ADF, KPSS és mások, amelyek már visszaadják a sorozat állóképességéhez szükséges eltérések számát:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")

Itt a 0,05-nél nagyobb p-érték azt mutatja, hogy az adatok nem stacionáriusak.
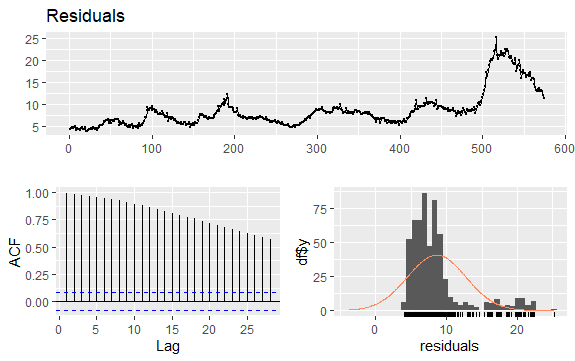
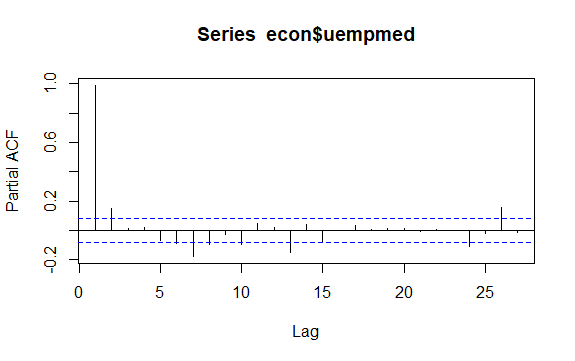
Az idősorok másik fontos kérdése a lehetséges korrelációk (a lineáris kapcsolat) azonosítása a sorozatok késleltetett értékei között. Az ACF és PACF korrelogramok segítenek azonosítani.
Mivel a sorozatnak nincs szezonalitása, de van egy bizonyos trendje, a kezdeti autokorrelációk általában nagyok és pozitívak, mivel az időben közel álló megfigyelések is közeli értékűek.
Így a trendezett idősorok autokorrelációs függvénye (ACF) általában pozitív értékekkel rendelkezik, amelyek lassan csökkennek a késések növekedésével.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed)
Következtetés
Amikor többé-kevésbé tiszta, vagyis már megtisztított adatokhoz jutunk, azonnal kedvünk támad a modellkészítés szakaszába merülni, hogy megrajzoljuk az első eredményeket. Ellen kell állnia ennek a kísértésnek, és el kell kezdenie a feltáró adatelemzést, amely egyszerű, de segít nekünk erőteljes betekintést nyerni az adatokba.
Felfedezhet néhány legjobb forrást a Data Science statisztikáinak megismeréséhez.