
A Reddit JSON-hírcsatornákat kínál minden egyes alreddithez. Így hozhat létre egy Bash-szkriptet, amely letölti és elemzi a bejegyzések listáját bármely tetszőleges subredditről. Ez csak egy dolog, amit megtehet a Reddit JSON-hírcsatornáival.
Tartalomjegyzék
A Curl és a JQ telepítése
A curl segítségével lekérjük a JSON-hírcsatornát a Redditből, a jq-t pedig a JSON-adatok elemzéséhez és a kívánt mezők kinyeréséhez az eredményekből. Telepítse ezt a két függőséget az apt-get segítségével az Ubuntu és más Debian-alapú Linux disztribúciókon. Más Linux-disztribúciók esetén használja inkább a disztribúció csomagkezelő eszközét.
sudo apt-get install curl jq
Szerezzen le néhány JSON-adatot a Redditből
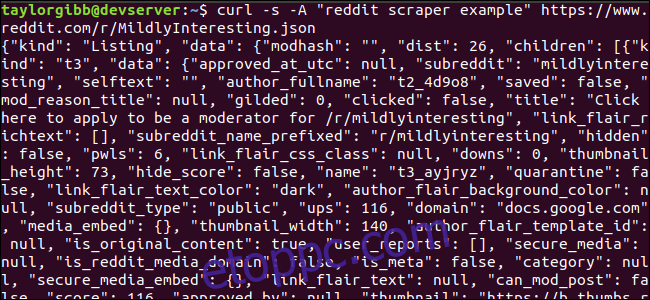
Nézzük meg, hogyan néz ki az adatfolyam. A curl használatával lekérheti a legújabb bejegyzéseket a Enyhén Érdekes subreddit:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json
Figyelje meg, hogy az URL előtt használt opciók: -s kényszerítik a curl-t néma módra, így nem látunk semmilyen kimenetet, kivéve a Reddit szervereiről származó adatokat. A következő beállítás és az azt követő paraméter, a „reddit scraper example” beállít egy egyéni felhasználói ügynök karakterláncot, amely segít a Redditnek azonosítani az adataihoz hozzáférő szolgáltatást. A Reddit API-kiszolgálók a felhasználói ügynök karakterlánca alapján sebességkorlátokat alkalmaznak. Egyéni érték beállítása azt eredményezi, hogy a Reddit elválasztja a sebességkorlátunkat a többi hívótól, és csökkenti annak esélyét, hogy HTTP 429-es sebességkorlát túllépve hibát kapunk.
A kimenetnek meg kell töltenie a terminál ablakát, és így kell kinéznie:
A kimeneti adatokban sok mező található, de minket csak a cím, az állandó hivatkozás és az URL érdekel. A típusok és mezőik kimerítő listája megtekinthető a Reddit API dokumentációs oldalán: https://github.com/reddit-archive/reddit/wiki/JSON
Adatok kinyerése a JSON-kimenetből
Ki akarjuk bontani a címet, az állandó hivatkozást és az URL-t a kimeneti adatokból, és elmenteni egy tabulátorral tagolt fájlba. Használhatunk szövegfeldolgozó eszközöket, például a sed-et és a grep-et, de rendelkezésünkre áll egy másik eszköz is, amely megérti a JSON-adatstruktúrákat, a jq. Első próbálkozásunkban használjuk a kimenet szép nyomtatására és színkódolására. Ugyanazt a hívást fogjuk használni, mint korábban, de ezúttal vezesse át a kimenetet a jq-n keresztül, és utasítsa a JSON-adatok elemzésére és kinyomtatására.
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq .
Jegyezze fel a parancsot követő időszakot. Ez a kifejezés egyszerűen elemzi a bemenetet, és kinyomtatja úgy, ahogy van. A kimenet szépen formázott és színkódolt:
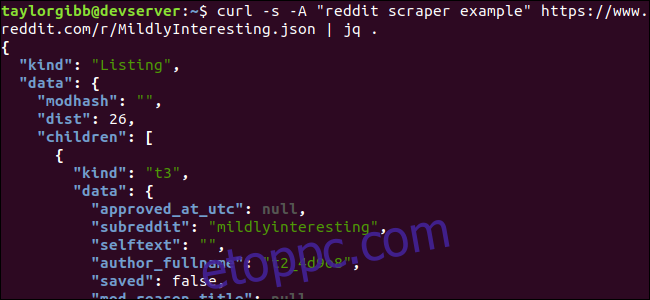
Vizsgáljuk meg a Reddittől visszakapott JSON-adatok szerkezetét. A gyökéreredmény egy objektum, amely két tulajdonságot tartalmaz: fajtát és adatot. Ez utóbbi rendelkezik egy children nevű tulajdonsággal, amely egy sor bejegyzést tartalmaz ehhez a subreddithez.
A tömb minden eleme egy objektum, amely két mezőt is tartalmaz, úgynevezett kind és data. A megragadni kívánt tulajdonságok az adatobjektumban vannak. A jq olyan kifejezést vár, amely alkalmazható a bemeneti adatokra, és előállítja a kívánt kimenetet. Le kell írnia a tartalmat a hierarchiájuk és a tömbhöz való tagságuk szempontjából, valamint azt, hogy az adatokat hogyan kell átalakítani. Futtassuk újra az egész parancsot a megfelelő kifejezéssel:
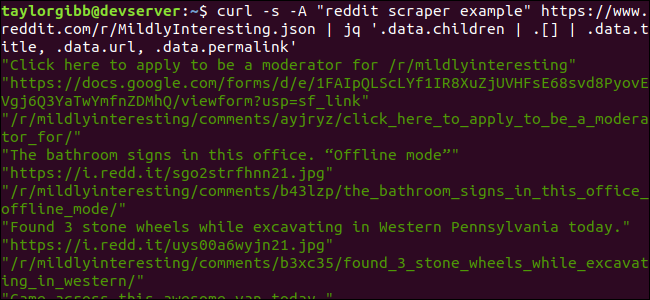
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
A kimenet a címet, az URL-t és az állandó hivatkozást mutatja a saját sorában:
Merüljünk el a jq parancsban, amelyet hívtunk:
jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
Ebben a parancsban három kifejezés található, amelyeket két csőszimbólum választ el. Az egyes kifejezések eredményeit továbbítjuk a következőnek további értékelés céljából. Az első kifejezés mindent kiszűr, kivéve a Reddit listák tömbjét. Ez a kimenet a második kifejezésbe kerül, és egy tömbbe kerül. A harmadik kifejezés a tömb minden elemére hat, és három tulajdonságot von ki. További információ a jq-ról és kifejezési szintaxisáról itt található jq hivatalos kézikönyve.
Mindezt egy forgatókönyvben
Tegyük össze az API-hívást és a JSON-utófeldolgozást egy szkriptben, amely létrehoz egy fájlt a kívánt bejegyzésekkel. Támogatjuk a bejegyzések letöltését bármilyen subredditről, nem csak az /r/MildlyInteresting fájlból.
Nyissa meg a szerkesztőt, és másolja a részlet tartalmát egy scrape-reddit.sh nevű fájlba
#!/bin/bash
if [ -z "$1" ]
then
echo "Please specify a subreddit"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}t${URL}t${PERMALINK}" | tr --delete " >> ${OUTPUT_FILE}
done
Ez a szkript először ellenőrzi, hogy a felhasználó megadott-e subreddit nevet. Ha nem, akkor hibaüzenettel és nullától eltérő visszatérési kóddal lép ki.
Ezután az első argumentumot subreddit névként tárolja, és létrehoz egy dátumbélyegzett fájlnevet, amelybe a kimenetet menti.
A művelet akkor kezdődik, amikor a curl meghívásra kerül egy egyéni fejléccel és a scrappeni kívánt subreddit URL-jével. A kimenet a jq-ba kerül, ahol elemzi, és három mezőre redukálódik: Cím, URL és állandó hivatkozás. Ezeket a sorokat egyesével beolvassa, és a read paranccsal változóba menti, mindezt egy while cikluson belül, amely addig folytatódik, amíg már nem lesz több olvasandó sor. A belső while blokk utolsó sora visszaadja a három mezőt, amelyeket egy tabulátor karakter határol el, majd átvezeti a tr parancson, így a dupla idézőjelek kihúzhatók. A kimenetet ezután egy fájlhoz fűzzük.
Mielőtt végrehajtanánk ezt a szkriptet, meg kell győződnünk arról, hogy megkapta a végrehajtási engedélyeket. Használja a chmod parancsot a következő engedélyek alkalmazásához a fájlra:
chmod u+x scrape-reddit.sh
És végül futtassa a szkriptet egy subreddit névvel:
./scrape-reddit.sh MildlyInteresting
A kimeneti fájl ugyanabban a könyvtárban jön létre, és a tartalma így fog kinézni:
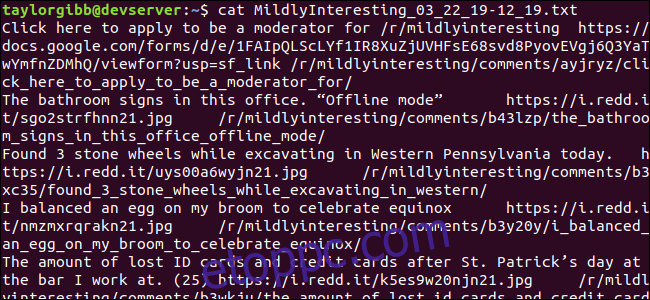
Minden sor tartalmazza azt a három mezőt, amelyet keresünk, tabulátor karakterrel elválasztva.
Tovább haladva
A Reddit érdekes tartalmak és médiák aranybánya, és mindez könnyen elérhető a JSON API segítségével. Most, hogy hozzáférhet ezekhez az adatokhoz és feldolgozhatja az eredményeket, a következőket teheti:
Fogja meg a /r/WorldNews legfrissebb főcímeit, és küldje el őket az asztalra a használatával értesít-küld
Integrálja a /r/DadJokes legjobb poénjait a rendszere Napi Üzenetébe
Szerezze meg napjaink legjobb képét az /r/aww fájlból, és tegye asztali hátterévé
Mindez lehetséges a megadott adatok és a rendszerén lévő eszközök segítségével. Boldog hackelést!