

Az adatkinyerés az a folyamat, amikor konkrét adatokat gyűjtenek a weboldalakról. A felhasználók szövegeket, képeket, videókat, ismertetőket, termékeket stb. bonthatnak ki. Adatok kinyerésével piackutatást, hangulatelemzést, versenyelemzést és összesített adatokat végezhet.
Ha kis mennyiségű adattal van dolga, manuálisan is kivonhatja az adatokat úgy, hogy a konkrét információkat a weboldalakról egy tetszőleges táblázatba vagy dokumentumformátumba másolja be. Ha például vásárlóként online véleményeket keres a vásárlási döntés meghozatalához, manuálisan törölheti az adatokat.
Másrészt, ha nagy adathalmazokkal van dolgunk, akkor automatizált adatkinyerési technikára van szüksége. Létrehozhat házon belüli adatkinyerési megoldást, vagy használhat Proxy API-t vagy Scraping API-t az ilyen feladatokhoz.
Előfordulhat azonban, hogy ezek a technikák kevésbé hatékonyak, mivel egyes megcélzott webhelyeket captchas védheti. Előfordulhat, hogy a robotokat és a proxykat is kezelnie kell. Az ilyen feladatok az idő nagy részét igénybe vehetik, és korlátozzák a kinyerhető tartalom jellegét.
Tartalomjegyzék
Scraping Browser: A megoldás
Ezeket a kihívásokat leküzdheti a Bright Data Scraping Browser segítségével. Ez a többfunkciós böngésző segít adatokat gyűjteni olyan webhelyekről, amelyeket nehéz lekaparni. Ez egy grafikus felhasználói felületet (GUI) használó böngésző, amelyet a Puppeteer vagy a Playwright API vezérel, így a robotok nem észlelhetik.
A Scraping Browser beépített feloldó funkciókkal rendelkezik, amelyek automatikusan kezelik az összes blokkot az Ön nevében. A böngésző a Bright Data szerverein nyílik meg, ami azt jelenti, hogy nincs szükség drága házon belüli infrastruktúrára ahhoz, hogy nagyszabású projektjeihez adatokat selejtezzen.
A Bright Data Scraping Browser jellemzői
- Automatikus webhely-feloldás: Nem kell folyamatosan frissítenie a böngészőt, mivel ez a böngésző automatikusan alkalmazkodik a CAPTCHA-megoldás, az új blokkok, az ujjlenyomatok és az újrapróbálkozások kezelésére. A Scraping Browser valódi felhasználót utánoz.
- Nagy proxyhálózat: Bármelyik országot megcélozhatja, mivel a Scraping Browser több mint 72 millió IP-vel rendelkezik. Célozhat városokat vagy akár szolgáltatókat, és profitálhat a kategória legjobb technológiájából.
- Skálázható: Több ezer munkamenetet nyithat meg egyszerre, mivel ez a böngésző a Bright Data infrastruktúrát használja az összes kérés kezelésére.
- Puppeteer és Playwright kompatibilis: Ez a böngésző lehetővé teszi API-hívások kezdeményezését és tetszőleges számú böngészőmunka lekérését a Puppeteer (Python) vagy a Playwright (Node.js) használatával.
- Időt és erőforrásokat takarít meg: Ahelyett, hogy proxykat állítana be, a Scraping Browser mindenről gondoskodik a háttérben. Nem kell házon belüli infrastruktúrát sem kiépíteni, hiszen ez az eszköz a háttérben mindent elintéz.
A Scraping Browser beállítása
- Menjen a Bright Data webhelyre, és kattintson a Scraping Browser elemre a „Scraping Solutions” lapon.
- Hozzon létre egy fiókot. Két lehetőséget fog látni; „Ingyenes próbaverzió indítása” és „Ingyenes indítás a Google-lal”. Most válasszuk az „Ingyenes próbaidőszak indítása” lehetőséget, és lépjünk a következő lépésre. A fiókot manuálisan is létrehozhatja, vagy használhatja Google-fiókját.
- Fiókja létrehozásakor az irányítópult számos lehetőséget kínál. Válassza a „Proxyk és Scraping Infrastructure” lehetőséget.
- A megnyíló új ablakban válassza a Scraping Browser lehetőséget, és kattintson a „Kezdés” gombra.
- Mentse és aktiválja a konfigurációkat.
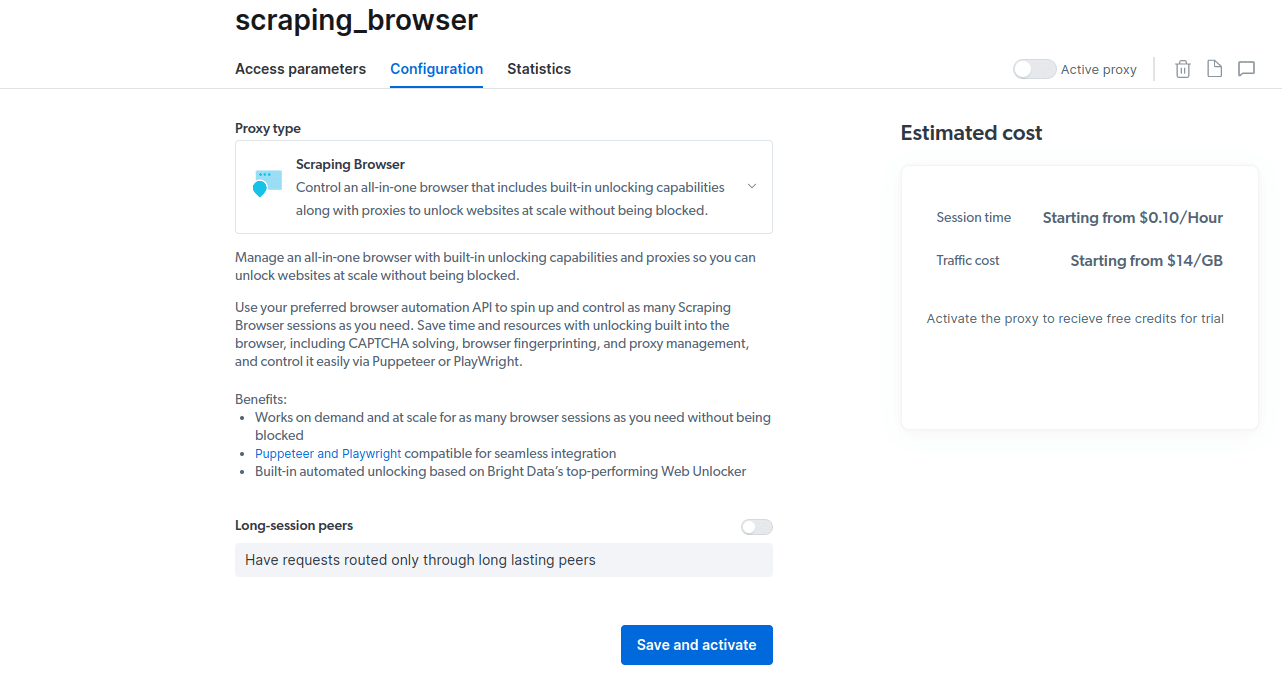
- Aktiválja az ingyenes próbaidőszakot. Az első lehetőség 5 USD jóváírást biztosít, amelyet a proxy használatára fordíthat. Kattintson az első lehetőségre a termék kipróbálásához. Ha azonban erős felhasználó, rákattinthat a második lehetőségre, amely 50 dollárt ad ingyen, ha 50 dollárral vagy többel tölti fel fiókját.
- Adja meg számlázási adatait. Ne aggódjon, mivel a platform nem számít fel Önnek semmit. A számlázási információk több fiók létrehozásával csak azt igazolják, hogy Ön új felhasználó, és nem keres ingyenes ajándékokat.
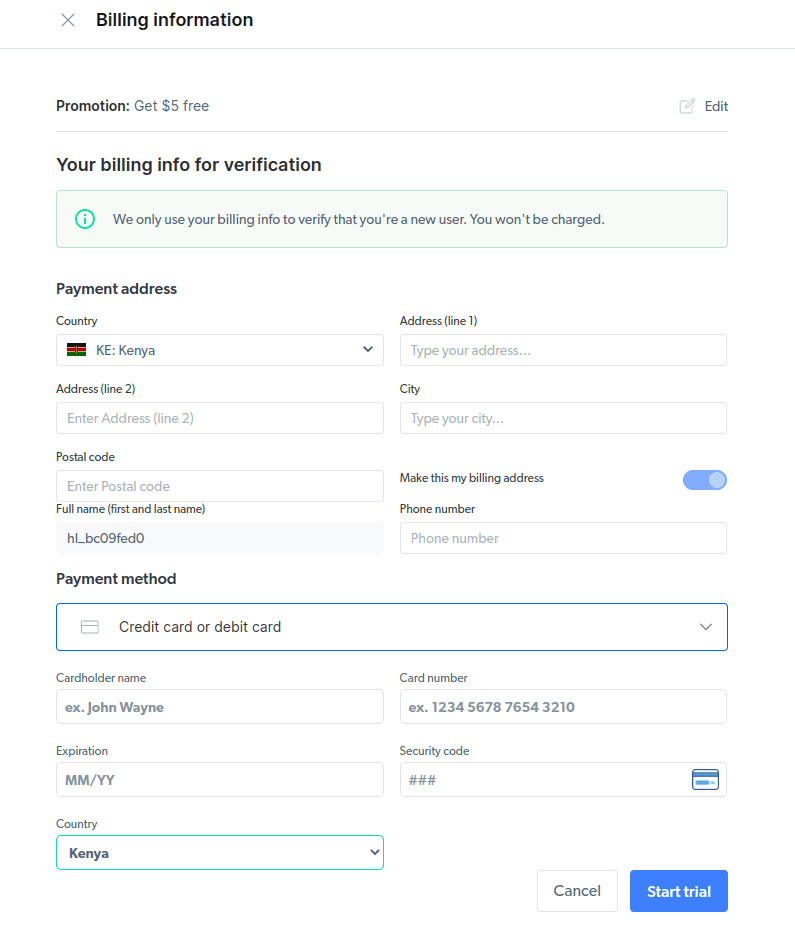
- Hozzon létre egy új proxyt. Miután elmentette számlázási adatait, létrehozhat egy új proxyt. Kattintson a „hozzáadás” ikonra, és válassza ki a Scraping Browser-t „Proxytípusként”. Kattintson a „Proxy hozzáadása” gombra, és lépjen a következő lépésre.
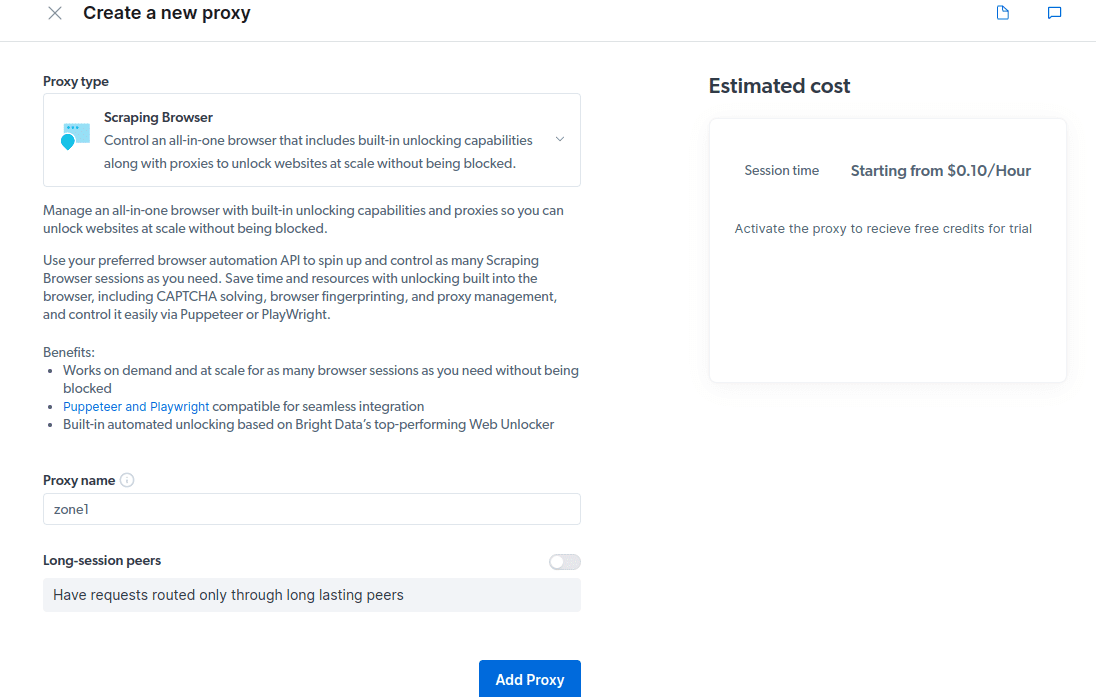
- Hozzon létre egy új „zónát”. Megjelenik egy előugró ablak, amely megkérdezi, hogy kíván-e új zónát létrehozni; kattintson az „Igen” gombra, és folytassa.
- Kattintson a „Nézze meg a kódot és az integrációs példákat” elemre. Most olyan proxy-integrációs példákat kap, amelyek segítségével adatokat törölhet a cél webhelyről. A Node.js vagy a Python segítségével adatokat nyerhet ki a célwebhelyről.
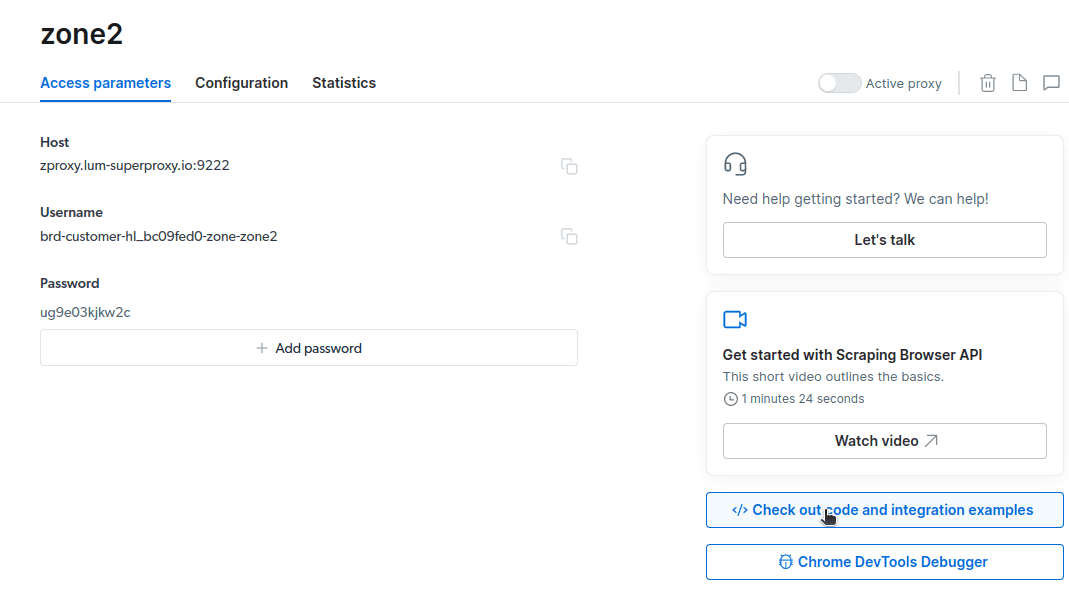
Most már mindent megtalál, amire szüksége van az adatok kinyeréséhez egy webhelyről. Weboldalunkat (etoppc.com.com) használjuk a Scraping Browser működésének bemutatására. Ehhez a bemutatóhoz a node.js fájlt fogjuk használni. Követheti, ha telepítve van a node.js.
Kovesd ezeket a lepeseket;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
A 10. sorban lévő kódomat a következőre módosítom;
várjon page.goto(‘https://etoppc.com.com/authors/‘);
A végső kódom most ez lesz;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://etoppc.com.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
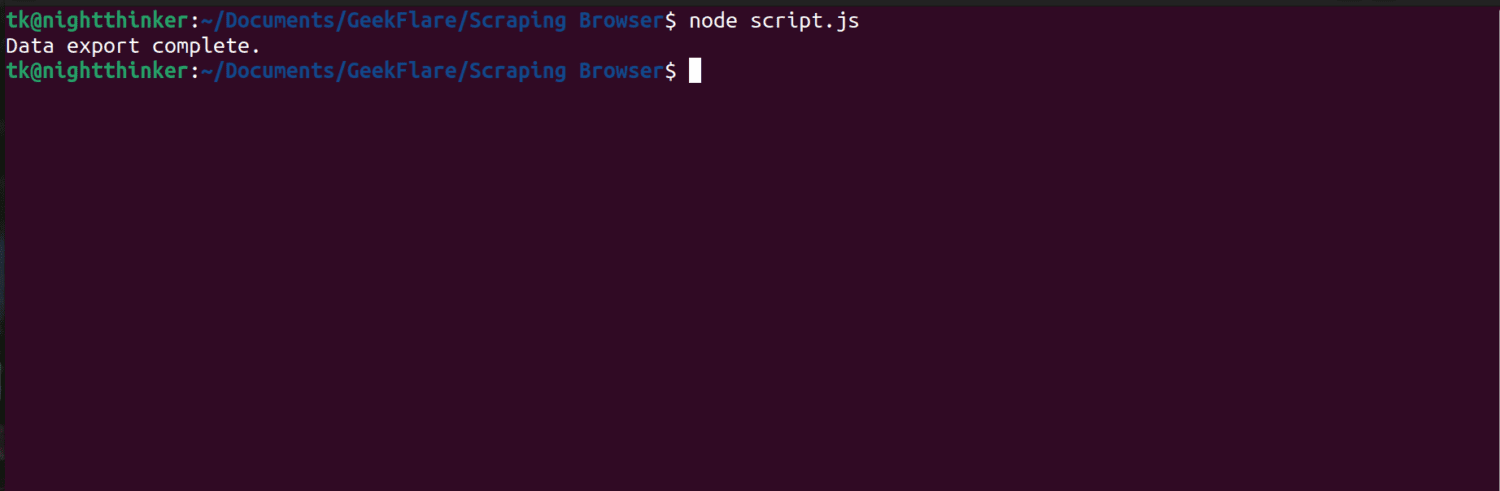
node script.js
Valami ehhez hasonló lesz a terminálján
Az adatok exportálása
Az adatok exportálására többféle módszert is használhat, attól függően, hogy hogyan kívánja használni azokat. Ma már exportálhatjuk az adatokat egy html fájlba úgy, hogy megváltoztatjuk a szkriptet, hogy létrehozzunk egy új fájlt data.html néven, ahelyett, hogy a konzolra nyomtatnánk.
A kódja tartalmát az alábbiak szerint módosíthatja;
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://etoppc.com.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Most már futtathatja a kódot ezzel a paranccsal;
node script.js
Amint az a következő képernyőképen látható, a terminál egy üzenetet jelenít meg, amely azt mondja: „Az adatok exportálása befejeződött”.
Ha megnézzük a projektmappánkat, most egy data.html nevű fájlt láthatunk több ezer sornyi kóddal.
Nemrég megkapartam, hogyan lehet adatokat kinyerni a Scraping böngészővel. Ezzel az eszközzel akár csak a szerzők nevét és leírását is szűkíthetem és törölhetem.
Ha használni szeretné a Scraping Browser-t, azonosítsa a kivonatolni kívánt adatkészleteket, és ennek megfelelően módosítsa a kódot. A megcélzott webhelytől és a HTML-fájl szerkezetétől függően szöveget, képeket, videókat, metaadatokat és hivatkozásokat bonthat ki.
GYIK
Legális az adatkinyerés és a webkaparás?
A webkaparás ellentmondásos téma, az egyik csoport szerint ez erkölcstelen, míg mások szerint ez rendben van. A webkaparás jogszerűsége a kimásolt tartalom természetétől és a cél weboldal szabályzatától függ.
Általában illegálisnak minősül az adatok személyes adatokkal, például címekkel és pénzügyi adatokkal való lekaparása. Az adatok törlése előtt ellenőrizze, hogy a megcélzott webhely rendelkezik-e irányelvekkel. Mindig ügyeljen arra, hogy ne törölje le azokat az adatokat, amelyek nem nyilvánosak.
A Scraping Browser ingyenes eszköz?
Nem. A Scraping Browser fizetős szolgáltatás. Ha ingyenes próbaidőszakra regisztrál, az eszköz 5 USD jóváírást biztosít Önnek. A fizetős csomagok 15 USD/GB + 0,1 USD/óra ártól indulnak. Választhatja a felosztó-kirovó opciót is, amelynek ára 20 USD/GB + 0,1 USD/óra.
Mi a különbség a Scraping böngészők és a fej nélküli böngészők között?
A Scraping Browser egy fejtörő böngésző, ami azt jelenti, hogy grafikus felhasználói felülettel (GUI) rendelkezik. Másrészt a fej nélküli böngészőknek nincs grafikus felülete. A fej nélküli böngészőket, például a Seleniumot a webkaparás automatizálására használják, de néha korlátozottak, mivel foglalkozniuk kell a CAPTCHA-val és a botfelismeréssel.
Becsomagolás
Mint látható, a Scraping Browser leegyszerűsíti az adatok kinyerését a weboldalakról. A Scraping Browser használata egyszerű az olyan eszközökhöz képest, mint a Selenium. Még a nem fejlesztők is használhatják ezt a fantasztikus felhasználói felülettel és jó dokumentációval rendelkező böngészőt. Az eszköz olyan feloldási képességekkel rendelkezik, amelyek más selejtező eszközökben nem érhetők el, így mindenki számára hatékony, aki automatizálni szeretné az ilyen folyamatokat.
Azt is megvizsgálhatja, hogyan akadályozhatja meg, hogy a ChatGPT beépülő modulok lekaparják webhelye tartalmát.