
Évekkel ezelőtt, amikor a nagy fájlrendszerekkel rendelkező, helyszíni Unix-kiszolgálók népszerűek voltak, a vállalatok kiterjedt mappakezelési szabályokat és stratégiákat dolgoztak ki a különböző mappák hozzáférési jogainak adminisztrálására különböző személyek számára.
Általában egy szervezet platformja különböző felhasználói csoportokat szolgál ki teljesen eltérő érdeklődési körökkel, titoktartási szintű korlátozásokkal vagy tartalomdefiníciókkal. Ez a globális szervezetek esetében akár a tartalom hely szerinti szétválasztását is jelentheti, tehát alapvetően a különböző országokhoz tartozó felhasználók között.
További jellemző példák lehetnek:
- az adatok szétválasztása a fejlesztési, tesztelési és éles környezet között
- széles közönség számára nem elérhető értékesítési tartalom
- országspecifikus jogszabályi tartalom, amely más régión belül nem látható vagy nem érhető el
- projekthez kapcsolódó tartalom, ahol a „vezetői adatokat” csak emberek korlátozott csoportja számára kell megadni stb.
Az ilyen példák végtelen listája létezik. A lényeg az, hogy mindig szükség van a fájlok és adatok hozzáférési jogainak összehangolására azon felhasználók között, akikhez a platform hozzáférést biztosít.
Az on-premise megoldások esetében ez rutinfeladat volt. A fájlrendszer adminisztrátora csak beállított néhány szabályt, egy választott eszközt használt, majd az embereket felhasználói csoportokba, a felhasználói csoportokat pedig azoknak a mappáknak vagy beillesztési pontoknak a listájába képezte le, amelyekhez hozzáférhetnek. Az út során a hozzáférés szintjét csak olvasási vagy írási és olvasási hozzáférésként határozták meg.
Az AWS felhőplatformjait vizsgálva nyilvánvaló, hogy az embereknek hasonló követelményeket kell támasztaniuk a tartalom-hozzáférési korlátozásokkal kapcsolatban. A probléma megoldásának azonban most másnak kell lennie. A fájlok már nem a Unix szervereken, hanem a felhőben állnak (és potenciálisan nem csak az egész szervezet, de akár az egész világ számára is elérhetők), a tartalmat pedig nem mappákban, hanem S3 tárolókban tárolják.

Az alábbiakban bemutatunk egy alternatívát a probléma megoldására. Azon a valós tapasztalatokon alapul, amelyeket egy konkrét projekthez hasonló megoldások tervezése során szereztem.
Tartalomjegyzék
Egyszerű, de nagymértékben kézi megközelítés
A probléma automatizálás nélküli megoldásának egyik módja viszonylag egyszerű és egyszerű:
- Hozzon létre egy új csoportot minden egyes embercsoport számára.
- Rendeljen hozzáférési jogokat a tárolóhoz, hogy csak ez a csoport férhessen hozzá az S3 tárolóhoz.
Ez minden bizonnyal lehetséges, ha a követelmény nagyon egyszerű és gyors megoldás. Vannak azonban bizonyos korlátok, amelyekkel tisztában kell lenni.
Alapértelmezés szerint legfeljebb 100 S3-csoport hozható létre egy AWS-fiók alatt. Ez a limit 1000-re bővíthető, ha az AWS jegyhez szolgáltatási limitemelést kell benyújtani. Ha ezek a korlátok nem olyanok, amelyek miatt az Ön konkrét megvalósítási esete aggodalomra ad okot, akkor megengedheti, hogy minden egyes domain felhasználója külön S3-csoporton működjön, és hívja azt naponta.
A problémák akkor merülhetnek fel, ha vannak olyan embercsoportok, akiknek több funkciója is van, vagy egyszerűen csak néhány embernek van szüksége egyszerre több tartomány tartalmához. Például:
- Az adatelemzők több különböző területre, régióra stb. értékelik az adattartalmat.
- A tesztelő csapat különböző fejlesztőcsapatokat kiszolgáló szolgáltatásokat osztott meg.
- Azon felhasználók bejelentése, akiknek irányítópult-elemzést kell készíteniük az ugyanazon régión belüli különböző országokról.
Elképzelhető, hogy ez a lista ismét olyan mértékben bővülhet, amennyire csak el tudja képzelni, és a szervezetek igényei mindenféle használati esetet generálhatnak.
Minél összetettebb lesz ez a lista, annál összetettebb hozzáférési jogok összehangolására lesz szükség ahhoz, hogy ezeknek a különböző csoportoknak különböző hozzáférési jogokat adjunk a szervezet különböző S3-csoportjaihoz. Szükség lesz további eszközökre, és talán még egy dedikált erőforrásnak (rendszergazdának) is szüksége lesz a hozzáférési jogok listáinak karbantartására és frissítésére, amikor bármilyen változtatást kérnek (ami nagyon gyakran előfordul, különösen, ha a szervezet nagy).
Tehát hogyan lehet ugyanazt szervezettebb és automatizáltabb módon elérni?
Ha a gyűjtőzónánkénti megközelítés nem működik, minden más megoldás több felhasználói csoport számára megosztott gyűjtőkhöz vezet. Ilyen esetekben a hozzáférési jogok hozzárendelésének teljes logikáját fel kell építeni egy olyan területen, amely könnyen módosítható vagy dinamikusan frissíthető.
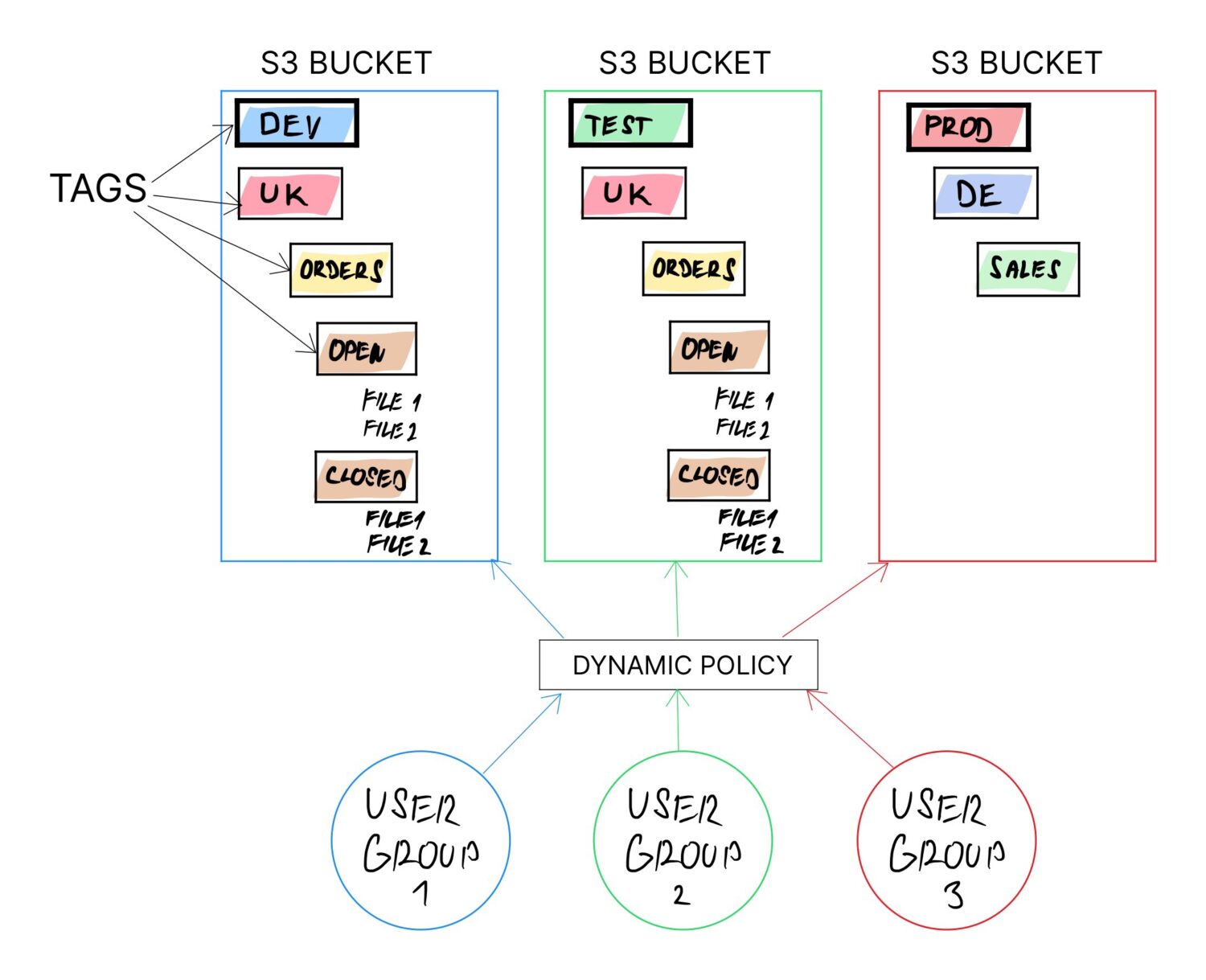
Ennek elérésének egyik módja a címkék használata az S3 vödrökön. A címkéket minden esetben javasolt használni (ha nem más, mint a számlázás egyszerűbb kategorizálása). A címke azonban a jövőben bármikor módosítható bármely gyűjtőhelyen.
Ha a teljes logika a vödör címkéire épül, a többi mögötte pedig a címkeértékektől függő konfiguráció, akkor a dinamikus tulajdonság garantált, mivel a címkeértékek frissítésével újradefiniálható a vödör célja.
Milyen címkéket kell használni, hogy ez működjön?
Ez a konkrét felhasználási esettől függ. Például:
- Szükség lehet környezettípusonkénti gyűjtőzónák elkülönítésére. Tehát ebben az esetben az egyik címkenévnek olyasminek kell lennie, mint az „ENV”, és a lehetséges értékekkel: „DEV”, „TEST”, „PROD” stb.
- Talán az ország alapján szeretné szétválasztani a csapatot. Ebben az esetben egy másik címke „COUNTRY” lesz, és valamilyen országnevet jelent.
- Vagy érdemes szétválasztani a felhasználókat a funkcionális részleg alapján, amelyhez tartoznak, például üzleti elemzők, adattárház-felhasználók, adattudósok stb. Így létrehoz egy címkét a „USER_TYPE” névvel és a megfelelő értékkel.
- Egy másik lehetőség lehet, hogy explicit módon szeretne fix mappastruktúrát definiálni bizonyos felhasználói csoportok számára, amelyeket használniuk kell (hogy ne hozzon létre saját mappákat, és ne vesszen el ott idővel). Ezt ismét megteheti címkékkel, ahol több munkakönyvtárat is megadhat, például: „data/import”, „data/processed”, „data/error” stb.
Ideális esetben úgy szeretné meghatározni a címkéket, hogy logikusan kombinálhatók legyenek, és egy teljes mappastruktúrát alkossanak a vödörben.
Például kombinálhatja a fenti példák következő címkéit, hogy létrehozzon egy dedikált mappastruktúrát a különböző országok különböző típusú felhasználók számára, előre meghatározott import mappákkal, amelyeket várhatóan használni fognak:
- /
/ / /
Csak az
Ez lehetővé teszi, hogy ugyanazt a vödröt több különböző felhasználó is használja. A csoportok nem támogatják kifejezetten a mappákat, de támogatják a „címkéket”. Ezek a címkék végül almappákként működnek, mert a felhasználóknak egy sor címkén kell keresztülmenniük ahhoz, hogy elérjék adataikat (akárcsak az almappák esetében).
Miután meghatározta a címkéket valamilyen használható formában, a következő lépés az S3 vödör házirendek felépítése, amelyek a címkéket használják.
Ha a házirendek a címkeneveket használják, akkor valami úgynevezett „dinamikus házirendet” hoz létre. Ez alapvetően azt jelenti, hogy a házirend másként fog viselkedni a különböző címkeértékekkel rendelkező gyűjtőknél, amelyekre az irányelv űrlapon vagy helyőrzőként hivatkozik.
Ez a lépés nyilvánvalóan magában foglalja a dinamikus házirendek egyéni kódolását, de ezt a lépést leegyszerűsítheti az Amazon AWS házirend-szerkesztő eszközével, amely végigvezeti a folyamaton.
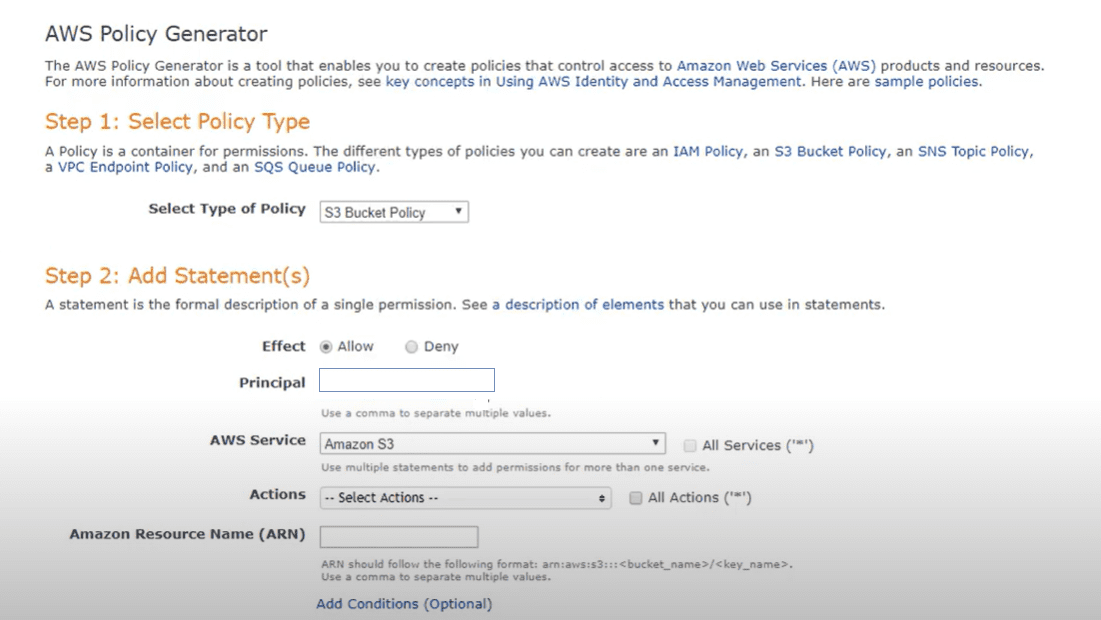
Magában a házirendben konkrét hozzáférési jogokat kell kódolni, amelyeket alkalmazni kell a gyűjtőhelyre, és az ilyen jogok hozzáférési szintjét (olvasás, írás). A logika beolvassa a vödrök címkéit, és felállítja a mappaszerkezetet a tárolón (címkéket hoz létre a címkék alapján). A címkék konkrét értékei alapján létrejönnek az almappák, és a sor mentén hozzárendeljük a szükséges hozzáférési jogokat.
Egy ilyen dinamikus irányelvben az a szép, hogy létrehozhat egyetlen dinamikus házirendet, majd ugyanazt a dinamikus házirendet több gyűjtőcsoporthoz rendelheti. Ez az irányelv eltérően fog viselkedni a különböző címkeértékekkel rendelkező gyűjtőknél, de mindig megfelel az ilyen címkeértékekkel rendelkező gyűjtőcsoportok elvárásainak.
Ez egy igazán hatékony módja a hozzáférési jogosultság-hozzárendelések szervezett, központosított kezelésének nagyszámú gyűjtőhelyen, ahol az elvárás, hogy minden gyűjtőkör kövesse bizonyos sablonstruktúrákat, amelyekről előzetesen megállapodtak, és amelyeket a felhasználók használni fognak. az egész szervezetet.
Automatizálja az új entitások bevezetését
A dinamikus házirendek meghatározása és a meglévő gyűjtőhelyekhez való hozzárendelése után a felhasználók elkezdhetik ugyanazokat a gyűjtőket használni anélkül, hogy a különböző csoportokhoz tartozó felhasználók nem fognak hozzáférni egy olyan mappastruktúra alatt található (ugyanazon a tárolóban tárolt) tartalomhoz, ahol nincs hozzáférés.
Ezenkívül egyes szélesebb hozzáférésű felhasználói csoportok számára könnyű lesz elérni az adatokat, mivel azokat ugyanabban a tárolóban tárolják.
Az utolsó lépés az, hogy a lehető legegyszerűbbé tegyük az új felhasználók, új csoportok és még új címkék felvételét. Ez egy másik egyéni kódoláshoz vezet, aminek azonban nem kell túl bonyolultnak lennie, feltételezve, hogy a bevezetési folyamatnak vannak nagyon világos szabályai, amelyek egyszerű, egyértelmű algoritmuslogikával beágyazhatók (legalábbis bizonyíthatja így, hogy a a folyamatnak van némi logikája, és nem túl kaotikus módon történik).
Ez olyan egyszerű lehet, mint egy AWS CLI paranccsal végrehajtható parancsfájl létrehozása az új entitás platformon való sikeres beépítéséhez szükséges paraméterekkel. Ez lehet akár CLI-szkriptek sorozata is, amelyek bizonyos sorrendben futtathatók, például:
- create_new_bucket(
, , , , ..) - create_new_tag(
, , ) - update_existing_tag(
, , ) - create_user_group(
, , ) - stb.
Érted a lényeget. 😃
Profi tipp 👨💻
Ha tetszik, van egy Pro Tipp, amelyet a fentieken felül egyszerűen fel lehet helyezni.
A dinamikus házirendek nem csak a mappahelyekhez való hozzáférési jogok hozzárendelésére használhatók, hanem a gyűjtőhelyek és felhasználói csoportok szolgáltatási jogainak automatikus hozzárendelésére is!
Csak ki kell bővíteni a gyűjtőhelyeken található címkék listáját, majd dinamikus házirend-hozzáférési jogokat kell hozzáadni, hogy meghatározott szolgáltatásokat használhassanak a felhasználók konkrét csoportjai számára.
Például előfordulhat, hogy a felhasználók egy csoportja hozzá kell férnie az adott adatbázis-fürtkiszolgálóhoz. Ez kétségtelenül elérhető dinamikus politikákkal, amelyek kihasználják a csoportos feladatokat, még inkább, ha a szolgáltatásokhoz való hozzáférést szerepalapú megközelítés vezérli. Csak adjon hozzá a dinamikus házirend kódhoz egy részt, amely feldolgozza az adatbázis-fürt specifikációival kapcsolatos címkéket, és közvetlenül hozzárendeli a házirend-hozzáférési jogosultságokat az adott DB-fürthöz és felhasználói csoporthoz.
Ily módon egy új felhasználói csoport felvétele csak ezen egyetlen dinamikus házirend által lesz végrehajtható. Ezen túlmenően, mivel dinamikus, ugyanazt a házirendet újra fel lehet használni sok különböző felhasználói csoport bevonására (amelyek várhatóan ugyanazt a sablont követik, de nem feltétlenül ugyanazokat a szolgáltatásokat).
Tekintse meg ezeket az AWS S3 parancsokat is a tárolók és adatok kezelésére.