Bereiten Sie sich darauf vor, tief in die Welt der Datenbanken der nächsten Generation einzutauchen: Serverlose Datenbanken stehen im Mittelpunkt!
Eine Datenbank, die auf den grundlegenden Prinzipien des Serverless Computing basiert, wird als serverlose Datenbank bezeichnet. Diese Art von Datenbank wurde speziell für Workloads konzipiert, die durch Unvorhersehbarkeit und schnelle Veränderungen gekennzeichnet sind.
Serverlos bedeutet jedoch nicht, dass Server überflüssig sind. Vielmehr bedeutet es, dass Sie die zugrunde liegende Serverinfrastruktur weder selbst verwalten noch bereitstellen oder dafür bezahlen müssen.
Stattdessen erfolgt die Abrechnung der genutzten Ressourcen anhand der tatsächlichen CPU- und RAM-Kapazität sowie der Aktivität.
So funktionieren serverlose Datenbanken
Das Prinzip der serverlosen Datenbank basiert auf der klaren Trennung von Verarbeitung und Datenspeicherung. Zunächst definieren Sie einen Endpunkt sowie die Mindest- und Maximalkapazitäten.
Bildquelle: Simform
An diesen Endpunkt können Sie dann Abfragen senden. Dieser Proxy agiert als Bindeglied zu einer Vielzahl von Datenbankressourcen. So bleiben Ihre Verbindungen stabil, selbst wenn im Hintergrund Skalierungsoperationen ablaufen.
Die Aufteilung in Speicher und Verarbeitung bringt einen weiteren Vorteil mit sich: Die Verarbeitung kann auf Null heruntergefahren werden, sodass Sie nur für den Speicher bezahlen. Die Skalierung kann je nach Bedarf innerhalb von nur 5 Sekunden erfolgen. Sie haben auch Zugriff auf einen Pool „warmer“ Ressourcen, die jederzeit bereitstehen, um Ihre Anforderungen zu erfüllen.
Die Vorteile von serverlosen Datenbanken
Kosteneffizienz
Die Nutzung einer festen Anzahl von Servern ist nicht nur teurer, sondern auch zeitaufwendiger als die Verwendung einer serverlosen Datenbank. Serverlose Datenbanken können kostengünstiger sein als die Einrichtung einer Autoscaling-Gruppe, da sie durch die Bündelung von Maschinenressourcen effizienter arbeiten.
Zusätzliche Kosten, wie für Lizenzierung, Installation, Wartung, Support und Patching entfallen. Es werden nur die tatsächlich genutzte Zeit und der Speicherplatz für die Ausführung des Codes berechnet.
Automatisierte Skalierbarkeit
Entwickler müssen sich nicht um die Konfiguration oder Einrichtung von Autoscaling-Richtlinien kümmern, da die serverlose Skalierung basierend auf der Arbeitslast automatisch erfolgt. Diese Aufgabe wird vom Cloud-Anbieter übernommen, der sich um die Bereitstellung der benötigten Leistung kümmert.
Schnelle Bereitstellungen und Updates
Mit einer serverlosen Infrastruktur entfällt das Hochladen von Code auf Server und die Konfiguration von Backend-Einstellungen, um eine funktionierende Anwendung zu erstellen. Entwickler können einzelne Code-Bestandteile hochladen und anschließend ein neues Produkt veröffentlichen. Sowohl der gesamte Code als auch einzelne Funktionen können gleichzeitig hochgeladen werden.
Das ermöglicht ein schnelles Aktualisieren, Patchen, Reparieren oder Hinzufügen neuer Features. Anstatt die gesamte Anwendung zu aktualisieren, können Entwickler kleine Änderungen an einzelnen Teilen vornehmen.
Gesteigerte Produktivität
Eine gesteigerte Produktivität ergibt sich, da weniger Zeit für die Interaktion mit dem System aufgewendet werden muss. Sie benötigen ein Team von Fachleuten, das optimal dimensioniert ist, um bessere Ergebnisse zu erzielen.
Die Nachteile von serverlosen Datenbanken
Probleme mit Kaltstarts
Einer der wichtigsten Aspekte und Herausforderungen in diesem Bereich sind die Kaltstarts. Eine serverlose Datenbank, die nicht verwendet wird, geht in einen Leerlaufmodus, um Ressourcen zu sparen und unnötige Leistung zu vermeiden.
Wenn das System dann wieder benötigt wird, muss es alle Prozesse neu starten, was Zeit kostet. Die erste Anfrage kann daher zu Verzögerungen und langsameren Reaktionszeiten führen.
Schwierigkeiten beim Testen und Debuggen
Eine weitere Herausforderung liegt in der Schwierigkeit, eine serverlose Umgebung zum Testen und Überwachen des Codes zu replizieren, bevor dieser live geschaltet wird. Dies liegt unter anderem daran, dass Entwickler keinen Zugriff auf die Backend-Dienste der Cloud-Anbieter haben.
Daher ist es schwierig, komplexe Systeme mit Profilern oder Debuggern zu testen. Hier können Tools von Drittanbietern eine Lösung darstellen, die jedoch immer häufiger auf dem Markt verfügbar sind.
Intensivere Überwachung
Serverlose Lösungen erfordern eine intensivere Überwachung und das genaue Beobachten möglicher Leistungsprobleme oder übermäßiger Ressourcennutzung. Dies liegt zu einem großen Teil daran, dass Cloud-Lösungen selten Open Source sind.
Anbieterbindung
Die Wahl eines serverlosen Modells kann bei der Migration zu einem anderen Anbieter zu Problemen führen, da jeder Anbieter unterschiedliche Arbeitsabläufe und Funktionen bietet.
Funktionen serverloser Datenbanken
Serverlose Datenbanken bieten einige der spannendsten Funktionen:
#1. Mandantenfähige Architektur
Ein großer Vorteil ist, dass serverlose Datenbanken eine einzelne Poolressource nutzen können, die für mehrere Projekte innerhalb Ihres Unternehmens verwendet wird. Das ist besonders vorteilhaft für Entwickler, da keine anwendungsspezifischen, isolierten Datenquellen mehr erstellt werden müssen.
Diese mandantenfähige Architektur erlaubt es Entwicklern, mehrere Anwendungen innerhalb eines einzigen Datenbankclusters einzurichten, zu konfigurieren und bereitzustellen.
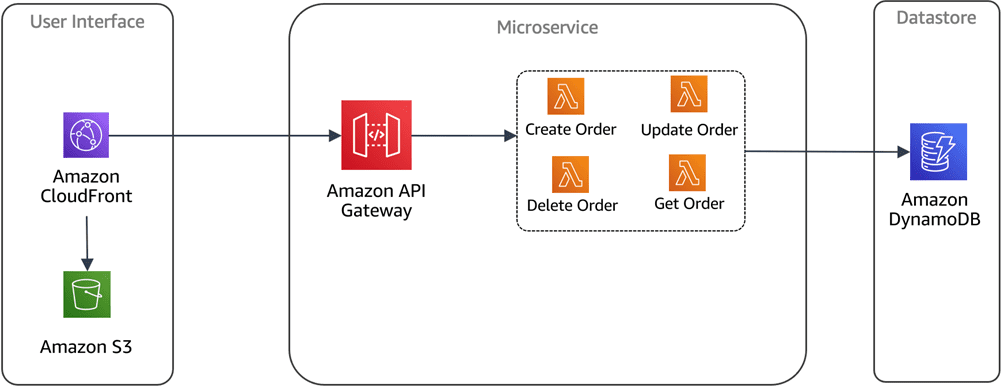 Bildquelle: AWS
Bildquelle: AWS
#2. Geografische Verteilung
In der heutigen globalisierten Welt ist es wichtig, dass Daten weltweit verfügbar sind. Die Nähe zu Rechenzentren verbessert das Echtzeiterlebnis. Zudem wird die Wahrscheinlichkeit von Ausfällen durch die Eliminierung eines einzelnen Fehlerpunkts reduziert.
Serverlose Datenbanken ermöglichen die Replikation mehrerer Datensätze weltweit, ohne zusätzliche Tools oder benutzerdefinierte Entwicklungen.
#3. Wenig bis gar keine manuelle Serververwaltung
Der Begriff serverlos ist etwas irreführend, da es sich tatsächlich um eine Sammlung von Servern handelt, die abstrahiert und automatisiert wurden, um die Verwaltung zu vereinfachen. Alle manuellen Aufgaben wie Bereitstellung, Kapazitätsplanung, Skalierung, Wartung, Updates usw. werden im Hintergrund ausgeführt. Die Bedienung ist denkbar einfach und erfordert wenig bis gar keinen manuellen Eingriff.
#4. Verbrauchsabhängige Abrechnung
Serverlose Datenbanken sind besonders kostengünstig, da die Gebühren auf der tatsächlichen Nutzung basieren. Es ist keine Speicherkapazität erforderlich, sondern nur die tatsächlich genutzten Ressourcen werden in Rechnung gestellt. Budgetüberschreitungen lassen sich vermeiden, da ein Ausgabenlimit festgelegt werden kann.
Relationale vs. nicht-relationale serverlose Datenbanken

Im digitalen Zeitalter lassen sich Daten in operative und analytische Daten unterteilen. Im Folgenden betrachten wir einige Datenbankoptionen, die Entwickler in Betracht ziehen, und vergleichen diese.
Die meisten Unternehmen benötigen sowohl OLTP- (operative) als auch OLAP- (analytische) Systeme für die Speicherung ihrer Daten. Zur Unterstützung ihrer Geschäftsanforderungen können sie entweder relationale oder nicht-relationale Datenbanken verwenden.
Relationale serverlose Datenbank
Eine relationale Datenbank organisiert und sammelt Daten anhand vordefinierter Beziehungen zwischen Schlüsseldatenpunkten. Sie ordnet Daten so an, dass mehrere Benutzer Daten finden und sortieren können, ohne die logische Datenkategorisierung zu verändern.
Außerdem wird die Datenduplizierung in Speicherprozessen vermieden. Structured Query Language (SQL) dient als API (Anwendungsprogrammierschnittstelle) für eine relationale Datenbank.
Das System stellt Daten in Tabellenform dar. Diese Tabelle repräsentiert eine Entität, wie z. B. ein Produkt oder eine mobile App. Jede Zeile enthält den tatsächlichen Wert und hat eine eindeutige Kennung, also eine Instanz dieses Entitätstyps. Jede Zeile wird als Datensatz bezeichnet.
Die Spalten hingegen enthalten die Attribute der Daten, also die tatsächlichen Werte des Unternehmens. Der Datenzugriff ist ohne Reorganisation der Datenbanktabelle möglich.
NoSQL (nicht-relationale) serverlose Datenbank
Nicht-relationale Datenbanken (NoSQL) sind eher verteilt als SQL-Datenbanken. Sie können mit einer großen Anzahl von Datenbanken eingesetzt werden. Moderne Unternehmen benötigen moderne Funktionen, wie NoSQL-Datenbanken, um cloud-native Anwendungen entwickeln zu können.
Serverlose NoSQL-Datenbanken werden in Echtzeit-Webanwendungen verwendet. Ihr Design ist einfach, und sie können große Datenmengen mit horizontaler Skalierung schnell verarbeiten. Sie eignen sich besonders für Situationen, in denen das Schema unklar ist und hohe Datenraten erforderlich sind.
Serverlose NoSQL-Datenbanken sind beliebt, weil sie große Datenmengen in unterschiedlichen Formaten speichern können, wie Diagramme, Dokumente, Schlüssel-Wert-Paare und spaltenorientierte Datenstrukturen. Das ermöglicht Entwicklern ein einfaches Ändern der Datenstruktur.
Warum serverlose Datenbanken?
Serverlose Datenbanken sind eine hervorragende Wahl für kleinere Teams, die nicht über ausreichend Personal für die Verwaltung und Skalierung herkömmlicher Datenbanken verfügen. Sie erfordern wenig Infrastruktur und Wartung, sodass Ihr Team weniger Zeit für die Systempflege aufwenden muss. Mit einer serverlosen Datenbank können neue Tabellen einfach erstellt und neue Funktionen getestet werden.
Ein weiterer wichtiger Faktor sind die Kosten: Serverlose Datenbanken ermöglichen es Ihnen, nur für die tatsächliche Nutzung zu bezahlen, ohne die Kosten für Konfiguration und Feinabstimmung wie bei herkömmlichen Datenbanken. Serverlose Datenbanken sind ideal für Entwickler und Teams, die neue Funktionen schnell veröffentlichen müssen.
Anwendungsfälle für serverlose Datenbanken

#1. Neue Anwendungen
Wenn Sie beispielsweise einen Blog mit wenig Traffic betreiben und nur für die Zeit bezahlen möchten, in der Benutzer auf Ihre Website zugreifen, sind serverlose Datenbanken eine optimale Lösung. Sie zahlen nur für die tatsächlich genutzten Datenbankressourcen pro Sekunde.
#2. Elastische Größenanpassung für Live-Videoübertragungen
Live-Videoübertragungen werden durch eine serverlose Architektur erst möglich. In Live-Videoübertragungen können mehrere Zuschauer interagieren. Der Host kann gleichzeitig mit mehreren Mikrofonen verbunden sein. Ein Moderator kann mehrere Zuschauer oder Freunde mit dem Bildschirm verbinden und die verschiedenen Quellen zu einem Szenario zusammenführen, das den Zuschauern des Live-Streams präsentiert wird.
#3. Selten verwendete Anwendungen
Wenn Sie eine App entwickelt haben, deren Annahme Sie nicht einschätzen können, eignet sich diese Methode. Erstellen Sie einfach einen Endpunkt, und die serverlose Datenbank wird automatisch skaliert, um die Anforderungen Ihrer Anwendung zu erfüllen.
#4. Internet der Dinge (IoT)
IoT ist ein Begriff für Geräte, die sich mit dem Internet verbinden können, um verschiedene Funktionen auszuführen. FaaS (Function-as-a-Service) wird zunehmend von diesen Geräten genutzt, um ihre Aufgaben zu erledigen. Daten werden nur dann gesendet und empfangen, wenn ein Ereignis dies auslöst.
Unternehmen sparen Geld, da sie nicht für Rechenleistung bezahlen müssen, die sie nicht nutzen. FaaS ermöglicht eine schnelle und automatische Skalierung, sodass Entwickler sich keine Gedanken über unvorhersehbare Nutzungsmuster machen müssen.
Fazit
Diese Anwendungsfälle zeigen, dass die serverlose Architektur viele Vorteile für Entwickler und Unternehmen bietet. Serverlose Datenbanken können die Rechengeschwindigkeit und Ausfallsicherheit verbessern, gleichzeitig Zeit und Kosten für Skalierung und Ressourcen reduzieren. Es gibt verschiedene Arten serverloser Datenbanken, sowohl relationale als auch nicht-relationale. Sie alle verfolgen jedoch das gleiche Ziel: Bedarfsgerechte Skalierung ohne zusätzlichen Verwaltungsaufwand und geringere Kosten.