Umgang mit Zugriffsrechten in AWS S3 – Eine Alternative zu traditionellen Ordnerstrukturen
In der Ära von On-Premise-Unix-Servern, die mit umfangreichen Dateisystemen arbeiteten, etablierten Unternehmen detaillierte Regeln und Strategien für die Ordnerverwaltung. Ziel war es, die Zugriffsrechte auf verschiedene Verzeichnisse für unterschiedliche Personengruppen zu kontrollieren.
Typischerweise nutzen verschiedene Benutzergruppen mit teils sehr unterschiedlichen Anforderungen und Einschränkungen bezüglich der Vertraulichkeit oder der Inhaltsdefinitionen eine Plattform. In global agierenden Unternehmen kann dies bedeuten, Inhalte geografisch zu trennen, also zwischen Nutzern aus verschiedenen Ländern zu unterscheiden.
Weitere gängige Beispiele umfassen:
- Trennung von Daten zwischen Entwicklungs-, Test- und Produktionsumgebungen.
- Vertriebsinhalte, die nicht für die breite Öffentlichkeit bestimmt sind.
- Länderspezifische, rechtlich relevante Inhalte, die in anderen Regionen nicht zugänglich sein dürfen.
- Projektbezogene Inhalte, bei denen „Managementdaten“ nur einem bestimmten Personenkreis zur Verfügung stehen sollen.
Die Liste solcher Beispiele ist potenziell endlos. Der springende Punkt ist, dass es stets notwendig ist, die Zugriffsrechte auf Dateien und Daten zwischen allen Nutzern der Plattform zu steuern.
Bei On-Premise-Lösungen war dies eine gängige Aufgabe. Der Systemadministrator legte Regeln fest, wählte ein passendes Werkzeug aus, ordnete Benutzer zu Gruppen und wies diesen Gruppen bestimmte Ordner oder Mount-Punkte zu, auf die sie zugreifen sollten. Die Zugriffsebene wurde dabei als „Nur Lesen“ oder „Lesen und Schreiben“ definiert.
Bei AWS-Cloud-Plattformen ist es nicht anders: Auch hier ist die Einschränkung des Inhaltszugriffs von Bedeutung. Die Lösung dieses Problems muss jedoch anders aussehen. Dateien befinden sich nicht mehr auf Unix-Servern, sondern in der Cloud, und sind möglicherweise für die gesamte Organisation oder sogar weltweit zugänglich. Inhalte werden nicht in Ordnern, sondern in S3-Buckets gespeichert.
Im Folgenden wird eine alternative Vorgehensweise beschrieben. Sie basiert auf praktischen Erfahrungen, die bei der Konzeption solcher Lösungen für ein konkretes Projekt gesammelt wurden.
Einfacher, aber manueller Ansatz
Eine einfache Methode, dieses Problem ohne Automatisierung zu lösen, ist wie folgt:
- Für jede Personengruppe wird ein neuer Bucket erstellt.
- Dem Bucket werden Zugriffsrechte zugewiesen, sodass nur die entsprechende Gruppe darauf zugreifen kann.
Dies ist eine praktikable Option für schnelle und einfache Lösungen. Es gibt jedoch einige Einschränkungen.
Standardmäßig können nur bis zu 100 S3-Buckets pro AWS-Konto erstellt werden. Dieses Limit kann durch eine Anfrage beim AWS-Support auf 1000 erhöht werden. Falls diese Beschränkungen kein Problem darstellen, kann jede Nutzergruppe mit einem separaten S3-Bucket arbeiten.
Probleme können auftreten, wenn es Nutzergruppen mit funktionsübergreifenden Aufgaben gibt oder wenn Nutzer auf Inhalte aus mehreren Bereichen zugreifen müssen. Zum Beispiel:
- Datenanalysten, die Inhalte aus verschiedenen Bereichen und Regionen auswerten.
- Testteams, die verschiedene Entwicklungsteams bedienen.
- Benutzer, die Dashboards mit Daten aus verschiedenen Ländern innerhalb einer Region erstellen.
Die Komplexität der Zugriffsverwaltung steigt mit der Anzahl solcher Anwendungsfälle. Es sind zusätzliche Werkzeuge erforderlich, und möglicherweise muss ein Administrator die Zugriffslisten pflegen und bei Bedarf aktualisieren.
Wie kann man das gleiche organisierter und automatisierter erreichen?
Wenn der Ansatz „ein Bucket pro Domäne“ nicht funktioniert, wird es unweigerlich zu gemeinsam genutzten Buckets kommen. In solchen Fällen muss die Logik der Zugriffsrechtezuweisung flexibel und dynamisch anpassbar sein.
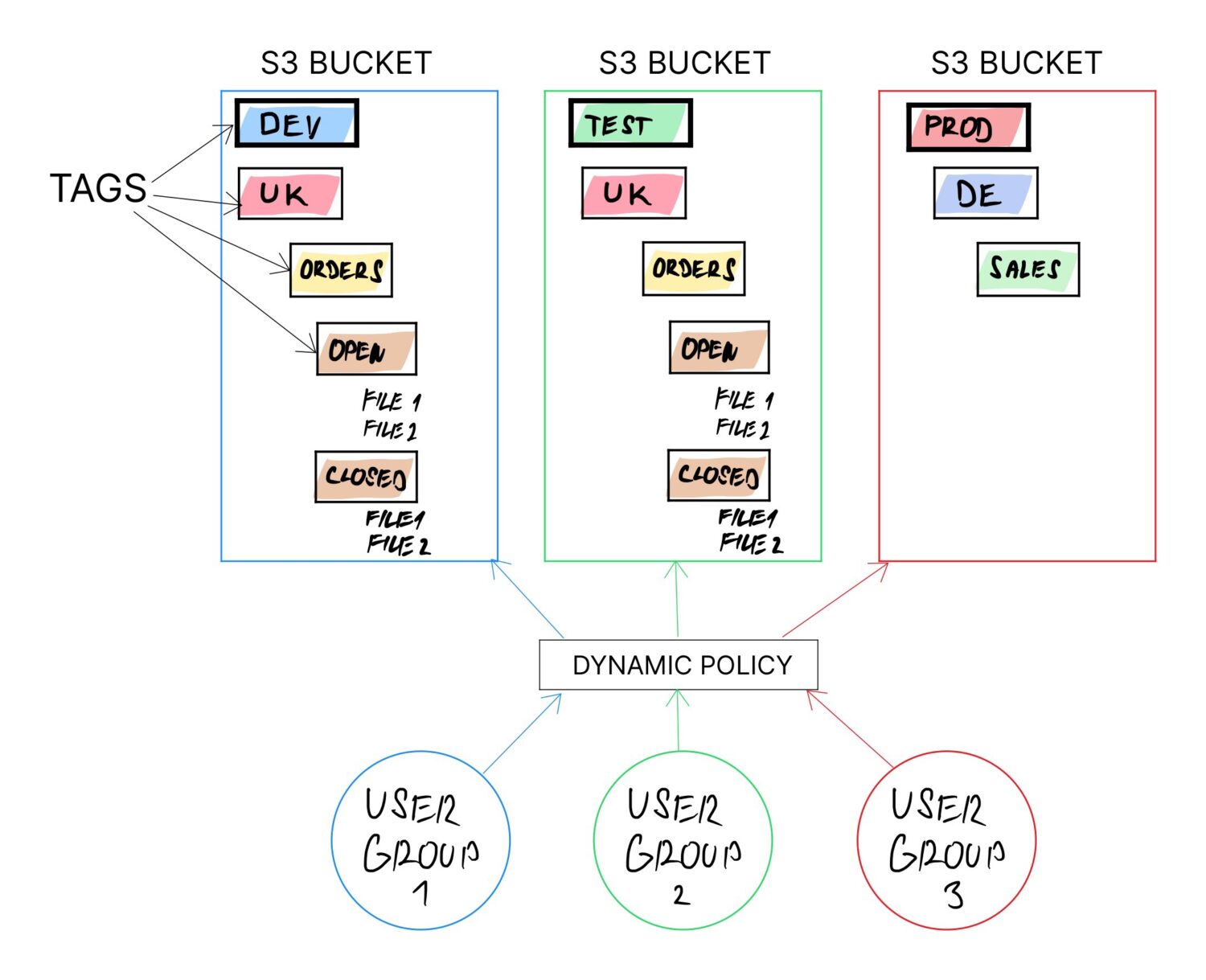
Eine Möglichkeit ist die Verwendung von Tags für S3-Buckets. Tags werden ohnehin zur Kategorisierung und Abrechnung empfohlen. Die Tags eines Buckets können jederzeit geändert werden.
Wenn die Logik auf Bucket-Tags aufbaut und die Konfiguration von den Tag-Werten abhängig ist, kann der Zweck des Buckets dynamisch neu definiert werden, indem man einfach die Tag-Werte ändert.
Welche Art von Tags sind geeignet?
Dies hängt vom jeweiligen Anwendungsfall ab. Zum Beispiel:
- Buckets nach Umgebungstyp trennen: Ein Tag „ENV“ mit den Werten „DEV“, „TEST“, „PROD“.
- Trennung nach Ländern: Ein Tag „COUNTRY“ mit dem jeweiligen Ländernamen.
- Trennung nach funktionalen Abteilungen: Ein Tag „USER_TYPE“ mit Werten wie „Business Analysts“, „Data Warehouse Users“, „Data Scientists“.
- Festlegung einer Ordnerstruktur: Mehrere Tags mit Arbeitsverzeichnissen wie „Daten/Import“, „Daten/Verarbeitet“, „Daten/Fehler“.
Idealerweise lassen sich die Tags logisch kombinieren, um eine gesamte Ordnerstruktur zu bilden.
Beispielsweise könnte die folgende Kombination verwendet werden:
- /
/ / /
Durch Ändern des
Dies ermöglicht die Verwendung eines einzigen Buckets für viele Nutzer. Buckets unterstützen keine Ordner im eigentlichen Sinne, sondern „Labels“, die wie Unterordner funktionieren. Nutzer müssen eine Reihe von Labels durchlaufen, um zu ihren Daten zu gelangen.
Nachdem die Tags definiert wurden, besteht der nächste Schritt darin, S3-Bucket-Richtlinien zu erstellen, die diese Tags nutzen.
Wenn die Richtlinien Tag-Namen verwenden, handelt es sich um „dynamische Richtlinien“. Diese verhalten sich unterschiedlich für Buckets mit unterschiedlichen Tag-Werten. Die Richtlinie bezieht sich in Form von Platzhaltern auf diese Werte.
Dieser Schritt erfordert eine benutzerdefinierte Codierung, kann aber mit dem Amazon AWS Richtlinien-Editor vereinfacht werden.
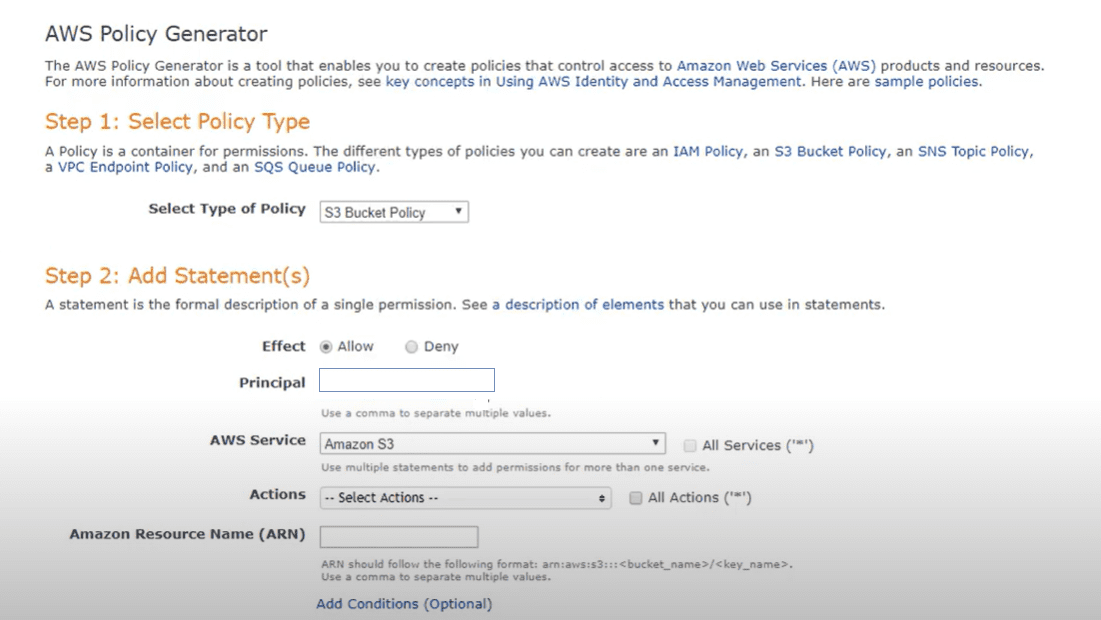
In der Richtlinie werden Zugriffsrechte (Lesen, Schreiben) definiert. Die Logik liest die Tags der Buckets und erstellt auf dieser Basis die Ordnerstruktur. Entsprechend der Tag-Werte werden Unterordner erstellt und die Zugriffsrechte vergeben.
Der Vorteil einer solchen dynamischen Richtlinie ist, dass sie nur einmal erstellt werden muss und dann vielen Buckets zugewiesen werden kann. Sie verhält sich unterschiedlich für Buckets mit unterschiedlichen Tag-Werten, erfüllt aber stets die Erwartungen.
Dies ist eine effektive Methode, die Zugriffsrechte für eine große Anzahl von Buckets organisiert und zentral zu verwalten. Jeder Bucket folgt dabei definierten Strukturen und wird von den Nutzern innerhalb der Organisation verwendet.
Automatisieren des Onboardings neuer Entitäten
Nachdem dynamische Richtlinien definiert und Buckets zugewiesen wurden, können Benutzer die gleichen Buckets verwenden, ohne dass es zu Konflikten durch unberechtigten Zugriff kommt.
Der Zugriff ist auch für Nutzergruppen mit umfangreicheren Rechten einfacher, da alle Daten im selben Bucket gespeichert sind.
Der letzte Schritt ist, das Onboarding neuer Benutzer, Buckets und Tags zu vereinfachen. Dies erfordert ebenfalls benutzerdefinierte Programmierung, die jedoch nicht übermäßig komplex sein muss, wenn klare Regeln existieren.
Dies kann so einfach sein wie das Erstellen eines Skripts, das mit einem AWS CLI-Befehl und Parametern ausführbar ist. Oder eine Reihe von CLI-Skripten, die in einer bestimmten Reihenfolge ausgeführt werden, wie zum Beispiel:
- create_new_bucket(
, , , , ..) - create_new_tag(
, , ) - update_existing_tag(
, , ) - create_user_group(
, , )
Du verstehst den Punkt. 😃
Ein Profi-Tipp 👨💻
Die dynamischen Richtlinien können nicht nur für Zugriffsrechte auf Ordnerstandorte, sondern auch für die automatische Zuweisung von Dienstrechten für Buckets und Benutzergruppen genutzt werden!
Dazu müsste lediglich die Liste der Tags auf den Buckets erweitert und dynamische Richtlinienzugriffsrechte hinzugefügt werden, um bestimmte Dienste für bestimmte Benutzergruppen zu ermöglichen.
Beispielsweise könnte eine Gruppe von Benutzern auch Zugriff auf einen Datenbank-Cluster-Server benötigen. Dies kann durch dynamische Richtlinien erreicht werden, die Bucket-Tags nutzen, insbesondere wenn die Zugriffe rollenbasiert gesteuert werden. Der dynamische Richtlinien-Code wird um einen Teil erweitert, der Tags bezüglich der Datenbank-Cluster-Spezifikation verarbeitet und die Richtlinienzugriffsrechte direkt zuweist.
Auf diese Weise wird das Onboarding neuer Benutzergruppen durch diese eine dynamische Richtlinie ermöglicht. Da die Richtlinie dynamisch ist, kann sie für das Onboarding vieler verschiedener Benutzergruppen wiederverwendet werden (es wird erwartet, dass sie derselben Vorlage folgen, aber nicht unbedingt dieselben Dienste verwenden).
Hier sind einige AWS S3-Befehle zum Verwalten von Buckets und Daten.