Wie man Pipes unter Linux verwendet
Nutzen Sie Linux-Pipes, um das Zusammenspiel von Befehlszeilenprogrammen zu organisieren. Vereinfachen Sie komplexe Abläufe und steigern Sie Ihre Effizienz, indem Sie eine Vielzahl von Einzelbefehlen verwenden und diese zu einer zielgerichteten Einheit formen. Wir zeigen Ihnen, wie das geht.
Pipes: Allgegenwärtig in Linux
Pipes gehören zu den grundlegenden und wirkungsvollsten Funktionen der Befehlszeile in Linux- und Unix-ähnlichen Systemen. Sie werden auf vielfältige Weise eingesetzt. In fast jedem Artikel über die Linux-Befehlszeile – egal auf welcher Website – werden Pipes regelmäßig verwendet. Auch in den Linux-Artikeln auf etoppc.com kommen Pipes immer wieder zum Einsatz.
Mit Linux-Pipes können Sie Operationen durchführen, die von der Shell standardmäßig nicht unterstützt werden. Die Linux-Philosophie setzt auf viele kleine Programme, die ihre spezifische Aufgabe gut erfüllen und auf unnötige Zusätze verzichten. Nach dem Motto "Tue eine Sache und tue sie gut" können Sie mit Pipes Befehle miteinander verketten, so dass die Ausgabe eines Befehls zur Eingabe eines anderen wird. Jeder Befehl bringt seine spezifischen Stärken ins Team ein, sodass Sie mit der Zeit eine leistungsstarke Befehlskette bilden.
Ein simples Anwendungsbeispiel
Nehmen wir an, wir haben ein Verzeichnis mit vielen unterschiedlichen Dateitypen. Wir möchten ermitteln, wie viele Dateien eines bestimmten Typs in diesem Verzeichnis vorhanden sind. Es gibt verschiedene Lösungswege, aber da es hier um die Einführung von Pipes geht, werden wir diese nutzen.
Mit dem Befehl `ls` können wir eine Liste der Dateien anzeigen:
ls
Um die gewünschten Dateien zu identifizieren, verwenden wir `grep`. Wir wollen nach Dateien suchen, deren Dateiname oder Dateiendung das Wort "Seite" enthält.
Das spezielle Zeichen "|" der Shell leitet die Ausgabe von `ls` an `grep` weiter.
ls | grep "seite"

`grep` gibt die Zeilen aus, die mit dem Suchmuster übereinstimmen. Damit erhalten wir eine Auflistung, die nur Dateien mit der Endung ".seite" umfasst.
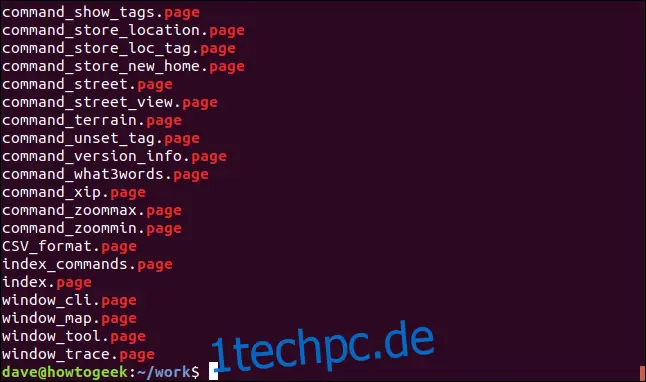
Selbst dieses einfache Beispiel zeigt die Leistungsfähigkeit von Pipes. Die Ausgabe von `ls` wurde nicht direkt im Terminal angezeigt, sondern als Eingabe an `grep` weitergeleitet. Die Ausgabe, die wir sehen, stammt von `grep`, dem letzten Befehl in der Kette.
Erweiterung der Befehlskette
Beginnen wir, unsere Kette von Befehlen zu erweitern. Wir können die Anzahl der ".seite"-Dateien zählen, indem wir den Befehl `wc` hinzufügen. Wir verwenden die Option `-l` (Zeilenzahl) mit `wc`. Beachten Sie, dass wir `ls` die Option `-l` (langes Format) hinzugefügt haben. Wir werden dies in Kürze nutzen.
ls -l | grep "seite" | wc -l

`grep` ist nicht mehr der letzte Befehl der Kette, daher sehen wir seine Ausgabe nicht. Die Ausgabe von `grep` wird an den Befehl `wc` weitergeleitet. Die Ausgabe, die wir im Terminal sehen, stammt von `wc`. Es gibt uns die Anzahl von 69 ".seite"-Dateien im Verzeichnis.
Lassen Sie uns die Befehlskette nochmals erweitern. Wir entfernen den Befehl `wc` und ersetzen ihn durch `awk`. Die Ausgabe von `ls -l` enthält neun Spalten. Wir verwenden `awk`, um die Spalten fünf, drei und neun auszugeben. Dies sind die Größe, der Besitzer und der Dateiname.
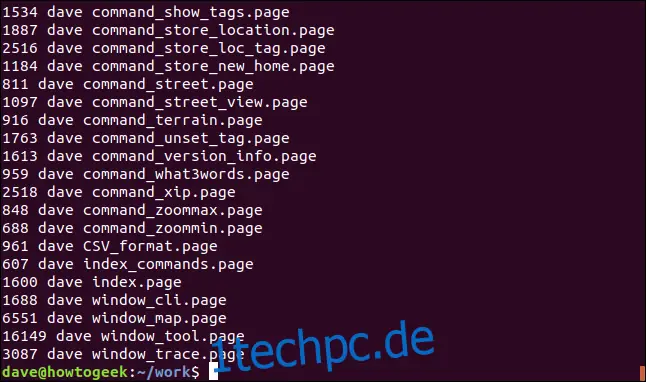
ls -l | grep "seite" | awk '{print $5 " " $3 " " $9}'

Wir erhalten eine Liste dieser Spalten für jede passende Datei.
Nun leiten wir diese Ausgabe an den Befehl `sort` weiter. Die Option `-n` (numerisch) weist `sort` an, die erste Spalte als Zahlen zu interpretieren.
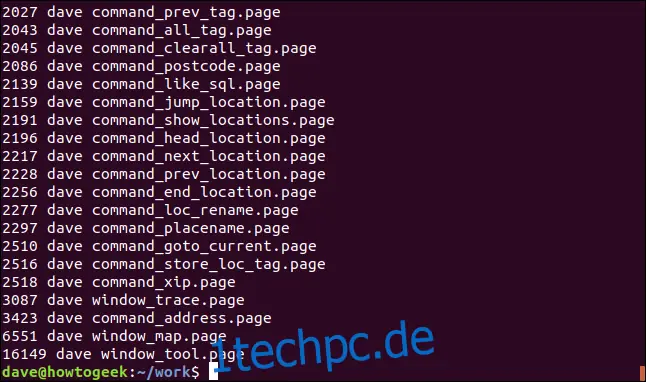
ls -l | grep "seite" | awk '{print $5 " " $3 " " $9}' | sort -n

Die Ausgabe ist jetzt nach Dateigröße sortiert, mit unserer benutzerdefinierten Auswahl von drei Spalten.
Einen weiteren Befehl hinzufügen
Zum Abschluss ergänzen wir die Befehlskette mit `tail`. Damit listen wir nur die letzten fünf Zeilen der Ausgabe auf.
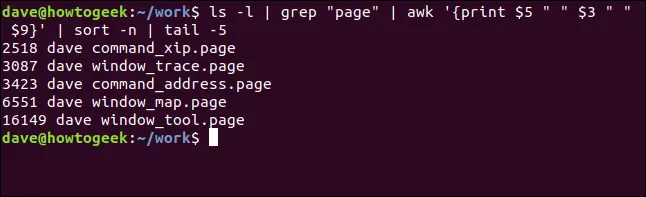
ls -l | grep "seite" | awk '{print $5 " " $3 " " $9}' | sort -n | tail -5

Das bedeutet, dass unser Befehl übersetzt "Zeige mir die fünf größten '.seite'-Dateien in diesem Verzeichnis, sortiert nach Größe" bedeutet. Natürlich gibt es keinen einzelnen Befehl dafür, aber mit Hilfe von Pipes haben wir ihn selbst erstellt. Wir können diesen – oder jeden anderen langen Befehl – als Alias oder Shell-Funktion hinzufügen, um uns die Eingabe zu sparen.
Hier ist die Ausgabe:
Wir könnten die Sortierreihenfolge umkehren, indem wir die Option `-r` (reverse) zum Befehl `sort` hinzufügen und anstelle von `tail` den Befehl `head` nutzen, um die Zeilen vom Anfang der Ausgabe zu wählen.
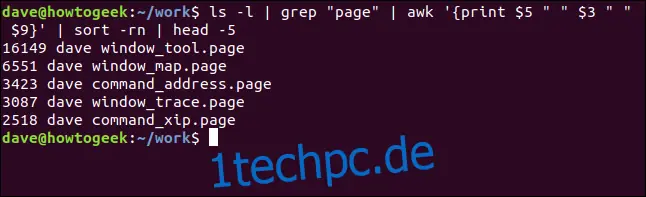
ls -l | grep "seite" | awk '{print $5 " " $3 " " $9}' | sort -nr | head -5

Diesmal werden die fünf größten ".seite"-Dateien von der größten zur kleinsten aufgeführt:
Einige aktuelle Beispiele
Hier sind zwei interessante Beispiele aus aktuellen Artikeln von etoppc.com.
Einige Befehle, wie der Befehl `xargs`, sind dafür ausgelegt, dass ihnen die Eingabe per Pipe übergeben wird. So können wir mit `wc` Wörter, Zeichen und Zeilen in mehreren Dateien zählen, indem wir `ls` an `xargs` weiterleiten. `xargs` übergibt die Dateinamen als Kommandozeilenparameter an `wc`.
ls *.seite | xargs wc

Die Gesamtzahl von Wörtern, Zeichen und Zeilen wird unten im Terminal angezeigt.
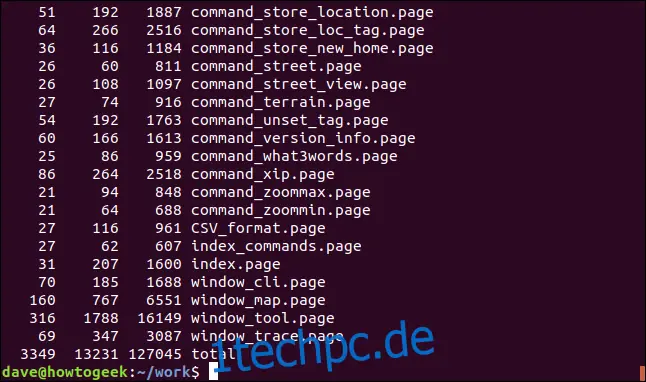
So erhalten Sie eine sortierte Liste der einzigartigen Dateiendungen im aktuellen Verzeichnis mit der Anzahl jedes Typs.
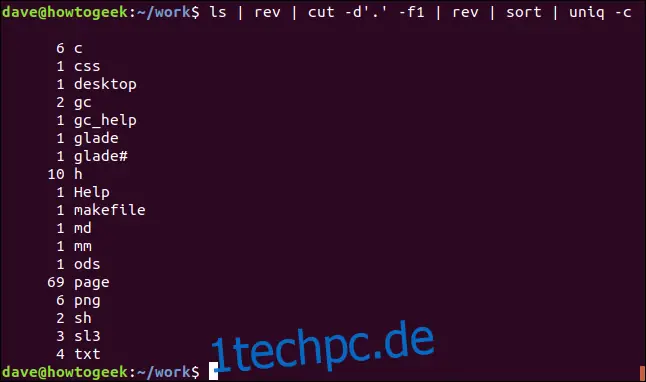
ls | rev | cut -d'.' -f1 | rev | sort | uniq -c

Hier passiert eine ganze Menge:
ls: Listet die Dateien im Verzeichnis auf.
rev: Kehrt den Text der Dateinamen um.
cut: Schneidet den String am ersten Auftreten des angegebenen Trennzeichens ".". Text danach wird verworfen.
rev: Kehrt den verbleibenden Text, also die Dateiendung, wieder um.
sort: Sortiert die Liste alphabetisch.
uniq: Zählt die Anzahl von jedem einzelnen Eintrag in der Liste.
Die Ausgabe zeigt die Liste der Dateiendungen, alphabetisch sortiert mit der Anzahl jedes einzelnen Typs.
Named Pipes
Es gibt noch eine weitere Art von Pipes, die als Named Pipes bezeichnet werden. Die Pipes in den vorherigen Beispielen werden von der Shell dynamisch erstellt, wenn sie die Befehlszeile verarbeitet. Diese Pipes werden erstellt, genutzt und dann wieder verworfen. Sie sind vergänglich und hinterlassen keine Spuren. Sie existieren nur so lange, wie der Befehl, der sie nutzt, ausgeführt wird.
Named Pipes erscheinen als permanente Objekte im Dateisystem, sodass Sie sie mit `ls` sehen können. Sie sind permanent, weil sie einen Neustart des Computers überstehen – obwohl alle ungelesenen Daten in ihnen zu diesem Zeitpunkt verworfen werden.
Named Pipes wurden früher oft dazu verwendet, um verschiedenen Prozessen das Senden und Empfangen von Daten zu ermöglichen. Zweifellos gibt es immer noch Anwender, die sie effektiv einsetzen. Zur Vollständigkeit oder einfach nur, um Ihre Neugier zu stillen, zeigen wir Ihnen, wie man sie verwendet.
Named Pipes werden mit dem Befehl `mkfifo` erstellt. Dieser Befehl erstellt eine Named Pipe namens "geek-pipe" im aktuellen Verzeichnis.
mkfifo geek-pipe

Wir können die Details der Named Pipe anzeigen, indem wir den Befehl `ls` mit der Option `-l` (langes Format) verwenden:
ls -l geek-pipe

Das erste Zeichen der Ausgabe ist ein "p", was bedeutet, dass es sich um eine Pipe handelt. Ein "d" würde bedeuten, dass das Dateisystemobjekt ein Verzeichnis ist, und ein Bindestrich "-" würde bedeuten, dass es sich um eine normale Datei handelt.
Verwendung der Named Pipe
Lassen Sie uns unsere Pipe nutzen. Die unbenannten Pipes, die wir in unseren vorherigen Beispielen verwendet haben, leiteten Daten sofort vom sendenden an den empfangenden Befehl weiter. Daten, die über eine Named Pipe gesendet werden, verbleiben in der Pipe, bis sie gelesen werden. Die Daten werden tatsächlich im Speicher gehalten, sodass die Größe der Named Pipe in den ls-Ausgaben nicht variiert, egal ob Daten vorhanden sind oder nicht.
Wir verwenden für dieses Beispiel zwei Terminalfenster. Ich verwende die Kennzeichnung:
# Terminal-1
in einem Terminalfenster und
# Terminal-2
im anderen, um die Fenster auseinanderzuhalten. Das Zeichen "#" weist die Shell an, dass es sich bei dem Folgenden um einen Kommentar handelt, der ignoriert werden soll.
Nehmen wir das vorherige Beispiel und leiten die Ausgabe in die Named Pipe um. Wir verwenden in diesem Befehl also sowohl unbenannte als auch benannte Pipes:
ls | rev | cut -d'.' -f1 | rev | sort | uniq -c > geek-pipe

Es scheint nicht viel zu passieren. Möglicherweise stellen Sie jedoch fest, dass Sie nicht zur Eingabeaufforderung zurückkehren. Das deutet darauf hin, dass etwas im Gange ist.
Geben Sie im anderen Terminalfenster diesen Befehl ein:
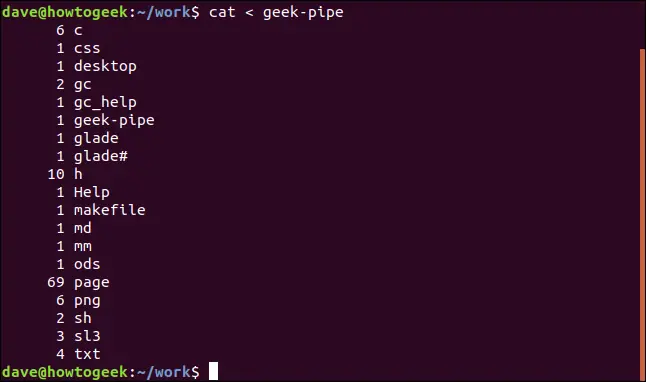
cat < geek-pipe
Wir leiten den Inhalt der Named Pipe an `cat` weiter, damit dieser die Daten im zweiten Terminalfenster anzeigt. Hier ist die Ausgabe:
Sie werden sehen, dass Sie im ersten Terminalfenster zur Eingabeaufforderung zurückgekehrt sind.

Was ist also gerade passiert?
- Wir haben eine Ausgabe in die Named Pipe umgeleitet.
- Das erste Terminalfenster kehrte nicht sofort zur Eingabeaufforderung zurück.
- Die Daten blieben in der Pipe, bis sie im zweiten Terminal ausgelesen wurden.
- Wir wurden zur Eingabeaufforderung im ersten Terminalfenster zurückgeführt.
Sie könnten denken, dass Sie den Befehl im ersten Terminalfenster als Hintergrundaufgabe ausführen können, indem Sie am Ende des Befehls ein "&" hinzufügen. Und Sie hätten Recht. In diesem Fall wären wir sofort zur Eingabeaufforderung zurückgekehrt.
Der Sinn, die Hintergrundverarbeitung nicht zu nutzen, war zu betonen, dass eine Named Pipe ein blockierender Prozess ist. Das Schreiben in eine Named Pipe öffnet nur ein Ende der Pipe. Das andere Ende wird erst geöffnet, wenn das lesende Programm die Daten extrahiert. Der Kernel stoppt den Prozess im ersten Terminalfenster, bis die Daten am anderen Ende der Pipe gelesen werden.
Die Macht der Pipes
Heutzutage sind Named Pipes eher eine Neuheit.
Einfache Linux-Pipes hingegen sind eines der nützlichsten Werkzeuge, die Sie in Ihrem Terminal-Toolkit haben können. Die Linux-Befehlszeile wird für Sie lebendig, und Sie erhalten eine ganz neue Leistungsfähigkeit, wenn Sie Befehle zu einer zusammenhängenden Operation kombinieren können.
Ein Tipp am Rande: Am besten schreiben Sie Ihre Pipe-Befehle, indem Sie jeweils einen Befehl hinzufügen, diesen Teil zum Laufen bringen und dann den nächsten Befehl anfügen.
