Was Sie nicht über AWS Glue wussten
Amazon Glue erfreut sich wachsender Beliebtheit, da immer mehr Unternehmen auf verwaltete Datenintegrationsdienste setzen.
Der ETL-Prozess (Extrahieren, Transformieren, Laden) ist eine Methode zur Übertragung von Daten aus einer Quelldatenbank in ein Data Warehouse. Aufgrund seiner Komplexität stellt er eine Herausforderung bei der Implementierung für alle Unternehmensdaten dar. Um dieses Problem zu lösen, hat Amazon AWS Glue eingeführt.
ETL-Entwickler und Dateningenieure nutzen Glue, um ETL-Workflows zu erstellen, zu überwachen und auszuführen.
Was ist AWS Glue?
AWS Glue, ein serverloser Datenintegrationsdienst, vereinfacht das Auffinden, Aufbereiten, Verschieben und Integrieren von Daten aus verschiedenen Quellen. Dies ist besonders nützlich für maschinelles Lernen (ML) und Datenanalysen.
Die für die Datenaufbereitung benötigte Zeit wird dadurch erheblich reduziert. Der Dienst findet und kategorisiert Daten automatisch, generiert Scala- oder Python-Code zur Datenübertragung und lädt sowie transformiert die Daten gemäß zeitgesteuerten Ereignissen.
Dies ermöglicht eine flexible Planung und schafft eine Apache Spark-Umgebung, die für das gezielte Laden von Daten skaliert werden kann. Darüber hinaus bietet AWS Glue umfassende Funktionen zur Überwachung und Änderung von Datenströmen. Als serverloser Dienst vereinfacht AWS Glue die komplexen Vorgänge der Anwendungsentwicklung.
AWS Glue ermöglicht die schnelle Integration verschiedener, gültiger Daten. Auch die Analyse und Autorisierung von Daten erfolgt in kurzer Zeit.
Wofür wird AWS Glue eingesetzt?
Es ist wichtig zu verstehen, wo Amazon Glue am besten eingesetzt wird. Hier sind einige Anwendungsbeispiele für AWS Glue, die Sie in Betracht ziehen sollten.
- Glue ist ein Werkzeug, das serverlose Abfragen in Amazon S3 Data Lakes ermöglicht. Der Einstieg wird durch Amazon Glue vereinfacht, indem alle Daten über eine einzige Schnittstelle zugänglich gemacht werden, sodass Analysen durchgeführt werden können, ohne die Daten verschieben zu müssen.
- Amazon Glue kann zur besseren Übersicht über Ihre Datenbestände genutzt werden. Der Datenkatalog von Amazon Glue erleichtert die Suche nach verschiedenen AWS-Datensätzen. Zudem können Sie mit dem Datenkatalog Daten über mehrere AWS-Dienste hinweg speichern und trotzdem eine konsistente Ansicht bewahren.
- Glue ist hilfreich bei der Erstellung ereignisgesteuerter ETL-Workflows. Sie können Ihre ETL-Operationen in Amazon S3 auslösen, indem Sie Ihre Glue-ETL-Aufgaben über einen AWS Lambda-Service aufrufen.
- AWS Glue kann auch zum Bereinigen, Verifizieren, Formatieren und Organisieren von Daten für die Speicherung in einem Data Lake oder Warehouse verwendet werden.
Welche Komponenten hat AWS Glue?
Im Folgenden werden die Hauptkomponenten von AWS Glue aufgeführt:
- Datenkatalog: Dieser Katalog enthält Metadaten und die Datenstruktur.
- Datenbank: Sie ist entscheidend für den Zugriff und die Erstellung der Datenbank für Quellen und Ziele.
- Tabelle: Erstellen Sie eine oder mehrere Tabellen in der Datenbank, die sowohl von der Quelle als auch vom Ziel verwendet werden können.
- Crawler und Classifier: Der Crawler ruft Daten aus der Quelle ab, indem er entweder integrierte oder benutzerdefinierte Klassifizierungen verwendet. Er erstellt/nutzt vordefinierte Metadatentabellen im Datenkatalog.
- Job: Dies ist der Auftrag der Geschäftslogik zur Ausführung einer ETL-Aufgabe. Diese Geschäftslogik wird intern von Apache Spark unter Verwendung von Python- und Scala-Sprachen geschrieben.
- Trigger: Ein ETL-Trigger ist ein Mechanismus, der die Ausführung eines ETL-Jobs bei Bedarf oder zu einem bestimmten Zeitpunkt initiiert.
- Entwicklungsendpunkt: Hiermit wird eine Umgebung geschaffen, in der das ETL-Jobskript getestet, entwickelt und debuggt werden kann.
Vorteile von AWS Glue
Dies sind einige Vorteile, die die Nutzung in Ihrem Unternehmen oder Ihrer Organisation mit sich bringt:
- AWS Glue scannt alle verfügbaren Daten mit einem Crawler.
- Die endgültig verarbeiteten Daten können an verschiedenen Orten gespeichert werden (Amazon RDS, Amazon Redshift, Amazon S3 usw.).
- Es handelt sich um einen Cloud-basierten Dienst, sodass keine Investitionen in eine lokale Infrastruktur erforderlich sind.
- Als serverloses ETL ist es eine kostengünstige Lösung.
- Es ist schnell. Es stellt den Python/Scala ETL-Code unmittelbar zur Verfügung.
Die wichtigsten Funktionen von AWS Glue?
Amazon Glue bietet alle notwendigen Funktionen für die Datenintegration, sodass Sie schneller zu besseren Erkenntnissen gelangen und Ihr Wissen effektiver nutzen können. Hier sind einige der wichtigsten Funktionen:
- Drag-and-Drop-Oberfläche: Mit einem Drag-and-Drop-Jobeditor können Sie ETL-Prozesse erstellen. AWS Glue generiert sofort den notwendigen Code zum Extrahieren, Konvertieren und Hochladen der Daten.
- Automatische Schemaerkennung: Sie können den Glue-Dienst verwenden, um Crawler zu erstellen, die Verbindungen zu verschiedenen Datenquellen herstellen. Die Daten werden organisiert und relevante Informationen extrahiert. Diese Daten können dann zur Überwachung von ETL-Prozessen über ETL-Tasks genutzt werden.
- Auftragsplanung: Glue kann nach Bedarf oder nach einem bestimmten Zeitplan verwendet werden. Der Scheduler ermöglicht die Erstellung komplexer ETL-Pipelines und die Definition von Abhängigkeiten zwischen Aufgaben.
- Codegenerierung: Mit Glue Elastic Views können auf einfache Weise materialisierte Ansichten erstellt werden, die Daten aus verschiedenen Datenquellen kombinieren und replizieren, ohne dass proprietärer Code erforderlich ist.
- Integriertes maschinelles Lernen: Glue verfügt über eine integrierte ML-Funktion namens "FindMatches". Sie dient zur Deduplizierung von Datensätzen, die keine perfekten Kopien voneinander sind.
- Entwickler-Endpunkte: Für die aktive Entwicklung von ETL-Code bietet Glue Entwickler-Endpunkte zum Ändern, Debuggen und Testen des erstellten Codes.
- Glue DataBrew: Es ist ein Tool zur Datenaufbereitung für Datenanalysten und -wissenschaftler, um Daten zu bereinigen und zu normalisieren. Es nutzt die aktive und visuelle Schnittstelle von Glue DataBrew.
Wie funktioniert die AWS Glue-Preisgestaltung?
AWS Glue berechnet stündliche Gebühren, die sekundengenau für Crawler (Datenermittlung) und ETL-Jobs (Datenverarbeitung und -laden) abgerechnet werden. Für den Zugriff auf und die Speicherung von Metadaten im AWS Glue-Datenkatalog wird eine monatliche Grundgebühr erhoben.
Amazon Glue beginnt bei 0,44 $. Es gibt vier Tarifpläne:
- ETL-Aufgaben, Entwicklungsendpunkte und andere ETL-Aufgaben sind für 0,44 $ erhältlich
- Interaktive Crawler-Sitzungen sind für 0,44 $ erhältlich
- DataBrew-Jobs beginnen bei 0,48 $
- Monatliche Speicherung und Anfragen an den Data Catalog kosten 1,00 USD
AWS bietet keinen kostenlosen Glue-Plan an. Jede Stunde kostet 0,44 $ pro DPU. Im Durchschnitt würden Sie etwa 21 $ pro Tag zahlen. Die Preise können je nach Standort variieren.
Schritte zur Einrichtung von AWS Glue
Mit dem Datenkatalog können Sie mehrere AWS-Datensätze schnell finden und durchsuchen, ohne die Daten verschieben zu müssen. Nach der Katalogisierung sind die Daten sofort für Abfragen und Recherchen mit Amazon Athena und Amazon EMR verfügbar.
Ref: https://aws.amazon.com/glue/
- Amazon Redshift, Amazon S3, Amazon RDS und Datenbanken auf Amazon EC2 – Entdecken Sie Ihre Daten, speichern Sie Metadaten und nutzen Sie den AWS Glue-Datenkatalog zur weiteren Verwendung.
- AWS Glue-Datenkatalog – Verwalten Sie Daten mit dem Datenkatalog, der als zentrales Metadaten-Repository dient.
- AWS Glue ETL – Lesen und Schreiben von Metadaten in Ihren Datenkatalog.
- Amazon Athena und Amazon Redshift, Amazon EMR, Amazon ETL – Nutzen Sie den Datenkatalog für ETL, Analysen und mehr.
Wie richte ich AWS Glue ein?
Melden Sie sich zunächst bei der AWS Management Console an und öffnen Sie die IAM-Konsole. Klicken Sie auf "Rolle erstellen". Suchen Sie dann nach dem Rollentyp "Glue" und wählen Sie die Berechtigungen aus.
Wählen Sie "AWSGlueServiceRole" für allgemeine AWS Glue Studio- und AWS Glue-Berechtigungen sowie die von AWS verwaltete Richtlinie "AmazonS3FullAccess" für den Zugriff auf Amazon S3-Ressourcen.
Geben Sie einen Rollennamen ein.
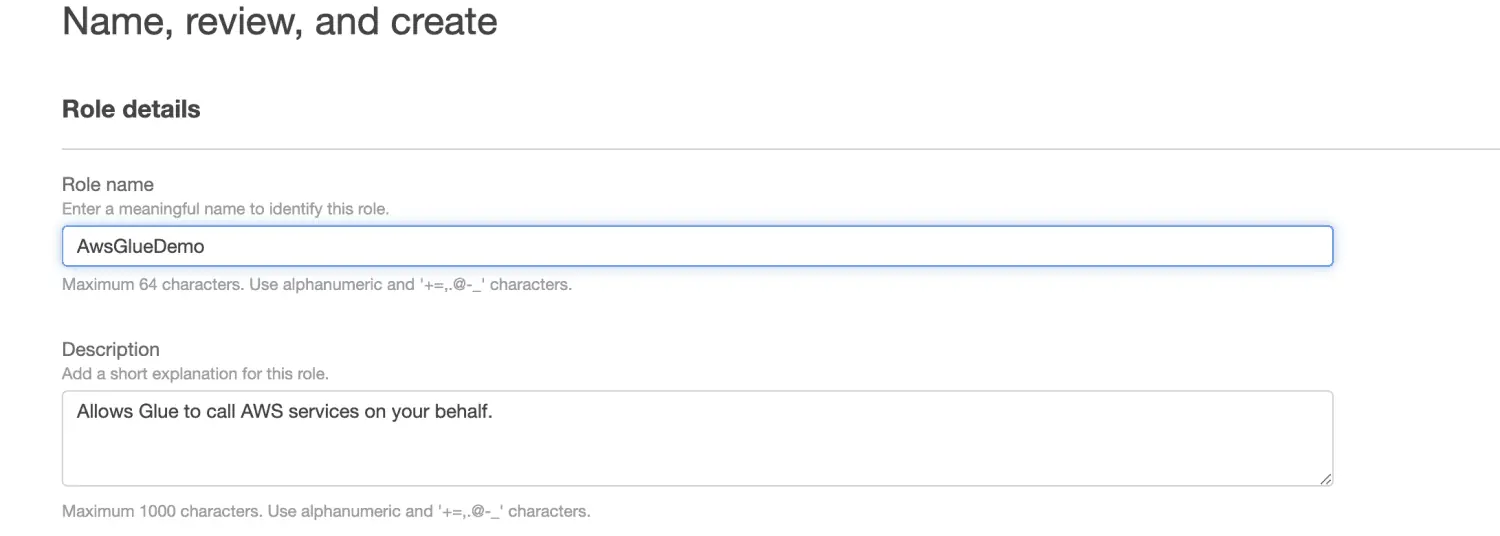
Klicken Sie auf "Rolle erstellen".
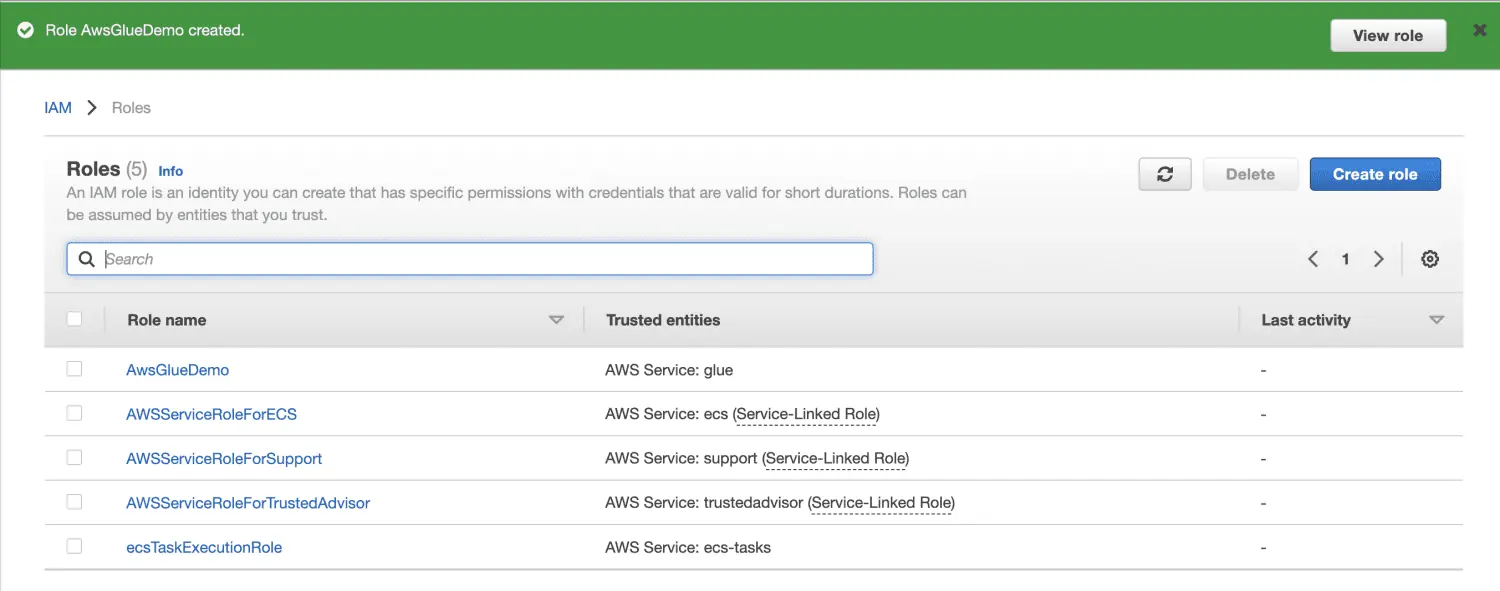
Erstellen Sie einen Amazon S3-Bucket.
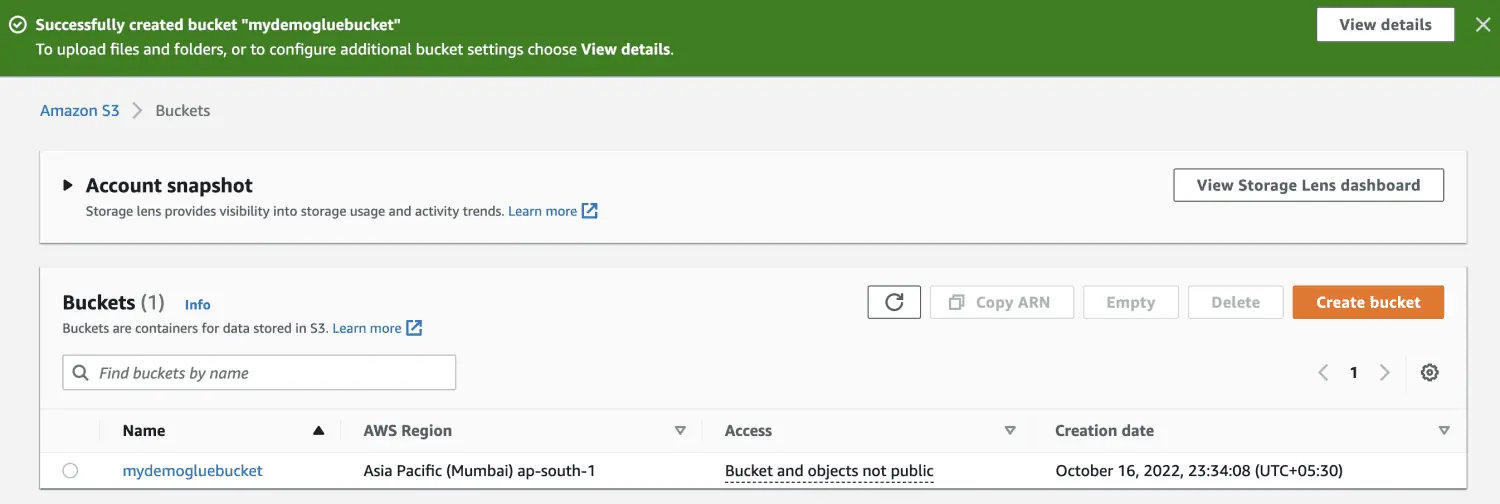
Erstellen Sie einen Ordner im S3-Bucket.
Wählen Sie die hochzuladende Datei aus.
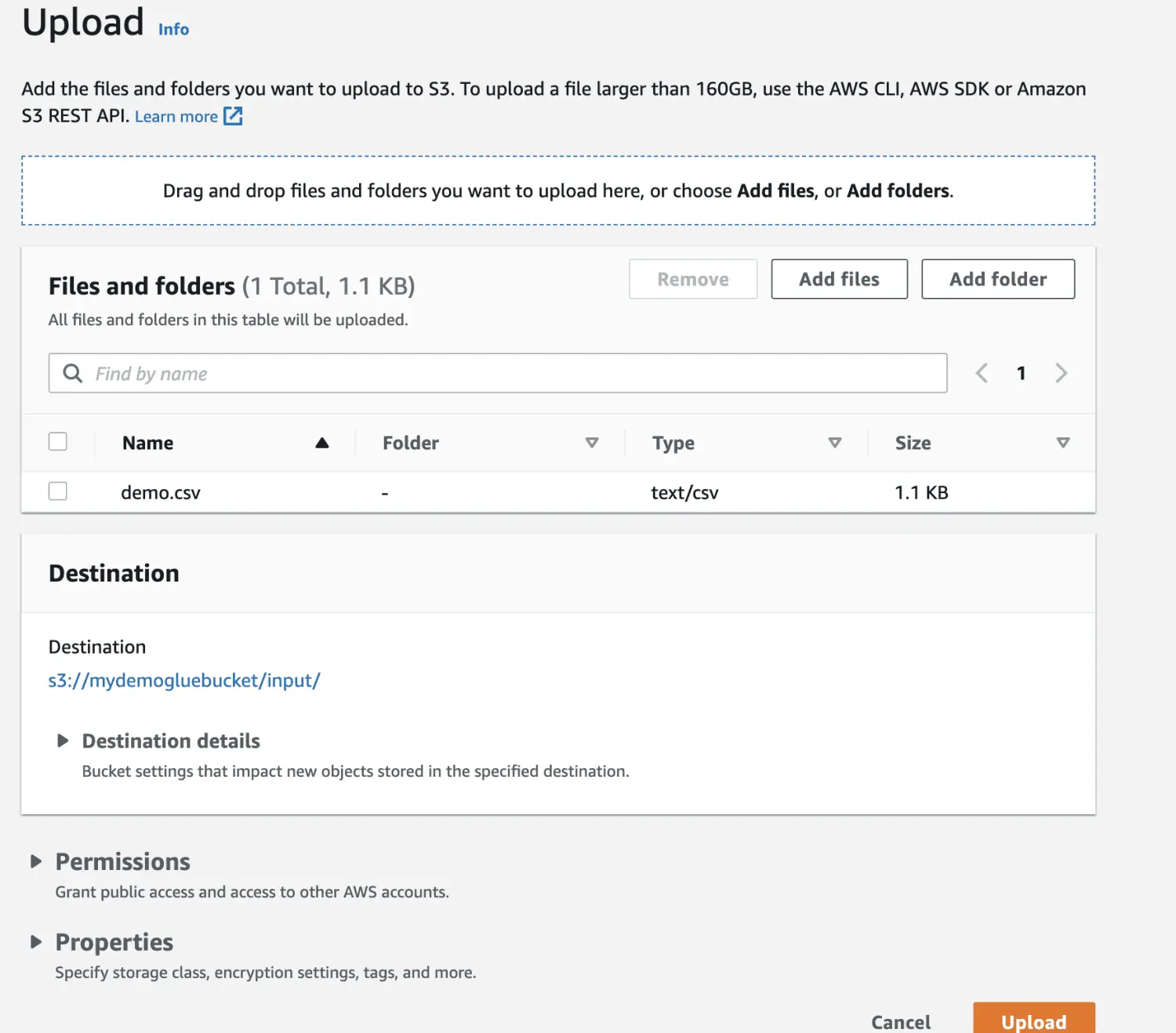
Laden Sie die Datei in den Bucket hoch.
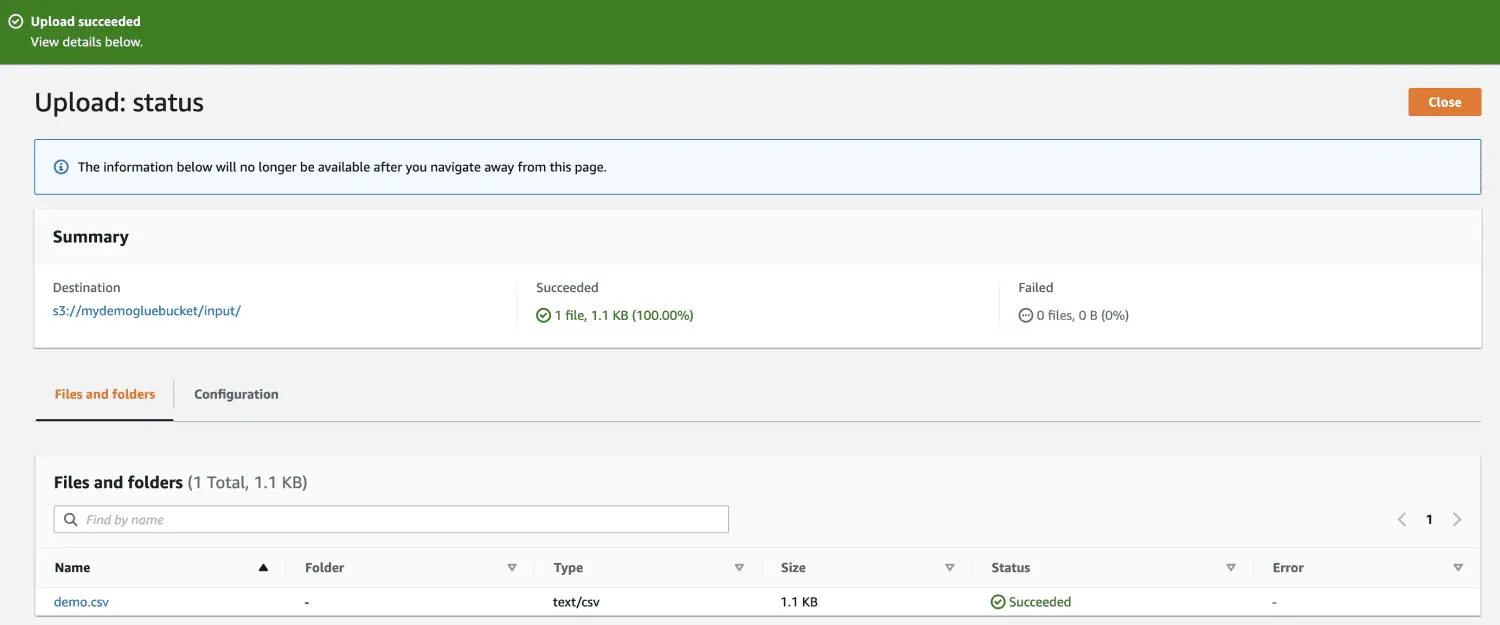
Öffnen Sie AWS Glue über die AWS-Verwaltungskonsole und erstellen Sie eine Datenbank.
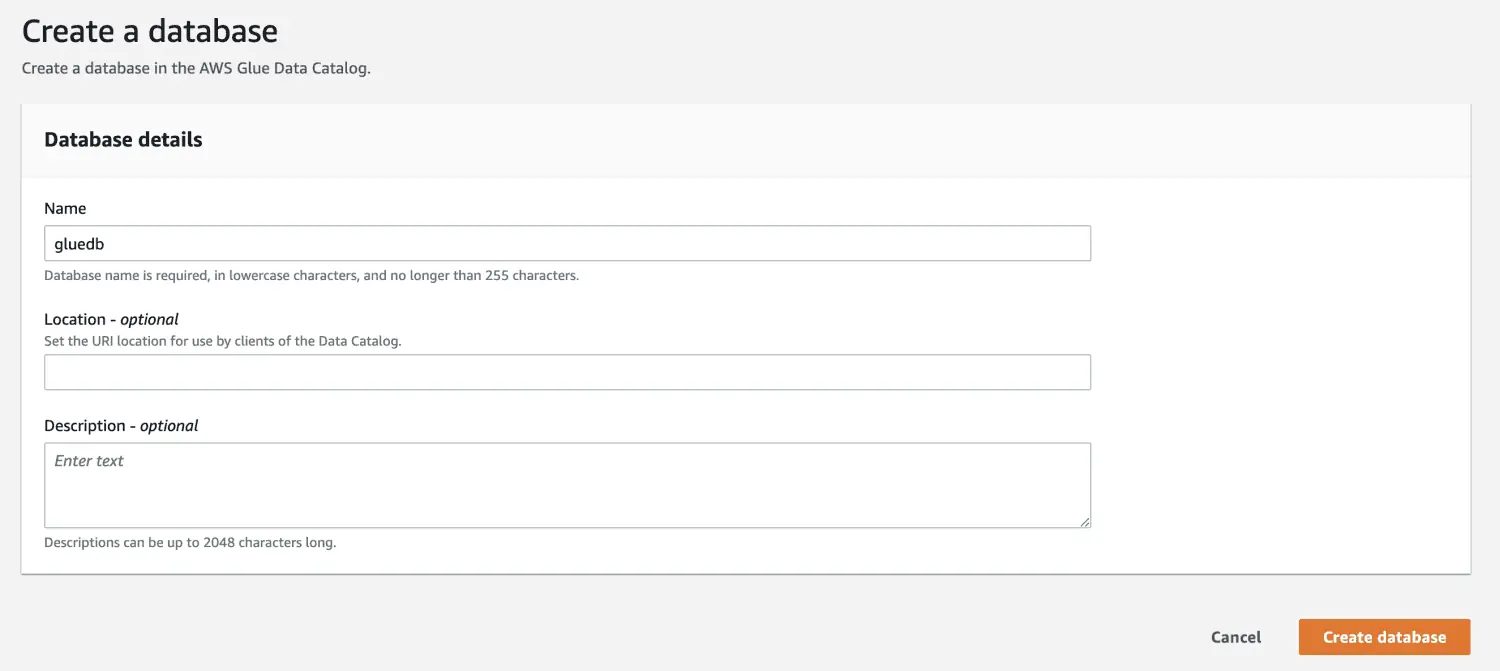
Nachdem Sie eine Datenbank in AWS Glue erstellt haben, erstellen Sie einen Crawler.
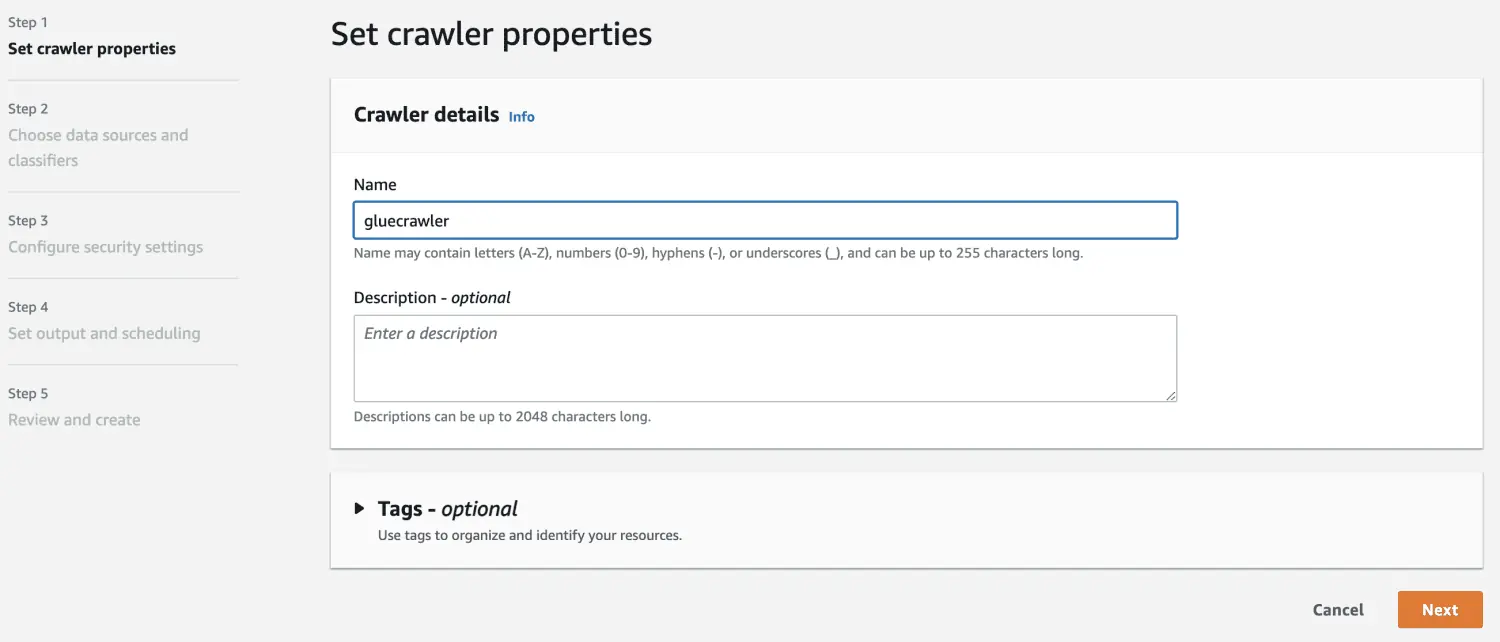
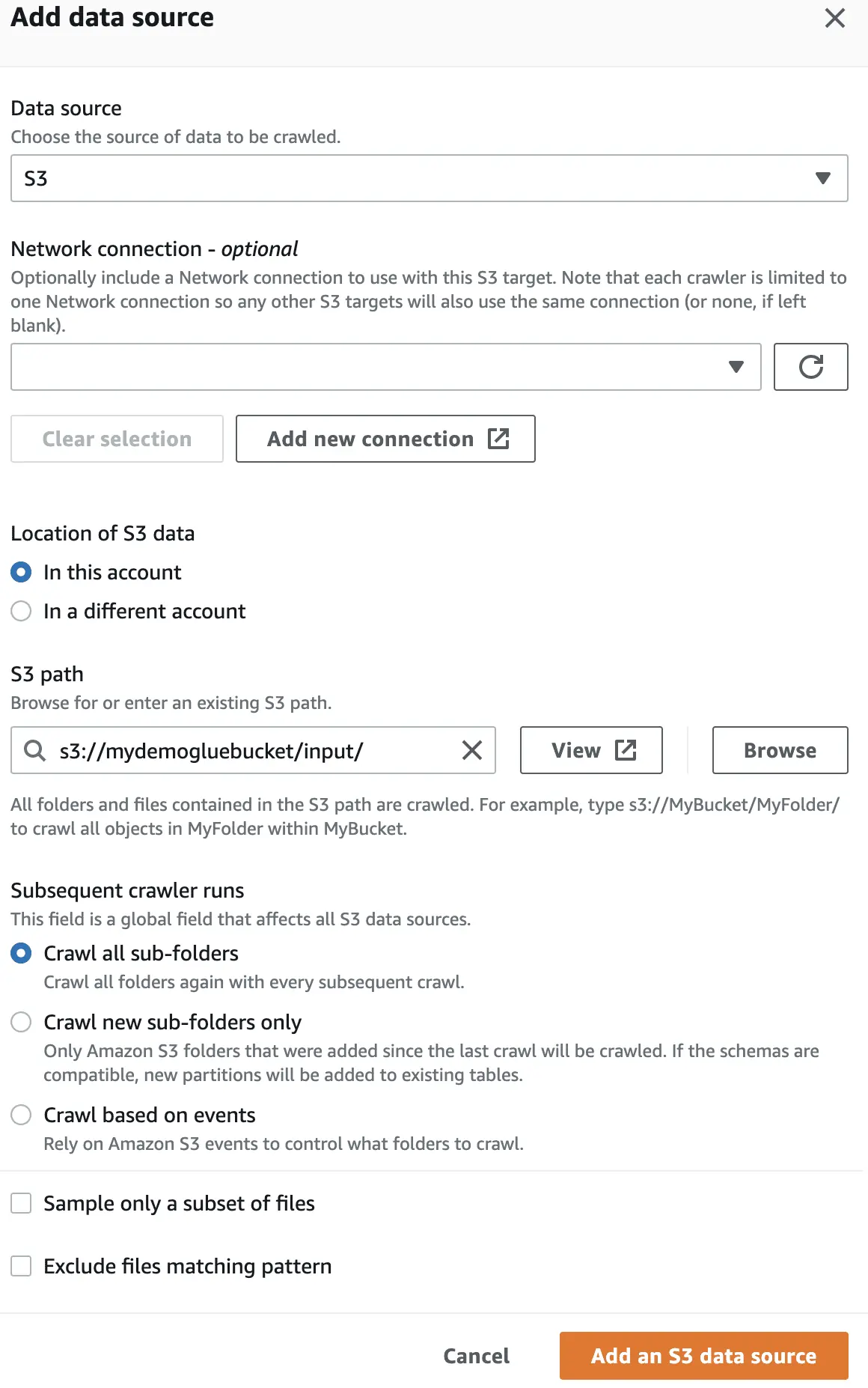
Wählen Sie in der Datenquelle den erstellten S3-Bucket aus.
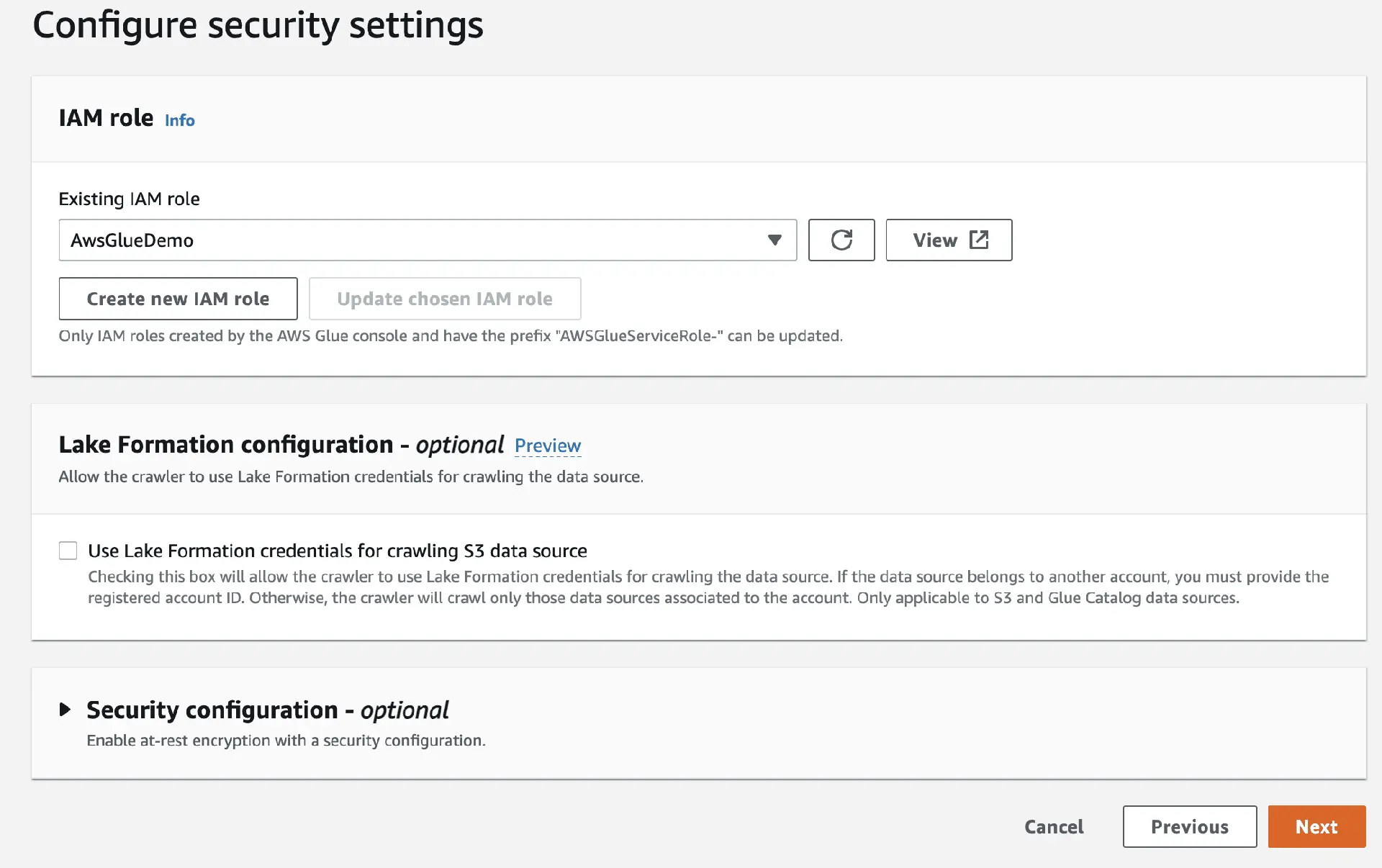
Wählen Sie als Nächstes die IAM-Rolle für AWS Glue, die Sie zuvor erstellt haben.
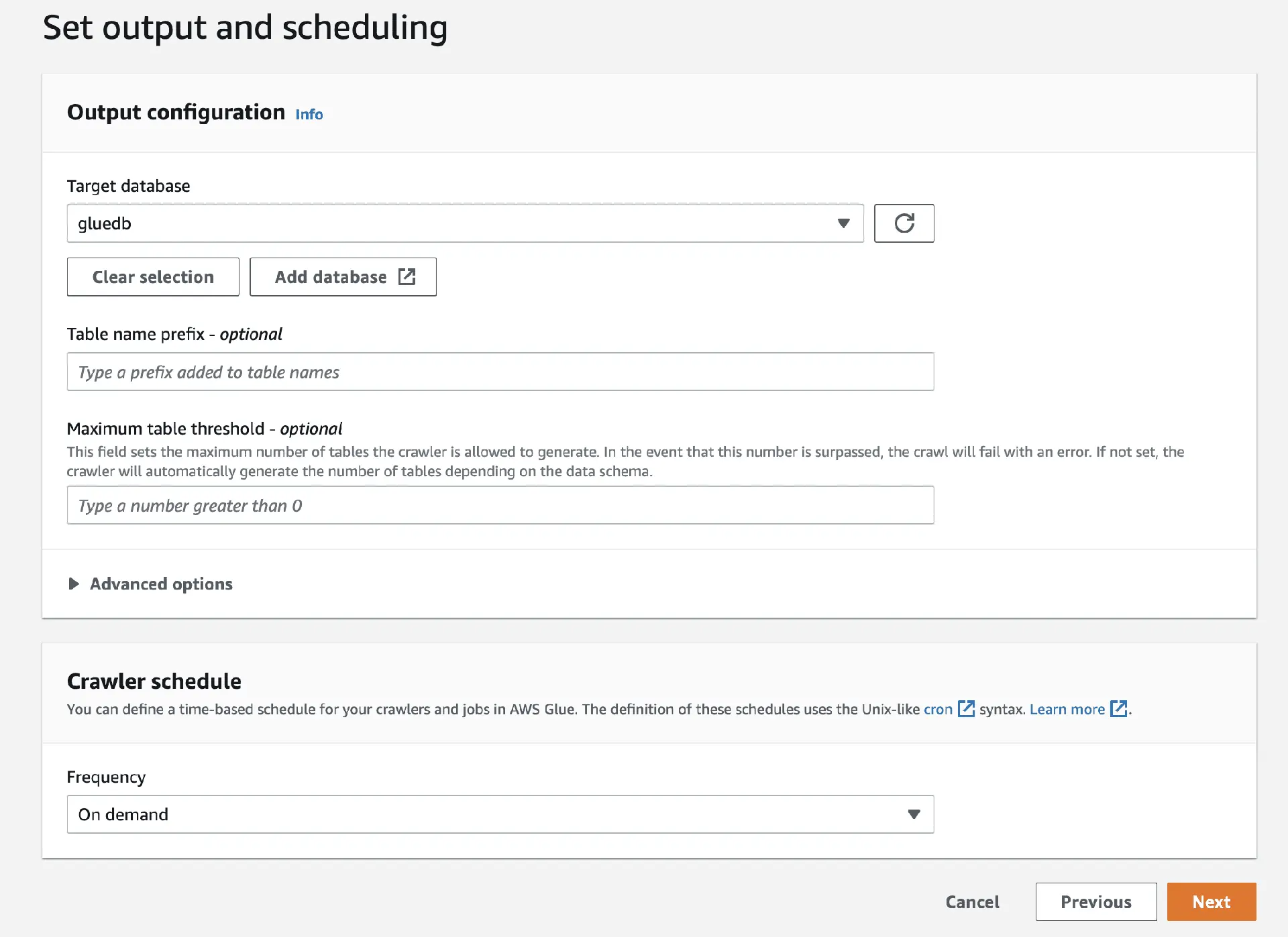
Wählen Sie in der Ausgabe die erstellte "gluedb" aus.
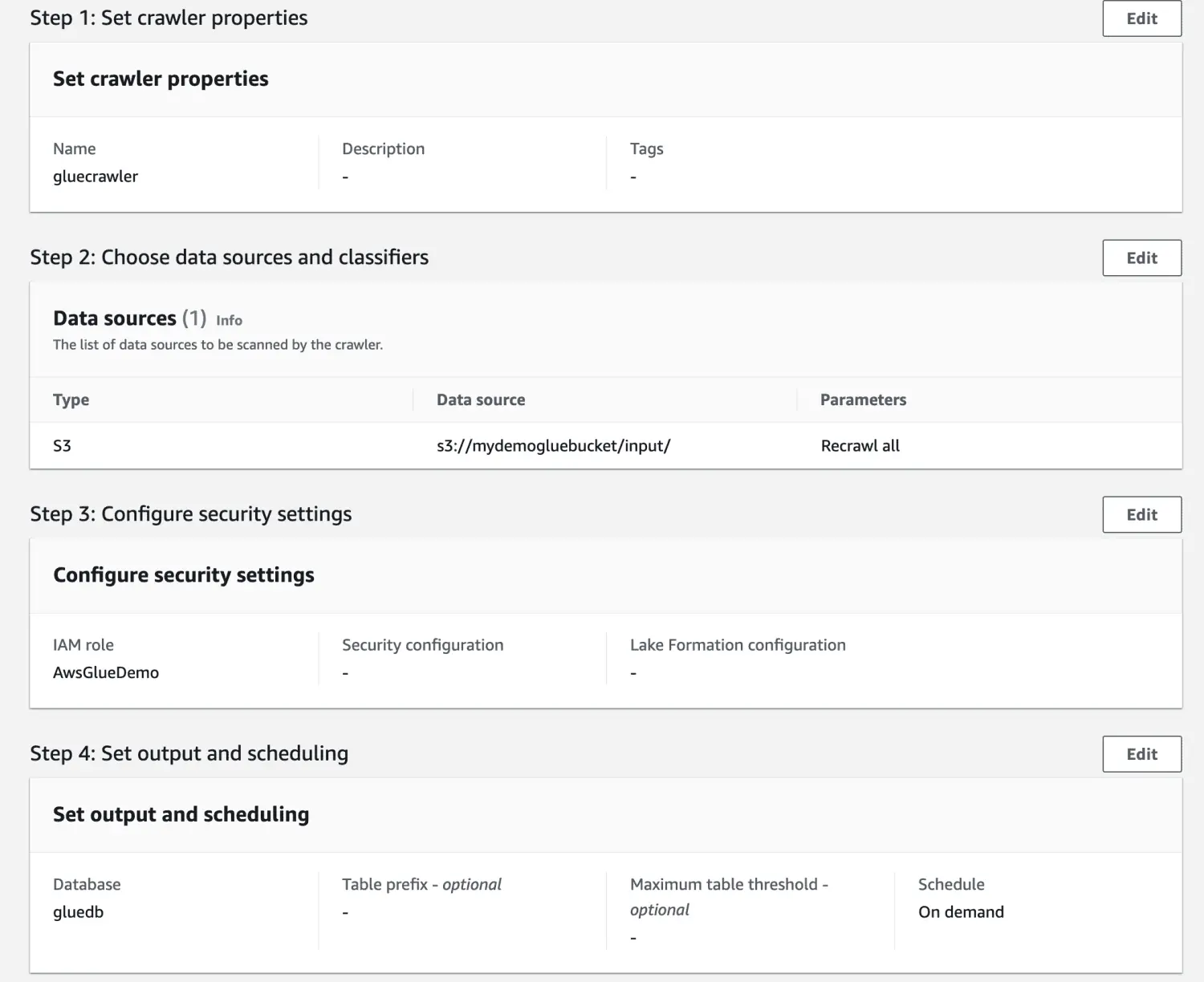
Überprüfen Sie alle Einstellungen und erstellen Sie den Crawler.
Nachdem der Crawler erstellt wurde, wählen Sie ihn aus und klicken Sie auf "Ausführen". Nach einiger Zeit wird der Status "bereit" angezeigt.
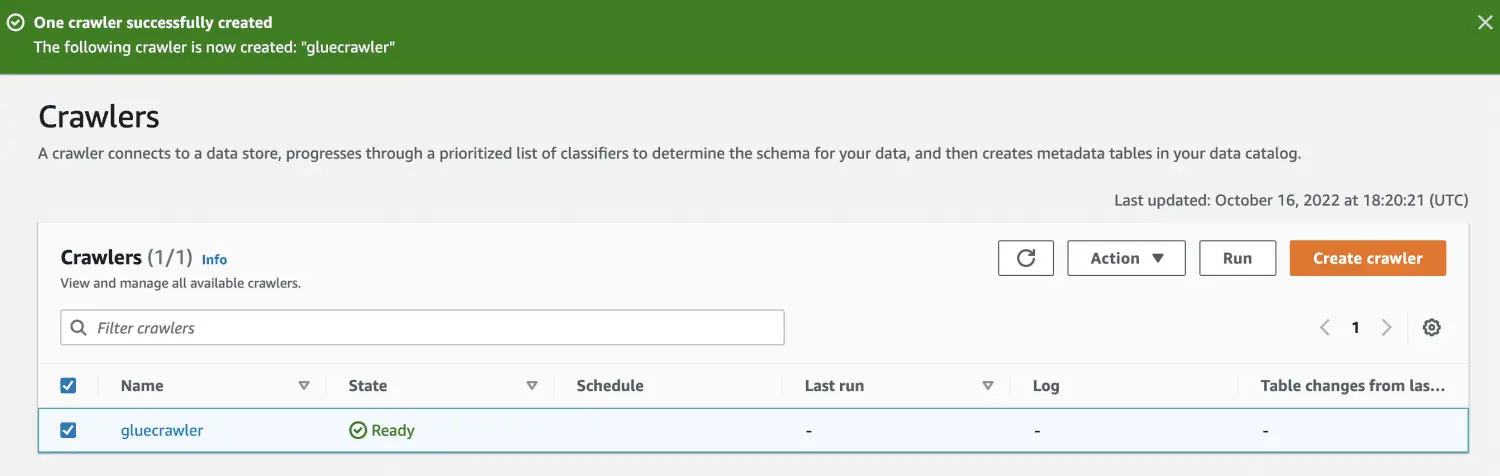
Durch Ausführen des Crawlers wird der Datenbank eine Tabelle mit allen Daten aus der CSV-Datei hinzugefügt.
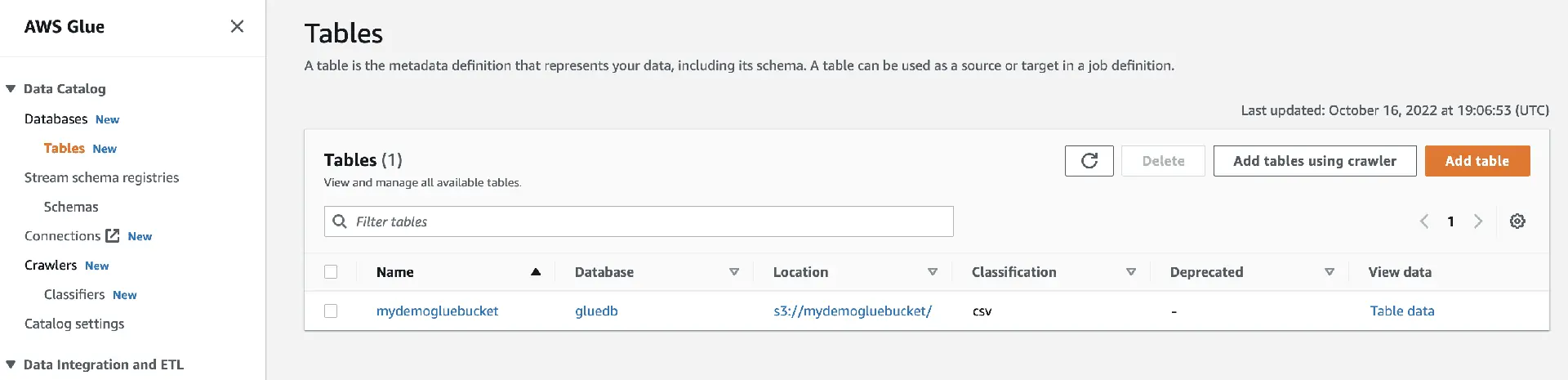
Wenn Sie auf "Daten anzeigen" klicken, werden Sie zu Amazon Athena (Abfrage-Editor) weitergeleitet. Führen Sie die Abfrage aus, um die Tabellendaten anzuzeigen.
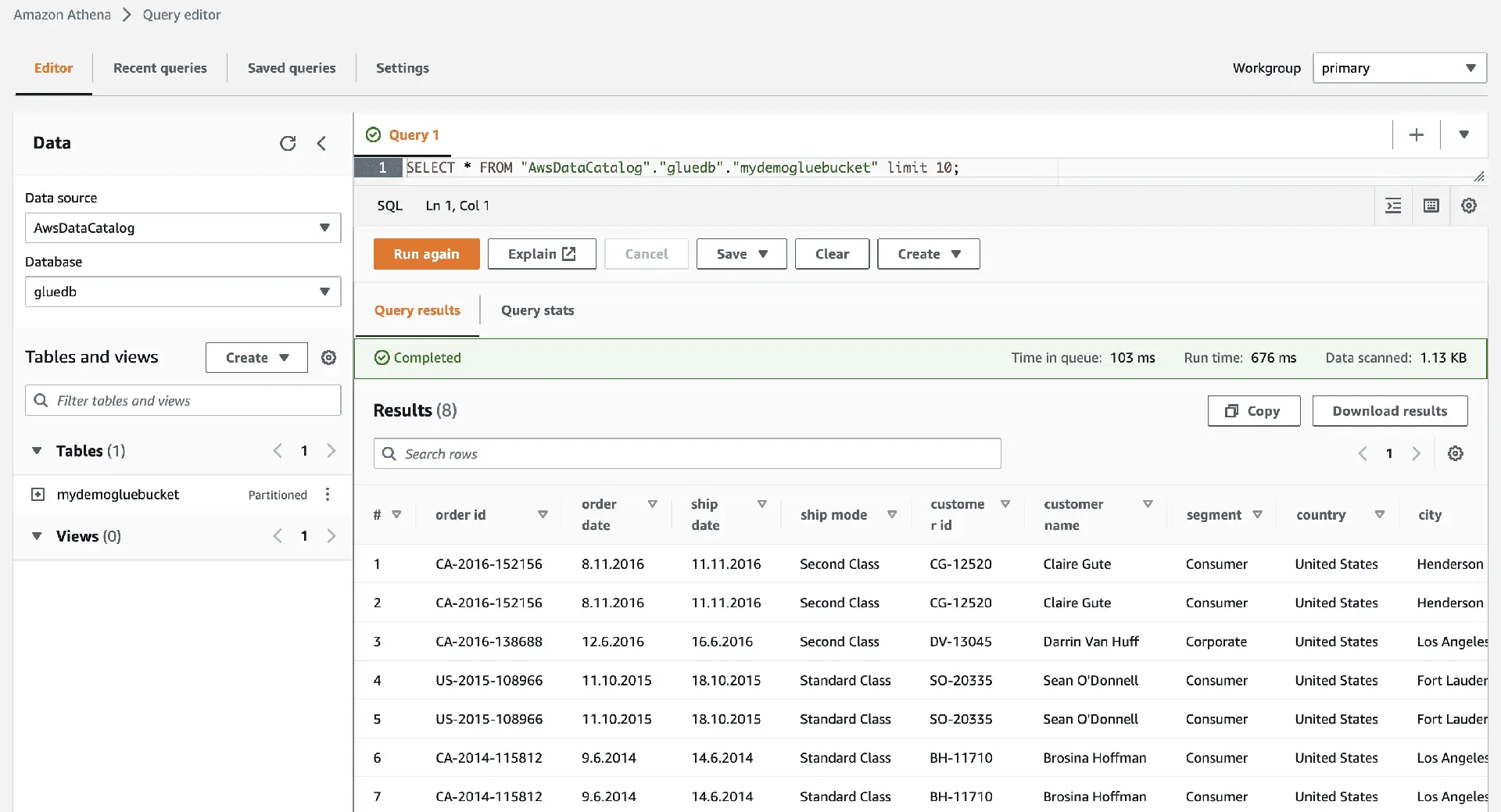
Jetzt können Sie diesen AWS Glue-Crawler erfolgreich in jedem ETL-Job verwenden.
Was ist AWS Glue DataBrew?
Mit AWS Glue DataBrew können Benutzer Daten normalisieren und bereinigen, ohne Code schreiben zu müssen. Im Vergleich zu einer kundenspezifisch entwickelten Datenaufbereitung kann DataBrew den Zeitaufwand für die Vorbereitung von Daten für maschinelles Lernen und Analysen um bis zu 80 Prozent reduzieren.
Es stehen über 250 vorgefertigte Datentransformationen zur Verfügung, um Datenaufbereitungsaufgaben wie das Herausfiltern von Anomalien, das Korrigieren ungültiger Werte und das Konvertieren von Daten in Standardformate zu automatisieren.
DataBrew erleichtert Datenwissenschaftlern, Geschäftsanalysten und Ingenieuren die Zusammenarbeit bei der Gewinnung von Erkenntnissen aus Rohdaten. Da DataBrew serverlos ist, müssen keine Infrastrukturen oder Cluster verwaltet werden, um Rohdaten im Umfang von Terabytes zu untersuchen und zu transformieren.
DataBrew-Funktionen für Unternehmen
Visualisierte Datenaufbereitung
DataBrew stellt Daten anders dar, als sie in spaltenorientierten Datenbanken als alphanumerische Zeichen angezeigt werden. DataBrew visualisiert alle geladenen Datenquellen, um die Datenbeziehungen und -hierarchie besser zu verstehen.
Über 250 Datenvorbereitungsautomatisierungen
Von Datenwissenschaftlern wird erwartet, dass sie im Rahmen ihrer Aufgaben einer Reihe wiederholbarer und isolierter Arbeitsabläufe folgen. Diese Workflows und Prozesse wurden von AWS als sprach- und datenunabhängige Module modelliert. Diese Bibliothek enthält Aktionen, die von Endbenutzern verwendet werden können.
Datenherkunft
Ähnlich wie bei Audit-Logs, die zur Nachverfolgung von Benutzeraktivitäten im IT-Netzwerk dienen, ermöglicht die Datenherkunft die Verfolgung der Datentransformationsaktivitäten innerhalb von AWS DataBrew. Zu diesen Informationen gehören die Datenquelle, die angewendeten Transformationen und die Datenausgabe, einschließlich des Zielspeicherorts.
Datenmapping
Mit Databrew können übereinstimmende Felder in zwei Datenquellen identifiziert werden. Sobald passende Felder gefunden wurden, können diese in ein Schema geladen werden.
AWS Glue DataBrew: Vorteile
Im Folgenden werden die Funktionen von AWS Glue DataBrew aufgeführt:
- Niedrigere Hürden für die Datenaufbereitung
- Automatisierte Datenprofilerstellung
- Automatisierung von mehr als 250 Datenvorbereitungsprozessen
- Intelligente Regulierungsratschläge
Alternativen zu AWS Glue
Airflow

Airflow gehört zum Workflow-Manager-Segment eines Tech-Stacks. Es ist ein Open-Source-Tool, das GitHub-Stars, GitHub-Forks und andere Funktionen unterstützt. Mit Airflow können Sie Workflows mithilfe von gerichteten azyklischen Graphen (DAGs) erstellen. Der Airflow-Scheduler führt Ihre Aufgaben mit einer Reihe von Workern gemäß den definierten Abhängigkeiten aus.
Matillion

Matillion ETL, ein ETL/ELT-Tool, wurde speziell für Cloud-Datenbankplattformen wie Amazon Redshift und Google BigQuery entwickelt. Es verfügt über eine moderne, browserbasierte Benutzeroberfläche mit leistungsstarken Pushdown-ETL/ELT-Funktionen. Dank der schnellen Einrichtung können Sie in wenigen Minuten einsatzbereit sein.
Stitch
Stitch ist ein Open-Source-ETL-Dienst, der mehrere Datenquellen verbindet und Daten an bevorzugte Ziele repliziert. Die Bedienung ist sehr einfach, da keine Programmierkenntnisse erforderlich sind, um Daten zwischen Quellen und Zielen in Stitch zu verschieben. Es ist benutzerfreundlich, verfügt über eine intuitive GUI und arbeitet schnell.
Im Gegensatz zu anderen ETL-Tools können Sie in Stitch kein vorgefertigtes Dashboard wählen. Stattdessen müssen Sie Ihre Daten in die von Ihnen als Ziel ausgewählten offenen Data Warehouses integrieren. Die Navigation innerhalb der Inventare kann schwierig sein.
Alteryx

Alteryx ist eine Analytics-Automatisierungsplattform, die bei der Vorbereitung und Zusammenführung der Datenerfassung hilft. Diese Daten können zur Beschleunigung von Prozessen und zur Generierung von Geschäftserkenntnissen genutzt werden. Da es sich um ein Drag-and-Drop-Tool handelt, sind keine Programmierkenntnisse erforderlich. Alteryx ist eine gute Anlaufstelle für Ratschläge und Antworten von Branchenexperten.
Fazit
Das war ein Überblick über AWS Glue, eine Cloud-basierte Lösung zur Arbeit mit ETL-Pipelines. Der Benutzerinteraktionsprozess von AWS Glue besteht im Wesentlichen aus drei Phasen: Zunächst werden Daten-Crawler zur Erstellung eines Datenkatalogs genutzt. Anschließend wird der ETL-Code für die AWS-Datenpipeline erstellt. Schließlich wird der ETL-Zeitplan definiert. Ich hoffe, dieser Blog hat Ihnen einen guten Einblick in Amazon Glue gegeben.
Vielleicht interessieren Sie auch die besten Tipps zur Sicherung von AWS S3-Speicher.