Was ist eine Konfusionsmatrix beim maschinellen Lernen?
Eine Konfusionsmatrix ist ein wichtiges Hilfsmittel, um die Leistungsfähigkeit von Klassifikationsalgorithmen im Bereich des überwachten maschinellen Lernens zu beurteilen.
Was verbirgt sich hinter dem Begriff "Konfusionsmatrix"?
Die menschliche Wahrnehmung ist subjektiv – selbst bei der Unterscheidung zwischen Wahrheit und Lüge. Eine Linie, die für mich 10 cm lang erscheint, mag für Sie 9 cm messen. Der tatsächliche Wert kann jedoch 9, 10 oder ein ganz anderer sein. Entscheidend ist der vorhergesagte Wert!
Die Arbeitsweise des menschlichen Gehirns
So wie unser Gehirn eigene Logik zur Vorhersage nutzt, setzen Maschinen verschiedene Algorithmen (sogenannte Algorithmen des maschinellen Lernens) ein, um einen Wert für eine Fragestellung zu ermitteln. Diese Werte können mit dem tatsächlichen Wert übereinstimmen oder davon abweichen.
In einer wettbewerbsorientierten Welt ist es wichtig, zu verstehen, ob unsere Vorhersage richtig ist, um unsere Leistung zu bewerten. Analog dazu können wir die Leistung eines Algorithmus für maschinelles Lernen anhand der Anzahl korrekter Vorhersagen beurteilen.
Was genau ist ein Algorithmus für maschinelles Lernen?
Maschinen versuchen, bestimmte Lösungen für ein Problem zu finden, indem sie eine spezifische Logik oder eine Reihe von Anweisungen verwenden, die als Algorithmen für maschinelles Lernen bekannt sind. Es gibt drei Haupttypen von Algorithmen für maschinelles Lernen: überwachtes, unüberwachtes und bestärkendes Lernen.
Verschiedene Arten von Algorithmen für maschinelles Lernen
Die einfachsten Algorithmen sind überwacht, d.h. die Antwort ist uns bekannt und wir trainieren die Maschinen, um diese Antwort zu finden, indem wir den Algorithmus mit vielen Daten füttern – ähnlich wie ein Kind lernt, Menschen verschiedener Altersgruppen anhand ihrer Gesichtszüge zu unterscheiden.
Es gibt zwei Hauptkategorien von Algorithmen für überwachtes ML: Klassifikation und Regression.
Klassifikationsalgorithmen ordnen oder sortieren Daten anhand bestimmter Kriterien. Möchte man beispielsweise Kunden nach ihren Essensvorlieben gruppieren (Pizza-Liebhaber vs. Nicht-Pizza-Liebhaber), könnte man einen Klassifikationsalgorithmus wie Entscheidungsbäume, Random Forests, Naive Bayes oder SVM (Support Vector Machine) verwenden.
Welcher dieser Algorithmen würde am besten funktionieren? Warum sollte man einen Algorithmus einem anderen vorziehen?
Hier kommt die Konfusionsmatrix ins Spiel...
Eine Konfusionsmatrix ist eine tabellarische Darstellung, die Informationen darüber liefert, wie präzise ein Klassifikationsalgorithmus bei der Kategorisierung eines Datensatzes ist. Der Name ist vielleicht etwas irreführend, aber viele falsche Vorhersagen deuten wahrscheinlich darauf hin, dass der Algorithmus verwirrt war 😉!
Eine Konfusionsmatrix ist somit eine Methode zur Bewertung der Leistung eines Klassifikationsalgorithmus.
Wie funktioniert das?
Nehmen wir an, Sie haben verschiedene Algorithmen auf unser vorheriges binäres Problem angewendet: die Klassifizierung (Aufteilung) von Personen danach, ob sie Pizza mögen oder nicht. Um den Algorithmus zu bewerten, dessen Werte der tatsächlichen Antwort am nächsten kommen, würden Sie eine Konfusionsmatrix verwenden. Bei einem binären Klassifikationsproblem (Gefällt mir/Gefällt mir nicht, Richtig/Falsch, 1/0) liefert die Konfusionsmatrix vier Gitterwerte, nämlich:
- Wahr Positiv (TP)
- Wahr Negativ (TN)
- Falsch Positiv (FP)
- Falsch Negativ (FN)
Was bedeuten die vier Felder der Konfusionsmatrix?
Die vier aus der Konfusionsmatrix abgeleiteten Werte bilden die Felder der Matrix.
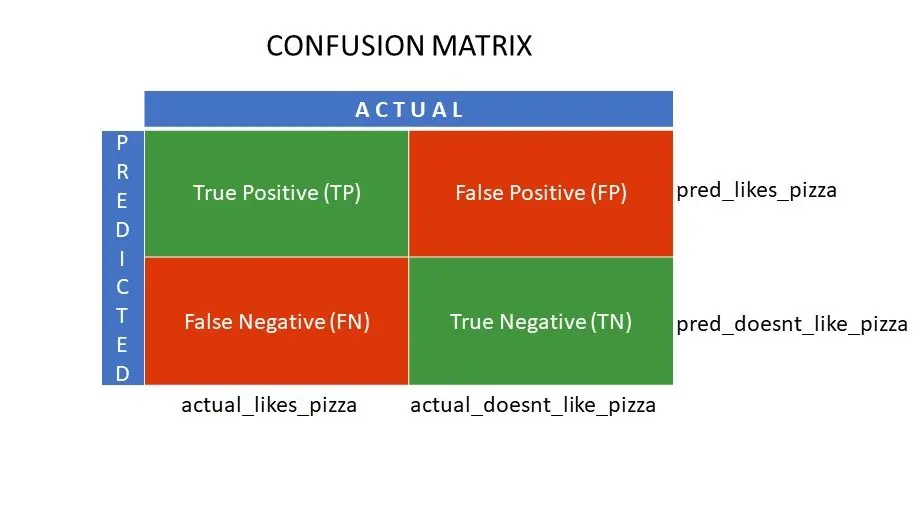
Wahr Positiv (TP) und Wahr Negativ (TN) sind die vom Klassifikationsalgorithmus korrekt vorhergesagten Werte.
- TP steht für die Personen, die Pizza mögen, und das Modell hat sie korrekt klassifiziert.
- TN steht für die Personen, die keine Pizza mögen, und das Modell hat sie korrekt klassifiziert.
Falsch Positiv (FP) und Falsch Negativ (FN) sind die Werte, die vom Klassifikator falsch vorhergesagt werden.
- FP steht für die Personen, die keine Pizza mögen (negativ), aber der Klassifikator hat fälschlicherweise vorhergesagt, dass sie Pizza mögen (positiv). FP wird auch als Typ-I-Fehler bezeichnet.
- FN steht für die Personen, die Pizza mögen (positiv), aber der Klassifikator hat fälschlicherweise vorhergesagt, dass sie keine Pizza mögen (negativ). FN wird auch als Typ-II-Fehler bezeichnet.
Um das Konzept besser zu veranschaulichen, betrachten wir ein reales Szenario.
Nehmen wir an, Sie haben einen Datensatz mit 400 Personen, die sich einem Covid-Test unterzogen haben. Sie haben nun die Ergebnisse verschiedener Algorithmen erhalten, die die Anzahl der Covid-positiven und Covid-negativen Personen ermittelt haben.
Hier sind zwei Konfusionsmatrizen zum Vergleich:
Auf den ersten Blick könnte man sagen, dass der erste Algorithmus genauer ist. Um jedoch ein konkretes Ergebnis zu erhalten, benötigen wir Kennzahlen, die die Genauigkeit, Präzision und viele andere Werte messen können, um zu beweisen, welcher Algorithmus besser ist.
Kennzahlen der Konfusionsmatrix und ihre Bedeutung
Die wichtigsten Kennzahlen, die uns bei der Entscheidung helfen, ob der Klassifikator korrekte Vorhersagen getroffen hat, sind:
#1. Recall / Sensitivität
Recall, Sensitivität oder True Positive Rate (TPR) oder Wahrscheinlichkeit der Erkennung ist das Verhältnis der korrekt positiven Vorhersagen (TP) zu allen Positiven (d.h. TP und FN).
R = ZP/(ZP + FN)
Recall ist ein Maß für die korrekten positiven Ergebnisse, die aus der Anzahl der korrekten positiven Ergebnisse zurückgegeben werden, die hätten produziert werden können. Ein höherer Recall-Wert bedeutet, dass es weniger falsch negative Ergebnisse gibt, was für den Algorithmus vorteilhaft ist. Nutzen Sie Recall, wenn es wichtig ist, die falsch negativen Ergebnisse zu berücksichtigen. Wenn beispielsweise eine Person mehrere Verstopfungen im Herzen hat und das Modell anzeigt, dass es ihr gut geht, könnte das tödlich enden.
#2. Präzision
Die Präzision ist das Maß der korrekten positiven Ergebnisse von allen vorhergesagten positiven Ergebnissen, einschließlich der korrekten und falschen positiven Ergebnisse.
Pr = TP/(TP + FP)
Die Präzision ist besonders wichtig, wenn Fehlalarme nicht ignoriert werden dürfen. Wenn beispielsweise eine Person keinen Diabetes hat, das Modell dies aber anzeigt und der Arzt bestimmte Medikamente verschreibt, könnte dies zu schwerwiegenden Nebenwirkungen führen.
#3. Spezifität
Die Spezifität oder True Negative Rate (TNR) sind korrekte negative Ergebnisse, die aus allen Ergebnissen ermittelt wurden, die negativ hätten sein können.
S = TN/(TN + FP)
Es ist ein Maß dafür, wie gut Ihr Klassifikator die negativen Werte identifiziert.
#4. Genauigkeit
Die Genauigkeit gibt an, wie viele Vorhersagen insgesamt richtig waren. Wenn Sie beispielsweise 20 positive und 10 negative Werte aus einer Stichprobe von 50 richtig identifiziert haben, beträgt die Genauigkeit Ihres Modells 30/50.
Genauigkeit A = (TP + TN)/(TP + TN + FP + FN)
#5. Prävalenz
Die Prävalenz misst den Anteil der positiven Ergebnisse an allen Ergebnissen.
P = (TP + FN)/(TP + TN + FP + FN)
#6. F-Score
Manchmal ist es schwierig, zwei Klassifikatoren (Modelle) nur mit Precision und Recall zu vergleichen, die lediglich arithmetische Mittel einer Kombination der vier Felder sind. In solchen Fällen kann der F-Score oder F1-Score verwendet werden, der das harmonische Mittel ist – das genauer ist, da es bei extrem hohen Werten nicht so stark variiert. Ein höherer F-Score (maximal 1) weist auf ein besseres Modell hin.
F-Score = 2 * Präzision * Recall / (Recall + Präzision)
Wenn es wichtig ist, sowohl falsch positive als auch falsch negative Ergebnisse zu berücksichtigen, ist der F1-Score eine gute Kennzahl. Beispielsweise sollten Personen, die nicht Covid-positiv sind (aber der Algorithmus hat dies angezeigt), nicht unnötig isoliert werden. Ebenso müssen Personen, die Covid-positiv sind (aber der Algorithmus hat dies nicht angezeigt), isoliert werden.
#7. ROC-Kurven
Kennzahlen wie Genauigkeit und Präzision sind dann aussagekräftig, wenn die Daten ausgewogen sind. Bei einem unausgeglichenen Datensatz bedeutet eine hohe Genauigkeit nicht unbedingt, dass der Klassifikator effizient arbeitet. Wenn beispielsweise 90 von 100 Schülern in einem Kurs Spanisch sprechen, würde Ihr Algorithmus mit einer Genauigkeit von 90 % arbeiten, wenn er behauptet, dass alle 100 Schüler Spanisch sprechen – was ein falsches Bild der Effizienz vermitteln kann. Bei unausgeglichenen Datensätzen sind Metriken wie ROC effektivere Bestimmungsfaktoren.
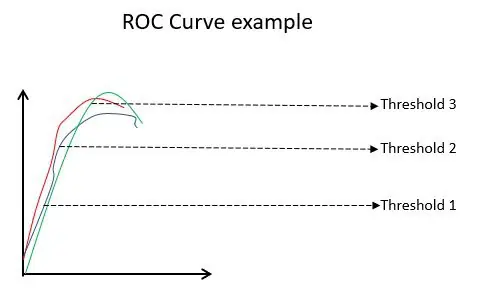
Die ROC-Kurve (Receiver Operating Characteristic) veranschaulicht die Leistung eines binären Klassifikationsmodells bei verschiedenen Klassifizierungsschwellenwerten. Sie ist ein Diagramm von TPR (True Positive Rate) gegen FPR (False Positive Rate), das als (1 - Spezifität) bei verschiedenen Schwellenwerten berechnet wird. Der Wert, der im Diagramm am nächsten an 45 Grad (oben links) liegt, ist der genaueste Schwellenwert. Wenn der Schwellenwert zu hoch ist, werden wir nicht viele falsch positive Ergebnisse haben, aber mehr falsch negative, und umgekehrt.
Wenn die ROC-Kurven für verschiedene Modelle aufgezeichnet werden, gilt im Allgemeinen dasjenige mit der größten Fläche unter der Kurve (AUC) als das bessere Modell.
Lassen Sie uns alle Kennzahlen für unsere Konfusionsmatrizen für Klassifikator I und Klassifikator II berechnen:
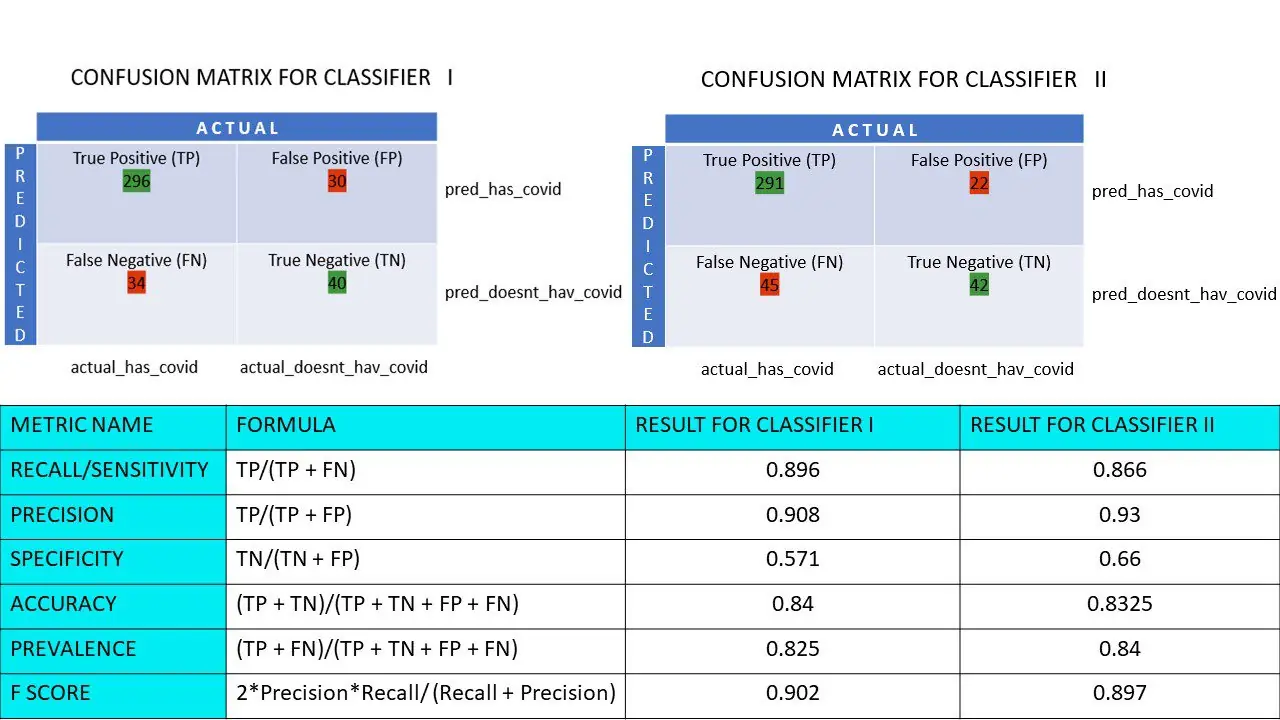
Wir sehen, dass die Genauigkeit bei Klassifikator II höher ist, während die Präzision bei Klassifikator I etwas höher ist. Abhängig vom jeweiligen Problem können Entscheidungsträger Klassifikator I oder II auswählen.
N x N Konfusionsmatrix
Bisher haben wir uns eine Konfusionsmatrix für binäre Klassifikatoren angesehen. Was ist aber, wenn es mehr Kategorien gibt als nur Ja/Nein oder Gefällt mir/Gefällt mir nicht? Wenn Ihr Algorithmus beispielsweise Bilder in den Farben Rot, Grün und Blau sortieren soll, spricht man von einer Mehrklassenklassifizierung. Die Anzahl der Ausgabevariablen bestimmt auch die Größe der Matrix. In diesem Fall ist die Konfusionsmatrix also 3 × 3.

Zusammenfassung
Eine Konfusionsmatrix ist ein hervorragendes Bewertungsinstrument, da sie detaillierte Informationen über die Leistung eines Klassifikationsalgorithmus liefert. Sie funktioniert sowohl für binäre als auch für Mehrklassenklassifikatoren, bei denen mehr als 2 Parameter zu berücksichtigen sind. Eine Konfusionsmatrix ist einfach zu visualisieren, und wir können alle anderen Leistungskennzahlen wie F-Score, Präzision, ROC und Genauigkeit mithilfe der Konfusionsmatrix generieren.
Sie können auch untersuchen, wie Sie ML-Algorithmen für Regressionsprobleme auswählen.
