Was du wissen musst
Ein physisches Datenmodell dient als Gerüst oder Blaupause, die detailliert beschreibt, wie Daten in einer Datenbank tatsächlich abgelegt werden.
Bevor wir uns dem physischen Datenmodell widmen, ist es wichtig zu verstehen, was Datenmodellierung im Kern bedeutet.
Welche Eigenschaften ermöglichen es Nutzern, Datenbanken optimal zu nutzen? Wie können wir gewährleisten, dass eine entwickelte Datenbank alle spezifischen Anforderungen erfüllt? Betrachten wir die Datenmodellierung als den Schlüssel, um Daten effizient abzurufen und in eine nutzbare Datenbank zu transformieren.
Was ist Datenmodellierung?
Datenmodellierung ist der Prozess, eine optimierte Darstellung einer Softwareanwendung und ihrer Datenkomponenten zu entwickeln. Dabei werden Text und Symbole eingesetzt, um Informationen und deren Übertragung abzubilden.
Es ist eine Methode, um die unterschiedlichen Speicherorte von Daten innerhalb einer Software oder Anwendung zu visualisieren und zu skizzieren. Darüber hinaus zeigt es, wie diese verschiedenen Informationsquellen integriert und miteinander verbunden werden.
Datenmodellierung ist ein grundlegender Aspekt des Datenmanagements. Sie unterstützt bei der Identifizierung von Informationsbedürfnissen für Arbeitsabläufe, indem sie eine visuelle Darstellung von Datenpunkten und deren Mustern bietet.
Es ermöglicht, zu definieren und zu verstehen, wie Daten innerhalb einer Organisation verwaltet, geändert, angezeigt und verteilt werden.
Bedeutung der Datenmodellierung
Moderne Unternehmen sammeln umfangreiche Datenmengen aus verschiedensten Quellen. Um effektive, strategische Entscheidungen treffen zu können, müssen diese Daten analysiert und in praktische Erkenntnisse umgewandelt werden.
Eine effiziente Datenerfassung, -speicherung und -verarbeitung sind für eine präzise Datenanalyse unerlässlich. Je nach Datenart – ob strukturiert, halbstrukturiert oder ordinal – werden unterschiedliche Analysewerkzeuge eingesetzt.

Die Datenmodellierung hilft dabei, die Daten besser zu verstehen und die optimale Lösung für deren Verwaltung und Steuerung auszuwählen. Unternehmen erstellen Datenmodelle, bevor sie Datenbanksysteme für ihren Betrieb entwickeln – ähnlich wie ein Architekt einen Bauplan erstellt, bevor er ein Haus errichtet.
Die Hauptvorteile der Datenmodellierung sind:
- Sie bietet schnelle und effiziente Lösungen für den Entwurf und die Bereitstellung von Datenbanken.
- Sie fördert die Einheitlichkeit der Datenpräsentation und der Entwicklungsarbeit innerhalb des gesamten Unternehmens.
Darüber hinaus erleichtert die Implementierung eines Datenmodellierungskonzepts die Kommunikation zwischen Analyseteams und Datenbankexperten.
Arten der Datenmodellierung
Datenmodellierer nutzen drei verschiedene Arten von Datenmodellen, um Marketingstrategien und -prozesse, relevante Datenelemente und deren Attribute, Beziehungen sowie praktische Rahmenbedingungen für das Datenmanagement zu beschreiben.
Da Unternehmen funktionale Programme und Datenbanken entwickeln, entstehen Datenmodelle oft schrittweise. Hier sind die verschiedenen Arten von Datenmodellen und ihre jeweiligen Inhalte:
#1. Konzeptionelle Datenmodellierung
Im Wesentlichen ist dies eine organisierte Sicht oder visuelle Darstellung von Datenbankkonzepten und ihren Beziehungen. Sie dient als grundlegender Ausgangspunkt für die Datenmodellierung und definiert die verschiedenen Datenquellen sowie den Datenfluss innerhalb einer Organisation.
Sie dient als allgemeine Richtlinie für die Erstellung logischer und physischer Modelle und ist ein wichtiger Bestandteil der Dokumentation für die Datenarchitektur.
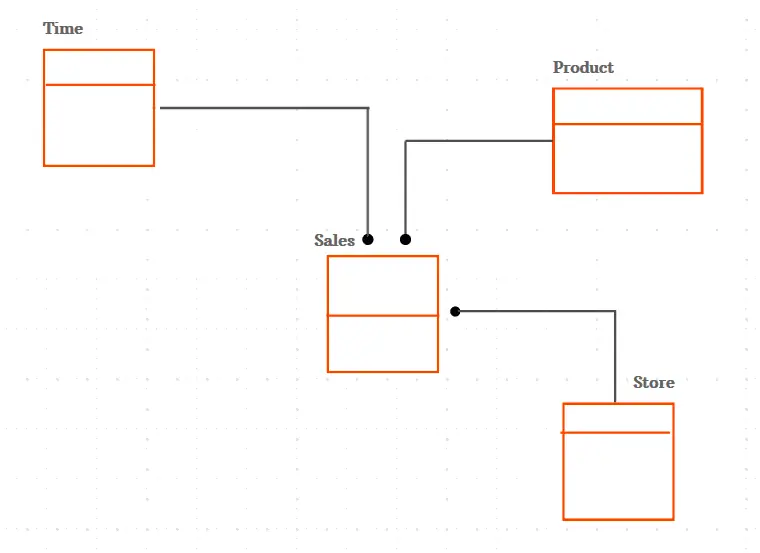
Das konzeptionelle Datenmodell zeigt nur das Gesamtlayout und den Inhalt, nicht die spezifischen Details der einzelnen Objekte. Es beschreibt die gesamte Organisationsstruktur und die Daten Ihres Unternehmens.
Es wird verwendet, um Geschäftskonzepte zu organisieren, die von Ihren Datenexperten definiert wurden. Der Fokus liegt auf dem Entwurf von Entitäten, der Definition von Attributen einer Entität sowie der Festlegung von Beziehungen zwischen Objekten und nicht nur auf den Details der Datenbankstruktur.
Nehmen wir beispielsweise Daten zu Filialen, Zeitpunkten und Produkten. Diese Datensätze oder Entitäten sind alle mit anderen Entitäten verbunden. In diesem konzeptionellen Datenmodell werden sowohl die Entitäten als auch die Beziehungen zwischen ihnen festgelegt.
#2. Logische Datenmodellierung
Ein logisches Datenmodell erweitert das konzeptionelle Modell um genaue Inhaltsmerkmale innerhalb jeder Entität sowie detaillierte Verbindungen zwischen diesen Attributen. Ein einfaches logisches Datenmodell kann unter Verwendung des konzeptionellen Datenmodells als Richtlinie erstellt werden.
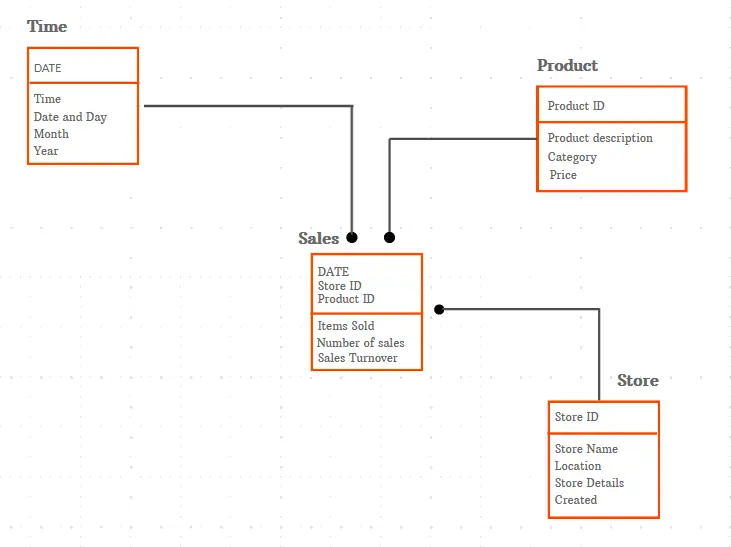
Logische Datenmodelle bilden die Beziehungen zwischen Datenelementen ab und liefern eine technische Beschreibung der Daten. Beispiel: Kunde A kauft Artikel B in Filiale C.
Dieses Modell definiert die Anordnung der Datenobjekte und die Beziehungen zwischen ihnen weiter. Da das Ziel darin besteht, ein detailliertes Diagramm von Standards und Datenstrukturen zu erstellen, werden logische Datenmodelle in der Regel für ein bestimmtes Projekt verwendet.
Das logische Datenmodell bietet mehr Informationen zum Gesamtdesign des konzeptionellen Modells, vernachlässigt jedoch Details zur Datenbank selbst, da das Modell zur Beschreibung verschiedener Datenbankprodukte und -dienste verwendet werden kann.
Es fungiert als technisches Modell der Prinzipien und Datenstrukturen, wie sie von Dateningenieuren festgelegt wurden, und unterstützt bei der Entscheidung über das physische Datenmodell, das zur Erfüllung Ihrer Betriebs- und Datenanforderungen erforderlich ist.
#3. Physische Datenmodellierung
Im Allgemeinen wird die Implementierung eines Datenmodells in einer Datenbank durch ein physisches Datenmodell beschrieben. Datenbankexperten nutzen physische Datenmodelle, um Layouts und Architekturen für Datenbanken zu entwickeln.
Durch die Simulation der Komponenten eines relationalen Datenbankmanagementsystems (RDBMS) – einschließlich Tabellen, Felder, Indizes, Spaltenschlüssel, Einschränkungen, Trigger usw. – leistet das physische Datenmodell einen großen Beitrag zur Visualisierung des Designs von Datenbanken.
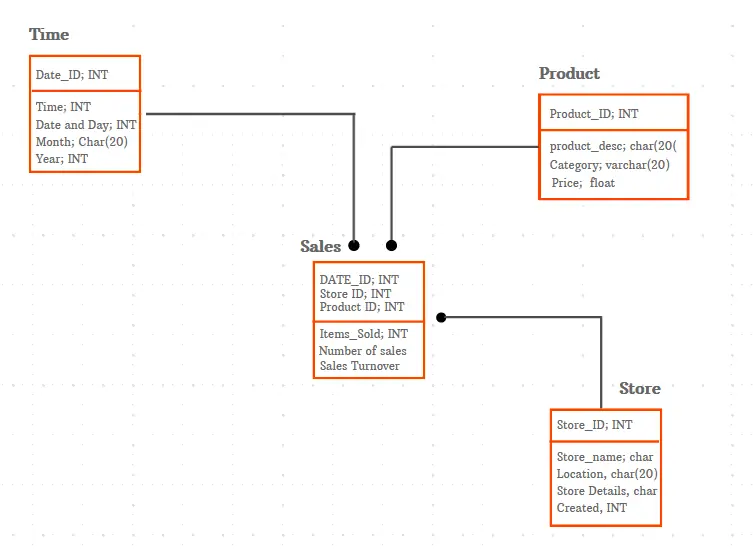
Es gibt die organisatorischen Prozesse an, die eine Datenbank oder ein Dateisystem verwendet, um die Daten zu erfassen und zu verarbeiten. Das physische Datenmodell erläutert die relevanten Details, wie das logische Modell implementiert wird.
Es bietet Datenbankabstraktion und hilft bei der Erstellung des Schemas oder Layouts. Dies ist auf die umfangreichen Metadaten zurückzuführen, die ein physisches Datenmodell bereitstellt.
In diesem Artikel wird hauptsächlich das Konzept der physischen Datenmodellierung behandelt.
Beginnen wir!
Was ist ein physisches Datenmodell?
Ein physisches Datenmodell ist ein Rahmenwerk oder eine Struktur, die beschreibt, wie Daten in einer Datenbank tatsächlich gespeichert werden. Das eigentliche Schema einer Datenbank wird anhand dieses physischen Datenmodells entwickelt. Dies umfasst sämtliche Tabellen, ihre Spalten sowie die Beziehungen zwischen ihnen.
Das interne Schema einer Datenbank wird mit Hilfe eines physischen Modells entworfen. Ziel ist es, die Datenbank in Betrieb zu nehmen. Dieses physische Modell kann direkt in ein tatsächliches Datenbankdesign umgesetzt werden und unterstützt somit die Weiterentwicklung des Informationsmanagements. Bei der Nutzung mehrerer Datenbanksysteme können aus demselben logischen Datenmodell unterschiedliche physische Modelle hervorgehen.
Eigenschaften eines physischen Datenmodells
- Es deckt die Datenanforderungen für ein bestimmtes Projekt oder Programm ab, kann aber je nach Projektzielen mit anderen physischen Modellen kombiniert werden.
- Die spezifischen Datentypen und zugewiesenen Größen sowie Standardwerte für Spalten sollten angegeben werden.
- Ansichten (virtuelle Tabellen basierend auf der Ergebnismenge), Indizes, Transaktionen und andere Konzepte werden definiert, einschließlich Primär- und Fremdschlüssel.
Datenbankingenieure erstellen das physische Datenmodell, bevor sie das endgültige Datenbankschema in Betrieb nehmen. Um sicherzustellen, dass alle Architekturkomponenten berücksichtigt werden, wenden sie zudem umfassende Datenmodellierungsansätze an.
Erforderliche Schritte zum Entwerfen eines physischen Datenmodells
Hier sind die Schritte, die beim Erstellen eines physischen Datenmodells zu beachten sind:
- Erstellen Sie ein physisches Datenmodell unter Verwendung des bereits vorhandenen logischen Datenmodells.
- Ergänzen Sie das physische Datenmodell um Datenbankattribute und -eigenschaften.
- Konvertieren Sie Entitäten in Tabellen und Entitätsbeziehungen in Fremdschlüssel.
- Konvertieren Sie Attribute in Spalten.
- Überprüfen Sie, ob alles korrekt ist, indem Sie die Datenbank und das Datenmodell vergleichen.
- Bei Änderungen zwischen der aktuellen und früheren Versionen des Datenmodells erstellen Sie ein Änderungsprotokoll.
Physisches vs. konzeptionelles vs. logisches Datenmodell
Hier vergleichen wir diese drei verschiedenen Kategorien von Datenmodellen. Die jeweiligen Merkmale sind in der folgenden Tabelle gegenübergestellt.
| Merkmal | Konzeptionell | Logisch | Physisch |
| Entitätsnamen | ✓ | ✓ | |
| Entitätsbeziehungen | ✓ | ✓ | |
| Attribute | ✓ | ||
| Primärschlüssel | ✓ | ✓ | |
| Fremdschlüssel | ✓ | ✓ | |
| Tabellennamen | ✓ | ||
| Spaltennamen | ✓ | ||
| Spaltendatentypen | ✓ |
Entitäten und Beziehungen werden in einem konzeptionellen Datenmodell dargestellt. Merkmale und Primärschlüssel werden nicht erwähnt. Es zeigt lediglich das Design auf einer hohen Ebene, einschließlich der Tabellen, die vorhanden sein sollten, und deren Verknüpfungen.
Nach dem konzeptionellen Modell wird das logische Modell erstellt. Logische Datenmodelle bilden die Beziehungen zwischen Datenelementen ab und liefern eine technische Beschreibung der Daten. Zusätzlich gibt es das physische Datenmodell, das das logische Datenmodell erweitert und jedem Feld seinen Datentyp, seine Größe usw. zuweist.
Lernressourcen zur Datenmodellierung

Es gibt viele Online-Ressourcen, die Ihnen helfen können, die Datenmodellierung zu verstehen, aber es kann schwierig sein, die geeigneten auszuwählen. Datenmodellierung ist eine wertvolle Fähigkeit, die auf die richtige Art und Weise erlernt werden muss.
Wenn Sie Ihre Datenverwaltungs- oder Analysefähigkeiten für private oder geschäftliche Zwecke verbessern möchten, sollten Sie sich diese Liste der besten Kurse und Bücher zur Datenmodellierung ansehen.
#1. Grundlagen der Datenmodellierung beherrschen
In diesem Udemy-Kurs lernen Sie die Methoden, die zum Erstellen von Datenmodellen für Ihre Organisation erforderlich sind. Dies umfasst semantisch korrekte Entitäten, Merkmale, Beziehungen, Strukturen und andere Modellierungselemente.

Die Teilnehmer benötigen lediglich ein grundlegendes Verständnis der Begriffe und Strukturen des Datenmanagements, wie z. B. RDBMS-Tabellen und wie verschiedene Datensätze konzeptionell miteinander in Beziehung stehen.
#2. Erweiterte Datenmodellierung

Dieser Coursera-Kurs ist ideal für Personen, die ihre Karriere vorantreiben möchten. Nach Abschluss dieses Kurses haben Sie ein fundiertes Verständnis der Anwendung grundlegender Datenmodellierungstechniken und der zeitgemäßen Speicherlösungen für ein Datenbanksystem. Vorkenntnisse in Datenbanktechnik sind für die Teilnehmer nicht erforderlich.
#3. OBIEE 12c Datenmodellierungskurs
Dieser Udemy-Kurs richtet sich an alle, die sich für eine Karriere in der OBIEE-Datenmodellierung interessieren, darunter Studenten, IT-Experten und Projektmanager.

Nach Abschluss dieses Kurses sind Sie in der Lage, mehrere Zeitreihenfunktionen und Datenmodellierungskonzepte zu implementieren, einschließlich Datendenormalisierung, Dimensionsdatenmodellierung und Sternschemamodellierung.
#4. Excel Business Intelligence: Datenmodellierung 101
In diesem LinkedIn-Kurs behandelt der Trainer die Grundlagen der Datenbankarchitektur und -normalisierung, die Datenmodellschnittstelle von Excel und stellt bewährte Techniken vor.

Sie können Ihr Wissen über Tabellenverknüpfungen, Topologien und andere Konzepte verbessern, indem Sie die in diesem Kurs behandelten Themen lernen. Es gibt keine Voraussetzungen für die Teilnahme an diesem Kurs.
#5. Das Data-Warehouse-Toolkit
In diesem Buch führen die Autoren Studenten in dimensionale Modellierungsansätze wie Rechnungsstellung, Kundeninteraktionen und grundlegende Datenbankerstellung ein. Es werden auch die neuen und verbesserten dimensionalen Modellierungsmuster des Sternschemas diskutiert.
Darüber hinaus enthält dieses Buch Richtlinien für fortgeschrittene Simulationssitzungen mit Stakeholdern des Unternehmens. Vorkenntnisse in Datenmodellierung sind nicht erforderlich. Selbst Anfänger werden sich beim Lesen dieses Buches beim Erlernen von Datenmodellierungskonzepten wohlfühlen.
#6. Datenmodellierung leicht gemacht, 2. Auflage
Dieses Buch ist in einem dialogorientierten Stil geschrieben, der die Leser dazu anregt, die wichtigsten Ziele zu lernen. Dazu gehören das Verständnis, wann ein Datenmodell erforderlich ist und welche Form am vorteilhaftesten ist, ein normalisiertes relationales Datenbanksystem zu erstellen, und Methoden zur Transformation eines Datenmodells in ein effektives physisches Datenbanklayout.
Dieses Buch bietet ein realistisches, praktisches Verständnis der Datenmodellierungsprinzipien und Best Practices für Geschäfts- oder IT-Zwecke.
#7. Grundlagen der Datenmodellierung, dritte Ausgabe
Dieses Buch vermittelt die Grundlagen der Datenmodellierung, wobei der Schwerpunkt auf der Technologieentwicklung liegt, anstatt sich nur mit „den Prinzipien“ vertraut zu machen.
Es untersucht die Komplexität der Erstellung von Systemen unter realen Bedingungen, indem es die Vor- und Nachteile verschiedener Alternativen abwägt und sprachliche sowie grafische Analysetechniken verwendet, die Industriestandards entsprechen. Dies ermutigt die Leser, die Grundlagen der Datenmodellierung auf reale Modelle anzuwenden.
Fazit
Organisationen und Unternehmen sind ständig bestrebt, Kunden zu gewinnen und müssen dafür Strategien entwickeln, die ihre Dienstleistungen vorantreiben. Diese Strategien beinhalten die Verwendung von Datenmodellen zur Verbesserung des Geschäftsbetriebs.
Ein gutes Datenmodell hilft Ihnen, Zeit und Geld zu sparen und die Produktivität zu steigern. Die Nutzung des Datenmodellierungskonzepts kann sicherstellen, dass ein Unternehmen durch Anpassungen auf der Grundlage der gesammelten Daten wettbewerbsfähig wird.
Heutzutage besteht eine hohe Nachfrage nach Fachleuten mit Datenmodellierungskenntnissen. Ein Job in dieser Branche kann zahlreiche Möglichkeiten bieten, da Daten immer zur Analyse und Speicherung zur Verfügung stehen. Ich hoffe, dieser Artikel hat Ihnen geholfen, die Konzepte der Datenmodellierung besser zu verstehen.
Vielleicht interessieren Sie sich auch dafür, mehr über SQL-Trigger zu erfahren.
