Verwenden Sie Chaos Engineering Tools, um die Produktionszuverlässigkeit zu überprüfen
Die Zuverlässigkeit Ihrer Produktion mit Chaos Engineering verbessern
Entdecken wir gemeinsam, wie Sie Ihre Produktionsumgebung durch den Einsatz von Chaos-Engineering-Tools stabil und zuverlässig gestalten können.
Chaos Engineering ist eine Methode, bei der Sie gezielt Experimente an Ihrem System oder Ihrer Anwendung durchführen. Ziel ist es, Schwachstellen und mögliche Kapazitätsengpässe aufzudecken, die während der Entwicklung möglicherweise übersehen wurden. Durch die bewusste Herbeiführung von Fehlern identifizieren Sie kritische Punkte, um Ihr System robuster und widerstandsfähiger zu machen.
Viele namhafte Unternehmen wie Netflix, LinkedIn und Facebook setzen Chaos Engineering ein, um ihre Microservice-Architekturen und verteilten Systeme besser zu verstehen. Dies ermöglicht es ihnen, potenzielle Probleme frühzeitig zu erkennen und zu beheben, bevor sie sich auf die Benutzererfahrung auswirken. Dadurch können diese Organisationen Millionen von Nutzern bedienen, ihre Produktivität steigern und erhebliche Kosten einsparen 🤑.
Vorteile von Chaos Engineering:
- Minimierung von Umsatzverlusten durch frühzeitige Erkennung kritischer Probleme
- Reduzierung von System- und Anwendungsfehlern
- Verbesserte Benutzererfahrung durch weniger Ausfälle und hohe Serviceverfügbarkeit
- Besseres Systemverständnis und gesteigertes Vertrauen in die eigene Infrastruktur
Wie sicher sind Sie sich der Zuverlässigkeit Ihrer Produktionsumgebung? Ist sie wirklich widerstandsfähig gegen unvorhergesehene Ereignisse?
Finden wir es heraus, indem wir uns einige beliebte Chaos-Testing-Tools genauer ansehen.
Chaos Mesh
Chaos Mesh ist eine umfassende Lösung für Chaos Engineering, die Fehler in verschiedenen Schichten eines Kubernetes-Systems injiziert. Dies umfasst Pods, das Netzwerk, System-I/O und den Kernel. Chaos Mesh ist in der Lage, Kubernetes-Pods automatisch zu terminieren und Latenzen zu simulieren. Es kann die Kommunikation zwischen Pods stören und Lese-/Schreibfehler provozieren. Die Experimente lassen sich durch YAML-Dateien definieren und planen, wobei der Umfang des Experiments festgelegt werden kann.
Chaos Mesh bietet ein Dashboard zur Analyse der Experimente. Es basiert auf Kubernetes und unterstützt die meisten Cloud-Plattformen. Als Open-Source-Projekt wurde es kürzlich als CNCF-Sandbox-Projekt akzeptiert. Durch die Integration von Chaos Mesh in Ihren DevOps-Workflow können Sie widerstandsfähigere Anwendungen entwickeln.
Chaos-Engineering-Funktionen:
- Einfache Bereitstellung auf Kubernetes-Clustern ohne Anpassung der Deployment-Logik
- Keine speziellen Abhängigkeiten für die Bereitstellung erforderlich
- Definition von Chaos-Objekten mithilfe von CustomResourceDefinitions (CRD)
- Dashboard zur Überwachung aller Experimente
Chaos Toolkit ist ein weiteres Open-Source-Tool zur Automatisierung von Chaos-Engineering-Experimenten, das sich durch seine Einfachheit auszeichnet.
Chaos Toolkit integriert sich nahtlos in Ihr System durch den Einsatz von Treibern oder Plugins, die unter anderem AWS, Google Cloud, Slack und Prometheus unterstützen.
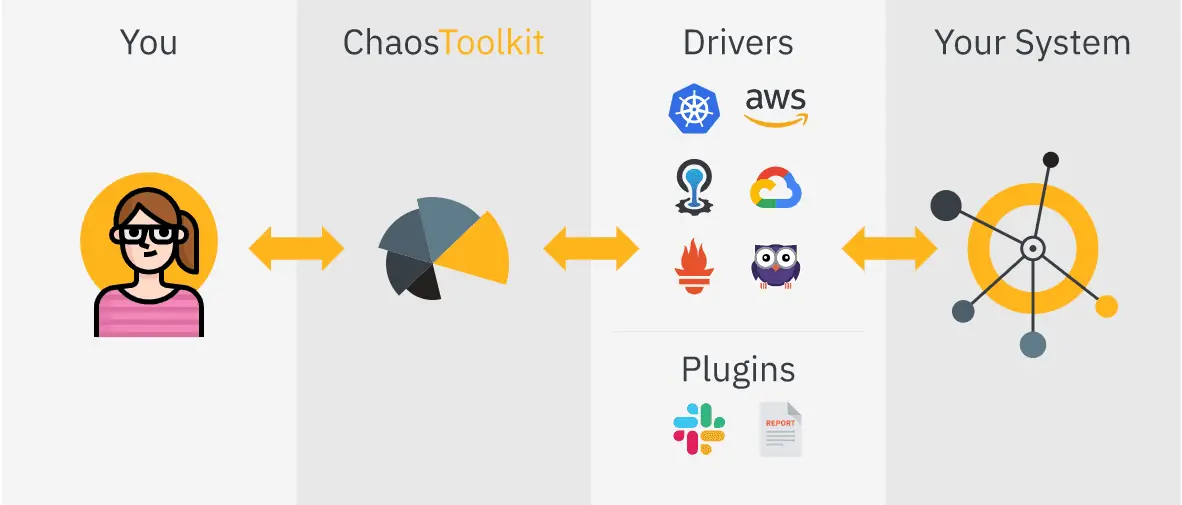
Funktionen des Chaos Toolkits:
- Bietet eine deklarative, offene API zur Erstellung von Chaos-Experimenten unabhängig von Anbieter oder Technologie.
- Kann problemlos in CI/CD-Pipelines zur Automatisierung eingebunden werden.
- Kommerzielle und Enterprise-Unterstützung durch ChaosIQ.
ChaosKube
Wie der Name schon sagt, bezieht sich dieses Tool direkt auf Kubernetes.
Chaoskube ist ein Open-Source-Chaos-Tool, das in regelmäßigen Abständen zufällig Pods in einem Kubernetes-Cluster terminiert. Dies hilft Ihnen zu verstehen, wie Ihr System auf den Ausfall eines Pods reagiert. Standardmäßig beendet Chaoskube alle 10 Minuten einen Pod in einem beliebigen Namespace. Die zu beendenden Pods können über Namespaces, Labels, Anmerkungen usw. gefiltert werden. Die Installation von Chaoskube ist unkompliziert.

Chaos-Affe
Chaos-Affe ist ein Werkzeug zur Überprüfung der Widerstandsfähigkeit von Cloud-Systemen. Es simuliert absichtlich Fehler, damit diese Systeme ihre Reaktionen zeigen können. Entwickelt von Netflix, diente es dazu, die Belastbarkeit und Wiederherstellbarkeit ihrer AWS-Infrastruktur zu testen. Der Name "Chaos-Affe" spiegelt die Zerstörung wider, die er anrichtet, um Fehler zu testen, wie ein wilder und bewaffneter Affe.
Chaos-Affe war auch der Auslöser für die Entstehung des modernen Chaos Engineerings. Es basiert auf der Idee, dass es besser ist, wiederholt zu scheitern, als von plötzlichen und schweren Fehlern überrascht zu werden.
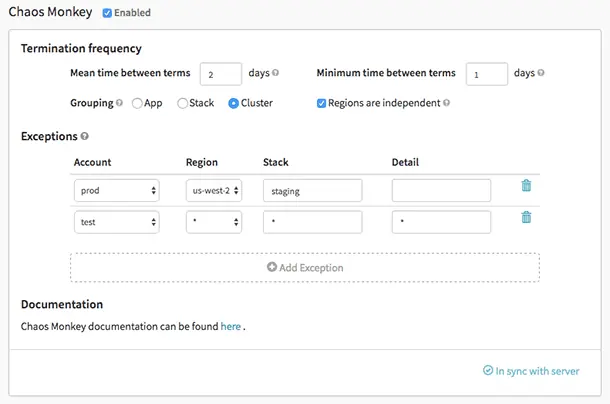
Eigenschaften von Chaos-Affe:
- Hilft bei der Vorbereitung auf zufällige Instanzausfälle.
- Fördert Redundanz für unerwartete Ausfälle.
- Nutzt Spinnaker für Cloud-übergreifende Kompatibilität.
- Bietet einen konfigurierbaren Zeitplan zur Simulation von Ausfällen.
- Integriert sich mit Govendor zur Integration neuer Abhängigkeiten.
Simmy
Simmy ist ein Fault-Injection-Chaos-Tool, das in das Polly-Resilience-Projekt für .NET integriert ist. Es ermöglicht die Erstellung von Chaos-Injection-Richtlinien mit Polly, an dem Ort, an dem Ihr Code ausgeführt wird. Es bietet verschiedene Richtlinien, wie Ausnahmerichtlinien zur Injektion von Ausnahmen und Verhaltensrichtlinien zur Injektion von neuem Verhalten. Diese Richtlinien sind so konzipiert, dass sie das Verhalten nach dem Zufallsprinzip einfügen.
Simmy-Funktionen:
- Bietet Monkey- oder Chaos-Richtlinien zur Chaos-Injektion.
- Ermöglicht einfaches Testen von Abhängigkeitsfehlern.
- Hilft, schnell zum funktionierenden Modell zurückzukehren und kontrolliert den "Explosionsradius".
- Ist produktionsreif.
- Ermöglicht die Fehlerdefinition basierend auf externen Faktoren (z.B. Fehler aufgrund globaler Konfigurationen).
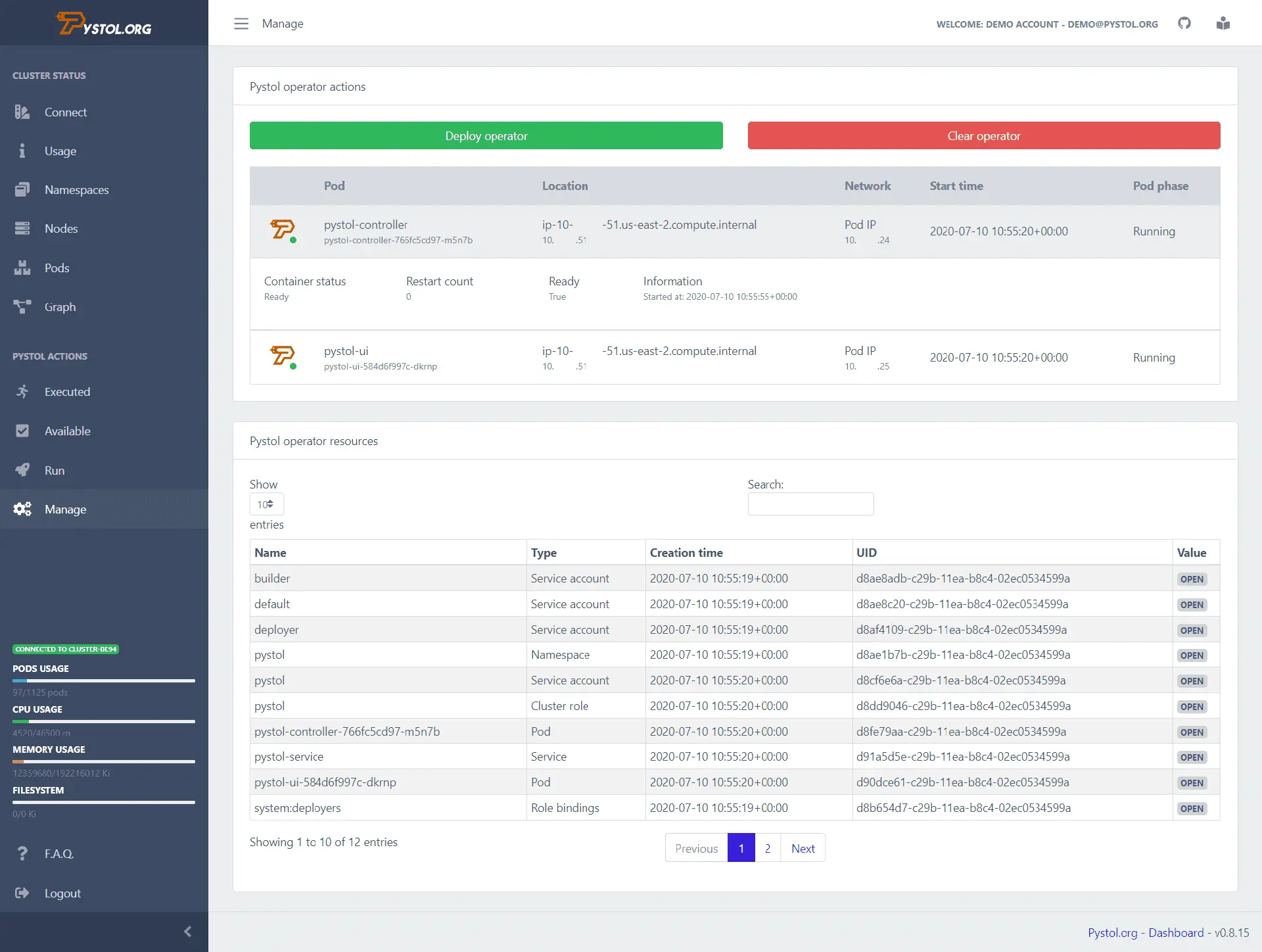
Pystol
Pystol ist ein Werkzeug, das zur Injektion von Fehlern in Cloud-nativen Umgebungen dient. Es überwacht Ereignisse in ETCD über Kubernetes-Operatoren. Bei einer Fehlereinspritzungsaktion erstellen die Operatoren Pods und führen einige Ansible-Sammlungen aus. Entwickler müssen also keine eigenen Aktionsroutinen schreiben.
Pystol bietet vordefinierte Aktionen zum Testen von Systemen. Entwickler können jedoch neue Aktionen in GoLang oder Python schreiben.
Es stellt ein Continuous-Integration-Dashboard zur Übersicht der Jobabläufe zur Verfügung. Pystol kann lokal ausgeführt oder als Docker-Image in einem Container bereitgestellt werden. Die Benutzeroberfläche ist entweder über eine Web-GUI oder die CLI erreichbar, wobei die Web-GUI die intuitivere Wahl darstellt.
Muxy
Muxy ist ein Proxy, der die Resilienz und Fehlertoleranz von verteilten Systemen unter realen Bedingungen testet. Es ist in der Lage, die Transportschicht (Schicht 4), die TCP-Sitzungsschicht (Schicht 5) und die HTTP-Protokollschicht (Schicht 7) zu manipulieren.
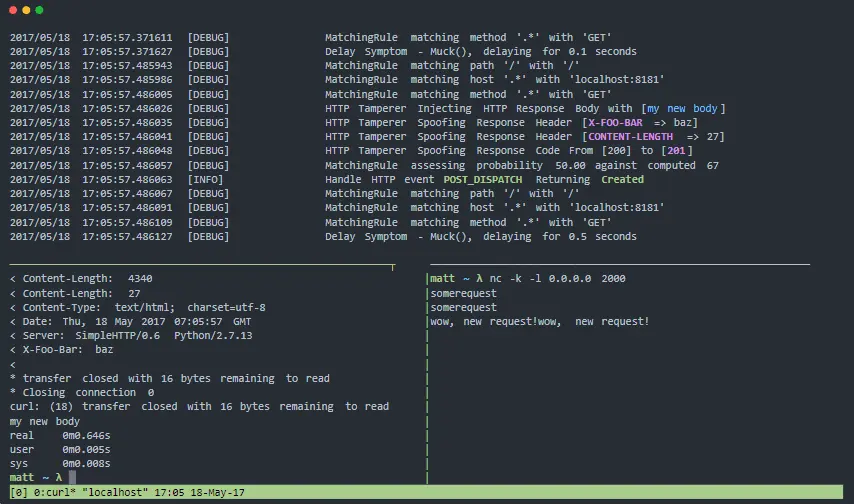
Muxy-Funktionen:
- Modulare Architektur und einfache Erweiterbarkeit.
- Verfügt über einen offiziellen Docker-Container.
- Einfache Installation, keine Abhängigkeiten erforderlich.
- Ideal für kontinuierliche Belastbarkeitstests.
- Simuliert Probleme mit der Netzwerkkonnektivität für verteilte Systeme und mobile Geräte.
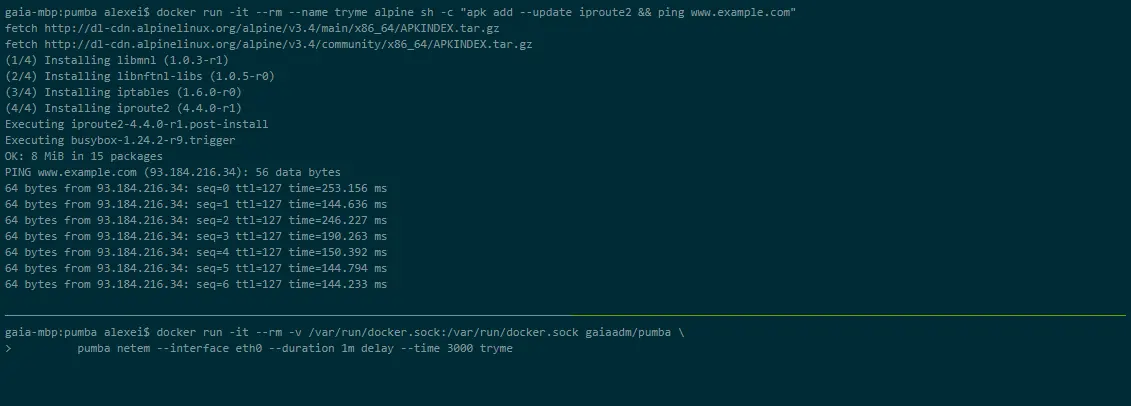
Pumba
Pumba ist ein Befehlszeilentool für Chaostests in Docker-Containern. Mit Pumba können Sie Docker-Container Ihrer Anwendung absichtlich abstürzen lassen, um zu beobachten, wie das System reagiert. Zudem lassen sich Stresstests für Containerressourcen wie CPU, Speicher, Dateisystem und I/O durchführen.
Pumba kann auch in einem Kubernetes-Cluster ausgeführt werden. Dazu werden DaemonSets verwendet, um Pumba auf Kubernetes-Knoten bereitzustellen. Es können mehrere Pumba-Container verwendet werden, um mehrere Pumba-Befehle im selben DaemonSet auszuführen.
ChaosBlade
ChaosBlade ist ein Open-Source-Tool zur Durchführung von Experimenten in den Systemen von Alibaba. Es testet Fehler, mit denen Alibaba in den letzten zehn Jahren konfrontiert war und setzt Best Practices zur Vermeidung um. Dabei werden die Prinzipien von Chaos Engineering befolgt, um die Fehlertoleranz von verteilten Systemen zu überprüfen.
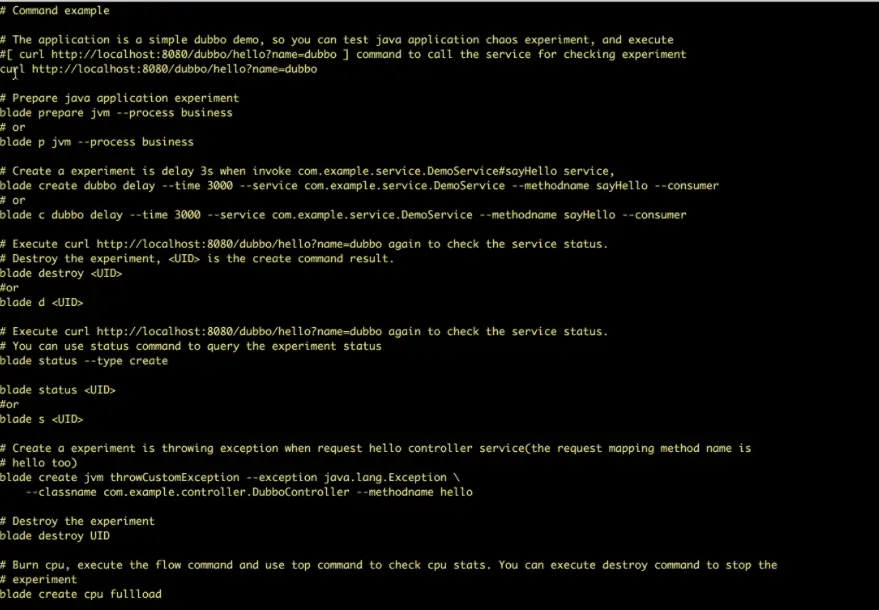
ChaosBlade-Funktionen:
- Bietet experimentelle Szenarien für verschiedene Ressourcen wie CPU, Netzwerk, Speicher, Festplatte usw.
- Stellt experimentelle Szenarien für Knoten, Netzwerke und Pods auf der Kubernetes-Plattform zur Verfügung.
- Bietet benutzerfreundliche CLI-Befehle zur Ausführung von Experimenten.
Litmus
Litmus basiert auf Cloud-nativen Chaos-Engineering-Prinzipien. Das Ziel von Litmus ist es, ein umfassendes Framework zur Identifizierung von Schwachstellen in Ihren Kubernetes-Systemen und den darauf laufenden Anwendungen bereitzustellen.
Es beinhaltet einen Chaos-Operator und die entsprechenden CRDs (CustomResourceDefinitions), die eine Plug-and-Play-Funktionalität ermöglichen. Die Chaoslogik wird in ein Docker-Image verpackt und dann mit Hilfe der CRDs orchestriert.
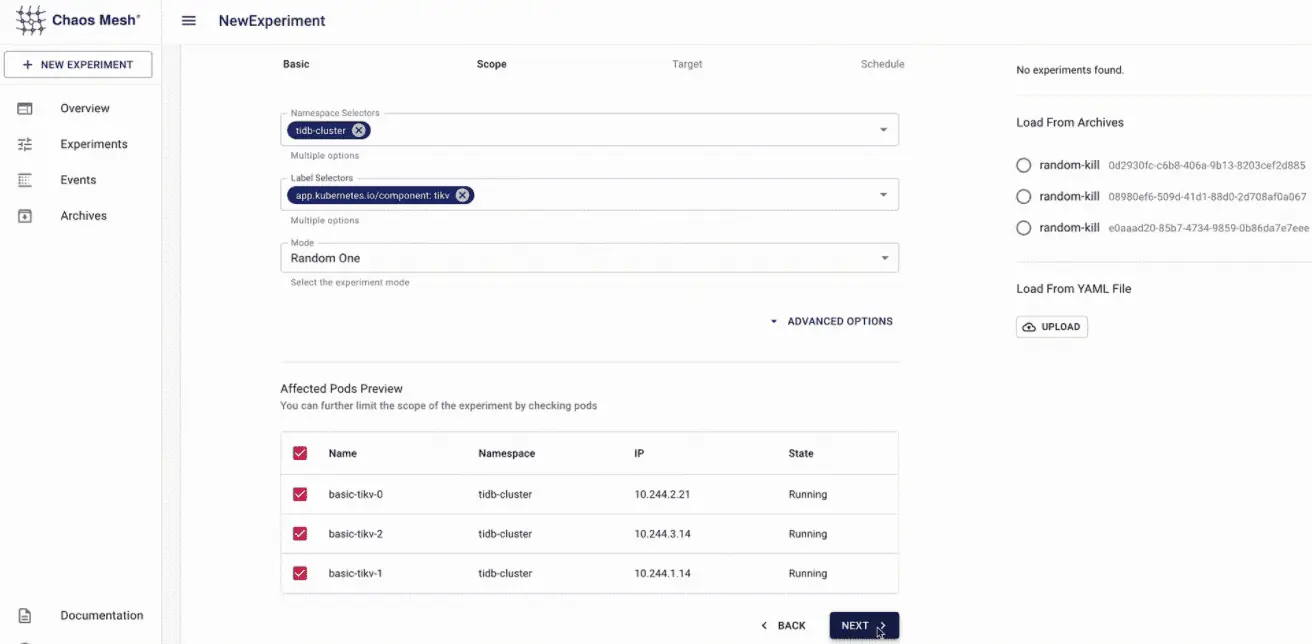
Litmus-Funktionen:
- Hilft Site Reliability Engineers und Entwicklern, Schwachstellen im Kubernetes-System zu finden.
- Stellt vorgefertigte, generische Experimente zur Verfügung.
- Bietet Chaos-API für das Chaos-Workflow-Management.
- Litmus SDK unterstützt Go, Python und Ansible zur Entwicklung eigener Experimente.
Gremlin
Gremlin unterstützt Ingenieure bei der Entwicklung widerstandsfähigerer Software. Es bietet eine Plattform zur Durchführung von Chaos-Engineering-Experimenten auf sichere und unkomplizierte Weise.

Mit Gremlin lassen sich gezielt Fehler in Hosts oder Containern injizieren, unabhängig davon, ob sie sich in der Public Cloud oder in Ihrem eigenen Rechenzentrum befinden.
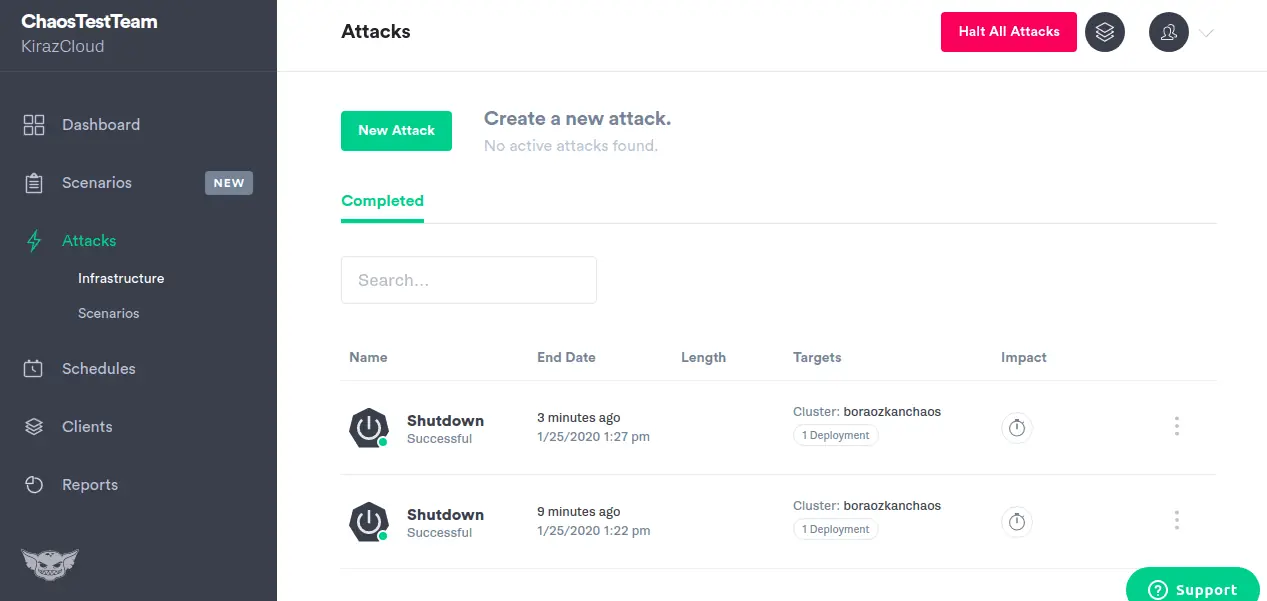
Gremlin-Funktionen:
- Installiert einen einfachen Agenten auf Ihren Hosts oder Containern, um Fehler zu injizieren.
- Bietet mehr als 10 verschiedene Angriffsmodi auf die Infrastruktur.
- Mit Zustands-Gremlins können Systemzeit manipuliert, Hosts heruntergefahren oder neu gestartet und Prozesse beendet werden.
- Netzwerk-Gremlins können Latenz injizieren, Paketverluste verursachen oder den Datenverkehr stören.
- Die Alfi-Bibliotheksangriffe von Gremlin lassen sich über die Web-App, API oder CLI konfigurieren, starten und stoppen.
- Ermöglicht die präzise Bestimmung des "Explosionsradius" für Angriffe.
- Ermöglicht die Beendigung aller Angriffe und die Wiederherstellung eines stabilen Systemzustands.
Steadybit
Steadybit hat das Ziel, Ausfallzeiten proaktiv zu reduzieren und bietet einen umfassenden Einblick in Systemprobleme. Es kann lokal in Ihrer Infrastruktur oder als Cloud-Service (SaaS) verwendet werden.
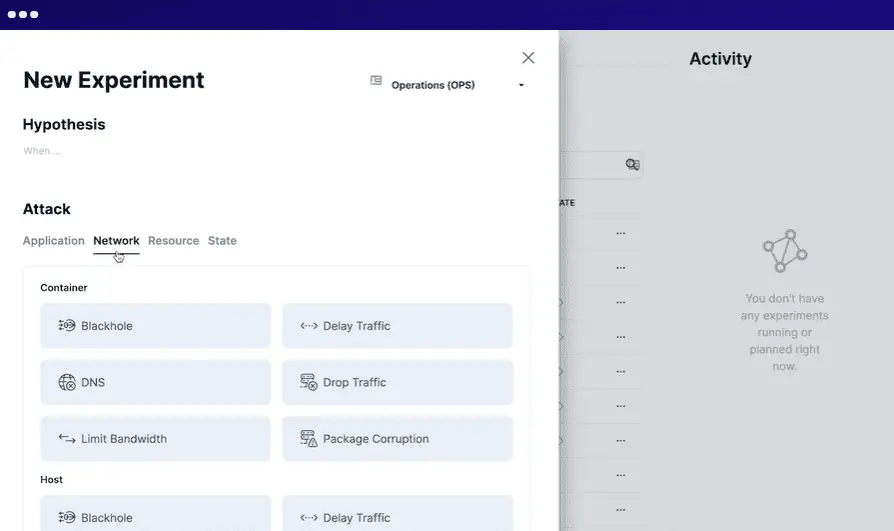
Der Einsatz von Steadybit umfasst die Definition der Situation, die Simulation von Experimenten, die Durchführung in der Produktion und die Automatisierung aller Experimente. Das Tool verwendet intelligente Agenten, um potenzielle Probleme und Schwachstellen zu erkennen und lässt sich nahtlos in verschiedene Systeme integrieren.
Fazit
Seien Sie mutig und setzen Sie die Prinzipien von Chaos Engineering in die Praxis um. Testen Sie Ihre Produktionsumgebung mit den vorgestellten Tools. Diese helfen Ihnen, eine Vielzahl von Schwachstellen in Ihrem System aufzudecken und Ihre Systeme widerstandsfähiger zu machen.
