So verwenden Sie den uniq-Befehl unter Linux
Der Befehl `uniq` in Linux analysiert Textdateien, um identische oder einzigartige Zeilen zu identifizieren. Dieser Artikel beleuchtet die Vielseitigkeit und Funktionalitäten dieses nützlichen Werkzeugs und zeigt, wie Sie es optimal einsetzen.
Identifizierung übereinstimmender Textzeilen unter Linux
Der Befehl `uniq` ist effizient, anpassungsfähig und meisterhaft in seinem Aufgabenbereich. Wie viele Linux-Befehle hat auch er seine Eigenheiten, die man kennen sollte, um unerwartete Ergebnisse zu vermeiden. Wir werden diese Besonderheiten im Laufe des Artikels ansprechen.
Der Befehl `uniq` eignet sich ideal für Benutzer, die einen Befehl suchen, der eine spezifische Aufgabe präzise erfüllt. Er ist besonders nützlich in Kombination mit Pipes, um Aufgaben in Befehlsketten zu erledigen. Ein häufiger Partner ist der Befehl `sort`, da `uniq` eine sortierte Eingabe benötigt, um korrekt zu funktionieren.
Legen wir los!
Ausführung von `uniq` ohne Optionen
Wir haben eine Textdatei, die den Text des Liedes Robert Johnsons, "Ich glaube, ich werde meinen Besen abstauben" enthält. Wir untersuchen, wie `uniq` mit dieser Datei umgeht.
Um die Ausgabe mit `less` zu betrachten, geben wir Folgendes ein:
uniq dust-my-broom.txt | lessDer gesamte Liedtext, einschließlich der doppelten Zeilen, wird in `less` angezeigt:
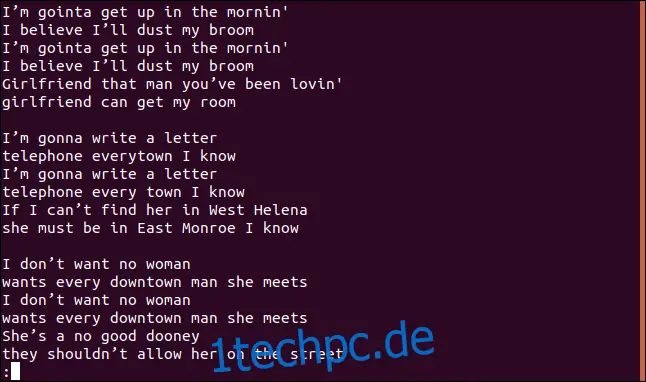
Das ist überraschend, da wir weder die einzigartigen noch die doppelten Zeilen sehen.
Das liegt daran, dass `uniq` ohne zusätzliche Optionen standardmäßig die Option `-u` (einzigartige Zeilen) verwendet. Diese Option weist `uniq` an, nur die eindeutigen Zeilen auszugeben. Die doppelten Zeilen werden angezeigt, weil `uniq` nur aufeinanderfolgende Zeilen als Duplikate betrachtet. Daher müssen die Zeilen sortiert werden, damit `uniq` sie als Duplikate erkennt.
Durch das Sortieren der Datei gruppieren wir die identischen Zeilen, und `uniq` kann sie als Duplikate behandeln. Wir sortieren die Datei, leiten die sortierte Ausgabe an `uniq` und dann die finale Ausgabe an `less` weiter.
Dazu geben wir Folgendes ein:
sort dust-my-broom.txt | uniq | less
Eine sortierte Liste von Zeilen wird in `less` angezeigt.
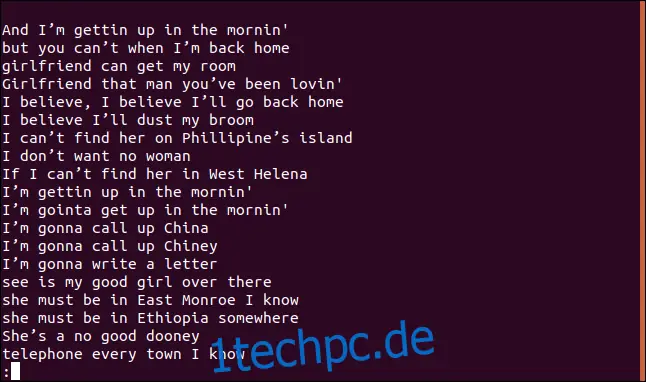
Die Zeile "Ich glaube, ich werde meinen Besen abstauben" kommt im Song mehrmals vor. In den ersten vier Zeilen des Liedes wird sie sogar zweimal wiederholt.
Warum wird sie dann in einer Liste mit einzigartigen Zeilen angezeigt? Weil diese Zeile zum ersten Mal in der Datei erscheint, ist sie einzigartig; erst die nachfolgenden Zeilen sind Duplikate. Sie können sich das so vorstellen, als würden Sie das erste Vorkommen jeder eindeutigen Zeile auflisten.
Lassen Sie uns die Datei erneut sortieren und die Ausgabe in eine neue Datei umleiten. Dadurch vermeiden wir, bei jedem Befehl sort verwenden zu müssen.
Wir verwenden folgenden Befehl:
sort dust-my-broom.txt > sorted.txt
Nun haben wir eine vorsortierte Datei, mit der wir arbeiten können.
Duplikate zählen
Mit der Option `-c` (Anzahl) können wir ermitteln, wie oft jede Zeile in einer Datei vorkommt.
Geben Sie folgenden Befehl ein:
uniq -c sorted.txt | less
Jede Zeile wird mit der Anzahl ihres Vorkommens in der Datei vorangestellt. Die erste Zeile ist jedoch leer. Dies bedeutet, dass die Datei fünf leere Zeilen enthält.
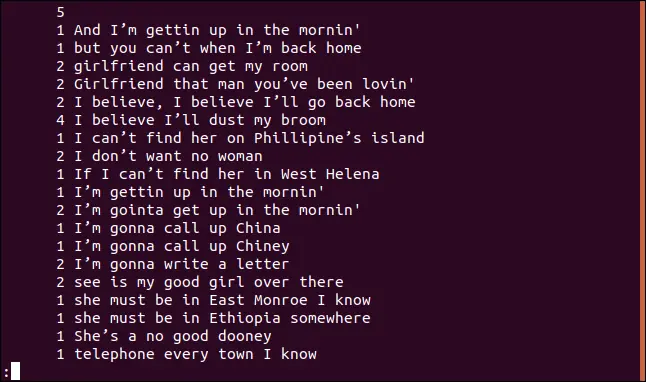
Um die Ausgabe in numerischer Reihenfolge zu sortieren, können wir die Ausgabe von `uniq` an `sort` weiterleiten. In unserem Fall verwenden wir die Optionen `-r` (umgekehrt) und `-n` (numerische Sortierung) und leiten die Ergebnisse an `less` weiter.
Wir geben Folgendes ein:
uniq -c sorted.txt | sort -rn | less
Die Liste wird nun in absteigender Reihenfolge sortiert, basierend auf der Häufigkeit des Vorkommens jeder Zeile.
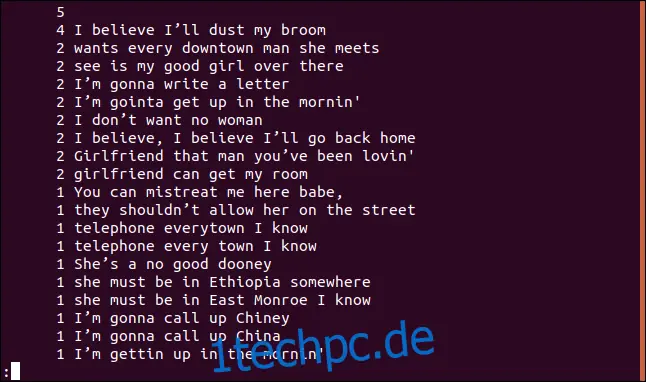
Nur doppelte Zeilen auflisten
Wenn Sie nur die Zeilen anzeigen möchten, die in einer Datei wiederholt vorkommen, können Sie die Option `-d` (wiederholt) verwenden. Unabhängig davon, wie oft eine Zeile dupliziert ist, wird sie nur einmal aufgelistet.
Um diese Option zu nutzen, geben wir Folgendes ein:
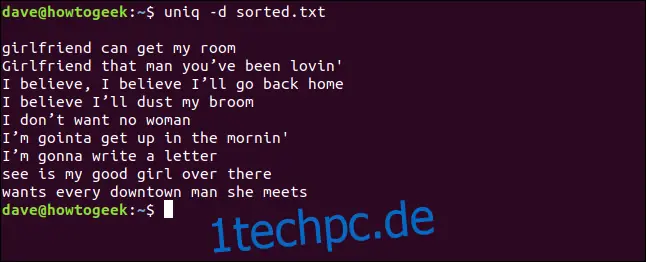
uniq -d sorted.txt
Die doppelten Zeilen werden aufgelistet. Die leere Zeile am Anfang zeigt, dass die Datei doppelte Leerzeilen enthält - es ist kein Platz, der von `uniq` gelassen wird, um die Auflistung visuell zu verschieben.
Wir können die Optionen `-d` (wiederholt) und `-c` (Anzahl) auch kombinieren und die Ausgabe durch Sortieren leiten. Dies ergibt eine sortierte Liste von Zeilen, die mindestens zweimal vorkommen.
Geben Sie Folgendes ein, um diese Option zu nutzen:
uniq -d -c sorted.txt | sort -rn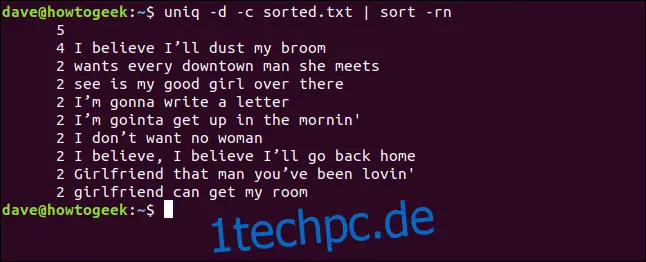
Alle doppelten Zeilen auflisten
Wenn Sie eine Liste aller doppelten Zeilen und für jedes Auftreten einer Zeile in der Datei sehen möchten, können Sie die Option `-D` (alle doppelten Zeilen) verwenden.
Um diese Option zu nutzen, geben Sie Folgendes ein:
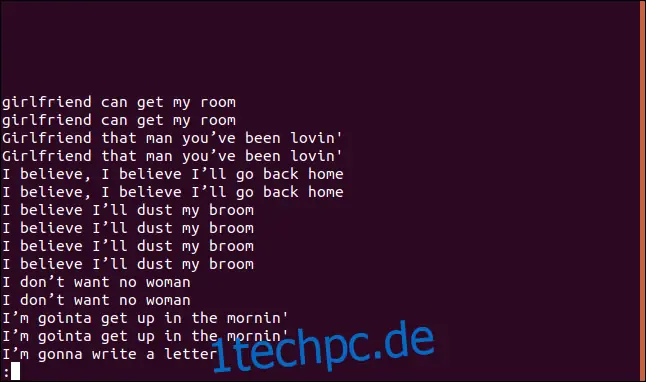
uniq -D sorted.txt | less
Die Liste zeigt jede doppelte Zeile an.
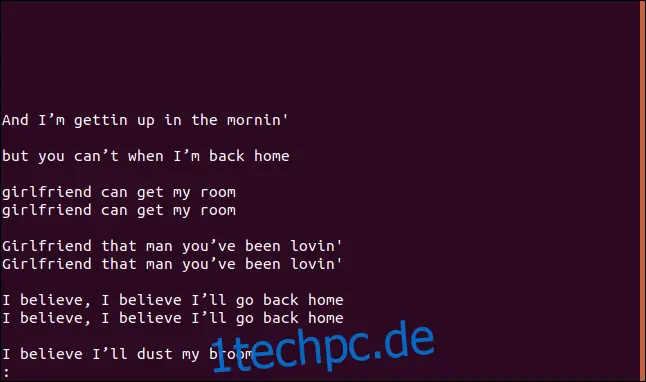
Wenn Sie die Option `--group` verwenden, wird jede Gruppe doppelter Zeilen mit einer Leerzeile entweder vor (`prepend`), nach (`append`) oder sowohl vor als auch nach (`both`) der jeweiligen Gruppe ausgeben.
Wir verwenden `append` als unseren Modifikator, also geben wir Folgendes ein:
uniq --group=append sorted.txt | less
Die Gruppen sind nun durch Leerzeilen voneinander getrennt, was die Lesbarkeit verbessert.
Prüfung auf eine bestimmte Anzahl von Zeichen beschränken
Standardmäßig prüft `uniq` die gesamte Länge jeder Zeile. Wenn Sie die Prüfung auf eine bestimmte Anzahl von Zeichen beschränken möchten, können Sie die Option `-w` (Prüfzeichen) verwenden.
In diesem Beispiel wiederholen wir den letzten Befehl, beschränken die Vergleiche aber auf die ersten drei Zeichen. Dazu geben wir folgenden Befehl ein:
uniq -w 3 --group=append sorted.txt | less
Die Ergebnisse und Gruppierungen, die wir erhalten, unterscheiden sich deutlich von den vorherigen.
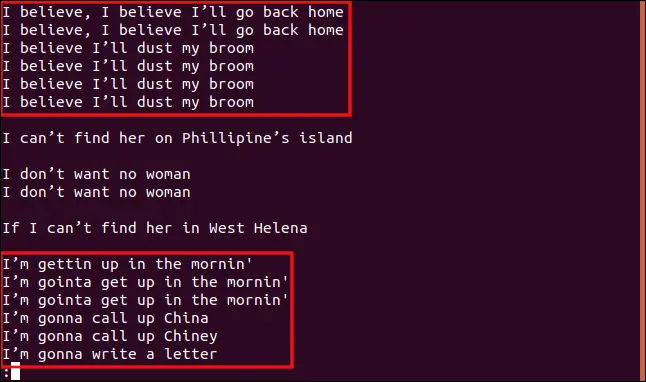
Alle Zeilen, die mit "I b" beginnen, werden gruppiert, da diese Teile der Zeilen identisch sind und daher als Duplikate betrachtet werden.
Ebenso werden alle Zeilen, die mit "I'm" beginnen, als Duplikate behandelt, auch wenn der restliche Text unterschiedlich ist.
Eine bestimmte Anzahl von Zeichen ignorieren
Es gibt Situationen, in denen es nützlich sein kann, eine bestimmte Anzahl von Zeichen am Anfang jeder Zeile zu überspringen, z.B. wenn Zeilen in einer Datei nummeriert sind. Oder Sie benötigen `uniq`, um einen Zeitstempel zu ignorieren und die Zeilen ab dem sechsten Zeichen statt vom ersten Zeichen an zu prüfen.
Unten ist eine Version unserer sortierten Datei mit nummerierten Zeilen.
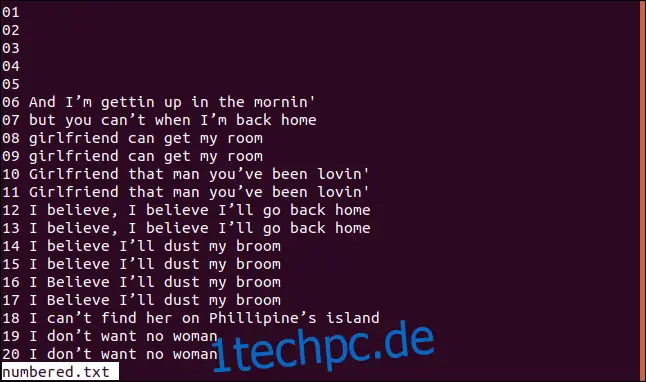
Wenn `uniq` seine Vergleichsprüfungen bei Zeichen 3 starten soll, können wir die Option `-s` (Zeichen überspringen) verwenden, indem Sie Folgendes eingeben:
uniq -s 3 -d -c numbered.txt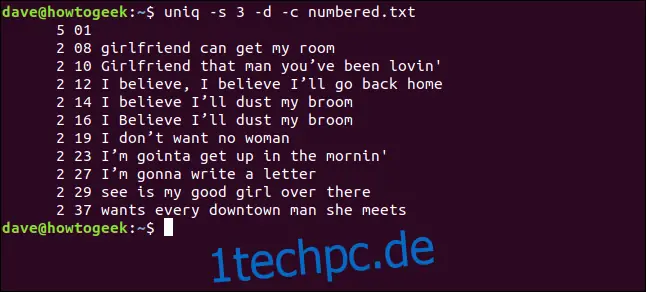
Die Zeilen werden als Duplikate erkannt und korrekt gezählt. Beachten Sie, dass die angezeigten Zeilennummern die des ersten Vorkommens jedes Duplikats sind.
Sie können auch Felder (eine Reihe von Zeichen und Leerzeichen) anstelle von Zeichen überspringen. Wir verwenden die Option `-f` (Felder), um `uniq` mitzuteilen, welche Felder ignoriert werden sollen.
Wir geben Folgendes ein, um `uniq` anzuweisen, das erste Feld zu ignorieren:
uniq -f 1 -d -c numbered.txt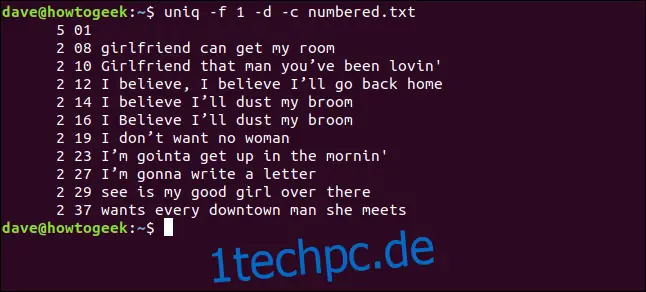
Wir erhalten die gleichen Ergebnisse, als würden wir mit `uniq` drei Zeichen am Anfang jeder Zeile überspringen.
Groß- und Kleinschreibung ignorieren
Standardmäßig beachtet `uniq` die Groß- und Kleinschreibung. Wenn der gleiche Buchstabe in Groß- und Kleinbuchstaben auftritt, betrachtet `uniq` die Zeilen als unterschiedlich.
Betrachten wir beispielsweise die Ausgabe des folgenden Befehls:
uniq -d -c sorted.txt | sort -rn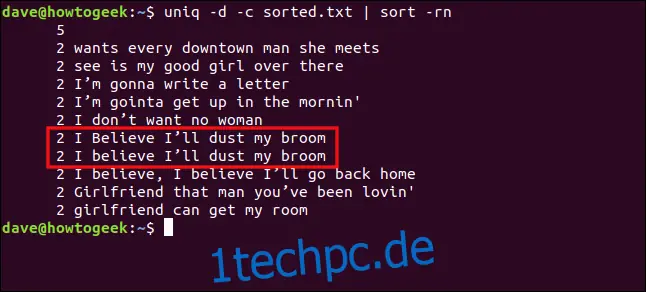
Die Zeilen "Ich glaube, ich werde meinen Besen abstauben" und "ich glaube, ich werde meinen Besen abstauben" werden aufgrund des Unterschieds in der Groß- und Kleinschreibung des "I" in "ich" nicht als Duplikate behandelt.
Wenn wir jedoch die Option `-i` (Groß- und Kleinschreibung ignorieren) verwenden, werden diese Zeilen als Duplikate behandelt. Wir geben Folgendes ein:
uniq -d -c -i sorted.txt | sort -rn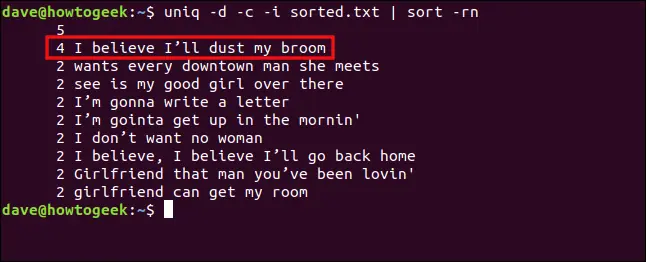
Die Zeilen werden nun als Duplikate behandelt und gruppiert.
Linux stellt eine Vielzahl von spezialisierten Werkzeugen bereit. Wie viele von ihnen ist `uniq` kein Werkzeug, das man jeden Tag benötigt.
Ein großer Teil des Wissens über Linux besteht darin, sich daran zu erinnern, welches Tool das aktuelle Problem löst und wo man es finden kann. Mit Übung sind Sie jedoch auf dem besten Weg.
Oder Sie können jederzeit auf etoppc.com suchen – wir haben wahrscheinlich einen Artikel dazu.