So verwenden Sie den stat-Befehl unter Linux
Der Befehl stat in Linux bietet deutlich mehr Details als der Befehl ls. Mit diesem informationsreichen und konfigurierbaren Werkzeug können Sie einen tiefen Einblick in Ihr System gewinnen. Wir zeigen Ihnen, wie Sie es nutzen können.
Ein Blick hinter die Kulissen mit `stat`
Der Befehl ls ist zwar sehr nützlich und vielseitig, aber unter Linux gibt es oft Möglichkeiten, noch tiefer zu gehen und zu erkunden, was sich unter der Oberfläche verbirgt. Manchmal genügt es nicht, nur den Teppich anzuheben; Sie können die Dielen aufbrechen und dann ein Loch graben. Linux kann wie eine Zwiebel Schicht für Schicht analysiert werden.
ls liefert eine Vielzahl von Informationen über eine Datei, wie zum Beispiel ihre Zugriffsrechte, Größe und ob es sich um eine Datei oder einen symbolischen Link handelt. Diese Informationen werden aus einer Dateisystemstruktur namens Inode entnommen.
Jede Datei und jedes Verzeichnis hat einen Inode, der Metadaten über die Datei speichert, wie z. B. die belegten Dateisystemblöcke und die zugehörigen Zeitstempel. Der Inode ist wie ein Bibliotheksausweis für die Datei, aber ls zeigt nur einen Teil dieser Informationen an. Um alle Details zu sehen, müssen wir den Befehl stat verwenden.
Ähnlich wie ls verfügt auch stat über viele Optionen, was es zu einem idealen Kandidaten für die Verwendung von Aliasen macht. Sobald Sie eine bestimmte Kombination von Optionen gefunden haben, die die gewünschte Ausgabe liefert, können Sie diese in einen Alias oder eine Shell-Funktion einbetten. Dies macht die Verwendung viel bequemer und erspart Ihnen das Merken komplexer Befehlszeilenoptionen.
Ein direkter Vergleich
Lassen Sie uns ls verwenden, um eine detaillierte Liste (Option -l) mit für Menschen lesbaren Dateigrößen (Option -h) zu erhalten:
ls -lh ana.h
Von links nach rechts liefert ls folgende Informationen:
Das erste Zeichen ist ein Bindestrich "-", der angibt, dass es sich um eine normale Datei handelt und nicht um ein Socket, einen symbolischen Link oder einen anderen Objekttyp.
Der Besitzer, die Gruppe und die Berechtigungen werden im Oktalformat angezeigt.
Die Anzahl der Hardlinks, die auf diese Datei verweisen, ist in diesem Fall meistens eins.
Der Dateibesitzer ist Dave.
Der Gruppenbesitzer ist Dave.
Die Dateigröße beträgt 802 Byte.
Die Datei wurde zuletzt am Freitag, dem 13. Dezember 2015, geändert.
Der Dateiname ist ana.c.
Sehen wir uns das Ganze mit stat an:
stat ana.h
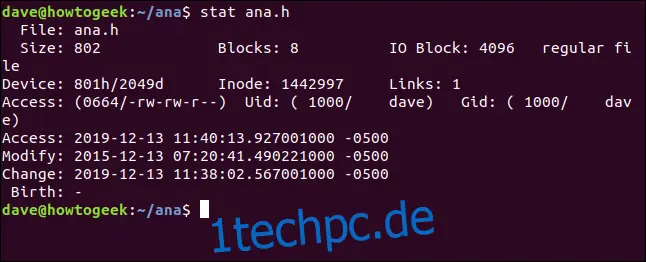
Die Informationen, die wir von stat erhalten, sind:
Datei: Der Name der Datei. Meistens ist es der gleiche Name, den wir an stat übergeben haben, aber er kann abweichen, wenn wir einen symbolischen Link betrachten.
Größe: Die Größe der Datei in Byte.
Blöcke: Die Anzahl der Dateisystemblöcke, die für die Speicherung der Datei benötigt werden.
IO-Block: Die Größe eines Dateisystemblocks.
Dateityp: Der Objekttyp, den die Metadaten beschreiben. Die gängigsten Typen sind Dateien und Verzeichnisse, aber es können auch Links, Sockets oder Named Pipes sein.
Gerät: Die Gerätenummer in hexadezimaler und dezimaler Form. Dies ist die ID des Speichermediums, auf dem die Datei gespeichert ist.
Inode: Die Inode-Nummer. Das ist die ID dieses Inodes. Zusammen identifizieren die Inode-Nummer und die Gerätenummer eine Datei eindeutig.
Links: Diese Zahl zeigt, wie viele Hardlinks auf diese Datei verweisen. Jeder Hardlink hat seinen eigenen Inode. Eine andere Sichtweise ist, wie viele Inodes auf diese eine Datei verweisen. Bei jedem Erstellen oder Löschen eines Hardlinks wird diese Zahl entsprechend angepasst. Wenn sie Null erreicht, wurde die Datei selbst gelöscht und der Inode entfernt. Wenn Sie stat für ein Verzeichnis verwenden, stellt diese Zahl die Anzahl der Einträge im Verzeichnis dar, einschließlich "." für das aktuelle Verzeichnis und ".." für das übergeordnete Verzeichnis.
Zugriff: Die Dateiberechtigungen werden in ihrem oktalen und traditionellen rwx-Format (Lesen, Schreiben, Ausführen) dargestellt.
Uid: Benutzer-ID und Benutzername des Eigentümers.
Gid: Gruppen-ID und Gruppenname des Eigentümers.
Zugriff: Der Zeitstempel des letzten Zugriffs. Nicht so einfach, wie es scheint. Moderne Linux-Distributionen verwenden ein Schema namens Relatime, das Festplatten-Schreibvorgänge, die für die Aktualisierung der Zugriffszeit erforderlich sind, zu optimieren versucht. Vereinfacht ausgedrückt wird die Zugriffszeit aktualisiert, wenn sie älter als die Änderungszeit ist.
Ändern: Der Änderungszeitstempel. Dies ist der Zeitpunkt, zu dem der Inhalt der Datei zuletzt geändert wurde. (Zufälligerweise wurde der Inhalt dieser Datei auf den Tag genau vor vier Jahren zuletzt geändert.)
Ändern: Der Zeitstempel der Statusänderung. Dies ist der Zeitpunkt, zu dem die Attribute oder der Inhalt der Datei zuletzt geändert wurden. Wenn Sie eine Datei durch Festlegen neuer Berechtigungen ändern, wird der Änderungszeitstempel aktualisiert (da sich die Dateiattribute geändert haben), der Änderungszeitstempel jedoch nicht (da sich der Dateiinhalt nicht geändert hat).
Geburt: Reserviert, um das ursprüngliche Erstellungsdatum der Datei anzuzeigen, aber unter Linux nicht implementiert.
Zeitstempel verstehen
Die Zeitstempel sind zeitzonenabhängig. Die "-0500" am Ende jeder Zeile deutet darauf hin, dass diese Datei auf einem Computer in einer Koordinierten Weltzeit (UTC) Zeitzone erstellt wurde, die der Zeitzone des aktuellen Computers um fünf Stunden voraus ist. Dieser Computer ist also fünf Stunden hinter dem Computer, der die Datei erstellt hat. Tatsächlich wurde die Datei auf einem Computer in der britischen Zeitzone erstellt, während wir sie hier auf einem Computer in der US-amerikanischen Ostküsten-Standardzeit betrachten.
Die Änderungs- und Änderungszeitstempel können verwirrend sein, da ihre Namen für den Uneingeweihten so klingen, als würden sie dasselbe bedeuten.
Lassen Sie uns mit chmod die Dateiberechtigungen für eine Datei namens `ana.c` ändern. Wir machen sie für jeden beschreibbar. Dies ändert nicht den Inhalt der Datei, sondern die Attribute der Datei:
chmod +w ana.c
Und dann verwenden wir stat, um die Zeitstempel anzuzeigen:
stat ana.c
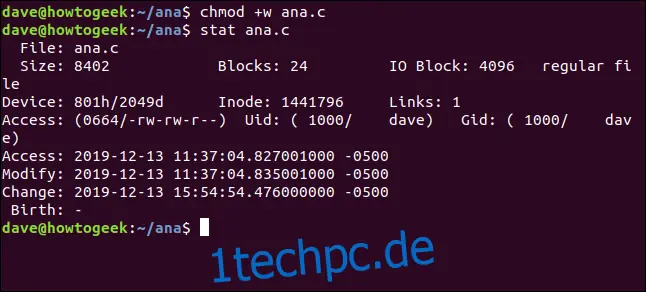
Der Änderungszeitstempel wurde aktualisiert, der Änderungszeitstempel jedoch nicht.
Der Änderungszeitstempel wird nur aktualisiert, wenn der Inhalt der Datei geändert wird. Der Änderungszeitstempel wird sowohl bei Inhaltsänderungen als auch bei Attributänderungen aktualisiert.
`stat` mit mehreren Dateien verwenden
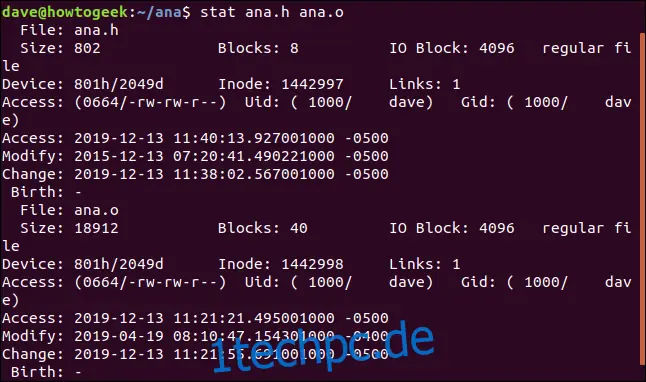
Um einen Statistikbericht für mehrere Dateien gleichzeitig zu erhalten, übergeben Sie die Dateinamen in der Befehlszeile an stat:
stat ana.h ana.o
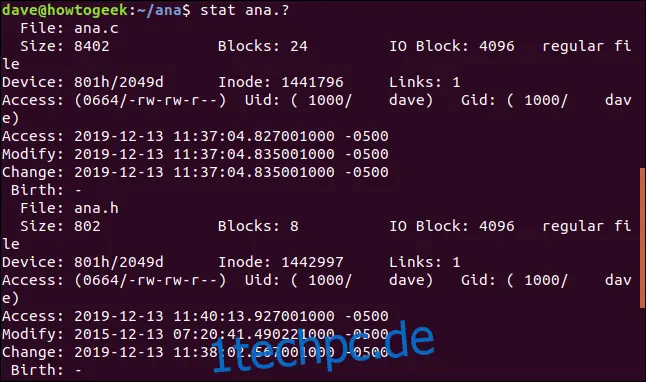
Um stat für eine Reihe von Dateien zu verwenden, nutzen Sie die Mustererkennung. Das Fragezeichen "?" steht für ein einzelnes beliebiges Zeichen und das Sternchen "*" für eine beliebige Zeichenfolge. Mit diesem Befehl können wir stat anweisen, über alle Dateien namens "ana" mit einer einzelnen Buchstabenendung zu berichten:
stat ana.?
`stat` zur Erstellung von Dateisystemberichten
stat kann sowohl über den Zustand von Dateisystemen als auch über den Zustand von Dateien berichten. Die Option -f (Dateisystem) weist stat an, über das Dateisystem zu berichten, in dem sich die Datei befindet. Beachten Sie, dass wir statt eines Dateinamens auch ein Verzeichnis wie "/" an stat übergeben können.
stat -f ana.c
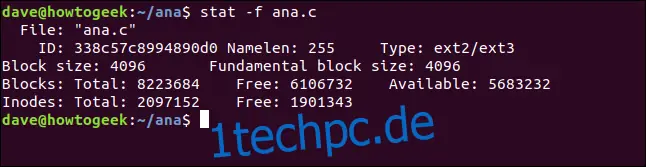
Die Informationen, die uns die Statistik liefert, sind:
Datei: Der Name der Datei.
ID: Die Dateisystem-ID in hexadezimaler Schreibweise.
Namelen: Die maximal zulässige Länge für Dateinamen.
Typ: Der Typ des Dateisystems.
Blockgröße: Die Datenmenge, um Leseanforderungen für optimale Datenübertragungsraten anzufordern.
Grundlegende Blockgröße: Die Größe jedes Dateisystemblocks.
Blöcke:
Total: Die Gesamtzahl aller Blöcke im Dateisystem.
Free: Die Anzahl der freien Blöcke im Dateisystem.
Verfügbar: Die Anzahl der freien Blöcke, die normalen (Nicht-Root-)Benutzern zur Verfügung stehen.
Inoden:
Total: Die Gesamtzahl der Inodes im Dateisystem.
Free: Die Anzahl der freien Inodes im Dateisystem.
Symbolische Links dereferenzieren
Wenn Sie stat für eine Datei verwenden, die eigentlich ein symbolischer Link ist, wird der Link gemeldet. Wenn Sie möchten, dass stat über die Datei berichtet, auf die der Link verweist, verwenden Sie die Option -L (Dereferenzierung). Die Datei code.c ist ein symbolischer Link zu ana.c. Sehen wir es uns ohne die Option -L an:
stat code.c
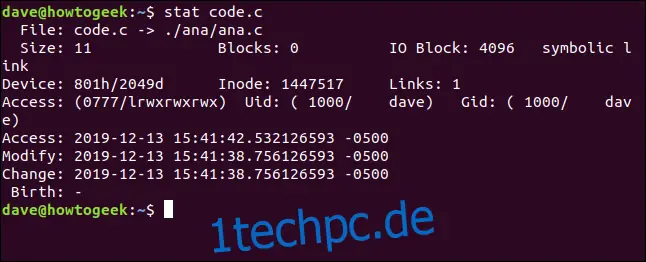
Der Dateiname lautet code.c und zeigt auf ( -> ) ana.c. Die Dateigröße beträgt nur 11 Byte. Es gibt null Blöcke, die für die Speicherung dieses Links vorgesehen sind. Der Dateityp wird als symbolischer Link aufgeführt.
Offensichtlich betrachten wir hier nicht die eigentliche Datei. Wiederholen wir das Ganze und fügen die Option -L hinzu:
stat -L code.c
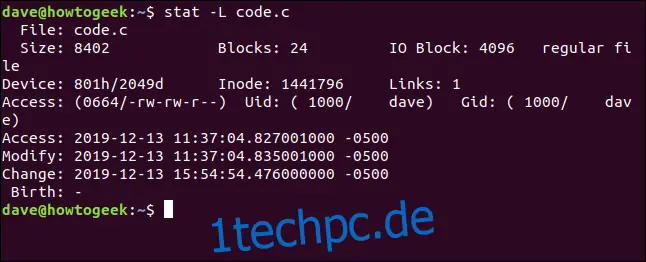
Dies zeigt nun die Dateidetails für die Datei an, auf die der symbolische Link verweist. Beachten Sie jedoch, dass der Dateiname weiterhin code.c lautet. Dies ist der Name des Links, nicht der Zieldatei. Das liegt daran, dass dies der Name ist, den wir in der Befehlszeile an stat übergeben haben.
Der kurze Bericht
Die Option -t (kurz) veranlasst stat, eine komprimierte Zusammenfassung zu liefern:
stat -t ana.c

Es werden keine Hinweise gegeben. Um das zu verstehen – bis Sie sich die Reihenfolge der Felder merken – müssen Sie diese Ausgabe mit einer vollständigen Statistikausgabe vergleichen.
Benutzerdefinierte Ausgabeformate
Eine bessere Möglichkeit, einen anderen Datensatz von stat zu erhalten, ist die Verwendung eines benutzerdefinierten Formats. Es gibt eine lange Liste von Token, die als Formatsequenzen bezeichnet werden. Jedes Token repräsentiert ein Datenelement. Wählen Sie die gewünschten Elemente für die Ausgabe aus und erstellen Sie einen Formatstring. Wenn wir stat aufrufen und ihm den Formatstring übergeben, enthält die Ausgabe nur die angeforderten Datenelemente.
Es gibt verschiedene Sätze von Formatsequenzen für Dateien und Dateisysteme. Die Liste für Dateien lautet:
- %a: Die Zugriffsrechte in Oktal.
- %A: Die Zugriffsrechte in lesbarer Form (rwx).
- %b: Die Anzahl der zugewiesenen Blöcke.
- %B: Die Größe jedes Blocks in Byte.
- %d: Die Gerätenummer in Dezimalform.
- %D: Die Gerätenummer in Hexadezimalform.
- %f: Der Rohmodus in Hexadezimalform.
- %F: Der Dateityp.
- %g: Die Gruppen-ID des Eigentümers.
- %G: Der Gruppenname des Eigentümers.
- %h: Die Anzahl der Hardlinks.
- %i: Die Inode-Nummer.
- %m: Der Mount-Punkt.
- %n: Der Dateiname.
- %N: Der Dateiname in Anführungszeichen, mit dereferenzierter Dateiname, wenn es sich um einen symbolischen Link handelt.
- %o: Hinweis zur optimalen E/A-Übertragungsgröße.
- %s: Die Gesamtgröße in Byte.
- %t: Der Hauptgerätetyp in Hexadezimalform, für spezielle Gerätedateien mit Zeichen/Block.
- %T: Der untergeordnete Gerätetyp in Hexadezimalform, für spezielle Gerätedateien für Zeichen-/Blockgeräte.
- %u: Die Benutzer-ID des Eigentümers.
- %U: Der Benutzername des Eigentümers.
- %w: Die Geburtszeit der Datei, für Menschen lesbar oder ein Bindestrich "-", falls unbekannt.
- %W: Der Zeitpunkt der Dateigeburt, Sekunden seit der Epoche; 0, falls unbekannt.
- %x: Der Zeitpunkt des letzten Zugriffs, für Menschen lesbar.
- %X: Die Zeit des letzten Zugriffs, Sekunden seit der Epoche.
- %y: Der Zeitpunkt der letzten Datenänderung, für Menschen lesbar.
- %Y: Die Zeit der letzten Datenänderung, Sekunden seit der Epoche.
- %z: Der Zeitpunkt der letzten Statusänderung, für Menschen lesbar.
- %Z: Der Zeitpunkt der letzten Statusänderung, Sekunden seit der Epoche.
Die "Epoche" ist die Unix-Epoche, die am 01.01.1970 00:00:00 +0000 (UTC) stattfand.
Für Dateisysteme lauten die Formatsequenzen:
- %a: Die Anzahl der freien Blöcke, die normalen (Nicht-Root-)Benutzern zur Verfügung stehen.
- %b: Die Gesamtzahl der Datenblöcke im Dateisystem.
- %c: Die Gesamtzahl der Inodes im Dateisystem.
- %d: Die Anzahl der freien Inodes im Dateisystem.
- %f: Die Anzahl der freien Blöcke im Dateisystem.
- %i: Die Dateisystem-ID in hexadezimaler Form.
- %l: Die maximale Länge von Dateinamen.
- %n: Der Dateiname.
- %s: Die Blockgröße (die optimale Schreibgröße).
- %S: Die Größe der Dateisystemblöcke (für die Blockanzahl).
- %t: Der Dateisystemtyp in hexadezimaler Form.
- %T: Dateisystemtyp in lesbarer Form.
Es gibt zwei Optionen, die Strings von Formatsequenzen akzeptieren: --format und --printf. Der Unterschied besteht darin, dass --printf Escape-Sequenzen im C-Stil wie Zeilenumbruch \n und Tabulator \t interpretiert und seiner Ausgabe nicht automatisch einen Zeilenumbruch hinzufügt.
Lassen Sie uns einen Formatstring erstellen und an stat übergeben. Die zu verwendenden Formatsequenzen sind %n für den Dateinamen, %s für die Größe der Datei und %F für den Dateityp. Wir fügen die Escape-Sequenz \n am Ende des Strings hinzu, um sicherzustellen, dass jede Datei in einer neuen Zeile behandelt wird. Unser Formatstring sieht so aus:
"File %n is %s bytes, and is a %F\n"
Wir übergeben dies mit der Option --printf an stat. Wir fordern stat auf, über eine Datei namens code.c und eine Reihe von Dateien, die mit ana.? übereinstimmen, zu berichten. Dies ist der vollständige Befehl. Beachten Sie das Gleichheitszeichen "=" zwischen --printf und dem Formatstring:
stat --printf="File %n is %s bytes, and is a %F\n" code.c ana/ana.?
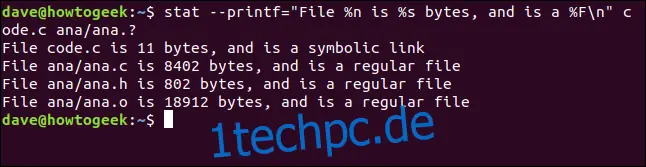
Der Bericht für jede Datei wird in einer neuen Zeile aufgelistet, wie wir es angefordert haben. Der Dateiname, die Dateigröße und der Dateityp werden uns zur Verfügung gestellt.
Benutzerdefinierte Formate ermöglichen Ihnen den Zugriff auf noch mehr Datenelemente, als in der standardmäßigen Statistikausgabe enthalten sind.
Feingesteuerte Kontrolle
Wie Sie sehen, gibt es viele Möglichkeiten, die für Sie interessanten Datenelemente zu extrahieren. Sie können wahrscheinlich auch verstehen, warum wir die Verwendung von Aliasen für die längeren und komplexeren Aufrufe empfohlen haben.