So verwenden Sie den rev-Befehl unter Linux
Der Linux-Befehl 'rev' dient dazu, Textzeichenketten umzukehren. Auf den ersten Blick wirkt dieser Befehl recht simpel. Er kann entweder direkt mit eingegebenem Text oder mit dem Inhalt einer Datei arbeiten. Doch wie so oft bei Kommandozeilenwerkzeugen, entfaltet sich sein wahres Potenzial erst in Kombination mit anderen Befehlen.
Auf den ersten Blick mag der Befehl 'rev' wie ein merkwürdiges kleines Werkzeug wirken. Seine Funktion ist sehr begrenzt: er kehrt Textsequenzen um. Außer der Möglichkeit, eine kurze Hilfeseite (-h) und die Versionsnummer (-V) anzuzeigen, akzeptiert er keine weiteren Befehlszeilenoptionen.
Ist das also alles? Kehrt 'rev' einfach nur Text um? Ja, er hat keine besonderen Variationen. Aber nein, das ist noch lange nicht alles. In diesem Artikel zeigen wir, wie man 'rev' in Kombination mit anderen Befehlen für komplexe Aufgaben nutzen kann.
Die Stärke von 'rev' zeigt sich erst, wenn er als Baustein in komplexeren Befehlsketten verwendet wird. 'rev' gehört zu einer Gruppe von Befehlen (wie z.B. 'tac' und 'yes'), die als sogenannte "Facilitatoren" fungieren. Ihre Nützlichkeit wird besonders deutlich, wenn man sieht, wie sie die Effizienz anderer Befehle steigern können.
Die Nutzung des 'rev'-Befehls
Wird 'rev' ohne weitere Parameter in der Befehlszeile aufgerufen, nimmt er jede eingegebene Zeile entgegen, kehrt diese um und gibt sie im Terminalfenster wieder aus. Dies setzt sich so lange fort, bis die Eingabe mit Strg + C abgebrochen wird.
rev
Nach der Eingabe eines Textes und der Betätigung der Eingabetaste, gibt 'rev' die Zeichenkette in umgekehrter Reihenfolge aus – es sei denn, es handelt sich um ein Palindrom.

Text an 'rev' übergeben
Mit dem Befehl 'echo' kann man Text an 'rev' weiterleiten.
echo one two three | rev

Man kann 'rev' auch nutzen, um den Inhalt einer Textdatei zeilenweise umzukehren. In diesem Beispiel haben wir eine Datei mit einer Liste von Dateinamen, die wir 'filelist.txt' nennen.
rev filelist.txt
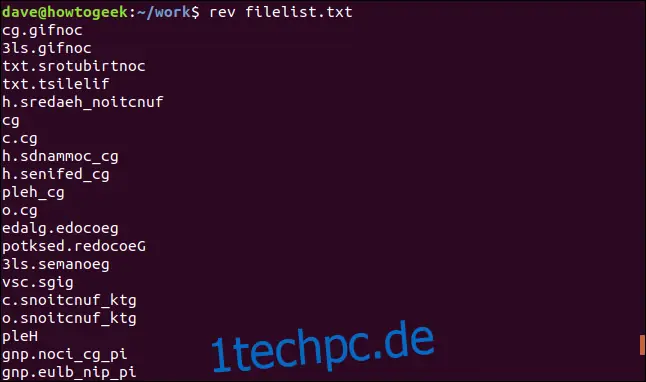
Jede Zeile wird aus der Datei gelesen, umgekehrt und dann im Terminal ausgegeben.
'rev' mit anderen Befehlen kombinieren
Hier ein Beispiel, das zeigt, wie man Eingaben per Pipe weiterleitet und 'rev' zweimal verwendet.
Dieser Befehl entfernt das letzte Zeichen einer Textkette. Dies kann beispielsweise nützlich sein, um Satzzeichen zu entfernen. Um ein Zeichen zu entfernen, nutzen wir den Befehl 'cut'.
echo 'Remove punctuation.' | rev | cut -c 2- | rev

Betrachten wir diesen Befehl genauer:
Zuerst sendet 'echo' die Zeichenkette an die erste Instanz von 'rev'.
'rev' kehrt die Zeichenkette um und leitet sie an 'cut' weiter.
Die Option '-c' (Character) weist 'cut' an, eine Teilkette zurückzugeben.
Die Option '2-' instruiert 'cut', den Bereich ab dem zweiten Zeichen bis zum Ende der Zeile zu berücksichtigen. Würde eine zweite Zahl angegeben (z.B. '2-5'), würde der Bereich vom zweiten bis zum fünften Zeichen reichen. Fehlt die zweite Zahl, bedeutet dies "bis zum Ende der Zeichenkette".
Die so veränderte Zeichenkette wird an eine zweite Instanz von 'rev' übergeben. Diese kehrt die Zeichenfolge in ihre ursprüngliche Reihenfolge zurück.
Da wir das erste Zeichen der umgekehrten Zeichenkette abgeschnitten haben, entfernen wir effektiv das letzte Zeichen der ursprünglichen Zeichenkette. Das Ergebnis ist ohne das letzte Satzzeichen. Zwar kann man dies auch mit 'sed' oder 'awk' erreichen, aber dies ist eine einfachere Syntax.
Das letzte Wort extrahieren
Mit einem ähnlichen Ansatz kann man das letzte Wort einer Zeile ausgeben.
Der Befehl ähnelt dem vorherigen: 'rev' wird wieder zweimal genutzt. Der Unterschied liegt in der Anwendung von 'cut' zur Auswahl von Textteilen.
echo 'Separate the last word' | rev | cut -d' ' -f1 | rev

Hier ist die Befehlsaufschlüsselung:
'echo' sendet die Zeichenkette an die erste Instanz von 'rev'.
'rev' kehrt die Zeichenkette um und leitet sie an 'cut' weiter.
Die Option '-d' ' (Delimiter) instruiert 'cut', die Zeichenkette nach Leerzeichen zu trennen.
Die Option '-f1' fordert 'cut' auf, den ersten Abschnitt des Strings zurückzugeben, welcher durch Leerzeichen getrennt ist. Also den ersten Teil des Satzes bis zum ersten Leerzeichen.
Das umgekehrte erste Wort wird an eine weitere Instanz von 'rev' übergeben. Dadurch wird das Wort wieder in seine ursprüngliche Reihenfolge gebracht.
Da wir das erste Wort des umgekehrten Strings extrahiert haben, haben wir effektiv das letzte Wort des ursprünglichen Strings erhalten. In diesem Fall war das letzte Wort des Satzes "word" und es wurde entsprechend ausgegeben.
Inhalte aus Dateien bearbeiten
Angenommen, wir haben eine Datei mit einer Liste von Dateinamen, welche in Anführungszeichen stehen. Wir möchten diese Anführungszeichen aus den Dateinamen entfernen.
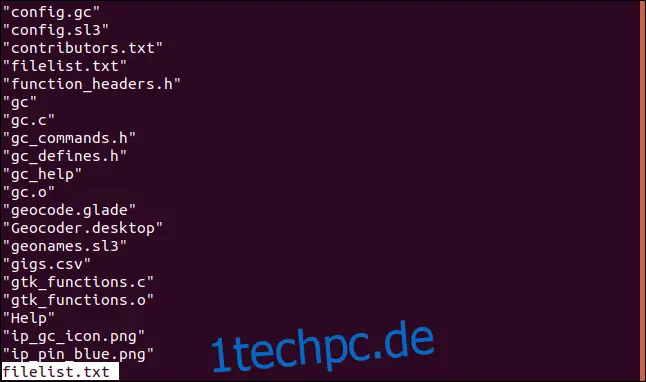
Sehen wir uns den Inhalt der Datei an:
less filelist.txt

Der Inhalt der Datei wird mit 'less' angezeigt.
Mit dem folgenden Befehl können wir Satzzeichen an beiden Enden jeder Zeile entfernen. Hier kommen 'rev' und 'cut' jeweils zweimal zum Einsatz:
rev filelist.txt | cut -c 2- | rev | cut -c 2-

Die Dateinamen werden nun ohne Anführungszeichen angezeigt.
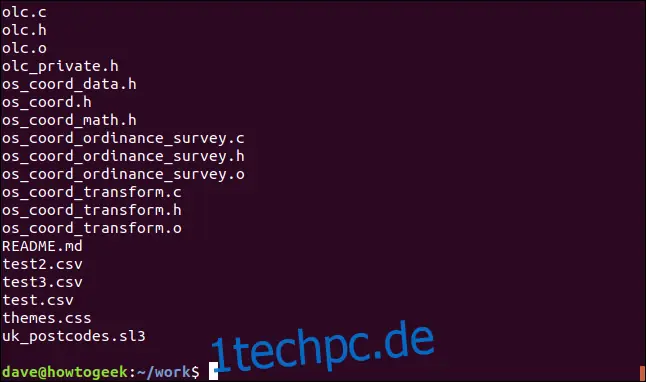
Der Befehl arbeitet wie folgt:
Zuerst kehrt 'rev' die Zeilen in der Datei um und leitet das Ergebnis an 'cut' weiter.
Die Option '-c' (Character) weist 'cut' an, eine Teilkette jeder Zeile zurückzugeben.
Die Option '2-' instruiert 'cut', den Bereich ab dem zweiten Zeichen bis zum Ende der Zeile zurückzugeben.
Die umgekehrten Zeichenketten, ohne ihre ersten Zeichen, werden an eine weitere Instanz von 'rev' übergeben.
'rev' kehrt die Zeichenketten wieder in ihre ursprüngliche Reihenfolge um und leitet diese erneut an 'cut' weiter.
Die Option '-c' (Character) fordert 'cut' auf, eine Teilkette jedes Strings zurückzugeben.
Die Option '2-' instruiert 'cut', den Zeichenbereich ab dem zweiten Zeichen bis zum Ende jeder Zeile zurückzugeben. Dies "überspringt" das führende Anführungszeichen, das in jeder Zeile das erste Zeichen ist.
Komplexere Befehlsketten
Hier ein Befehl, der eine sortierte Liste aller Dateiendungen im aktuellen Verzeichnis liefert. Er verwendet fünf verschiedene Linux-Befehle:
ls | rev | cut -d'.' -f1 | rev | sort | uniq
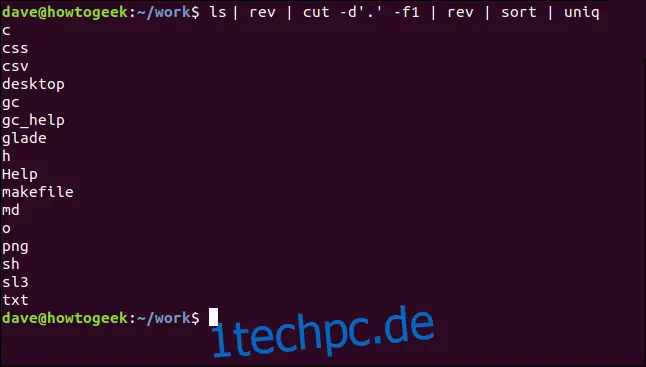
Die Befehlskette funktioniert wie folgt:
'ls' listet die Dateien im aktuellen Verzeichnis auf. Die Ausgabe wird an 'rev' weitergeleitet.
'rev' kehrt die Dateinamen um und leitet diese an 'cut' weiter.
'cut' gibt den ersten Teil jedes Dateinamens bis zu einem Trennzeichen zurück. Die Option '-d\'.\' weist 'cut' an, den Punkt '.' als Trennzeichen zu nutzen. Der Teil der umgekehrten Dateinamen bis zum ersten Punkt sind die Dateiendungen. Diese werden an 'rev' weitergeleitet.
'rev' kehrt die Dateiendungen wieder in ihre ursprüngliche Reihenfolge zurück. Diese werden dann sortiert.
'sort' sortiert die Dateiendungen und leitet das Ergebnis an 'uniq' weiter.
'uniq' gibt für jeden Dateiendungstyp eine einzelne Liste zurück. Es ist zu beachten, dass der gesamte Dateiname aufgeführt wird, falls keine Dateiendung vorhanden ist (wie bei den Dateien Makefile und den Verzeichnissen Help und gc_help).
Um das Ergebnis zu verfeinern, kann man die Befehlszeilenoption '-c' (Count) zu 'uniq' hinzufügen:
ls | rev | cut -d'.' -f1 | rev | sort | uniq -c
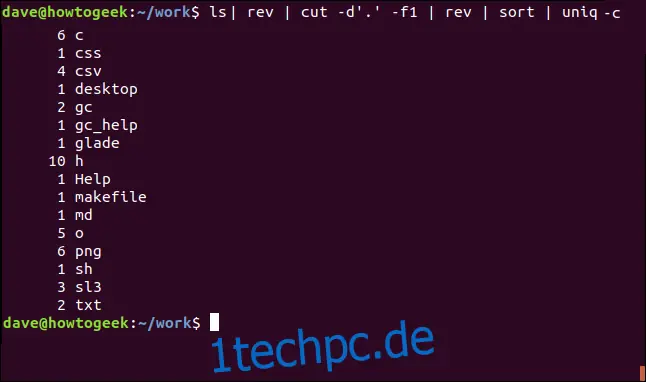
Nun erhalten wir eine sortierte Liste der verschiedenen Dateitypen im aktuellen Verzeichnis zusammen mit der jeweiligen Anzahl.
Das ist eine recht elegante Einzeiler-Lösung!
Vorwärts gehen, indem man Rückwärts denkt
Manchmal muss man rückwärts denken, um vorwärtszukommen. Und oft kommt man im Team am schnellsten zum Ziel.
Erweitern Sie Ihr Repertoire an Befehlen um 'rev'. Bald werden Sie feststellen, dass er Ihnen helfen wird, komplexe Befehlssequenzen zu vereinfachen.
