So verwenden Sie curl zum Herunterladen von Dateien von der Linux-Befehlszeile
Der Linux-Befehl `curl` ist weit mehr als ein reines Download-Werkzeug. Entdecken Sie das vielseitige Potenzial von `curl` und erfahren Sie, wann dieser Befehl anstelle von `wget` eingesetzt werden sollte.
`curl` vs. `wget`: Eine Gegenüberstellung
Oftmals fällt es schwer, die jeweiligen Vorteile von `wget` und `curl` zu erkennen. Zwar ähneln sich ihre Funktionen in mancher Hinsicht – beide können Daten von entfernten Quellen beziehen – doch damit sind die Gemeinsamkeiten auch schon erschöpft.
`wget` ist ein hervorragendes Hilfsmittel zum Herunterladen von Dateien und Inhalten. Es ermöglicht den Download einzelner Dateien, ganzer Webseiten und Verzeichnisse. Durch seine Fähigkeit, Links auf Webseiten zu verfolgen und Inhalte rekursiv von einer gesamten Website herunterzuladen, ist es als Kommandozeilen-Download-Manager unübertroffen.
Auf der anderen Seite deckt `curl` einen ganz anderen Bedarf ab. Zwar kann `curl` auch Dateien herunterladen, doch es ist nicht in der Lage, Webseiten rekursiv zu durchsuchen, um nach Inhalten zu suchen. Die eigentliche Stärke von `curl` liegt in der Interaktion mit entfernten Systemen, indem es Anfragen an diese Systeme sendet und die Antworten empfängt und anzeigt. Diese Antworten können Webseiten-Inhalte, Dateien oder auch Daten umfassen, die über einen Webdienst oder eine API als Ergebnis einer `curl`-Anfrage bereitgestellt werden.
Darüber hinaus ist `curl` nicht auf Websites beschränkt. Es unterstützt über 20 Protokolle, darunter HTTP, HTTPS, SCP, SFTP und FTP. Aufgrund seiner überlegenen Handhabung von Linux-Pipes lässt sich `curl` außerdem einfacher in andere Befehle und Skripte integrieren.
Der Entwickler von `curl` stellt auf seiner Webseite eine detaillierte Beschreibung der Unterschiede zwischen `curl` und `wget` bereit.
Installation von `curl`
Auf den Rechnern, die für die Recherche zu diesem Artikel verwendet wurden, war `curl` bereits auf Fedora 31 und Manjaro 18.1.0 vorinstalliert. Lediglich auf Ubuntu 18.04 LTS musste `curl` erst installiert werden. Unter Ubuntu erfolgt die Installation mit diesem Befehl:
sudo apt-get install curl
Abrufen der `curl`-Version
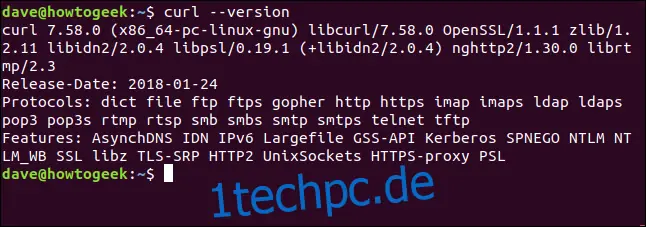
Mit der Option `--version` kann man sich die Versionsnummer von `curl` anzeigen lassen. Zusätzlich werden alle unterstützten Protokolle aufgelistet.
curl --version
Abrufen einer Webseite
Wenn wir `curl` auf eine Webseite zeigen lassen, wird diese abgerufen.
curl https://www.bbc.com

Standardmäßig wird der Quellcode der Webseite im Terminalfenster angezeigt.
Achtung: Sofern Sie `curl` nicht anweisen, die abgerufenen Daten als Datei zu speichern, werden diese stets im Terminalfenster ausgegeben. Bei Binärdateien kann dies zu unerwarteten Ergebnissen führen, da die Shell versuchen könnte, Teile der Binärdaten als Steuerzeichen oder Escape-Sequenzen zu interpretieren.
Speichern von Daten in einer Datei
Um die Ausgabe von `curl` in eine Datei umzuleiten, verwenden wir:
curl https://www.bbc.com > bbc.html

Dieses Mal wird die abgerufene Webseite nicht im Terminalfenster angezeigt, sondern direkt in der Datei gespeichert. Da keine Ausgabe im Terminalfenster erfolgt, zeigt `curl` stattdessen eine Fortschrittsanzeige an.
Im vorherigen Beispiel war dies nicht der Fall, da die Fortschrittsinformationen im Quellcode der Webseite untergegangen wären. Daher hat `curl` die Anzeige der Fortschrittsinformationen automatisch unterdrückt.
Hier erkennt `curl`, dass die Ausgabe in eine Datei umgeleitet wird und dass die Fortschrittsinformationen gefahrlos angezeigt werden können.
Die angezeigten Informationen umfassen:
% Total: Die Gesamtmenge der abzurufenden Daten.
% Empfangen: Der Prozentsatz und die tatsächlichen Werte der bisher heruntergeladenen Daten.
% Xferd: Der Prozentsatz und der tatsächlich gesendete Wert, wenn Daten hochgeladen werden.
Durchschnittliche Download-Geschwindigkeit: Die durchschnittliche Download-Geschwindigkeit.
Durchschnittliche Upload-Geschwindigkeit: Die durchschnittliche Upload-Geschwindigkeit.
Gesamtzeit: Die geschätzte Gesamtübertragungsdauer.
Verbrauchte Zeit: Die bisher für diese Übertragung verstrichene Zeit.
Verbleibende Zeit: Die geschätzte Zeit bis zum Abschluss der Übertragung.
Aktuelle Geschwindigkeit: Die aktuelle Übertragungsgeschwindigkeit für diese Übertragung.
Nach der Umleitung der `curl`-Ausgabe in eine Datei existiert nun die Datei `bbc.html`.

Durch einen Doppelklick auf diese Datei wird Ihr Standardbrowser geöffnet und die heruntergeladene Webseite angezeigt.
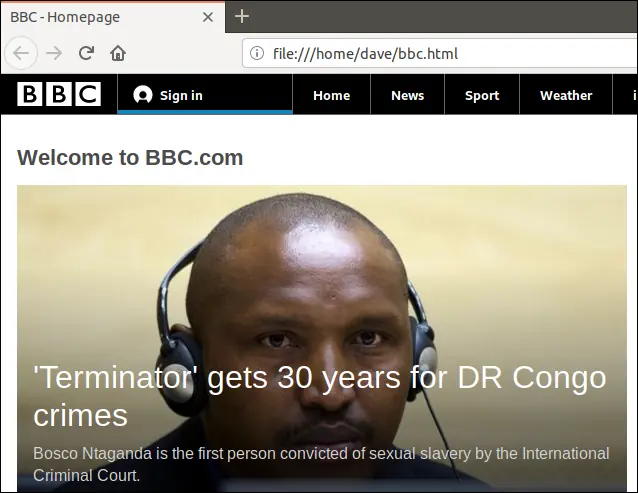
Beachten Sie, dass die Adresse in der Adressleiste des Browsers eine lokale Datei auf Ihrem Rechner und keine Remote-Website ist.
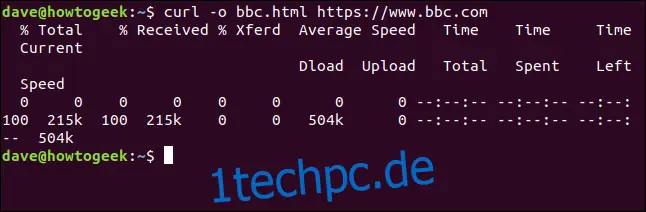
Um eine Datei zu erstellen, ist eine Umleitung der Ausgabe nicht zwingend erforderlich. Mit der Option `-o` (Ausgabe) kann `curl` angewiesen werden, eine Datei zu erstellen. Im folgenden Beispiel verwenden wir die Option `-o` und geben den Namen der zu erstellenden Datei, `bbc.html`, an.
curl -o bbc.html https://www.bbc.com
Verwenden einer Fortschrittsanzeige zur Überwachung von Downloads
Um die textbasierten Downloadinformationen durch eine simple Fortschrittsanzeige zu ersetzen, verwenden Sie die Option `-#` (Fortschrittsbalken).
curl -# -o bbc.html https://www.bbc.com

Fortsetzen eines unterbrochenen Downloads
Ein abgebrochener oder unterbrochener Download kann problemlos fortgesetzt werden. Zunächst starten wir den Download einer großen Datei. Hierfür verwenden wir den aktuellen Long Term Support-Build von Ubuntu 18.04. Mit der Option `--output` geben wir den Namen der Zieldatei an, in der die Datei gespeichert werden soll: `ubuntu180403.iso`.
curl --output ubuntu18043.iso https://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Der Download beginnt und läuft bis zum Abschluss.
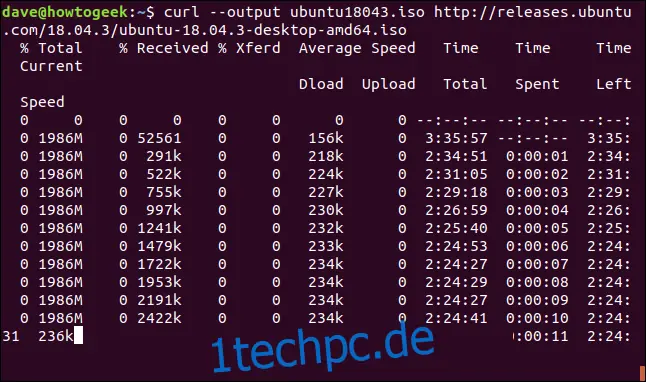
Wenn wir den Download mit Strg+C unterbrechen, kehren wir zur Eingabeaufforderung zurück, und der Download ist abgebrochen.
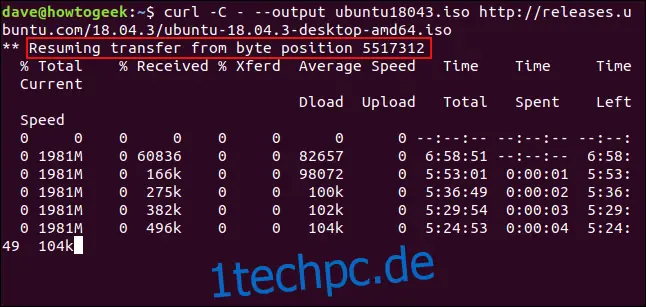
Um den Download wiederaufzunehmen, verwenden Sie die Option `-C` (fortsetzen mit). Dadurch wird `curl` angewiesen, den Download an einem bestimmten Punkt oder Offset in der Zieldatei wiederaufzunehmen. Wenn Sie einen Bindestrich als Offset verwenden, ermittelt `curl` automatisch den bereits heruntergeladenen Teil der Datei und setzt an der entsprechenden Stelle fort.
curl -C - --output ubuntu18043.iso https://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Der Download wird fortgesetzt. `curl` gibt den Offset an, an dem der Download wiederaufgenommen wurde.
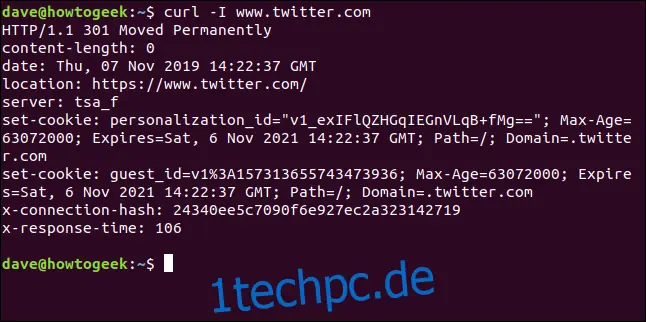
Abrufen von HTTP-Headern
Mit der Option `-I` (head) können Sie ausschließlich die HTTP-Header abrufen. Dies entspricht dem Senden des HTTP HEAD-Befehls an einen Webserver.
curl -I www.twitter.com

Dieser Befehl ruft nur Informationen ab, es werden keine Webseiten oder Dateien heruntergeladen.
Herunterladen mehrerer URLs
Mit `xargs` können mehrere URLs gleichzeitig heruntergeladen werden. Dies kann nützlich sein, wenn Sie beispielsweise eine Reihe von Webseiten herunterladen möchten, die einen einzelnen Artikel oder ein Tutorial bilden.
Kopieren Sie diese URLs in einen Editor und speichern Sie die Liste in einer Datei namens `urls-to-download.txt`. Mit `xargs` können die einzelnen Zeilen der Textdatei als Parameter an `curl` weitergeleitet werden.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
Um `xargs` diese URLs nacheinander an `curl` weiterzuleiten, verwenden wir folgenden Befehl:
xargs -n 1 curl -O < urls-to-download.txt
Der Befehl verwendet die Option `-O` (Remote-Datei). Diese Option bewirkt, dass `curl` die abgerufene Datei unter dem gleichen Namen speichert, den die Datei auf dem Remote-Server hat.
Die Option `-n 1` weist `xargs` an, jede Zeile der Textdatei als separaten Parameter zu behandeln.
Beim Ausführen des Befehls werden Sie sehen, wie mehrere Downloads nacheinander gestartet und abgeschlossen werden.
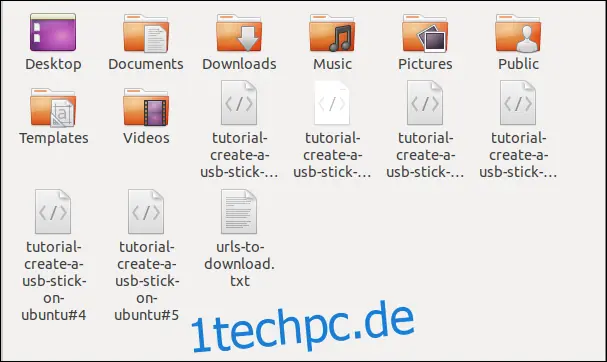
Die Überprüfung im Dateibrowser zeigt, dass mehrere Dateien heruntergeladen wurden. Jede Datei trägt den Namen, den sie auf dem Remote-Server hatte.
Herunterladen von Dateien von einem FTP-Server
Die Verwendung von `curl` mit einem File Transfer Protocol (FTP)-Server ist unkompliziert, auch wenn eine Authentifizierung mit Benutzername und Passwort erforderlich ist. Um Benutzername und Passwort an `curl` zu übergeben, verwenden Sie die Option `-u` (Benutzer) und geben Sie den Benutzernamen, einen Doppelpunkt `:` und das Passwort an. Setzen Sie kein Leerzeichen vor oder nach den Doppelpunkt.
Dieser kostenlose Test-FTP-Server wird von Rebex gehostet. Auf diesem Test-FTP-Server ist der Benutzername `demo` und das Passwort `password` festgelegt. Verwenden Sie solche einfachen Benutzernamen und Passwörter nicht auf Produktions- oder "echten" FTP-Servern.
curl -u demo:password ftp://test.rebex.net

`curl` erkennt, dass wir auf einen FTP-Server verweisen und gibt eine Liste der Dateien zurück, die sich auf dem Server befinden.

Auf diesem Server befindet sich lediglich die Datei `readme.txt` mit einer Länge von 403 Byte. Laden wir diese Datei herunter. Verwenden Sie den gleichen Befehl wie zuvor, und hängen Sie den Dateinamen an:
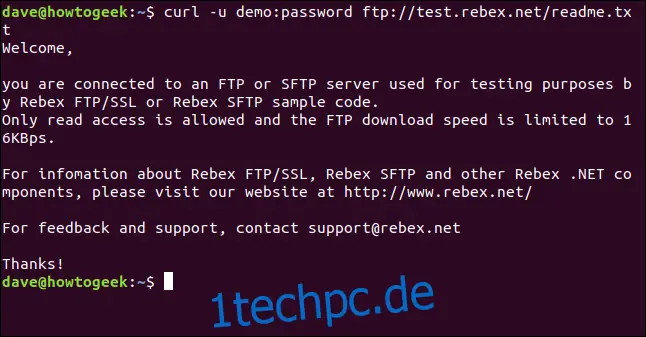
curl -u demo:password ftp://test.rebex.net/readme.txt

Die Datei wird abgerufen, und `curl` gibt deren Inhalt im Terminalfenster aus.
In den meisten Fällen ist es praktischer, die heruntergeladene Datei direkt auf der Festplatte zu speichern, anstatt sie im Terminalfenster anzuzeigen. Wiederum können wir den Ausgabebefehl `-O` (Remote-Datei) verwenden, um die Datei auf der Festplatte mit dem gleichen Dateinamen zu speichern, den sie auf dem Remote-Server hatte.
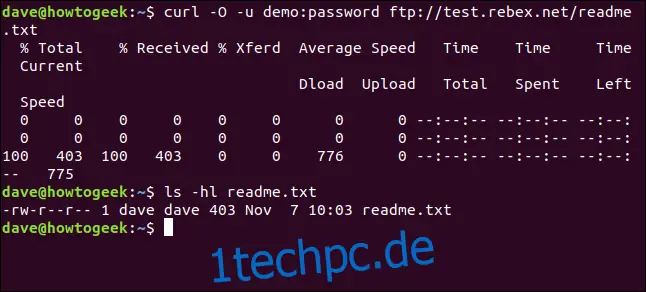
curl -O -u demo:password ftp://test.rebex.net/readme.txt

Die Datei wird heruntergeladen und auf der Festplatte gespeichert. Mit `ls` können wir die Details der Datei überprüfen. Sie hat den gleichen Namen wie die Datei auf dem FTP-Server und die gleiche Länge, 403 Byte.
ls -hl readme.txt
Senden von Parametern an entfernte Server
Einige entfernte Server akzeptieren Parameter in Anfragen, die an sie gesendet werden. Parameter können z.B. verwendet werden, um die zurückgegebenen Daten zu formatieren oder um bestimmte Daten auszuwählen, die der Benutzer abrufen möchte. Oft ist es möglich, über `curl` mit dem Application Programming Interfaces (APIs) zu interagieren.
Als einfaches Beispiel verwenden wir die Website ipify, die eine API bereitstellt, über die man die eigene externe IP-Adresse ermitteln kann.
curl https://api.ipify.org
Durch Hinzufügen des Parameters `format` mit dem Wert `json` fordern wir erneut unsere externe IP-Adresse an, doch dieses Mal werden die zurückgegebenen Daten im JSON-Format codiert.
curl https://api.ipify.org?format=json

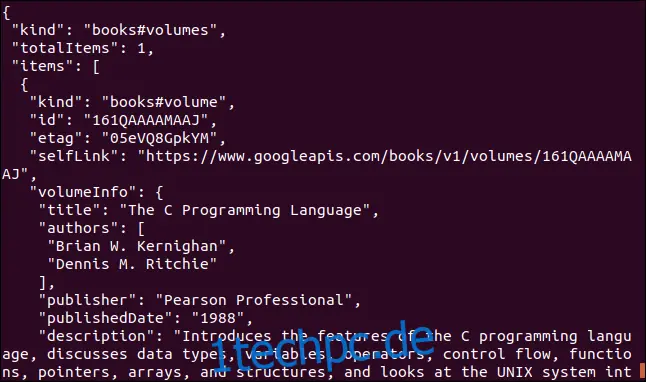
Ein weiteres Beispiel verwendet eine Google-API. Es wird ein JSON-Objekt zurückgegeben, das ein Buch beschreibt. Der Parameter, den Sie angeben müssen, ist die International Standard Book Number (ISBN) eines Buches. Sie finden diese in der Regel auf der Rückseite der meisten Bücher unter einem Strichcode. Der hier verwendete Parameter lautet "0131103628".
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

Die zurückgegebenen Daten sind umfangreich:
Manchmal `curl`, manchmal `wget`
Wenn ich Inhalte von einer Webseite herunterladen und die Baumstruktur der Webseite rekursiv nach Inhalten durchsuchen möchte, würde ich `wget` verwenden.
Wenn ich mit einem entfernten Server oder einer API interagieren und möglicherweise Dateien oder Webseiten herunterladen möchte, würde ich `curl` verwenden. Insbesondere, wenn ein Protokoll verwendet wird, das `wget` nicht unterstützt.
