So verwenden Sie at und Batch unter Linux zum Planen von Befehlen
Wenn du unter Linux einen Task planst, der nur ein einziges Mal ausgeführt werden soll, ist die Verwendung von Cron oft überdimensioniert. Die Befehlsfamilie `at` ist hierfür die ideale Lösung! Möchtest du hingegen, dass ein Prozess nur dann ausgeführt wird, wenn das System freie Kapazitäten hat, kannst du `batch` nutzen.
Planen von Aufgaben unter Linux
Der Cron-Daemon verwaltet eine Liste von Aufgaben, die zu bestimmten Zeiten ausgeführt werden. Diese Tasks und Programme laufen dann zu den definierten Zeitpunkten im Hintergrund. Das bietet dir eine hohe Flexibilität, wenn es um wiederkehrende Aufgaben geht. Egal, ob du einen Task stündlich, zu einer bestimmten Tageszeit, einmal im Monat oder im Jahr ausführen möchtest, mit Cron ist das problemlos möglich.
Das hilft jedoch nicht, wenn du eine Aufgabe nur ein einziges Mal starten willst. Natürlich könntest du auch hier Cron verwenden, müsstest aber dann daran denken, den entsprechenden Eintrag in der Crontab wieder zu löschen, nachdem die Aufgabe erledigt wurde – was unpraktisch ist.
Wenn du unter Linux ein Problem hast, ist es sehr wahrscheinlich, dass auch andere damit zu kämpfen hatten. Da Unix-ähnliche Systeme schon lange existieren, ist die Wahrscheinlichkeit groß, dass jemand bereits eine Lösung für dein Problem entwickelt hat.
Für das oben beschriebene Szenario gibt es diese Lösung, und sie wird mit dem Befehl `at` bereitgestellt.
Installation des at-Befehls
Unter Ubuntu 18.04 und Manjaro 18.1.0 war die Installation erforderlich (auf Fedora 31 war er bereits installiert).
Unter Ubuntu installierst du den Befehl mit:
sudo apt-get install at
Nach der Installation kannst du den at-Daemon mit folgendem Befehl starten:
sudo systemctl enable --now atd.service

Auf Manjaro erfolgt die Installation mit folgendem Befehl:
sudo pacman -Sy at

Nach der Installation startest du den at-Daemon mit:
sudo systemctl enable --now atd.service

Auf jeder Distribution kannst du mit diesem Befehl prüfen, ob der atd-Daemon läuft:
ps -e | grep atd

Interaktive Nutzung des at-Befehls
Um `at` nutzen zu können, musst du ihm ein Datum und eine Zeit für die Ausführung mitgeben. Dabei gibt es flexible Möglichkeiten, auf die wir später noch genauer eingehen werden.
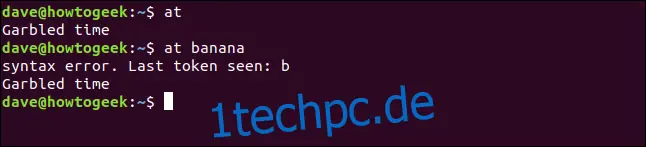
Selbst wenn wir `at` interaktiv verwenden, musst du Datum und Zeit im Voraus angeben. Wenn du in der Befehlszeile keine Zeitangabe machst, oder etwas eingibst, was keine Zeit ist, wird `at` mit „Ungültige Zeitangabe“ antworten, wie hier gezeigt:
at
at banane
Datums- und Zeitangaben können explizit oder relativ angegeben werden. Möchtest du beispielsweise, dass ein Befehl in einer Minute ausgeführt wird, weiß `at`, was "jetzt" bedeutet. Du kannst also "now" verwenden und eine Minute hinzufügen:
at now + 1 minute

Nach Eingabe des Befehls gibt `at` eine Nachricht und eine Eingabeaufforderung aus und wartet darauf, dass du die auszuführenden Befehle eingibst. Beachte jedoch zuerst die folgende Nachricht:

Hier wird dir mitgeteilt, dass eine Instanz der sh-Shell gestartet wird und die Befehle darin ausgeführt werden. Deine Befehle werden also nicht in der Bash-Shell ausgeführt, die zwar kompatibel mit der sh-Shell ist, aber einen größeren Funktionsumfang bietet.
Wenn deine Befehle oder Skripte Funktionen nutzen, die Bash bereitstellt, sh jedoch nicht, werden diese fehlschlagen.
Du kannst leicht testen, ob deine Befehle oder Skripte in sh ausgeführt werden. Starte hierzu eine sh-Shell mit dem Befehl `sh`:
sh

Die Eingabeaufforderung ändert sich zu einem Dollarzeichen ($), und du kannst jetzt deine Befehle ausführen und überprüfen, ob sie korrekt funktionieren.
Um zur Bash-Shell zurückzukehren, gibst du den Befehl `exit` ein:
exit
Du wirst keine Standardausgaben oder Fehlermeldungen der Befehle auf dem Bildschirm sehen, da die sh-Shell als Hintergrundaufgabe ohne grafische Oberfläche gestartet wird.
Jegliche Ausgaben der Befehle – ob positiv oder negativ – werden dir per E-Mail zugesandt. Diese wird über das interne Mailsystem an den Benutzer gesendet, der den `at`-Befehl ausführt. Das bedeutet, dass du dieses interne Mailsystem einrichten und konfigurieren musst.
Viele (die meisten) Linux-Systeme haben kein internes Mailsystem, da es selten benötigt wird. Die Systeme, die eines haben, verwenden typischerweise Programme wie sendmail oder Postfix. Wenn dein System kein internes Mailsystem hat, kannst du Skripte in Dateien schreiben oder die Ausgaben in Dateien umleiten, um sie zu protokollieren.
Sollte ein Befehl keine Standardausgabe oder Fehlermeldungen produzieren, wirst du ohnehin keine E-Mail erhalten. Viele Linux-Befehle signalisieren Erfolg durch Stille, sodass du in den meisten Fällen keine E-Mail erhalten wirst.
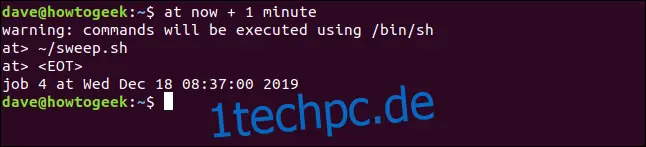
Nun ist es Zeit, einen Befehl einzugeben. In diesem Beispiel verwenden wir eine kleine Skriptdatei namens `sweep.sh`, die Dateien mit den Endungen `.bak`, `.tmp` und `.o` löscht. Gib den Pfad zu dem Befehl wie unten gezeigt ein und drücke dann die Eingabetaste:

Eine weitere Eingabeaufforderung wird angezeigt, und du kannst beliebig viele Befehle hinzufügen. In der Regel ist es einfacher, deine Befehle in einem Skript zusammenzufassen und dieses Skript dann aufzurufen.
Drücke Strg+D, um zu signalisieren, dass du mit dem Hinzufügen von Befehlen fertig bist. `at` zeigt dann `
Nach der Ausführung des Jobs kannst du deine internen E-Mails mit folgendem Befehl überprüfen:

Wenn keine E-Mail kommt, kannst du davon ausgehen, dass die Aufgabe erfolgreich war. In diesem Fall kannst du natürlich prüfen, ob die Dateien `.bak`, `.tmp` und `.o` gelöscht wurden, um zu bestätigen, dass der Befehl korrekt funktioniert hat.
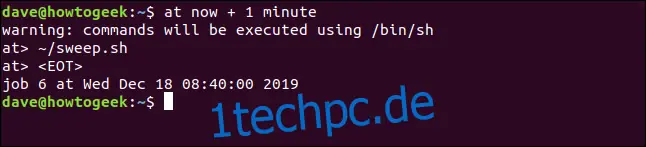
Um das Ganze erneut auszuführen, gib Folgendes ein:
at now + 1 minute
Nach einer Minute gibst du den folgenden Befehl ein, um deine E-Mails erneut zu prüfen:

Tatsächlich, wir haben Post! Um die erste Nachricht zu lesen, drücke die Ziffer 1 und dann die Eingabetaste.
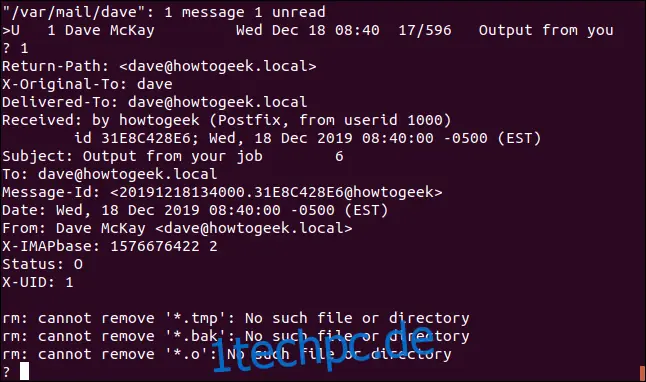
Wir haben eine E-Mail von `at` erhalten, weil die Befehle im Skript Fehlermeldungen produziert haben. In diesem Beispiel gab es keine zu löschenden Dateien, da diese beim vorherigen Ausführen des Skripts bereits entfernt wurden.
Drücke D+Eingabe, um die E-Mail zu löschen und Q+Eingabe, um das E-Mail-Programm zu beenden.
Datums- und Zeitformate
Du bist sehr flexibel, was die Zeitformate angeht, die du nutzen kannst. Hier sind ein paar Beispiele:
Ausführung um 11:00 Uhr:
at 11:00 AM
Ausführung morgen um 11:00 Uhr:
at 11:00 AM tomorrow
Ausführung nächste Woche um 11:00 Uhr an diesem Tag:
at 11:00 AM next week
Ausführung zu dieser Zeit, an diesem Tag, nächste Woche:
at next week
Ausführung um 11:00 Uhr nächsten Freitag:
at 11:00 AM next fri
Ausführung nächsten Freitag zu dieser Zeit:
at next fri
Ausführung um 11:00 Uhr an diesem Tag, nächsten Monat:
at 11:00 AM next month
Ausführung um 11:00 Uhr an einem bestimmten Datum:
at 11:00 AM 3/15/2020
Ausführung in 30 Minuten ab jetzt:
at now + 30 minutes
Ausführung in zwei Stunden ab jetzt:
at now + 2 hours
Ausführung morgen um diese Zeit:
at tomorrow
Ausführung am Donnerstag zu dieser Zeit:
at thursday
Ausführung um 12:00 Uhr Mitternacht:
at midnight
Ausführung um 12:00 Uhr Mittag:
at noon
Wenn du Brite bist, kannst du sogar einen Befehl für die Teezeit (16:00 Uhr) planen:
at teatime
Einblick in die Job-Warteschlange
Du kannst den Befehl `atq` nutzen, um die Warteschlange der geplanten Jobs anzuzeigen, wie unten gezeigt:

Für jeden Befehl in der Warteschlange zeigt `atq` folgende Informationen:
| Job-ID |
| Geplantes Datum |
| Geplante Zeit |
| Die Warteschlange, in die der Job eingereiht wird. Die Warteschlangen werden mit "a", "b", usw. gekennzeichnet. Normale Tasks, die du mit `at` planst, werden in die Warteschlange "a" eingeordnet, während Tasks, die du mit `batch` planst (später in diesem Artikel behandelt), in die Warteschlange "b" kommen. |
| Die Person, die den Job geplant hat. |
Nutzung von at in der Befehlszeile
Du musst `at` nicht interaktiv nutzen; du kannst den Befehl auch direkt in der Befehlszeile verwenden. Das erleichtert die Nutzung in Skripten.
Du kannst Befehle wie folgt an `at` weiterleiten:
echo "sh ~/sweep.sh" | at 08:45 AM

Der Job wird von `at` angenommen und geplant, und die Jobnummer und das Ausführungsdatum werden wie zuvor gemeldet.
Nutzung von at mit Befehlsdateien
Du kannst auch eine Befehlsfolge in einer Datei speichern und diese dann an `at` übergeben. Das kann eine einfache Textdatei mit Befehlen sein – es muss kein ausführbares Skript sein.
Du kannst die Option `-f` (Datei) verwenden, um einen Dateinamen an `at` zu übergeben:
at now + 5 minutes -f clean.txt

Du kannst das gleiche Ergebnis erzielen, indem du die Datei in `at` umleitest:
at now + 5 minutes < clean.txt

Entfernen geplanter Jobs aus der Warteschlange
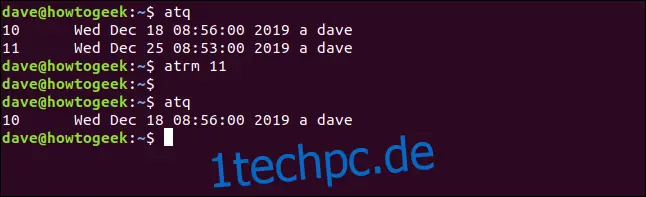
Um einen geplanten Job aus der Warteschlange zu entfernen, kannst du den Befehl `atrm` verwenden. Wenn du dir zuerst die Warteschlange ansehen möchtest, um die Jobnummer zu finden, kannst du `atq` verwenden. Dann verwendest du diese Jobnummer zusammen mit `atrm`, wie unten gezeigt:
atq
atrm 11
atq
Detaillierte Jobansicht
Wie bereits erwähnt, kannst du Jobs weit in die Zukunft planen. Es kann vorkommen, dass du vergisst, was ein Job tun soll. Der Befehl `atq` zeigt dir die Jobs in der Warteschlange an, aber nicht, was sie tun werden. Wenn du eine detaillierte Ansicht eines Jobs anzeigen möchtest, kannst du die Option `-c` (cat) verwenden.
Zuerst nutzen wir `atq`, um die Jobnummer zu finden:
atq

Nun verwenden wir Jobnummer 13 mit der Option `-c`:
at -c 13
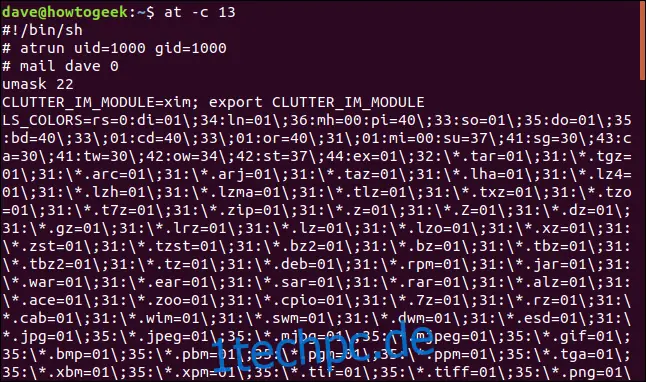
Hier ist eine Aufschlüsselung der Informationen, die wir über den Job erhalten:
Erste Zeile: Diese Zeile zeigt an, dass die Befehle unter der sh-Shell ausgeführt werden.
Zweite Zeile: Wir sehen, dass die Befehle sowohl mit einer Benutzer- als auch mit einer Gruppen-ID von 1000 ausgeführt werden. Dies sind die Werte des Nutzers, der den Befehl `at` ausgeführt hat.
Dritte Zeile: Die Person, die alle E-Mails erhalten wird, wird angegeben.
Vierte Zeile: Die Benutzermaske ist 22. Dies ist die Maske, die verwendet wird, um die Standardberechtigungen für alle Dateien festzulegen, die in dieser sh-Sitzung erstellt wurden. Die Maske wird von 666 abgezogen, was uns 644 (das oktale Äquivalent von rw-r--r--) ergibt.
Restliche Daten: Der Großteil sind Umgebungsvariablen.
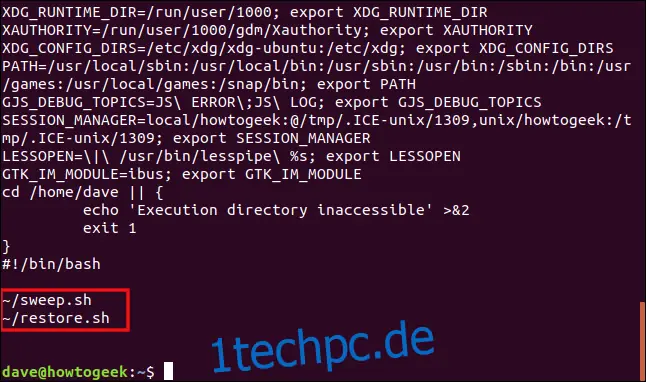
Ergebnisse eines Tests. Ein Test prüft, ob auf das Ausführungsverzeichnis zugegriffen werden kann. Wenn das nicht möglich ist, wird ein Fehler ausgegeben und die Jobausführung abgebrochen.
Die auszuführenden Befehle. Diese werden aufgelistet, und der Inhalt der geplanten Skripte wird angezeigt. Beachte, dass das Skript in unserem obigen Beispiel zwar für die Ausführung unter Bash geschrieben wurde, es jedoch in einer SH-Shell ausgeführt wird.
Der Batch-Befehl
Der Batch-Befehl funktioniert ähnlich wie der at-Befehl, jedoch mit drei wesentlichen Unterschieden:
Du kannst den Batch-Befehl nur interaktiv verwenden.
Anstatt Jobs so zu planen, dass sie zu einem bestimmten Zeitpunkt ausgeführt werden, fügst du sie der Warteschlange hinzu, und der Batch-Befehl führt sie aus, wenn die durchschnittliche Auslastung des Systems unter 1,5 liegt.
Aus diesem Grund gibst du beim Batch-Befehl niemals ein Datum und eine Uhrzeit an.
Um den Batch-Befehl zu verwenden, gibst du ihn ohne Befehlszeilenparameter wie folgt ein:
batch
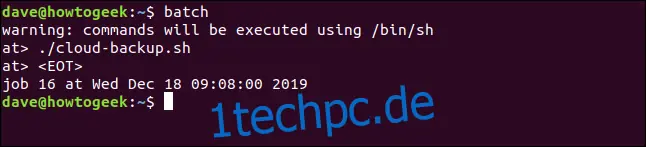
Danach fügst du Aufgaben auf die gleiche Weise hinzu wie beim at-Befehl.
Kontrolle des Zugriffs auf den at-Befehl
Die Dateien `at.allow` und `at.deny` steuern, wer die Befehlsfamilie `at` verwenden darf. Diese Dateien befinden sich im Verzeichnis `/etc`. Standardmäßig existiert nur die Datei `at.deny`, die bei der Installation von `at` erstellt wird.
So funktionieren diese Dateien:
`at.deny`: Listet Benutzer und Entitäten auf, die `at` nicht zur Planung von Jobs verwenden können.
`at.allow`: Listet auf, wer `at` verwenden darf, um Jobs zu planen. Wenn die Datei `at.allow` nicht existiert, verwendet `at` nur die Datei `at.deny`.
Standardmäßig kann jeder `at` verwenden. Wenn du den Zugriff einschränken möchtest, wer ihn verwenden darf, kannst du die Datei `at.allow` nutzen, um die erlaubten Benutzer aufzulisten. Das ist einfacher, als alle Benutzer, die `at` nicht nutzen dürfen, zur Datei `at.deny` hinzuzufügen.
So sieht die Datei `at.deny` aus:
sudo less /etc/at.deny

Die Datei listet Komponenten des Betriebssystems auf, die nicht verwendet werden dürfen. Viele von ihnen werden aus Sicherheitsgründen davon abgehalten, sodass du keine davon aus der Datei entfernen solltest.

Nun bearbeiten wir die Datei `at.allow`. Wir werden Dave und Mary hinzufügen, aber niemand sonst darf `at` nutzen.
Zuerst gibst du Folgendes ein:
sudo gedit /etc/at.allow

Im Editor fügen wir die beiden Namen wie unten gezeigt hinzu und speichern dann die Datei:

Wenn nun jemand anders versucht, `at` zu verwenden, wird er darauf hingewiesen, dass er keine Berechtigung hat. Angenommen, ein Benutzer namens Eric gibt Folgendes ein:
at
Er würde, wie unten gezeigt, abgewiesen werden.

Auch hier ist Eric nicht in der Datei `at.deny` aufgelistet. Sobald du jemanden in die Datei `at.allow` einträgst, wird jedem anderen die Berechtigung zur Verwendung von `at` verweigert.
Ideal für einmalige Aufgaben
Wie du siehst, eignen sich sowohl `at` als auch `batch` ideal für Aufgaben, die du nur einmal ausführen musst. Hier nochmals eine kurze Zusammenfassung:
Wenn du etwas tun musst, was nicht regelmäßig ist, plane es mit `at`.
Wenn du eine Aufgabe nur ausführen möchtest, wenn die Systemauslastung niedrig genug ist, verwende `batch`.
