So laden Sie Apache Kafka herunter und installieren es [Windows and Linux]
Apache Kafka präsentiert sich als ein Nachrichten-Streaming-System, welches in einem verteilten Umfeld verschiedenen Applikationen die Möglichkeit bietet, über Nachrichten zu kommunizieren und Daten auszutauschen.
Es agiert als ein Pub/Sub-System, bei dem produzierende Anwendungen Meldungen veröffentlichen und konsumierende Systeme diese abonnieren.
Durch den Einsatz von Apache Kafka ist es möglich, eine lose gekoppelte Architektur zwischen den datenproduzierenden und -verbrauchenden Einheiten Ihres Systems zu realisieren. Dies vereinfacht sowohl die Entwicklung als auch die Administration des Gesamtsystems. Kafka greift für die Metadatenverwaltung und Synchronisation der verschiedenen Clusterkomponenten auf Zookeeper zurück.
Besondere Merkmale von Apache Kafka
Die Popularität von Apache Kafka beruht unter anderem auf folgenden Eigenschaften:
- Skalierbarkeit durch Cluster und Partitionen
- Hohe Geschwindigkeit mit der Fähigkeit, 2 Millionen Schreibvorgänge pro Sekunde zu bewältigen
- Einhaltung der Reihenfolge, in der Nachrichten gesendet werden
- Zuverlässigkeit durch ein Replikationssystem
- Möglichkeit zur Durchführung von Upgrades ohne Ausfallzeiten
Im Folgenden werden wir einige typische Anwendungsfälle von Kafka näher betrachten.
Typische Anwendungsbereiche von Apache Kafka
Kafka findet häufig Verwendung bei der Verarbeitung großer Datenmengen (Big Data), der Aufzeichnung und Aggregation von Ereignissen (wie z.B. Klicks auf Schaltflächen für Analysen) sowie der zentralen Zusammenführung von Protokollen aus verschiedenen Systembereichen.
Es unterstützt die Kommunikation zwischen unterschiedlichen Anwendungen innerhalb eines Systems und die Echtzeitverarbeitung von Daten, die von IoT-Geräten generiert werden.
Lassen Sie uns nun die detaillierten Schritte zur Installation von Kafka unter Windows und Linux untersuchen.
Kafka-Installation unter Windows
Um Apache Kafka unter Windows zu installieren, muss zunächst geprüft werden, ob Java auf Ihrem Rechner installiert ist. Öffnen Sie die Eingabeaufforderung als Administrator und geben Sie folgenden Befehl ein:
java --version
Bei erfolgreicher Installation von Java wird Ihnen die aktuelle JDK-Versionsnummer angezeigt.
Wenn eine Fehlermeldung angezeigt wird, die besagt, dass der Befehl nicht erkannt wird, ist Java nicht installiert und muss zuerst installiert werden. Für die Installation von Java besuchen Sie bitte Adoptium.net und klicken Sie auf den Download-Button.
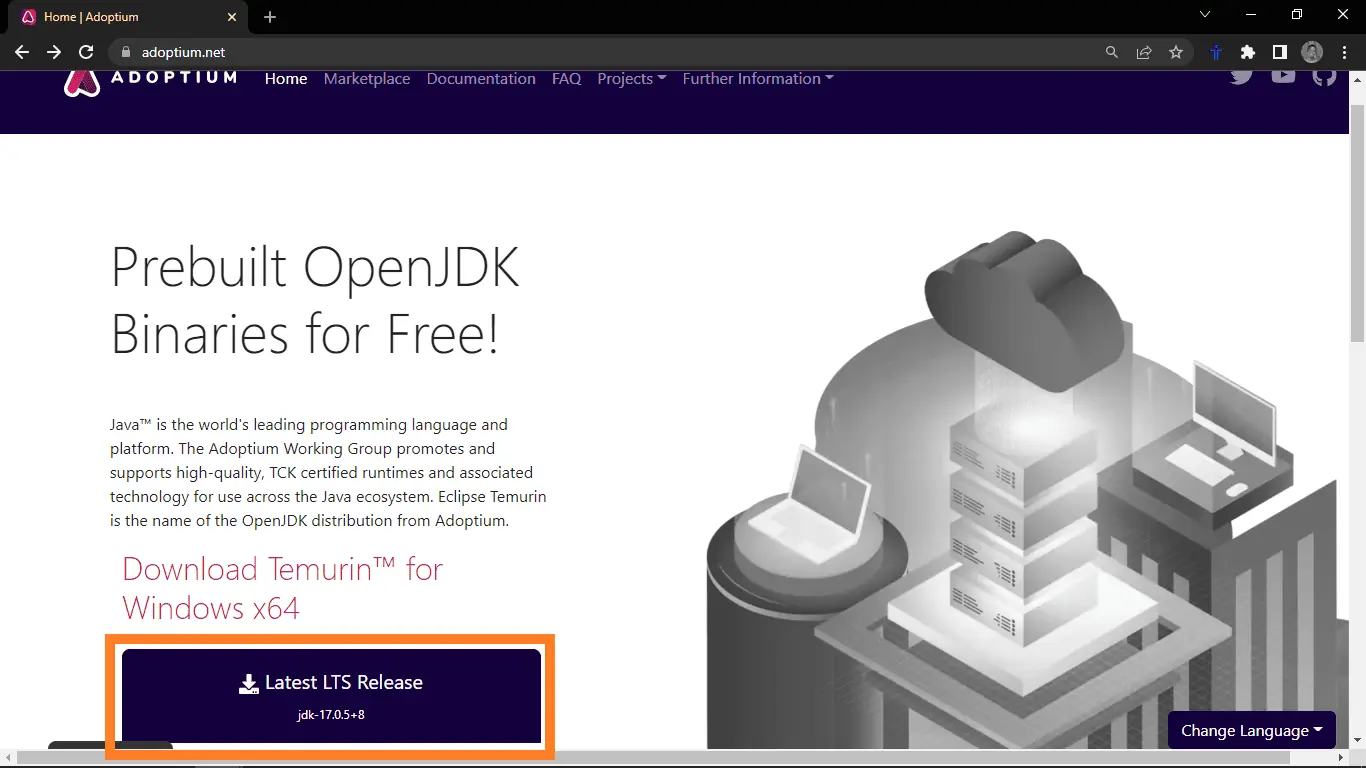
Dadurch wird die Java-Installationsdatei heruntergeladen. Führen Sie nach dem Download das Installationsprogramm aus. Es sollte sich ein Installationsdialog öffnen.
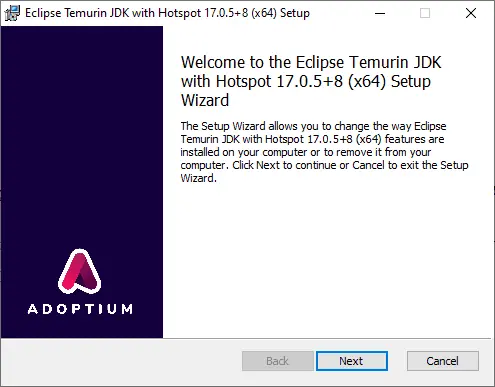
Klicken Sie wiederholt auf "Weiter", um die Standardoptionen beizubehalten. Die Installation sollte danach starten. Um die Installation zu überprüfen, schließen Sie die Eingabeaufforderung, öffnen eine neue Eingabeaufforderung im Administratormodus und geben Sie erneut den folgenden Befehl ein:
java --version
Dieses Mal sollte Ihnen die zuvor installierte JDK-Version angezeigt werden. Nach Abschluss der Installation können wir mit der Kafka-Installation beginnen.
Um Kafka zu installieren, besuchen Sie zuerst die offizielle Kafka-Webseite.
Nach dem Klicken auf den Link werden Sie zur Download-Seite weitergeleitet. Laden Sie dort die aktuellsten verfügbaren Binärdateien herunter.
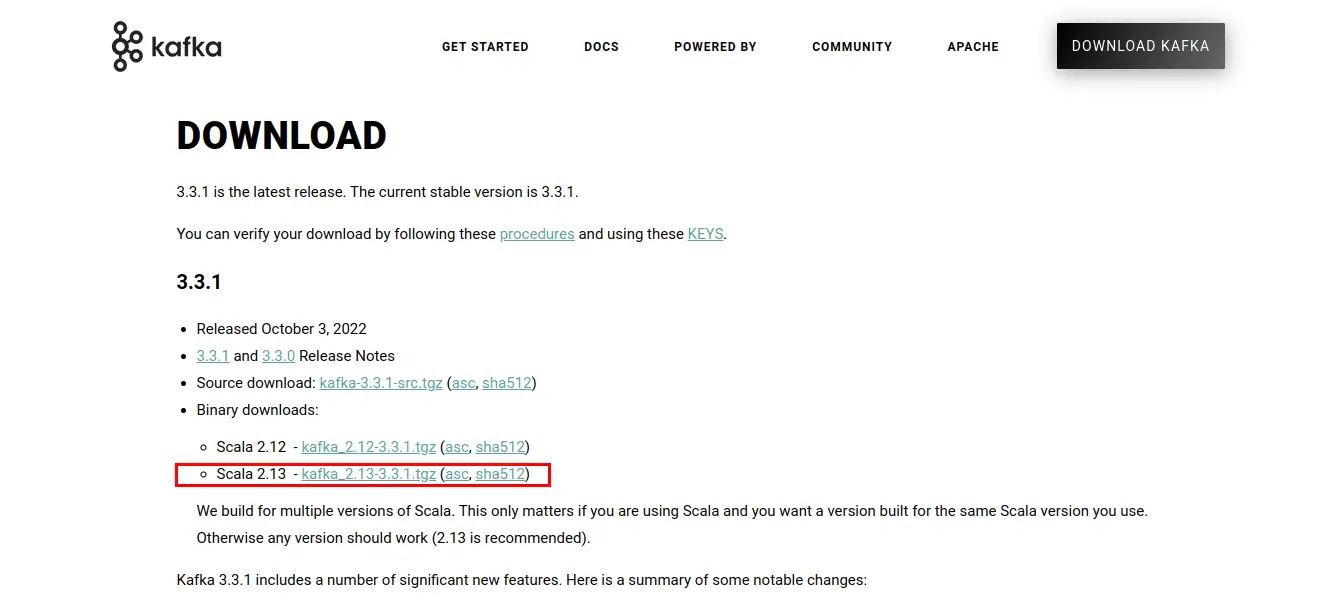
Dies lädt Kafka-Skripte und Binärdateien, verpackt in einer .tgz-Datei, herunter. Nach dem Download müssen Sie die Dateien aus dem .tgz-Archiv entpacken. Für die Extraktion verwende ich WinZip, welches von der WinZip-Webseite bezogen werden kann.
Nach dem Entpacken verschieben Sie das Verzeichnis nach C:, sodass der Dateipfad zu C:kafka wird.
Öffnen Sie danach die Eingabeaufforderung im Administratormodus und starten Sie Zookeeper, indem Sie zuerst in das Kafka-Verzeichnis navigieren. Führen Sie dann die Datei zookeeper-server-start.bat mit zookeeper.properties als Konfigurationsdatei aus.
cd C:kafka bin\windows\zookeeper-server-start.bat config\zookeeper.properties
Nach dem Start von Zookeeper muss die ausführbare wmic-Datei zum System-PATH hinzugefügt werden, damit Kafka sie nutzen kann:
set PATH=C:\Windows\System32\wbem;%PATH%;
Danach starten Sie den Apache Kafka-Server, indem Sie eine weitere Eingabeaufforderungs-Session im Administratormodus öffnen und zum Ordner C:kafka navigieren.
cd C:kafka
Starten Sie Kafka durch Ausführen von:
bin\windows\kafka-server-start.bat config\server.properties
Kafka sollte jetzt laufen. Sie können Servereigenschaften wie den Speicherort für die Protokolle in der Datei server.properties konfigurieren.
Kafka-Installation unter Linux
Stellen Sie zunächst sicher, dass Ihr System aktuell ist, indem Sie alle Pakete aktualisieren:
sudo apt update && sudo apt upgrade
Überprüfen Sie anschließend, ob Java auf Ihrem Rechner installiert ist, indem Sie Folgendes ausführen:
java --version
Wenn Java installiert ist, wird Ihnen die Versionsnummer angezeigt. Falls nicht, können Sie Java mit apt installieren:
sudo apt install default-jdk
Danach können wir Apache Kafka installieren, indem wir die Binärdateien von der offiziellen Webseite herunterladen.
Öffnen Sie Ihr Terminal und navigieren Sie zu dem Ordner, in dem der Download gespeichert wurde. In meinem Fall ist dies der Download-Ordner.
cd Downloads
Sobald Sie sich im Download-Ordner befinden, entpacken Sie die heruntergeladenen Dateien mit tar:
tar -xvzf kafka_2.13-3.3.1.tgz
Navigieren Sie in den extrahierten Ordner:
cd kafka_2.13-3.3.1
Lassen Sie sich die Verzeichnisse und Dateien anzeigen.
Sobald Sie sich im Ordner befinden, starten Sie einen Zookeeper-Server durch Ausführen des Skripts zookeeper-server-start.sh, welches sich im Unterordner bin des extrahierten Verzeichnisses befindet.
Das Skript erfordert eine Zookeeper-Konfigurationsdatei. Die Standarddatei heißt zookeeper.properties und befindet sich im Unterverzeichnis config.
Um den Server zu starten, verwenden Sie folgenden Befehl:
bin/zookeeper-server-start.sh config/zookeeper.properties
Nach dem Start von Zookeeper können wir den Apache Kafka-Server starten. Das Skript kafka-server-start.sh befindet sich ebenfalls im Verzeichnis bin. Der Befehl erwartet ebenfalls eine Konfigurationsdatei. Die Standardeinstellung ist server.properties, welche sich im Konfigurationsverzeichnis befindet.
bin/kafka-server-start.sh config/server.properties
Dies sollte Apache Kafka starten. Im Verzeichnis bin finden Sie viele Skripte, mit denen Sie beispielsweise Themen erstellen, Produzenten und Konsumenten verwalten können. Sie können Servereigenschaften auch in der Datei server.properties anpassen.
Abschließende Bemerkungen
In dieser Anleitung wurde die Installation von Java und Apache Kafka erläutert. Neben der manuellen Installation und Verwaltung von Kafka-Clustern stehen Ihnen auch Managed Services wie Amazon Web Services und Confluent zur Verfügung.
Als nächsten Schritt können Sie sich mit der Datenverarbeitung mit Kafka und Spark beschäftigen.
