So kratzen Sie eine Liste von Themen aus einem Subreddit mit Bash
Reddit stellt für jedes Subreddit JSON-Feeds bereit. Dies ermöglicht es, mithilfe eines Bash-Skripts eine Liste von Beiträgen aus einem beliebigen Subreddit herunterzuladen und zu analysieren. Dies ist nur ein Beispiel für die vielfältigen Möglichkeiten, die die JSON-Feeds von Reddit bieten.
Installation von Curl und JQ
Um den JSON-Feed von Reddit abzurufen, nutzen wir das Kommandozeilentool curl. Für die Analyse der JSON-Daten und die Extraktion der gewünschten Informationen verwenden wir jq. Diese beiden Abhängigkeiten können mit apt-get auf Ubuntu und anderen Debian-basierten Linux-Distributionen installiert werden. Nutzer anderer Linux-Distributionen verwenden bitte das entsprechende Paketverwaltungstool ihrer Distribution.
sudo apt-get install curl jq
Abrufen von JSON-Daten von Reddit
Lassen Sie uns untersuchen, wie der Datenfeed aufgebaut ist. Mit curl rufen wir die neuesten Beiträge des Subreddits /r/MildlyInteresting ab:
curl -s -A "reddit scraper example" https://www.reddit.com/r/MildlyInteresting.json
Die verwendeten Optionen vor der URL sind wie folgt: `-s` bewirkt, dass curl im Silent-Modus arbeitet, sodass keine Ausgabe im Terminal erscheint außer den Daten von Reddits Servern. Die Option `-A "reddit scraper example"` setzt einen benutzerdefinierten User-Agent-String, der Reddit hilft, den zugreifenden Dienst zu identifizieren. Die Reddit-API verwendet User-Agent-Strings, um Ratenlimits festzulegen. Mit einem benutzerdefinierten Wert stellen wir sicher, dass unsere Anfragen von anderen getrennt behandelt werden und die Wahrscheinlichkeit von HTTP 429 Fehlern (Rate Limit Exceeded) sinkt.
Die Ausgabe, die im Terminalfenster erscheint, wird in etwa so aussehen:
Die Ausgabedaten enthalten viele Felder, für uns sind jedoch nur Titel, Permalink und URL relevant. Eine umfassende Liste aller Typen und ihrer Felder findet man in der API-Dokumentation von Reddit: https://github.com/reddit-archive/reddit/wiki/JSON
Extrahieren von Daten aus der JSON-Ausgabe
Unser Ziel ist es, die Titel, Permalinks und URLs aus den Daten zu extrahieren und in einer tabulatorgetrennten Datei zu speichern. Wir könnten Textverarbeitungstools wie sed und grep verwenden, jedoch ist jq das ideale Werkzeug, da es JSON-Datenstrukturen versteht. Zu Beginn nutzen wir jq, um die Ausgabe übersichtlich formatiert und farblich hervorgehoben darzustellen. Wir verwenden denselben curl-Befehl wie zuvor, leiten die Ausgabe jedoch über jq und weisen dieses an, die JSON-Daten zu analysieren und auszugeben.
curl -s -A "reddit scraper example" https://www.reddit.com/r/MildlyInteresting.json | jq .
Der Punkt nach dem Befehl bewirkt, dass die Eingabe analysiert und unverändert ausgegeben wird. Die Ausgabe wird übersichtlich formatiert und farblich hervorgehoben:
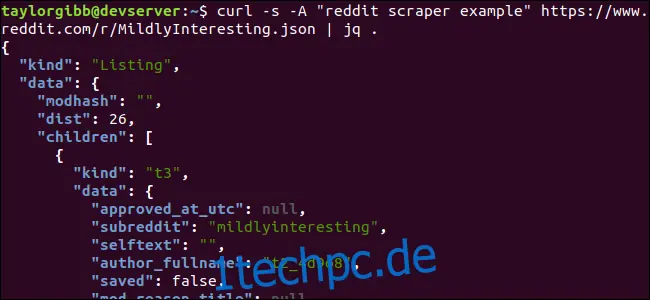
Betrachten wir die Struktur der JSON-Daten genauer. Das Ergebnis ist ein Objekt, das zwei Eigenschaften enthält: "kind" und "data". Die Eigenschaft "data" enthält die Eigenschaft "children", welche ein Array von Beiträgen des Subreddits ist.
Jedes Element des Arrays ist wiederum ein Objekt, das die Felder "kind" und "data" enthält. Die gesuchten Eigenschaften befinden sich im Datenobjekt. jq benötigt einen Ausdruck, der auf die Eingabedaten angewendet wird, um die gewünschte Ausgabe zu erzeugen. Der Ausdruck muss die Hierarchie und die Arrayzugehörigkeit des Inhalts beschreiben und festlegen, wie die Daten transformiert werden sollen. Wir führen den Befehl erneut mit dem passenden Ausdruck aus:
curl -s -A "reddit scraper example" https://www.reddit.com/r/MildlyInteresting.json | jq '.data.children | .[] | .data.title, .data.url, .data.permalink'
Die Ausgabe zeigt Titel, URL und Permalink jeweils in einer eigenen Zeile:
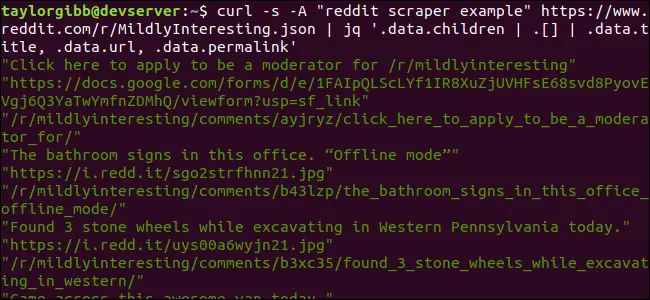
Wir analysieren den jq-Befehl genauer:
jq '.data.children | .[] | .data.title, .data.url, .data.permalink'
Der Befehl besteht aus drei Ausdrücken, die durch zwei Pipe-Symbole getrennt sind. Die Ergebnisse jedes Ausdrucks werden zur Weiterverarbeitung an den nächsten Ausdruck weitergegeben. Der erste Ausdruck filtert alles außer dem Array der Reddit-Einträge heraus. Diese Ausgabe wird an den zweiten Ausdruck geleitet und in ein Array umgewandelt. Der dritte Ausdruck wirkt auf jedes Element des Arrays und extrahiert die drei genannten Eigenschaften. Weitere Informationen zu jq und seiner Ausdruckssyntax finden Sie in jqs offizieller Anleitung.
Zusammenfassung in einem Skript
Fassen wir den API-Aufruf und die JSON-Nachbearbeitung in einem Skript zusammen, das eine Datei mit den gewünschten Beiträgen erstellt. Das Skript soll es ermöglichen, Beiträge von jedem beliebigen Subreddit abzurufen, nicht nur von /r/MildlyInteresting.
Erstellen Sie eine Datei namens "scrape-reddit.sh" und fügen Sie den folgenden Inhalt ein:
#!/bin/bash
if [ -z "$1" ]
then
echo "Bitte gib ein Subreddit an"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}\t${URL}\t${PERMALINK}" | tr --delete "\"" >> ${OUTPUT_FILE}
done
Das Skript prüft zuerst, ob ein Subreddit-Name als Argument übergeben wurde. Andernfalls wird es mit einer Fehlermeldung und einem Rückgabewert ungleich null beendet.
Als nächstes wird das erste Argument als Subreddit-Name gespeichert und ein Dateiname mit Datumsstempel für die Ausgabe erstellt.
Der eigentliche Ablauf beginnt mit dem Aufruf von curl, unter Verwendung eines benutzerdefinierten Headers und der URL des Subreddits, welches ausgelesen werden soll. Die Ausgabe wird an jq geleitet, wo sie verarbeitet und auf die Felder Titel, URL und Permalink reduziert wird. Diese Zeilen werden einzeln gelesen und in Variablen gespeichert, alles innerhalb einer while-Schleife, die solange läuft, bis keine Zeilen mehr zu lesen sind. Die letzte Zeile des while-Blocks gibt die drei Felder tabulatorgetrennt wieder und leitet sie an den tr-Befehl weiter, um die doppelten Anführungszeichen zu entfernen. Die Ausgabe wird abschließend in eine Datei umgeleitet.
Bevor das Skript ausgeführt werden kann, müssen Ausführungsrechte gewährt werden. Mit dem Befehl chmod kann dies erledigt werden:
chmod u+x scrape-reddit.sh
Führen Sie das Skript nun mit einem Subreddit-Namen aus:
./scrape-reddit.sh MildlyInteresting
Eine Ausgabedatei wird im gleichen Verzeichnis erstellt und sieht in etwa so aus:
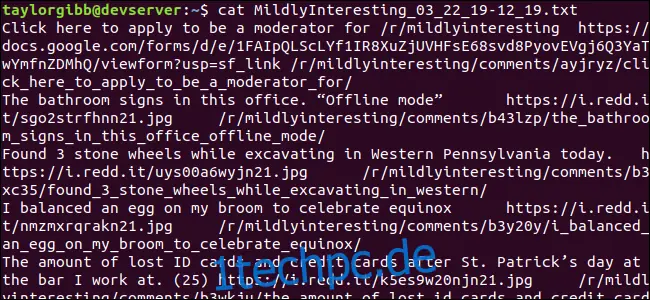
Jede Zeile enthält die drei gesuchten Felder, getrennt durch Tabulatorzeichen.
Weiterführende Ideen
Reddit bietet eine Fülle interessanter Inhalte und Medien, auf die man über die JSON-API zugreifen kann. Nun, da du eine Möglichkeit hast, auf diese Daten zuzugreifen und zu verarbeiten, kannst du beispielsweise folgende Aufgaben automatisieren:
Abrufen der aktuellen Schlagzeilen von /r/WorldNews und Senden einer Benachrichtigung auf den Desktop mit notify-send.
Integration der besten Witze von /r/DadJokes in die Nachricht des Tages des Systems.
Abrufen des besten Bildes des Tages von /r/aww und Verwendung als Desktop-Hintergrund.
All dies ist mit den bereitgestellten Daten und den Werkzeugen, die auf dem System vorhanden sind, möglich. Viel Spaß beim Experimentieren!