Modellbeziehungen in Laravel Eloquent verstehen
Eloquent-Modellbeziehungen in Laravel: Ein umfassender Leitfaden
Das Fundament von Laravel Eloquent bilden die Beziehungen zwischen den Modellen. Wenn Ihnen diese schwerfallen oder Sie eine einfach verständliche, umfassende Anleitung suchen, sind Sie hier genau richtig!
Es ist für Autoren von Programmierartikeln ein Leichtes, die Autorität und das Prestige der Plattform zu nutzen. Doch ich möchte ehrlich sein: Ich hatte erhebliche Schwierigkeiten beim Erlernen von Laravel, nicht zuletzt, weil es mein erstes Full-Stack-Framework war. Ich habe es in meiner Freizeit aus Neugier erkundet. Ich habe es versucht, bin an einen Punkt gelangt, an dem ich verwirrt war, habe aufgegeben und schließlich alles wieder vergessen. Ich schätze, das ist mir 5-6 Mal passiert, bevor es bei mir "Klick" machte – die Dokumentation war dabei leider keine große Hilfe.
Was mir jedoch weiterhin Probleme bereitete, war Eloquent, oder genauer gesagt, die Beziehungen zwischen den Modellen (denn Eloquent selbst ist ein sehr umfangreiches Thema). Die Beispiele in Artikeln und Blogbeiträgen sind meist sehr einfach gestrickt, während echte Projekte wesentlich komplexer sind. Die offizielle Dokumentation verwendet leider die gleichen (oder ähnliche) Beispiele. Selbst wenn ich einen nützlichen Artikel oder eine Ressource fand, waren die Erklärungen oft so schlecht oder unvollständig, dass sie mir keine wirkliche Hilfe waren.
(Nebenbei bemerkt, ich wurde schon einmal dafür angegriffen, dass ich die offizielle Dokumentation kritisiert habe. Wenn Sie ähnliche Gedanken haben, ist hier meine Standardantwort: Schauen Sie sich die Dokumentation von Django an, und dann können wir gerne weiterreden.)
Mit der Zeit hat sich das Puzzle jedoch zusammengefügt und alles hat einen Sinn ergeben. Endlich konnte ich Projekte richtig modellieren und die Modelle selbstsicher verwenden. Eines Tages stieß ich auf einige nützliche Tricks im Umgang mit Collections, die die Arbeit noch angenehmer machen. In diesem Artikel möchte ich Ihnen alles von den Grundlagen bis hin zu den vielfältigen Anwendungsfällen zeigen, die Ihnen in echten Projekten begegnen werden.
Warum sind Eloquent-Modellbeziehungen so schwierig?
Es ist bedauerlich, dass ich immer wieder auf Laravel-Entwickler treffe, die Schwierigkeiten haben, die Modelle richtig zu verstehen.
Aber warum ist das so?
Obwohl es heutzutage eine riesige Menge an Kursen, Artikeln und Videos über Laravel gibt, ist das Gesamtverständnis oft mangelhaft. Ich denke, das ist ein wichtiger Punkt, über den es sich lohnt nachzudenken.
Wenn Sie mich fragen, würde ich sagen, dass Eloquent-Modellbeziehungen an sich nicht schwierig sind. Zumindest wenn man "schwierig" im eigentlichen Sinne des Wortes betrachtet. Das Durchführen von Live-Schema-Migrationen ist schwierig; das Schreiben einer neuen Templating-Engine ist schwierig; zum Kern von Laravel beizutragen, ist schwierig. Im Vergleich dazu ist das Erlernen und Verwenden eines ORM... na ja, das kann doch nicht schwer sein! 🤭🤭
Tatsächlich ist das Problem, dass PHP-Entwickler, die Laravel lernen, Eloquent oft als schwierig empfinden. Meiner Meinung nach gibt es dafür verschiedene Gründe (Achtung: kontroverse Meinung!):
- Vor Laravel war CodeIgniter für die meisten PHP-Entwickler der Einstieg in ein Framework (es ist übrigens immer noch aktiv, auch wenn es Laravel/CakePHP-ähnlicher geworden ist). In der alten CodeIgniter-Community (sofern es eine gab) war es "Best Practice", SQL-Abfragen direkt dort zu platzieren, wo sie benötigt wurden. Und obwohl wir heute ein überarbeitetes CodeIgniter haben, sind diese alten Gewohnheiten geblieben. Daher ist für PHP-Entwickler, die Laravel lernen, die Idee eines ORM etwas völlig Neues.
- Abgesehen von dem sehr kleinen Anteil an PHP-Entwicklern, die Frameworks wie Yii oder CakePHP verwenden, sind die meisten anderen es gewohnt, mit reinem PHP oder in einer Umgebung wie WordPress zu arbeiten. Auch hier gibt es keine Denkweise, die auf OOP basiert. Frameworks, Service-Container, Entwurfsmuster oder ORMs sind fremde Konzepte.
- In der PHP-Welt gibt es nur wenig Verständnis für kontinuierliches Lernen. Der durchschnittliche Entwickler ist zufrieden mit Single-Server-Setups, relationalen Datenbanken und dem Schreiben von Abfragen als Strings. Asynchrone Programmierung, Web-Sockets, HTTP 2/3, Linux (vergessen Sie Docker), Unit-Tests oder Domain-Driven Design – das sind alles Fremdwörter für die meisten PHP-Entwickler. Die Folge ist, dass das Lernen von etwas Neuem und Herausforderndem, das so lange dauert, bis es angenehm wird, oft nicht stattfindet, wenn sie auf Eloquent treffen.
- Das allgemeine Verständnis von Datenbanken und Modellierung ist ebenfalls mangelhaft. Da das Datenbankdesign direkt mit Eloquent-Modellen zusammenhängt, ist die Hürde höher.
Ich möchte nicht hart sein oder pauschalisieren – es gibt auch viele exzellente PHP-Entwickler, aber ihr Gesamtanteil ist sehr gering.
Wenn Sie das hier lesen, bedeutet das, dass Sie all diese Hürden überwunden haben, auf Laravel gestoßen sind und sich mit Eloquent auseinandergesetzt haben.
Herzlichen Glückwunsch! 👏
Sie sind fast am Ziel. Alle Bausteine sind vorhanden, und wir müssen sie nur in der richtigen Reihenfolge und im Detail durchgehen. Anders ausgedrückt, wir beginnen auf Datenbankebene.
Datenbankmodelle: Beziehungen und Kardinalität
Vereinfachen wir die Dinge, indem wir annehmen, dass wir uns in diesem Artikel nur mit relationalen Datenbanken beschäftigen. Ein Grund dafür ist, dass ORMs ursprünglich für relationale Datenbanken entwickelt wurden. Der andere Grund ist, dass RDBMS immer noch sehr beliebt sind.
Datenmodell
Beginnen wir damit, Datenmodelle besser zu verstehen. Das Konzept eines Modells (genauer gesagt eines Datenmodells) stammt aus dem Bereich der Datenbanken. Ohne Datenbank gibt es keine Daten und somit auch kein Datenmodell. Und was ist ein Datenmodell? Es ist einfach die Art und Weise, wie Sie Ihre Daten speichern und strukturieren. In einem E-Commerce-Shop könnten Sie beispielsweise alles in einer riesigen Tabelle speichern (eine SCHRECKLICHE Vorgehensweise, aber leider nicht unüblich in der PHP-Welt). Das wäre Ihr Datenmodell. Sie könnten die Daten auch in 20 Haupt- und 16 Verbindungstabellen aufteilen. Das wäre ebenfalls ein Datenmodell.
Beachten Sie, dass die Strukturierung der Daten in der Datenbank nicht zu 100 % mit der Struktur im ORM des Frameworks übereinstimmen muss. Dennoch sollte man versuchen, die Dinge so ähnlich wie möglich zu gestalten, um keine zusätzlichen Hürden bei der Entwicklung zu schaffen.
Kardinalität
Lassen Sie uns auch diesen Begriff schnell aus dem Weg räumen: Kardinalität. Es bezieht sich einfach auf das "Zählen", grob gesagt. Also 1, 2, 3... können alle die Kardinalität von etwas sein. Ende der Geschichte. Gehen wir weiter!
Beziehungen
Immer wenn wir Daten in einem System speichern, gibt es Möglichkeiten, Datenpunkte miteinander in Beziehung zu setzen. Ich weiß, das klingt abstrakt und langweilig, aber halten Sie kurz durch. Die Art und Weise, wie verschiedene Datenelemente miteinander verbunden sind, wird als Beziehungen bezeichnet. Sehen wir uns zuerst einige Beispiele außerhalb von Datenbanken an, um sicherzustellen, dass wir das Konzept vollständig verstehen.
- Wenn wir alles in einem Array speichern, könnte eine Beziehung sein: Das nächste Datenelement befindet sich an einem Index, der um 1 höher ist als der vorherige Index.
- Wenn wir Daten in einem Binärbaum speichern, könnte eine Beziehung sein: Der Unterbaum auf der linken Seite hat immer kleinere Werte als der übergeordnete Knoten (wenn wir uns entscheiden, den Baum auf diese Weise zu pflegen).
- Wenn wir Daten als ein Array von Arrays derselben Länge speichern, können wir eine Matrix simulieren. Ihre Eigenschaften werden dann zu Beziehungen für unsere Daten.
Wir sehen also, dass der Begriff "Beziehung" im Zusammenhang mit Daten keine feste Bedeutung hat. Wenn zwei Personen die gleichen Daten betrachten, könnten sie sogar zwei sehr unterschiedliche Datenbeziehungen identifizieren (Hallo, Statistik!). Beide könnten gültig sein.
Relationale Datenbanken
Auf der Grundlage all der Begriffe, die wir bisher besprochen haben, können wir endlich über etwas sprechen, das eine direkte Verbindung zu Modellen in einem Web-Framework (Laravel) hat – relationale Datenbanken. Die meisten von uns verwenden hauptsächlich Datenbanken wie MySQL, MariaDB, PostgreSQL, MSSQL, SQL Server oder SQLite. Wir wissen vielleicht auch grob, dass diese als RDBMS bezeichnet werden, aber die meisten von uns haben vergessen, was das eigentlich bedeutet und warum es wichtig ist.
Das "R" in RDBMS steht natürlich für relational. Dies ist kein willkürlich gewählter Begriff. Er betont, dass diese Datenbanksysteme so konzipiert sind, dass sie effizient mit Beziehungen zwischen den gespeicherten Daten arbeiten können. Tatsächlich hat "Beziehung" hier eine strenge mathematische Bedeutung. Obwohl sich kein Entwickler damit befassen muss, ist es hilfreich zu wissen, dass es ein strenges mathematisches Fundament für diese Art von Datenbanken gibt.
Weitere Informationen zu SQL und NoSQL finden Sie in diesen Ressourcen.
Okay, wir wissen also aus Erfahrung, dass Daten in RDBMS als Tabellen gespeichert werden. Wo sind dann die Beziehungen?
Arten von Beziehungen in RDBMS
Dies ist vielleicht der wichtigste Teil des gesamten Themas Laravel und Modellbeziehungen. Wenn Sie dies nicht verstehen, wird Eloquent nie Sinn ergeben. Nehmen Sie sich also bitte die nächsten Minuten Zeit, um aufzupassen (es ist gar nicht so schwierig).
Ein RDBMS ermöglicht es uns, Beziehungen zwischen Daten herzustellen – auf Datenbankebene. Das bedeutet, dass diese Beziehungen nicht unpraktisch, imaginär oder subjektiv sind, sondern von verschiedenen Personen mit dem gleichen Ergebnis erstellt oder abgeleitet werden können.
Gleichzeitig gibt es bestimmte Funktionen und Werkzeuge innerhalb eines RDBMS, mit denen wir diese Beziehungen erstellen und durchsetzen können, wie z. B.:
- Primärschlüssel
- Fremdschlüssel
- Einschränkungen
Ich möchte diesen Artikel nicht zu einem Datenbankkurs machen, daher gehe ich davon aus, dass Sie mit diesen Konzepten vertraut sind. Wenn das nicht der Fall ist oder Sie sich unsicher fühlen, empfehle ich dieses hilfreiche Video (Sie können sich gerne die gesamte Serie ansehen):

Diese Beziehungen im RDBMS-Stil sind übrigens auch die häufigsten, die in realen Anwendungen vorkommen (nicht immer, da ein soziales Netzwerk am besten als Graph und nicht als Sammlung von Tabellen modelliert wird). Betrachten wir sie also nacheinander und versuchen wir auch zu verstehen, wo sie nützlich sein könnten.
Eins-zu-eins-Beziehung
In fast jeder Webanwendung gibt es Benutzerkonten. Außerdem gilt im Allgemeinen Folgendes für Benutzer und Konten:
- Ein Benutzer kann nur ein Konto haben.
- Ein Konto kann nur einem Benutzer gehören.
Ja, man könnte argumentieren, dass sich eine Person mit einer anderen E-Mail-Adresse anmelden und somit zwei Konten erstellen kann, aber aus Sicht der Webanwendung sind das zwei verschiedene Personen mit zwei verschiedenen Konten. Die Anwendung zeigt beispielsweise nicht die Daten eines Kontos in einem anderen an.
Was all dieses Haarspalterei bedeutet: Wenn Sie in Ihrer Anwendung eine Situation wie diese haben und eine relationale Datenbank verwenden, müssen Sie sie als Eins-zu-eins-Beziehung konzipieren. Beachten Sie, dass Sie niemand künstlich dazu zwingt – es gibt eine eindeutige Situation in der Geschäftswelt, und Sie verwenden zufällig eine relationale Datenbank... Nur wenn diese beiden Bedingungen erfüllt sind, haben Sie eine Eins-zu-eins-Beziehung.
Für dieses Beispiel (Benutzer und Konten) können wir diese Beziehung beim Erstellen des Schemas wie folgt implementieren:
CREATE TABLE users(
id INT NOT NULL AUTO_INCREMENT,
email VARCHAR(100) NOT NULL,
password VARCHAR(100) NOT NULL,
PRIMARY KEY(id)
);
CREATE TABLE accounts(
id INT NOT NULL AUTO_INCREMENT,
role VARCHAR(50) NOT NULL,
PRIMARY KEY(id),
FOREIGN KEY(id) REFERENCES users(id)
);
Haben Sie den Trick bemerkt? Es ist eher ungewöhnlich beim Erstellen von Apps im Allgemeinen, aber in der Kontentabelle haben wir das Feld "id" sowohl als Primärschlüssel als auch als Fremdschlüssel festgelegt! Die Fremdschlüsseleigenschaft verbindet sie mit der Benutzertabelle (natürlich 🙄), während die Primärschlüsseleigenschaft die Spalte "id" eindeutig macht – eine echte Eins-zu-eins-Beziehung!
Zugegeben, die Einhaltung dieser Beziehung ist nicht garantiert. Ich könnte beispielsweise 200 neue Benutzer hinzufügen, ohne einen einzigen Eintrag in die Kontentabelle einzufügen. Wenn ich das tue, habe ich am Ende eine Eins-zu-null-Beziehung! 🤭🤭 Aber innerhalb der Grenzen der reinen Struktur ist dies das Beste, was wir tun können. Wenn wir verhindern wollen, dass Benutzer ohne Konten hinzugefügt werden, müssen wir uns von einer Programmierlogik helfen lassen, entweder in Form von Datenbankauslösern oder von Laravel erzwungenen Validierungen.

Wenn Sie sich jetzt gestresst fühlen, habe ich einige sehr gute Ratschläge:
- Machen Sie langsam. So langsam wie nötig. Anstatt zu versuchen, diesen Artikel und die 15 anderen Artikel, die Sie sich heute als Lesezeichen gesetzt haben, fertigzustellen, bleiben Sie bei diesem. Lassen Sie es 3, 4 oder 5 Tage dauern, wenn es das braucht – Ihr Ziel sollte es sein, Eloquent-Modellbeziehungen für immer von Ihrer Liste zu streichen. Sie sind schon früher von Artikel zu Artikel gesprungen, haben mehrere hundert Stunden verschwendet, und es hat trotzdem nicht geholfen. Also machen Sie es diesmal anders. 😇
- Obwohl es in diesem Artikel um Laravel Eloquent geht, kommt das alles erst viel später. Die Grundlage von allem ist das Datenbankschema, also sollten wir uns zuerst darauf konzentrieren, das richtig zu machen. Wenn Sie nicht rein auf Datenbankebene arbeiten können (vorausgesetzt, es gäbe keine Frameworks auf der Welt), werden Modelle und Beziehungen nie wirklich Sinn machen. Vergessen Sie also Laravel vorerst. Vollständig. Wir sprechen vorerst nur über Datenbankdesign und setzen es um. Ja, ich werde hin und wieder auf Laravel Bezug nehmen, aber Ihre Aufgabe ist es, diese vollständig zu ignorieren, wenn sie die Dinge für Sie komplizierter machen.
- Lesen Sie später mehr über Datenbanken und deren Möglichkeiten. Indizes, Leistung, Trigger, zugrunde liegende Datenstrukturen und deren Verhalten, Caching, Beziehungen in MongoDB... alle Randthemen, die Sie behandeln können, werden Ihnen als Ingenieur helfen. Denken Sie daran, dass Frameworks nur Geisterhüllen sind; die eigentliche Funktionalität einer Plattform ergibt sich aus den zugrunde liegenden Datenbanken.
Eins-zu-viele-Beziehung
Ich bin mir nicht sicher, ob Sie das erkannt haben, aber dies ist die Art von Beziehung, die wir alle intuitiv in unserer täglichen Arbeit aufbauen. Wenn wir beispielsweise eine Auftragstabelle erstellen (ein hypothetisches Beispiel), um einen Fremdschlüssel für die Benutzertabelle zu speichern, erstellen wir eine Eins-zu-viele-Beziehung zwischen Benutzern und Bestellungen. Warum ist das so? Betrachten Sie es noch einmal aus der Perspektive, wer wie viele haben darf: Ein Benutzer darf mehr als eine Bestellung haben, und so funktioniert der gesamte E-Commerce. Und von der anderen Seite gesehen besagt die Beziehung, dass eine Bestellung nur einem Benutzer gehören kann, was auch sehr sinnvoll ist.
In der Datenmodellierung, in RDBMS-Büchern und in der Systemdokumentation wird diese Situation schematisch wie folgt dargestellt:

Beachten Sie die drei Linien, die eine Art Dreizack bilden? Das ist das Symbol für "viele", und dieses Diagramm besagt, dass ein Benutzer viele Bestellungen haben kann.
Diese "viele" und "eins"-Zählungen, auf die wir immer wieder stoßen, werden übrigens als Kardinalität einer Beziehung bezeichnet (erinnern Sie sich an dieses Wort aus einem früheren Abschnitt?). Auch hier ist der Begriff für diesen Artikel nicht so wichtig, aber es ist hilfreich, das Konzept zu kennen, falls es in Interviews oder beim Weiterlesen auftaucht.
Einfach, oder? Und in Bezug auf das eigentliche SQL ist das Erstellen dieser Beziehung ebenfalls einfach. Es ist sogar viel einfacher als bei einer Eins-zu-eins-Beziehung!
CREATE TABLE users(
id INT NOT NULL AUTO_INCREMENT,
email VARCHAR(100) NOT NULL,
password VARCHAR(100) NOT NULL,
PRIMARY KEY(id)
);
CREATE TABLE orders(
id INT NOT NULL AUTO_INCREMENT,
user_id INT NOT NULL,
description VARCHAR(50) NOT NULL,
PRIMARY KEY(id),
FOREIGN KEY(user_id) REFERENCES users(id)
);
Die Auftragstabelle speichert Benutzer-IDs für jeden Auftrag. Da es keine Einschränkung gibt, dass die Benutzer-IDs in der Auftragstabelle eindeutig sein müssen, bedeutet das, dass wir eine einzelne ID viele Male wiederholen können. Das ist es, was die Eins-zu-viele-Beziehung schafft, und keine obskure Magie, die darunter verborgen ist. Die Benutzer-IDs werden gewissermaßen "dumm" in der Orders-Tabelle gespeichert, und SQL hat kein Konzept von Eins-zu-vielen, Eins-zu-eins usw. Aber sobald wir Daten auf diese Weise speichern, können wir uns eine Eins-zu-viele-Beziehung vorstellen.

Ich hoffe, das macht jetzt Sinn. Oder zumindest mehr Sinn als zuvor. 😅 Denken Sie daran, dass dies wie alles andere nur eine Frage der Übung ist, und wenn Sie das 4-5 Mal in realen Situationen gemacht haben, werden Sie nicht einmal mehr darüber nachdenken.
Viele-zu-viele-Beziehungen
Die nächste Art von Beziehung, die in der Praxis auftritt, ist die sogenannte Viele-zu-viele-Beziehung. Bevor wir uns Gedanken über Frameworks machen oder überhaupt in Datenbanken eintauchen, denken wir wieder an ein Analogon aus der realen Welt: Bücher und Autoren. Denken Sie an Ihren Lieblingsautor; er hat mehr als ein Buch geschrieben, richtig? Gleichzeitig ist es ziemlich üblich, dass mehrere Autoren an einem Buch zusammenarbeiten (zumindest im Sachbuchgenre). Ein Autor kann also viele Bücher schreiben, und viele Autoren können ein Buch schreiben. Zwischen den beiden Entitäten (Buch und Autor) ergibt sich daraus eine Viele-zu-viele-Beziehung.
Da Sie wahrscheinlich keine reale App entwickeln, die Bibliotheken oder Bücher und Autoren umfasst, denken wir uns ein paar weitere Beispiele aus. In einer B2B-Umgebung bestellt ein Hersteller Artikel bei einem Lieferanten und erhält dafür eine Rechnung. Die Rechnung enthält mehrere Positionen, von denen jede die gelieferte Menge und den gelieferten Artikel auflistet; z. B. 5-Zoll-Rohrstücke x 200 usw. In dieser Situation haben Artikel und Rechnungen eine Viele-zu-viele-Beziehung (überlegen Sie es sich und überzeugen Sie sich selbst). In einem Flottenmanagementsystem haben Fahrzeuge und Fahrer eine ähnliche Beziehung. Auf einer E-Commerce-Website können Benutzer und Produkte eine Viele-zu-viele-Beziehung haben, wenn wir Funktionen wie Favoriten oder Wunschlisten berücksichtigen.
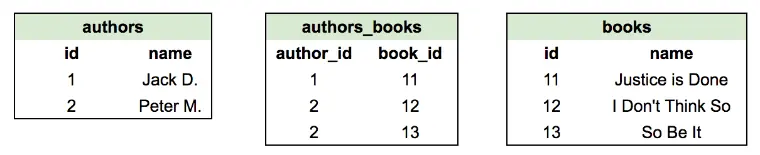
Genug geredet, wie erstellen wir diese Viele-zu-viele-Beziehung in SQL? Basierend auf unserem Wissen über die Funktionsweise der Eins-zu-viele-Beziehung könnte es verlockend sein zu glauben, wir sollten Fremdschlüssel für die andere Tabelle in beiden Tabellen speichern. Wir stoßen jedoch auf große Probleme, wenn wir das versuchen. Sehen Sie sich dieses Beispiel an, in dem Bücher von Autoren eine Viele-zu-viele-Beziehung haben sollen:

Auf den ersten Blick scheint alles in Ordnung zu sein – Bücher sind den Autoren in einer Many-to-Many-Manier zugeordnet. Aber sehen Sie sich die Daten der Autorentabelle genauer an: Die Buch-IDs 12 und 13 wurden beide von Peter M. (Autoren-ID 2) geschrieben, daher bleibt uns keine andere Wahl, als die Einträge zu wiederholen. Die Tabelle "authors" hat jetzt nicht nur Probleme mit der Datenintegrität (richtige Normalisierung und all das), sondern die Werte in der Spalte "id" werden wiederholt. Das bedeutet, dass es in unserem gewählten Design keine Primärschlüsselspalte geben kann (da Primärschlüssel keine doppelten Werte haben können), und alles bricht zusammen.
Natürlich brauchen wir einen neuen Ansatz dafür, und zum Glück wurde dieses Problem bereits gelöst. Da das Speichern von Fremdschlüsseln direkt in beiden Tabellen zu Problemen führt, besteht der richtige Weg, um viele-zu-viele-Beziehungen in RDBMS zu erstellen, darin, eine sogenannte "Verbindungstabelle" zu erstellen. Die Idee ist, die beiden ursprünglichen Tabellen unberührt zu lassen und eine dritte Tabelle zu erstellen, um das Many-to-Many-Mapping zu demonstrieren.
Wiederholen wir das gescheiterte Beispiel und fügen eine Verbindungstabelle hinzu:
Beachten Sie, dass es drastische Änderungen gegeben hat:
- Die Anzahl der Spalten in der Autorentabelle wurde reduziert.
- Die Anzahl der Spalten in der Büchertabelle wurde reduziert.
- Die Anzahl der Zeilen in der Autorentabelle wurde reduziert, da keine Wiederholung mehr erforderlich ist.
- Eine neue Tabelle namens authors_books ist entstanden, die Informationen darüber enthält, welche Autoren-ID mit welcher Buch-ID verbunden ist. Wir hätten die Verbindungstabelle beliebig benennen können, aber die Konvention besagt, dass sie aus der einfachen Verkettung der beiden Tabellen, die sie repräsentiert, mit einem Unterstrich dazwischen besteht.
Die Verbindungstabelle hat keinen Primärschlüssel und enthält in den meisten Fällen nur zwei Spalten – IDs aus den beiden Tabellen. Es ist fast so, als hätten wir die Fremdschlüsselspalten aus unserem vorherigen Beispiel entfernt und sie in diese neue Tabelle eingefügt. Da es keinen Primärschlüssel gibt, kann es so viele Wiederholungen geben, wie nötig sind, um alle Beziehungen aufzuzeichnen.
Nun können wir mit eigenen Augen sehen, wie die Verbindungstabelle die Zusammenhänge übersichtlich darstellt, aber wie greifen wir in unseren Anwendungen darauf zu? Das Geheimnis liegt in der Bezeichnung – Verbindungstabelle. Dies ist kein Kurs über SQL-Abfragen, daher werde ich nicht darauf eingehen, aber die Idee ist, dass Sie, wenn Sie alle Bücher eines bestimmten Autors in einer effizienten Abfrage haben möchten, die Tabellen in dieser Reihenfolge per SQL verknüpfen –> Autoren, Autoren_Bücher und Bücher. Die Tabellen "authors" und "authors_books" werden über die Spalten "id" bzw. "author_id" verknüpft, während die Tabellen "authors_books" und "books" über die Spalten "book_id" bzw. "id" verknüpft werden.

Anstrengend, ja. Aber sehen Sie das Positive – wir haben alle notwendigen Theorien und Grundlagen behandelt, die wir vor dem Arbeiten mit Eloquent-Modellen erledigen mussten. Und ich möchte Sie daran erinnern, dass all dies nicht optional ist! Wenn Sie sich nicht mit dem Datenbankdesign auskennen, werden Sie für immer im Verwirrungsland von Eloquent gefangen sein. Was Eloquent auch tut oder zu tun versucht, spiegelt diese Details auf Datenbankebene perfekt wider, sodass es leicht einzusehen ist, warum der Versuch, Eloquent zu lernen, während man vor RDBMS davonläuft, ein sinnloses Unterfangen ist.
Erstellen von Modellbeziehungen in Laravel Eloquent
Endlich, nach einem Umweg von etwa 70.000 Meilen, haben wir den Punkt erreicht, an dem wir über Eloquent, seine Modelle und deren Erstellung und Verwendung sprechen können. Wir haben im vorherigen Teil des Artikels gelernt, dass alles mit der Datenbank beginnt und wie Sie Ihre Daten modellieren. Daher wurde mir klar, dass ich ein einzelnes, vollständiges Beispiel verwenden sollte, wenn ich ein neues Projekt beginne. Gleichzeitig möchte ich, dass dieses Beispiel real ist und nicht über Blogs und Autoren oder Bücher und Regale (die auch real sind, aber zu Tode geritten wurden).
Stellen wir uns ein Geschäft vor, das Stofftiere verkauft. Nehmen wir außerdem an, dass wir das Anforderungsdokument erhalten haben, anhand dessen wir diese vier Entitäten im System identifizieren können: Benutzer, Bestellungen, Rechnungen, Artikel, Kategorien, Unterkategorien und Transaktionen. Ja, es wird wahrscheinlich mehr Komplikationen geben, aber lassen wir das beiseite und konzentrieren wir uns darauf, wie wir von einem Dokument zu einer App gelangen.
Nachdem die Hauptentitäten im System identifiziert wurden, müssen wir darüber nachdenken, wie sie in Bezug auf die bisher besprochenen Datenbankbeziehungen zueinander in Beziehung stehen. Hier sind die Beziehungen, die mir einfallen:
- Benutzer und Bestellungen: Eins zu vielen.
- Bestellungen und Rechnungen: Eins zu eins. Mir ist klar, dass dies nicht in Stein gemeißelt ist und je nach Geschäftsbereich eine Eins-zu-viele-, eine Viele-zu-eins- oder eine Viele-zu-viele-Beziehung bestehen kann. In einem durchschnittlichen kleinen E-Commerce-Shop führt eine Bestellung jedoch nur zu einer Rechnung und umgekehrt.
- Bestellungen und Artikel: Viele zu viele.
- Artikel und Kategorien: Viele zu eins. Auch dies ist bei großen E-Commerce-Websites nicht der Fall, aber wir haben einen kleinen Betrieb.
- Kategorien und Unterkategorien: Eins zu vielen. Auch hier werden Sie die meisten Beispiele aus der realen Welt finden, die dem widersprechen, aber hey, Eloquent ist schon schwierig genug, also machen wir die Datenmodellierung nicht noch schwieriger!
- Bestellungen und Transaktionen: Eins zu vielen. Ich möchte auch diese beiden Punkte als Begründung für meine Wahl hinzufügen: 1) Wir hätten auch eine Beziehung zwischen Transaktionen und Rechnungen hinzufügen können. Es ist nur eine Datenmodellierungsentscheidung. 2) Warum hier eins zu vielen? Es ist üblich, dass eine Auftragszahlung aus irgendeinem Grund fehlschlägt und beim nächsten Mal erfolgreich ist. In diesem Fall haben wir zwei Transaktionen für diese Bestellung erstellt. Ob wir diese fehlgeschlagenen Transaktionen anzeigen möchten oder nicht, ist eine geschäftliche Entscheidung, aber es ist immer eine gute Idee, wertvolle Daten zu erfassen.
Gibt es noch andere Beziehungen? Nun, viele weitere Beziehungen sind möglich, aber sie sind nicht praktikabel. Wir könnten zum Beispiel sagen, dass ein Benutzer viele Transaktionen hat, also sollte es eine Beziehung zwischen ihnen geben. Hier muss man erkennen, dass es bereits eine indirekte Beziehung gibt: Benutzer -> Bestellungen -> Transaktionen, und das ist im Allgemeinen gut genug, da RDBMS "Bestien" beim Verknüpfen von Tabellen sind. Zweitens würde das Erstellen dieser Beziehung bedeuten, dass der Transaktionstabelle eine "user_id"-Spalte hinzugefügt wird. Wenn wir dies für jede mögliche direkte Beziehung tun würden, würden wir der Datenbank viel mehr Last hinzufügen (in Form von mehr Speicherplatz, insbesondere bei Verwendung von UUIDs, und bei der Pflege von Indizes) und das Gesamtsystem verketten. Sicher, wenn das Unternehmen sagt, dass es Transaktionsdaten benötigt und diese innerhalb von 1,5 Sekunden benötigt werden, können wir uns entscheiden, diese Beziehung hinzuzufügen und die Dinge zu beschleunigen (Kompromisse, Kompromisse...).
Und jetzt, meine Damen und Herren, ist es an der Zeit, echten Code zu schreiben!

Laravel-Modellbeziehungen – ein echtes Code-Beispiel
In der nächsten Phase dieses Artikels geht es darum, uns die Hände schmutzig zu machen – aber auf eine nützliche Art und Weise. Wir werden die gleichen Datenbankentitäten wie im vorherigen E-Commerce-Beispiel verwenden und sehen, wie Modelle in Laravel erstellt und verbunden werden, direkt nach der Installation von Laravel!
Natürlich gehe ich davon aus, dass Sie Ihre Entwicklungsumgebung eingerichtet haben und wissen, wie Sie Composer installieren und zum Verwalten von Abhängigkeiten verwenden.
$ composer global require laravel/installer -W $ laravel new model-relationships-study
Diese beiden Konsolenbefehle installieren den Laravel-Installer (der "-W"-Teil wird für das Upgrade verwendet, da ich bereits eine ältere Version installiert hatte). Und falls Sie neugierig sind, ist die Laravel-Version, die zum Zeitpunkt des Schreibens installiert wurde, 8.5.9. Sollten Sie in Panik geraten und ebenfalls upgraden? Davon rate ich ab, da ich im Rahmen unserer Anwendung keine großen Änderungen zwischen Laravel 5 und Laravel 8 erwarte. Einige Dinge haben sich geändert und werden sich auf diesen Artikel auswirken (z. B. Modellfabriken), aber ich denke, Sie werden den Code übertragen können.
Da wir das Datenmodell und seine Beziehungen bereits durchdacht haben, wird die Erstellung der Modelle ein Kinderspiel sein. Und Sie werden auch sehen (ich klinge jetzt wie eine Schallplatte mit Sprung!), dass es das Datenbankschema widerspiegelt, da es zu 100 % davon abhängig ist!
Anders gesagt, wir müssen zuerst die Migrationen (und Modelldateien) für alle Modelle erstellen, die auf die Datenbank angewendet werden. Später können wir an den Modellen arbeiten und die Beziehungen hinzufügen.
Mit welchem Modell fangen wir also an? Dem einfachsten und am wenigsten zusammenhängenden natürlich. In unserem Fall ist dies das Benutzermodell. Da Laravel dieses Modell mitbringt (und ohne dieses nicht funktionieren kann 🤣), ändern wir die Migrationsdatei und bereinigen auch das Modell, um es an unsere einfachen Bedürfnisse anzupassen.
Hier ist die Migrationsklasse:
class CreateUsersTable extends Migration
{
public function up()
{
Schema::create('users', function (Blueprint $table) {
$table->id();
$table->string('name');
});
}
}
Da wir eigentlich kein Projekt erstellen, müssen wir uns nicht mit Passwörtern, "is_active" und all dem beschäftigen. Unsere Benutzertabelle wird nur zwei Spalten haben: die ID und den Namen des Benutzers.
Als Nächstes erstellen wir die Migration für die Kategorie. Da Laravel es uns ermöglicht, das Modell auch mit einem einzigen Befehl zu generieren, werden wir dies nutzen, obwohl wir die Modelldatei vorerst nicht anfassen werden.
$ php artisan make:model Category -m Model created successfully. Created Migration: 2021_01_26_093326_create_categories_table
Und hier ist die Migrationsklasse:
class CreateCategoriesTable extends Migration
{
