
Az adatbázis-felosztás egy olyan technika, amellyel vízszintes skálázhatóság érhető el nagyméretű rendszerekben.
Szinte minden valós rendszer egy adatbázis-kiszolgálóból áll, amely sok olvasási kérést és nem elhanyagolható mennyiségű írási kérelmet kap. Ez túlterhelheti a szervert, és ronthatja a rendszer teljesítményét.
Az ilyen hatások mérséklése és a rendszer teljesítményének javítása érdekében léteznek olyan megközelítések, mint az adatbázis-replikáció és az adatbázis-felosztás. Ebben az útmutatóban először a rendszer teljesítményének javítására szolgáló technikákat vizsgáljuk meg, többek között:
- Az adatbázis-kiszolgáló felnagyítása
- Adatbázis replikáció
- Vízszintes particionálás
E technikák megvitatása után folytatjuk az adatbázis-felosztás működésének megismerését, valamint megvizsgáljuk ennek a megközelítésnek az előnyeit és korlátait.
Kezdjük!
Tartalomjegyzék
A rendszer teljesítményének javítására szolgáló technikák
Kezdjük azzal, hogy megvitatjuk azokat a technikákat, amelyek javítják a rendszer teljesítményét, ha az adatbázis-kiszolgáló miatt szűk keresztmetszetek vannak:
#1. Az adatbázis-kiszolgáló bővítése
Az adatbázis-kiszolgáló példányának felnagyítása egyszerű megközelítésnek tűnhet a rendszer teljesítményének javítására. Ez magában foglalja a feldolgozási teljesítmény növelését, több RAM hozzáadását és hasonlókat.
Ez a technika azonban a következő korlátozásokkal jár. Nem rendelkezhetünk végtelen tárolási és feldolgozási teljesítménnyel rendelkező szerverünkkel. Egy bizonyos határon túl pedig csökkenő hozamot kapunk.
#2. Adatbázis replikáció
Ha az adatbázis-kiszolgáló példányának túlterhelése a bejövő kérések miatt következik be, fontolóra vehetjük az adatbázis-replikációt.
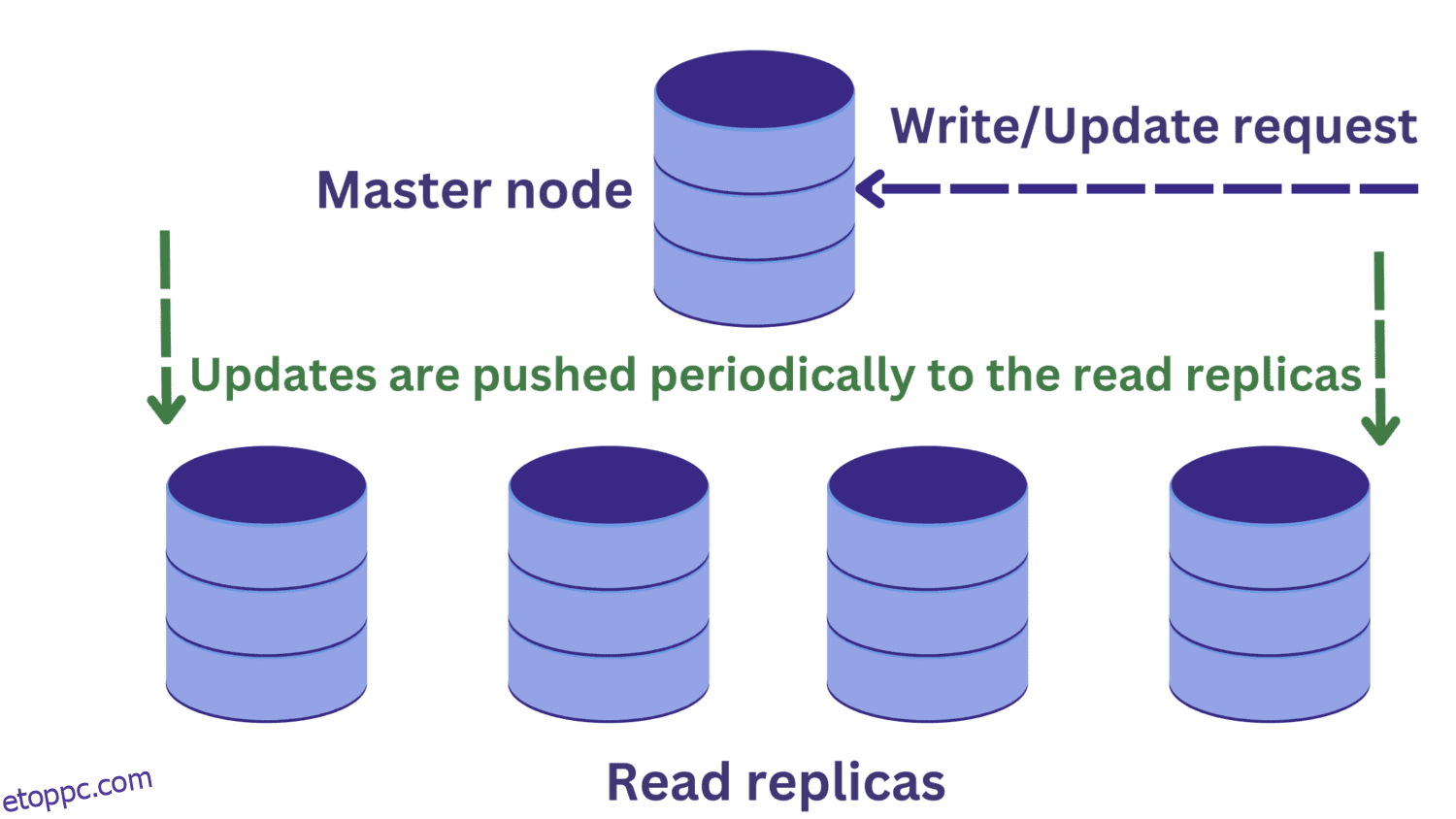
Az adatbázis-replikáció alatt van egy fő csomópont, amely általában írási kéréseket kap. Több olvasott replika létezik.
Ez javítja a rendelkezésre állást és csökkenti a rendszer túlterhelését. Mostantól párhuzamosan több lekérdezést is feldolgozhatunk, mivel az olvasási kérelmek az olvasási replikák egyikéhez irányíthatók.
De ez újabb problémát vet fel. A főcsomóponthoz intézett írási kérelmek módosíthatják az adatokat, és ezeket a frissítéseket rendszeresen továbbítják az olvasási replikákhoz.
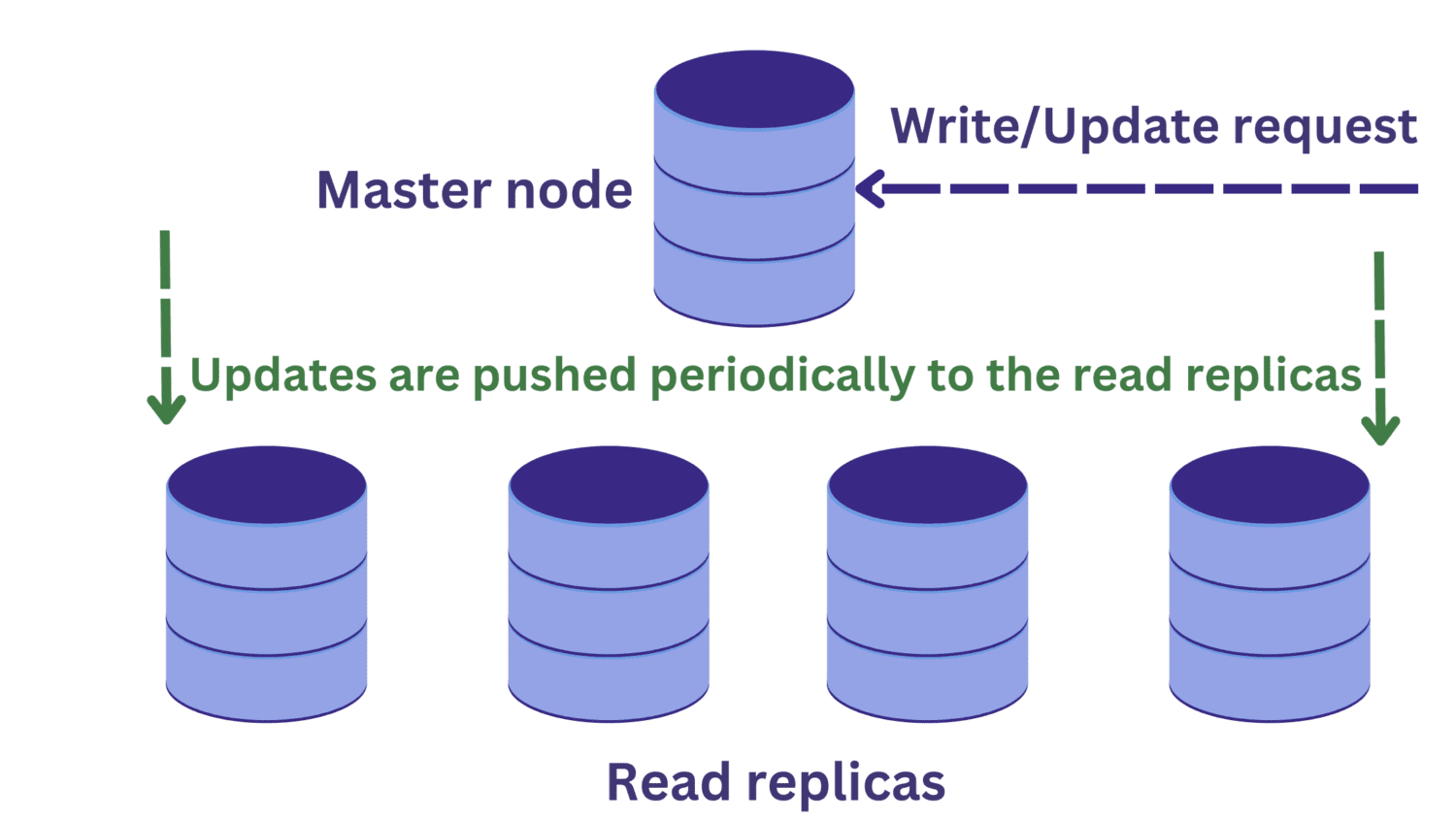
Tegyük fel, hogy van egy olvasási kérés az egyik olvasási replikához, miközben írási művelet van folyamatban a főcsomóponton.
A főcsomópont változásai még nem terjedtek át az olvasási replikákra. Ebben az esetben előfordulhat, hogy elavult adatokat olvasunk, ami nem kívánatos.
#3. Vízszintes particionálás
A vízszintes particionálás egy másik módszer a rendszer teljesítményének optimalizálására. Előfordulhat, hogy egyetlen nagy táblánk több milliárd sorból áll (például ügyfelek és tranzakciós adatok táblája).
Az ilyen adatbázistáblák olvasási műveletei lassabbak. De vízszintes particionálással az egyetlen nagy tábla több partícióra (vagy kisebb táblákra) van felosztva, amelyekből olvashatunk. A relációs adatbázisok, például a PostgreSQL natívan támogatják a particionálást.
Az összes partíció azonban továbbra is egyetlen adatbázis-kiszolgáló-példányon belül van. Az egyetlen különbség az, hogy most már a partíciókból tudunk olvasni az egyetlen nagy tábla helyett.
Emiatt a bejövő kérések számának növekedése esetén előfordulhat, hogy a szerver nem tudja támogatni a megnövekedett keresletet.
Hogyan működik az adatbázis-megosztás?
Most, hogy megvitattuk a rendszer teljesítményének javítását célzó megközelítéseket és azok korlátait, értsük meg, hogyan működik az adatbázis-felosztás.
A felosztás során az egyetlen nagy adatbázist több kisebb adatbázisra bontjuk, amelyek mindegyike egy adatbázis-kiszolgáló-példányon fut. Minden ilyen kisebb adatbázist szilánknak neveznek. És minden szilánk az adatok egy egyedi részhalmazát tartalmazza.
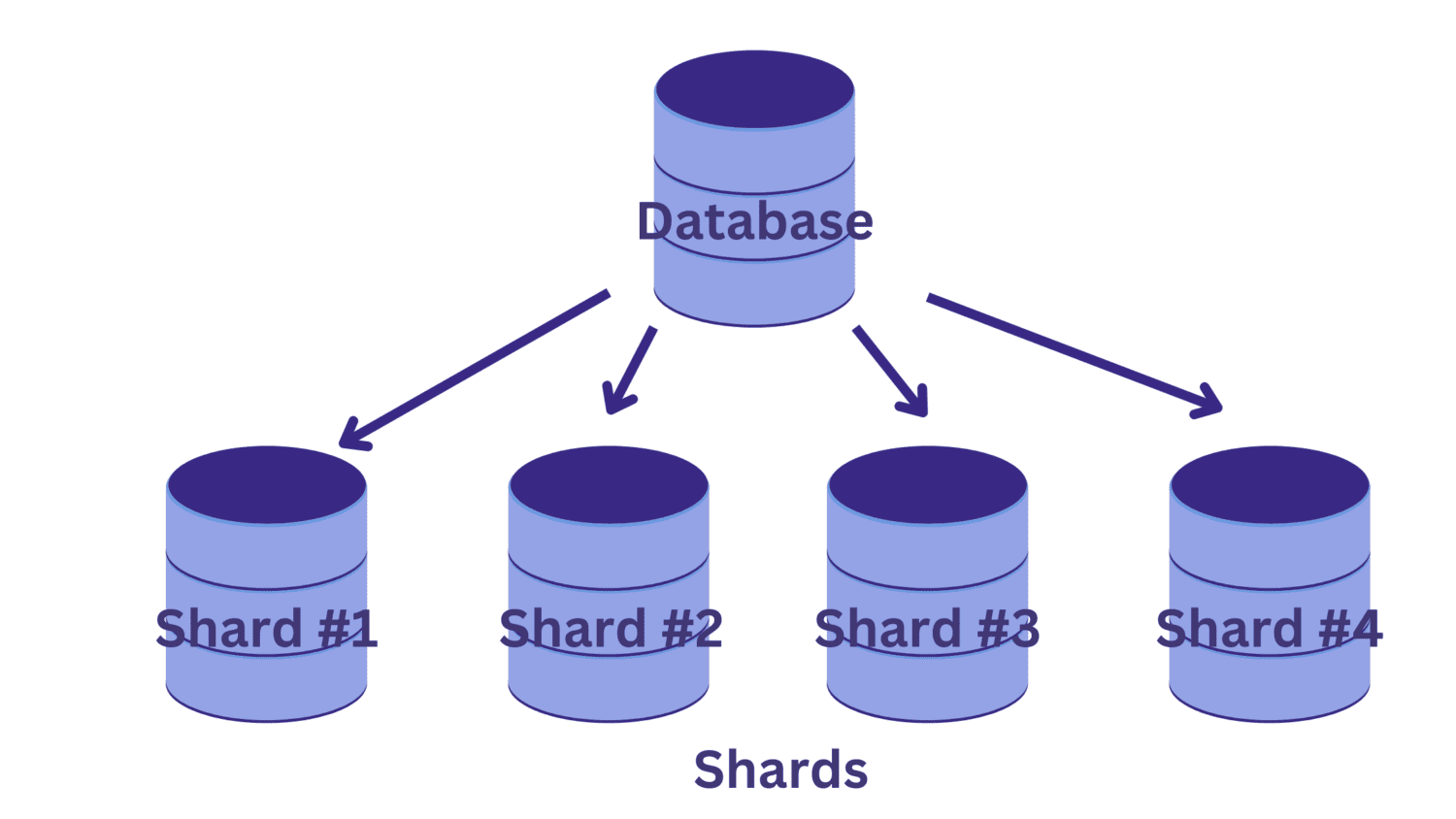
De hogyan particionáljuk az adatbázist szilánkokra? És hogyan határozzuk meg, hogy melyik sor melyik szilánkba kerül?
🔑 Adja meg a megosztási kulcsot.
A megosztási kulcs megértése
Értsük meg a sharding kulcs szerepét.
A felosztási kulcsot, amely általában egy oszlop (vagy oszlopok kombinációja) az adatbázistáblában, úgy kell megválasztani, hogy az adatok több szilánk között egyenletesen oszlanak el. Mert nem akarjuk, hogy egy adott szilánk sokkal nagyobb legyen, mint a többi szilánk.
Az ügyfelek és tranzakciók adatait tároló adatbázisban az ügyfél_azonosítója jó jelölt a felosztási kulcsra.
Miután eldöntöttük a sharding kulcsot, kitalálhatunk egy hash-függvényt, amely meghatározza, hogy melyik sor melyik szilánkba kerüljön.
Ebben a példában tegyük fel, hogy fel kell osztanunk az adatbázist öt szilánkra (a #0-tól a #4-ig), az ügyfél_ID-t használva felosztási kulcsként. Ebben az esetben egy egyszerű hash-függvény az ügyfél_ID % 5.
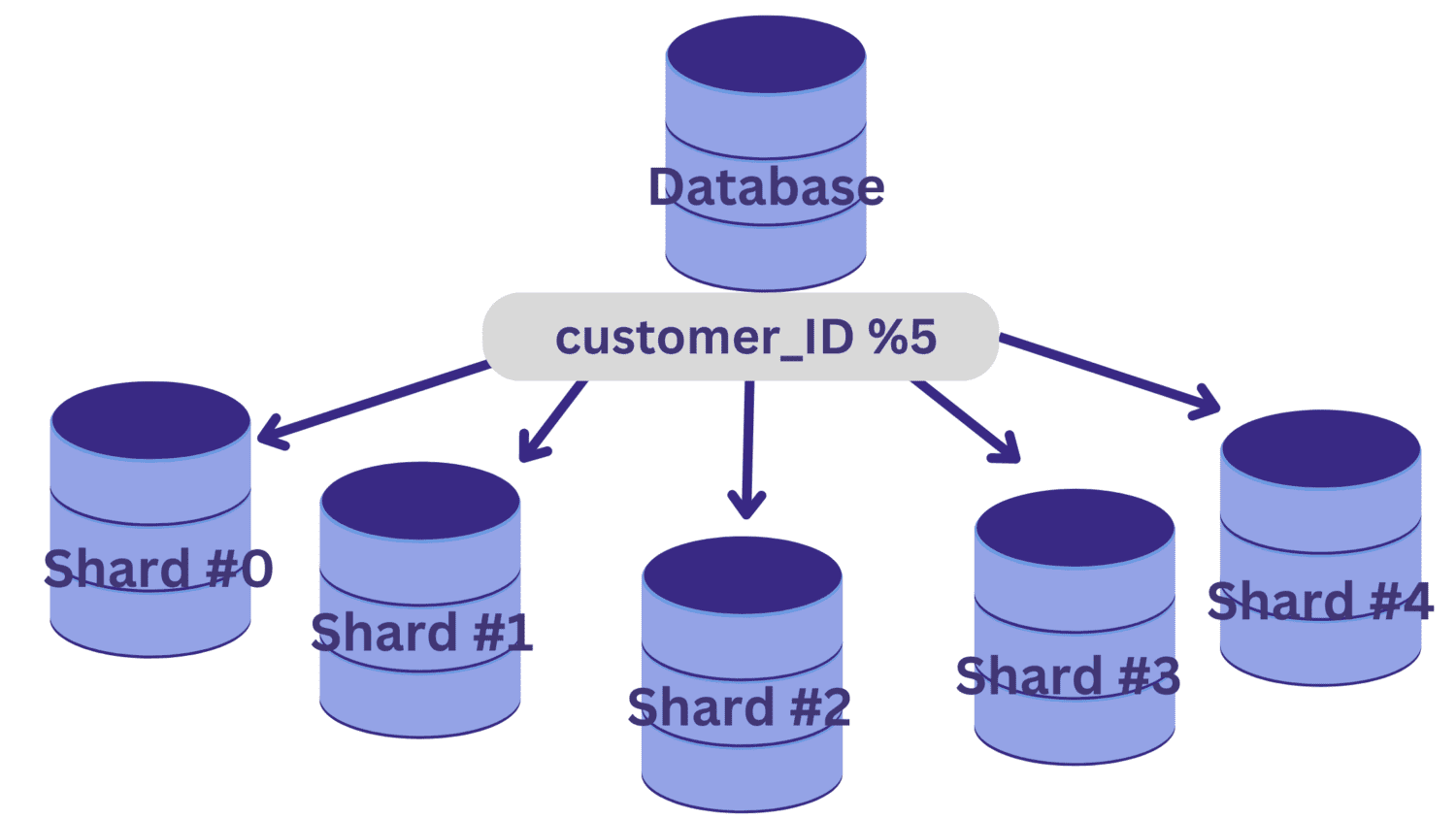
Minden ügyfél_azonosító érték, amely 5-tel osztva nulla maradékot hagy, a 0. szilánkra lesz leképezve. Az 1–4. maradékot hagyó customer_ID értékek pedig az 1–4. szilánkra lesznek leképezve.
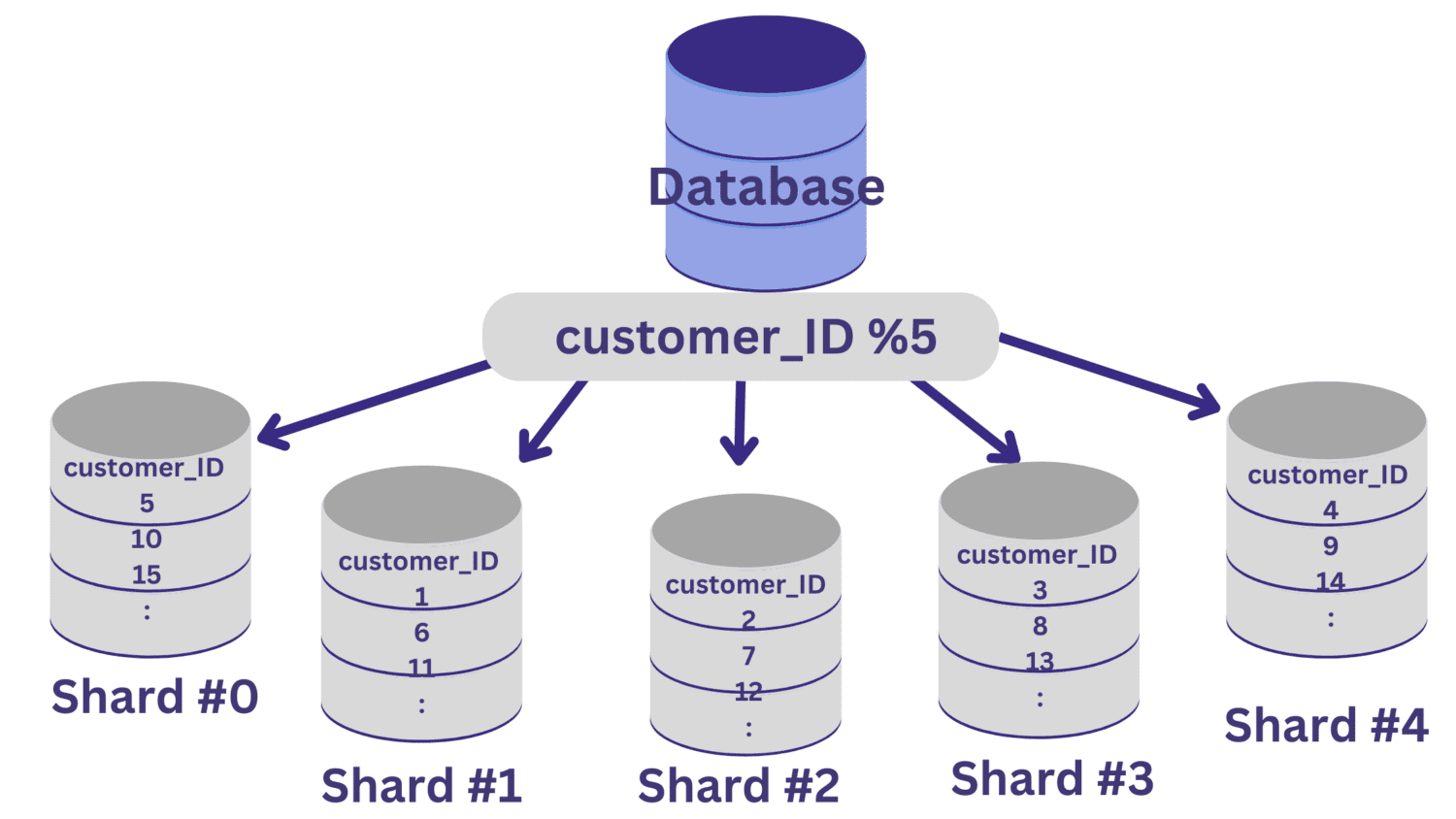
Az adatbázis-felosztás ilyen módon történő megvalósítása után fontos, hogy legyen egy útválasztási réteg, amely a bejövő kéréseket a megfelelő adatbázis-szilánkhoz irányítja.
Az adatbázis-megosztás előnyei
Íme néhány előnye az adatbázis-felosztásnak:
#1. Magas skálázhatóság
Mindig lehetőség van egy nagyobb adatbázis több kisebb szilánkra történő feldarabolására. Tehát az adatbázis felosztása lehetővé teszi a vízszintes méretezést.
#2. Magas rendelkezésre állás
Ha egyetlen adatbázis-kiszolgáló-példány kezeli az összes bejövő kérést, akkor egyetlen hibapontunk van. Ha az adatbázis-kiszolgáló nem működik, az egész alkalmazás nem működik.
Adatbázis-felosztással viszonylag kicsi annak a valószínűsége, hogy egy adott pillanatban az összes adatbázis-szilánk leáll. Ezért, ha egy adott szilánk nem működik, nem tudjuk feldolgozni az adott szilánk olvasási kérelmeit. De a többi szilánk továbbra is képes feldolgozni a bejövő kéréseket. Ez magas rendelkezésre állást és megnövekedett hibatűrést eredményez.
Az adatbázis-megosztás korlátai
Most nézzük meg az adatbázis-felosztás néhány korlátját:
#1. Bonyolultság
Bár a felosztásnak vannak előnyei a skálázhatóság és a hibatűrés szempontjából, összetettebbé teszi a rendszert.
A rekordok partíciókra való leképezésétől az útválasztási réteg megvalósításáig a lekérdezések megfelelő szilánkokhoz való irányításáig az adatbázisok felosztása jelentős bonyolultsággal jár.
#2. Újradarabolás
A felosztás másik korlátja az újrafelosztás szükségessége.
Bár hash funkciót használunk az adatrekordok egyenletes eloszlására, előfordulhat, hogy az egyik szilánk sokkal nagyobb, mint a többi, és hamarabb kimerül. Ebben az esetben számolnunk kell az újrafelosztással (vagy újrakeveréssel), ami jelentős rezsiköltséggel jár.
#3. Összetett lekérdezések futtatása
Ha olyan elemzési lekérdezéseket kell futtatnia, amelyek összekapcsolást tartalmaznak, akkor több szilánkból származó rekordokat kell használnia, nem pedig egyetlen adatbázist. Ez tehát kihívást jelenthet, ha túl sok elemző lekérdezést kell futtatnia. Ezt az adatbázisok denormalizálásával megkerülheti, de ez még némi erőfeszítést igényel!
Következtetés
Zárjuk le a vitát a tanultak összegzésével.
A hardver bővítése nem mindig optimális. Tehát a kiszolgálópéldány feljavítása nem ajánlott. Áttekintettük az olyan technikákat is, mint az adatbázis-replikáció és a horizontális particionálás, valamint ezek korlátai.
Ezután megtudtuk, hogyan működik az adatbázis-felosztás azáltal, hogy egy nagy adatbázist kisebb és könnyen kezelhető szilánkokra osztunk fel. Megbeszéltük, hogyan kell gondosan megválasztani a felosztási kulcsot, hogy egyenletes partíciókat kapjunk, és hogy szükség van egy útválasztási rétegre, amely a bejövő kéréseket a megfelelő adatbázis-szilánkhoz irányítja.
Az adatbázis-felosztásnak olyan előnyei vannak, mint a magas rendelkezésre állás és a méretezhetőség. A hátrányok közé tartozik a felosztás és az újrafeldarabolás beállításának bonyolultsága, amikor egy vagy több szilánk kimerül.
Tehát fontolóra veheti a feldarabolást, ha úgy gondolja, hogy az előnyök meghaladják a feldarabolás összetettségét. Ezután tekintse meg a különböző AWS relációs adatbázisok összehasonlítását.