
A zavaros mátrix egy eszköz a felügyelt gépi tanulási algoritmusok osztályozási típusának teljesítményének értékelésére.
Tartalomjegyzék
Mi az a zavaros mátrix?
Mi, emberek, másképp érzékeljük a dolgokat – még az igazságot és a hazugságot is. Ami számomra 10 cm-es vonalnak tűnik, az Ön számára 9 cm-es vonalnak tűnhet. De a tényleges érték lehet 9, 10 vagy valami más. Amit sejtünk, az a megjósolt érték!
Hogyan gondolkodik az emberi agy
Ahogy az agyunk a saját logikánkat alkalmazza, hogy megjósoljon valamit, a gépek különféle algoritmusokat (úgynevezett gépi tanulási algoritmusokat) alkalmaznak a kérdés előrejelzett értékéhez. Ezek az értékek ismételten megegyezhetnek vagy eltérhetnek a tényleges értéktől.
Egy versengő világban szeretnénk tudni, hogy jóslatunk helyes-e vagy sem, hogy megértsük teljesítményünket. Ugyanígy meghatározhatjuk egy gépi tanulási algoritmus teljesítményét az alapján, hogy hány előrejelzést adott helyesen.
Szóval, mi az a gépi tanulási algoritmus?
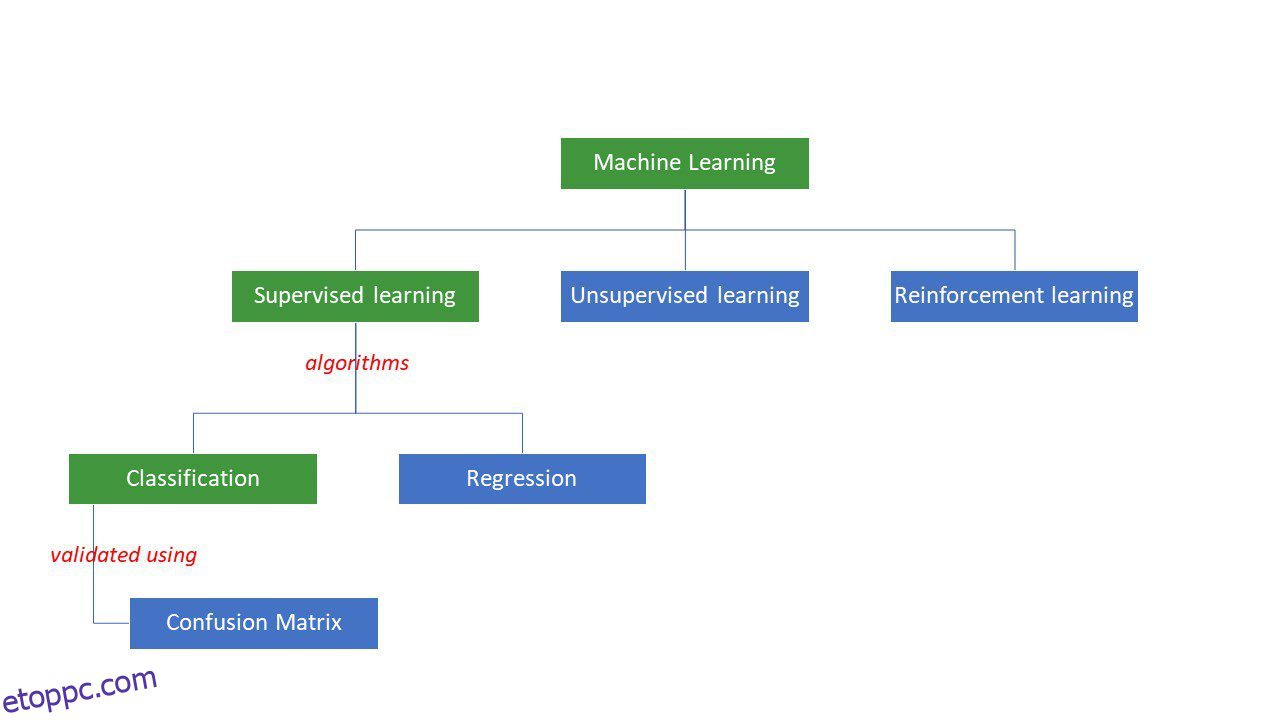
A gépek bizonyos logikát vagy utasításkészletet alkalmazva, úgynevezett gépi tanulási algoritmusokkal próbálnak megoldást találni a problémákra. A gépi tanulási algoritmusoknak három típusa van – felügyelt, nem felügyelt vagy megerősített.
 Gépi tanulási algoritmusok típusai
Gépi tanulási algoritmusok típusai
A legegyszerűbb típusú algoritmusokat felügyeljük, ahol már tudjuk a választ, és a gépeket arra tanítjuk, hogy az algoritmus sok adatot tartalmazó betanításával megérkezzenek erre a válaszra – ugyanúgy, mint ahogyan egy gyerek különbséget tesz a különböző korcsoportok között. újra és újra nézegetve arcvonásaikat.
A felügyelt ML algoritmusok két típusból állnak: osztályozás és regresszió.
Az osztályozási algoritmusok bizonyos kritériumok alapján osztályozzák vagy rendezik az adatokat. Például, ha azt szeretné, hogy az algoritmusa az ügyfeleket étkezési preferenciáik alapján csoportosítsa – akik szeretik a pizzát, és akik nem szeretik a pizzát, akkor olyan osztályozási algoritmust kell használnia, mint a döntési fa, a véletlenszerű erdő, a naiv Bayes vagy az SVM (Support). Vektorgép).
Az alábbi algoritmusok közül melyik lenne a legjobb? Miért érdemes az egyik algoritmust a másik helyett választani?
Írja be a zavaró mátrixot…
A zavaros mátrix egy mátrix vagy táblázat, amely információt ad arról, hogy az osztályozási algoritmus mennyire pontos egy adatkészlet osztályozásában. Nos, a név nem azért van, hogy megzavarjuk az embereket, de a túl sok helytelen előrejelzés valószínűleg azt jelenti, hogy az algoritmus összezavarodott😉!
Tehát a zavaros mátrix egy osztályozási algoritmus teljesítményének értékelési módszere.
Hogyan?
Tegyük fel, hogy különböző algoritmusokat alkalmazott a korábban említett bináris problémánkra: osztályozza (különítse el) az embereket az alapján, hogy szeretik-e a pizzát vagy nem. Annak az algoritmusnak a kiértékeléséhez, amelynek értékei a legközelebb állnak a helyes válaszhoz, egy összekeverési mátrixot kell használni. Egy bináris osztályozási probléma esetén (tetszik/nem tetszik, igaz/hamis, 1/0) a zavaros mátrix négy rácsértéket ad, nevezetesen:
- Valódi pozitív (TP)
- Valódi negatív (TN)
- Hamis pozitív (FP)
- Hamis negatív (FN)
Mi a négy rács egy zavaros mátrixban?
A konfúziós mátrix segítségével meghatározott négy érték alkotja a mátrix rácsát.
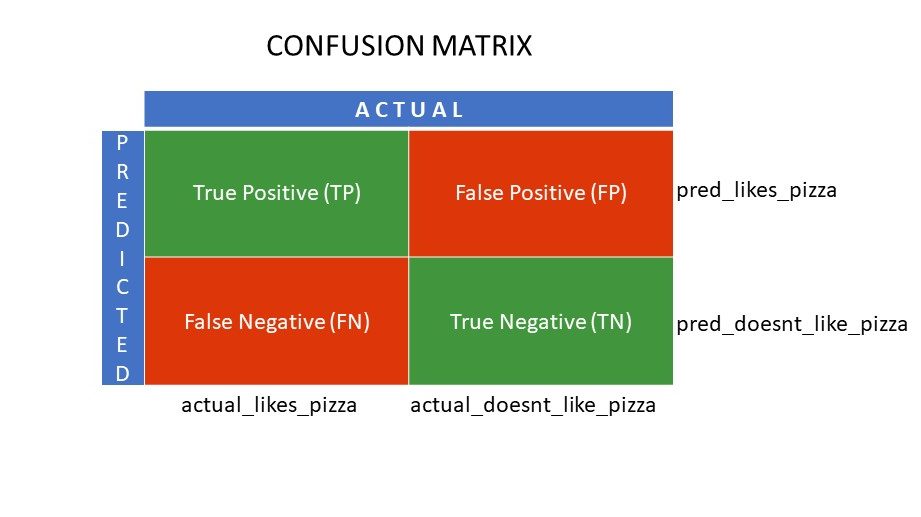 Zavaros mátrix rácsok
Zavaros mátrix rácsok
A True Positive (TP) és a True Negative (TN) az osztályozási algoritmus által helyesen megjósolt értékek,
- A TP azokat képviseli, akik szeretik a pizzát, és a modell helyesen osztályozta őket,
- A TN azokat képviseli, akik nem szeretik a pizzát, és a modell helyesen osztályozta őket,
A fals pozitív (FP) és a fals negatív (FN) azok az értékek, amelyeket az osztályozó rosszul jósol meg,
- Az FP azokat jelenti, akik nem szeretik a pizzát (negatív), de az osztályozó azt jósolta, hogy szeretik a pizzát (rosszul pozitív). Az FP-t I. típusú hibának is nevezik.
- Az FN azokat jelenti, akik szeretik a pizzát (pozitív), de az osztályozó előre jelezte, hogy nem (rosszul negatív). Az FN-t II típusú hibának is nevezik.
A koncepció további megértéséhez vegyünk egy valós forgatókönyvet.
Tegyük fel, hogy van egy 400 emberből álló adatkészlete, aki átesett a Covid-teszten. Most különböző algoritmusok eredményeit kapta, amelyek meghatározták a Covid pozitív és Covid negatív emberek számát.
Összehasonlításképpen itt van a két zavaró mátrix:
Ha mindkettőt megnézi, kísértést érezhet azt mondani, hogy az 1. algoritmus pontosabb. De ahhoz, hogy konkrét eredményt kapjunk, szükségünk van néhány mérőszámra, amelyek képesek mérni a pontosságot, precizitást és sok más értéket, amelyek igazolják, melyik algoritmus a jobb.
Konfúziós mátrixot használó metrikák és jelentőségük
A főbb mutatók, amelyek segítenek eldönteni, hogy az osztályozó helyesen jósolt-e:
#1. Visszahívás/Érzékenység
A visszahívás vagy az érzékenység vagy a valódi pozitív arány (TPR) vagy az észlelési valószínűség a helyes pozitív előrejelzések (TP) és az összes pozitív (azaz TP és FN) aránya.
R = TP/(TP + FN)
A visszahívás a helyes pozitív eredmények mértéke, amely az előállítható helyes pozitív eredmények számából származik. A Recall magasabb értéke azt jelenti, hogy kevesebb a hamis negatív, ami jó az algoritmus számára. Használja a Recall alkalmazást, ha fontos a hamis negatívok ismerete. Például, ha egy személy szívében többszörös elzáródás van, és a modell azt mutatja, hogy teljesen jól van, az végzetesnek bizonyulhat.
#2. Pontosság
A pontosság az összes előrejelzett pozitív eredmény helyes pozitív eredményének mértéke, beleértve az igaz és hamis pozitív eredményeket is.
Pr = TP/(TP + FP)
A pontosság nagyon fontos, ha a hamis pozitív eredmények túl fontosak ahhoz, hogy figyelmen kívül hagyjuk őket. Például, ha valakinek nincs cukorbetegsége, de a modell ezt mutatja, és az orvos felír bizonyos gyógyszereket. Ez súlyos mellékhatásokhoz vezethet.
#3. Specifikusság
A specifikusság vagy a valódi negatív arány (TNR) a helyes negatív eredményeket jelenti az összes olyan eredmény közül, amely negatív lehetett.
S = TN/(TN + FP)
Ez annak mértéke, hogy az osztályozó mennyire jól azonosítja a negatív értékeket.
#4. Pontosság
A pontosság a helyes előrejelzések száma az összes jóslatból. Tehát, ha egy 50-es mintából 20 pozitív és 10 negatív értéket talált helyesen, a modell pontossága 30/50 lesz.
Pontosság A = (TP + TN)/(TP + TN + FP + FN)
#5. Prevalencia
A prevalencia az összes eredményből kapott pozitív eredmények számának mérőszáma.
P = (TP + FN)/(TP + TN + FP + FN)
#6. F Pontszám
Néha nehéz két osztályozót (modellt) összehasonlítani pusztán a Precision és Recall használatával, amelyek csupán a négy rács kombinációjának számtani eszközei. Ilyen esetekben használhatjuk az F Score-t vagy az F1 Score-t, ami a harmonikus átlag – ami pontosabb, mert nem változik túlságosan magas értékek esetén. A magasabb F pontszám (max 1) jobb modellt jelez.
F pontszám = 2*pontosság*visszahívás/ (visszahívás + pontosság)
Amikor létfontosságú a hamis pozitív és hamis negatívumok kezelése, az F1-es pontszám jó mérőszám. Például azokat, akik nem covid pozitívak (de az algoritmus ezt mutatta), nem kell feleslegesen elszigetelni. Ugyanígy el kell különíteni azokat, amelyek Covid-pozitívak (de az algoritmus szerint nem).
#7. ROC görbék
Az olyan paraméterek, mint a Pontosság és a Precízió, jó mérőszámok, ha az adatok kiegyensúlyozottak. Kiegyensúlyozatlan adatkészlet esetén a nagy pontosság nem feltétlenül jelenti azt, hogy az osztályozó hatékony. Például egy csoport 100 diákjából 90 tud spanyolul. Még ha az algoritmusod azt mondja is, hogy mind a 100 tud spanyolul, a pontossága 90%-os lesz, ami rossz képet adhat a modellről. Kiegyensúlyozatlan adatkészletek esetén az olyan metrikák, mint a ROC hatékonyabb meghatározók.
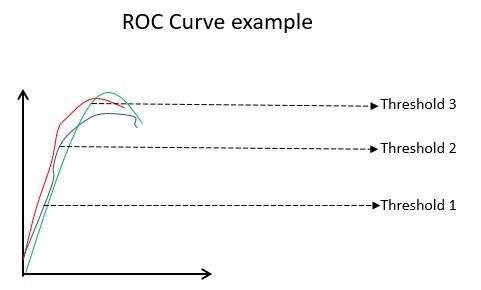 ROC görbe példa
ROC görbe példa
A ROC (Receiver Operating Characteristic) görbe vizuálisan megjeleníti a bináris osztályozási modell teljesítményét különböző osztályozási küszöbök mellett. Ez a TPR (True Positive Rate) és az FPR (hamis pozitív arány) függvénye, amely (1-specificitás) különböző küszöbértékeken kerül kiszámításra. A diagramban a 45 fokhoz legközelebb eső érték (bal felső sarokban) a legpontosabb küszöbérték. Ha a küszöb túl magas, akkor nem lesz sok téves pozitív, de több hamis negatív és fordítva.
Általában, ha a különböző modellek ROC-görbéjét ábrázoljuk, akkor azt tekintjük jobb modellnek, amelyiknek a legnagyobb a görbe alatti területe (AUC).
Számítsuk ki az összes metrikaértéket az I. és II. osztályozó összetévesztési mátrixainkhoz:
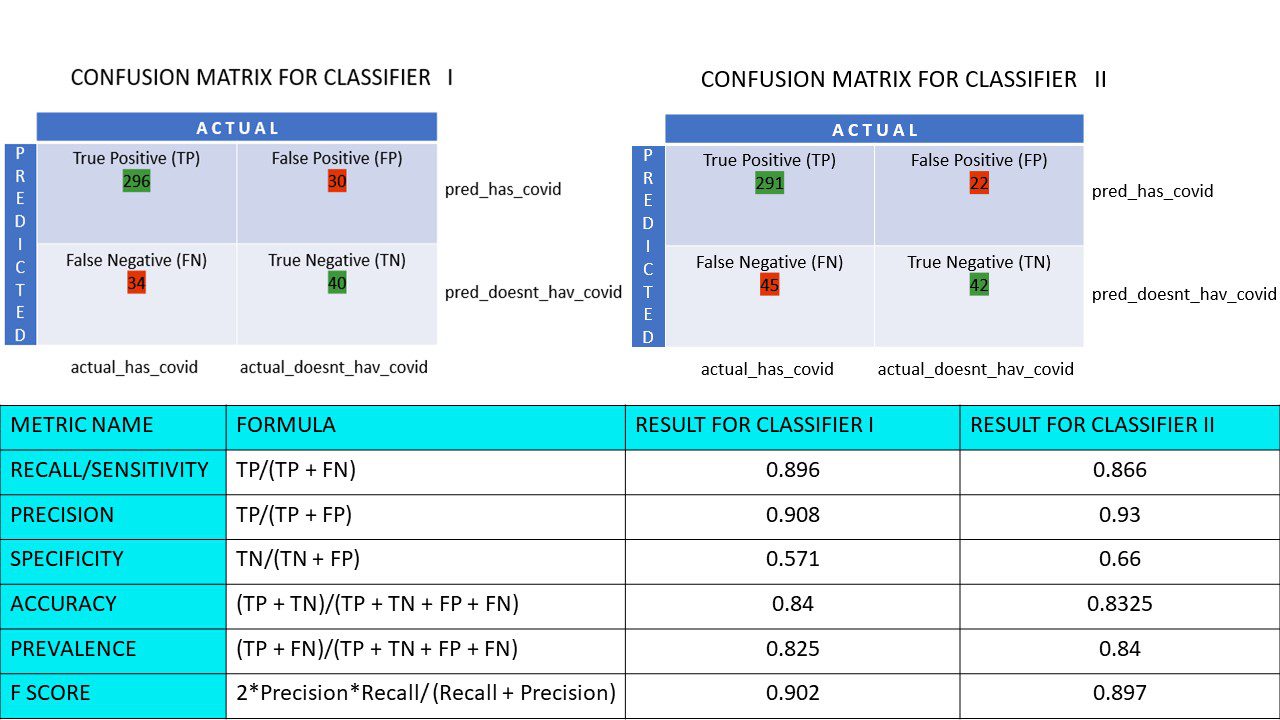 A pizzafelmérés 1. és 2. osztályozójának metrikus összehasonlítása
A pizzafelmérés 1. és 2. osztályozójának metrikus összehasonlítása
Azt látjuk, hogy a pontosság nagyobb a II. osztályozóban, míg a pontosság valamivel nagyobb az I. osztályozóban. Az adott probléma alapján a döntéshozók választhatják az I. vagy II. osztályozót.
N x N zavaró mátrix
Eddig a bináris osztályozók zavarmátrixát láthattuk. Mi lenne, ha több kategória lenne, mint az igen/nem vagy a tetszik/nem tetszik. Például, ha az algoritmusa vörös, zöld és kék színű képeket rendezett. Az ilyen típusú osztályozást többosztályos osztályozásnak nevezik. A kimeneti változók száma meghatározza a mátrix méretét is. Tehát ebben az esetben a zavaró mátrix 3×3 lesz.
 Zavaros mátrix többosztályos osztályozóhoz
Zavaros mátrix többosztályos osztályozóhoz
Összegzés
A zavaros mátrix nagyszerű kiértékelő rendszer, mivel részletes információkat ad egy osztályozási algoritmus teljesítményéről. Jól működik bináris és több osztályú osztályozókhoz is, ahol 2-nél több paraméterre kell ügyelni. Könnyű megjeleníteni egy zavaros mátrixot, és a zavaró mátrix segítségével előállíthatjuk a teljesítmény összes többi mérőszámát, például az F Score-t, a precizitást, a ROC-t és a pontosságot.
Azt is megnézheti, hogyan válasszon ML algoritmusokat regressziós problémákhoz.