
A modern mesterséges intelligencia (AI) területén a megerősítéses tanulás (RL) az egyik legmenőbb kutatási téma. A mesterséges intelligencia és a gépi tanulás (ML) fejlesztői az RL gyakorlatokra is összpontosítanak az általuk fejlesztett intelligens alkalmazások vagy eszközök rögtönzése érdekében.
A gépi tanulás az összes AI-termék alapelve. A humán fejlesztők különféle ML-módszereket használnak intelligens alkalmazásaik, játékaik stb. képzésére. Az ML rendkívül szerteágazó terület, és a különböző fejlesztőcsapatok új módszerekkel készülnek a gépek betanítására.
Az ML egyik ilyen jövedelmező módszere a mély megerősítéses tanulás. Itt megbünteti a gép nem kívánt viselkedését, és jutalmazza az intelligens gép kívánt cselekedeteit. A szakértők úgy vélik, hogy az ML ezen módszere arra készteti az MI-t, hogy tanuljon saját tapasztalataiból.
Olvassa tovább ezt a végső útmutatót az intelligens alkalmazások és gépek megerősítő tanulási módszereiről, ha a mesterséges intelligencia és a gépi tanulás területén gondolkodik.
Tartalomjegyzék
Mi az erősítő tanulás a gépi tanulásban?
Az RL a gépi tanulási modellek tanítása számítógépes programok számára. Ezután az alkalmazás döntések sorozatát hozhatja meg a tanulási modellek alapján. A szoftver megtanulja elérni a célt egy potenciálisan összetett és bizonytalan környezetben. Az ilyen típusú gépi tanulási modellben az AI játékszerű forgatókönyvvel néz szembe.
Az AI-alkalmazás próba- és hibapróbákat alkalmaz, hogy kreatív megoldást találjon ki a felmerülő problémára. Miután az AI alkalmazás megtanulja a megfelelő ML modelleket, utasítja az általa vezérelt gépet, hogy végezzen el néhány olyan feladatot, amelyet a programozó akar.
A helyes döntés és a feladat elvégzése alapján az MI jutalmat kap. Ha azonban a mesterséges intelligencia rossz döntéseket hoz, büntetés vár rá, például jutalompontok elvesztése. Az AI alkalmazás végső célja a maximális számú jutalompont felhalmozása a játék megnyeréséhez.
Az AI alkalmazás programozója határozza meg a játékszabályokat vagy a jutalmazási szabályzatot. A programozó azt a problémát is megadja, amelyet az AI-nak meg kell oldania. Más ML modellekkel ellentétben az AI program nem kap semmilyen utalást a szoftverprogramozótól.
Az AI-nak ki kell találnia, hogyan oldja meg a játék kihívásait, hogy maximális jutalmat szerezzen. Az alkalmazás próba- és hibapróbákat, véletlenszerű kísérleteket, szuperszámítógépes készségeket és kifinomult gondolkodási folyamat taktikákat használhat a megoldás eléréséhez.
Az AI-programot hatékony számítástechnikai infrastruktúrával kell felszerelnie, és gondolkodási rendszerét különféle párhuzamos és történelmi játékmenetekkel kell összekapcsolnia. Ezután a mesterséges intelligencia olyan kritikus és magas szintű kreativitást tud felmutatni, amelyet az emberek el sem tudnak képzelni.
Népszerű példák a megerősítő tanulásra
#1. A legjobb Human Go játékos legyőzése
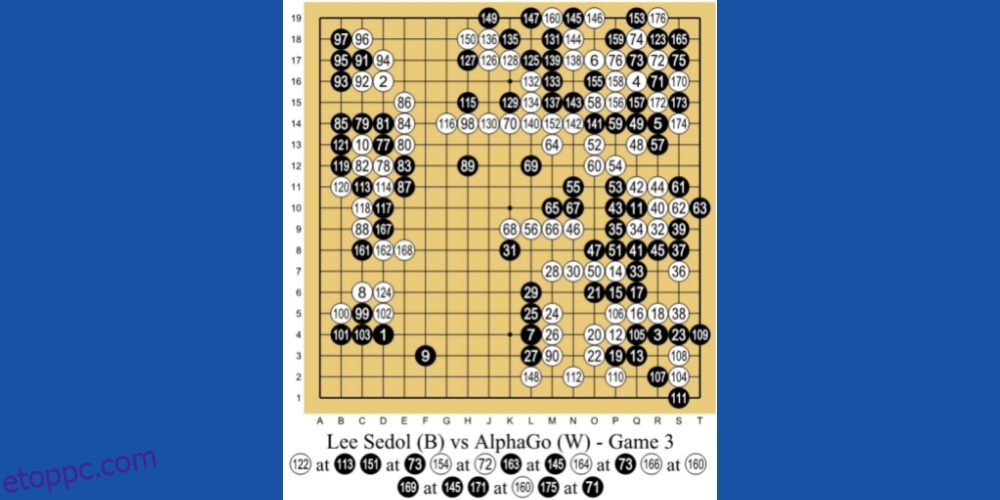
A Google leányvállalata, a DeepMind Technologies AlphaGo AI az RL-alapú gépi tanulás egyik vezető példája. Az AI a Go nevű kínai társasjátékkal játszik. Ez egy 3000 éves játék, amely a taktikára és stratégiákra összpontosít.
A programozók az RL tanítási módszert alkalmazták az AlphaGo számára. Több ezer Go játékmenetet játszott le emberekkel és önmagával. Aztán 2016-ban legyőzte a világ legjobb Go-játékosát, Lee Se-dolt egy-egy meccsen.
#2. Valós robotika
Az emberek régóta használják a robotikát olyan gyártósorokon, ahol a feladatok előre meg vannak tervezve és ismétlődőek. De ha egy általános célú robotot kell készítenie a való világ számára, ahol a cselekvések nincsenek előre megtervezve, akkor ez nagy kihívás.
A tanulást megerősítő mesterséges intelligencia azonban sima, navigálható és rövid útvonalat fedezhet fel két hely között.
#3. Önvezető járművek
Az autonóm járművek kutatói széles körben használják az RL-módszert mesterséges intelligencia oktatására:
- Dinamikus útvonal
- Pálya optimalizálás
- Mozgástervezés, például parkolás és sávváltás
- Optimalizáló vezérlők, (elektronikus vezérlőegység) ECU-k, (mikrokontrollerek) MCU-k stb.
- Forgatókönyv-alapú tanulás autópályákon
#4. Automatizált hűtőrendszerek

Az RL-alapú AI-k segíthetnek minimalizálni a hűtőrendszerek energiafogyasztását óriási irodaházakban, üzleti központokban, bevásárlóközpontokban és – ami a legfontosabb – adatközpontokban. Az AI több ezer hőérzékelőtől gyűjt adatokat.
Ezenkívül adatokat gyűjt az emberi és gépi tevékenységekről. Ezekből az adatokból az AI előre tudja látni a jövőbeli hőtermelési potenciált, és megfelelően be- és kikapcsolja a hűtőrendszereket az energiatakarékosság érdekében.
Megerősítő tanulási modell felállítása
Az RL modellt a következő módszerek alapján állíthatja be:
#1. Politika alapú
Ez a megközelítés lehetővé teszi az AI-programozó számára, hogy megtalálja az ideális szabályzatot a maximális jutalom érdekében. Itt a programozó nem használja az érték függvényt. Miután beállította a házirend-alapú módszert, a megerősítő tanulási ügynök megpróbálja alkalmazni a házirendet, hogy az egyes lépésekben végrehajtott műveletek lehetővé tegyék az AI számára a jutalompontok maximalizálását.
Elsősorban kétféle irányelv létezik:
#1. Determinisztikus: A házirend bármely adott állapotban ugyanazokat a műveleteket tudja előidézni.
#2. Sztochasztikus: Az előállított cselekvéseket az előfordulási valószínűség határozza meg.
#2. Érték alapú
Az értékalapú megközelítés éppen ellenkezőleg, segít a programozónak megtalálni az optimális értékfüggvényt, amely egy adott állapot esetén a maximális érték egy szabályzat alatt. Alkalmazása után az RL ügynök hosszú távú megtérülést vár az említett házirend bármelyik vagy több állapotában.
#3. Modell alapú
A modell alapú RL megközelítésben az AI programozó virtuális modellt hoz létre a környezet számára. Ezután az RL ügynök mozog a környezetben, és tanul belőle.
Az erősítő tanulás típusai
#1. Pozitív megerősítő tanulás (PRL)
A pozitív tanulás azt jelenti, hogy hozzáadunk néhány elemet annak érdekében, hogy növeljük annak valószínűségét, hogy a várt viselkedés megismétlődik. Ez a tanulási módszer pozitívan befolyásolja az RL ügynök viselkedését. A PRL emellett javítja a mesterséges intelligencia bizonyos viselkedéseinek erősségét.
A PRL típusú tanulási megerősítésnek fel kell készítenie az MI-t a változásokhoz való hosszú távú alkalmazkodásra. A túl sok pozitív tanulás azonban túlterhelt állapotokhoz vezethet, ami csökkentheti az AI hatékonyságát.

#2. Negatív megerősítésű tanulás (NRL)
Amikor az RL algoritmus segít az MI-nek elkerülni vagy megállítani a negatív viselkedést, tanul belőle, és javítja a jövőbeni cselekvéseit. Negatív tanulásnak nevezik. Csak korlátozott intelligenciát biztosít a mesterséges intelligencia számára, hogy megfeleljen bizonyos viselkedési követelményeknek.
A megerősítő tanulás valós használati esetei
#1. Az e-kereskedelmi megoldások fejlesztői személyre szabott termék- vagy szolgáltatásjavasló eszközöket építettek ki. Az eszköz API-ját csatlakoztathatja online vásárlási webhelyéhez. Ezután az AI tanul az egyes felhasználóktól, és egyedi termékeket és szolgáltatásokat javasol.
#2. A nyílt világú videojátékok határtalan lehetőségeket rejtenek magukban. A játékprogram mögött azonban van egy mesterséges intelligencia program, amely a játékosok beviteléből tanul, és módosítja a videojáték kódját, hogy alkalmazkodjon egy ismeretlen helyzethez.
#3. A mesterséges intelligencia alapú tőzsdei kereskedési és befektetési platformok az RL modellt használják, hogy tanuljanak a részvények és a globális indexek mozgásából. Ennek megfelelően valószínűségi modellt fogalmaznak meg, amely részvényeket befektetésre vagy kereskedésre javasol.
#4. Az olyan online videokönyvtárak, mint a YouTube, a Metacafe, a Dailymotion stb., RL-modellre kiképzett AI-botokat használnak, hogy személyre szabott videókat javasoljanak felhasználóiknak.
Megerősítő tanulás vs. Felügyelt tanulás
A megerősítő tanulás célja, hogy a mesterséges intelligencia ügynökét szekvenciális döntések meghozatalára tanítsa. Dióhéjban megfontolható, hogy az AI kimenete a jelenlegi bemenet állapotától függ. Hasonlóképpen, az RL algoritmus következő bemenete a múltbeli bemenetek kimenetétől függ.

Az RL gépi tanulási modell példája egy mesterséges intelligencia-alapú robotgép, amely sakkot játszik egy emberi sakkozó ellen.
Éppen ellenkezőleg, a felügyelt tanulás során a programozó megtanítja az AI-ügynököt, hogy döntéseket hozzon az induláskor megadott bemenetek vagy bármely más kezdeti bemenet alapján. Az autonóm autóvezetés a környezeti tárgyakat felismerő mesterséges intelligencia kiváló példája a felügyelt tanulásnak.
Megerősítő tanulás vs. Felügyelet nélküli tanulás
Eddig megértette, hogy az RL-módszer arra készteti az AI-ügynököt, hogy tanuljon a gépi tanulási modell irányelveiből. Főleg az AI csak azokat a lépéseket teszi meg, amelyekért maximális jutalompontot kap. Az RL segít egy mesterséges intelligencia számára, hogy próba-hibán keresztül rögtönözze magát.
Másrészt a felügyelet nélküli tanulás során az AI programozó bevezeti az AI szoftvert címkézetlen adatokkal. Ezenkívül az ML oktató nem mond semmit az AI-nak az adatstruktúráról vagy arról, hogy mit kell keresnie az adatokban. Az algoritmus úgy tanul meg különféle döntéseket, hogy az adott ismeretlen adatsorokon saját megfigyeléseit katalogizálja.
Megerősítő tanulási tanfolyamok
Most, hogy megtanulta az alapokat, itt van néhány online kurzus a haladó megerősítő tanulás elsajátítására. Kap egy tanúsítványt is, amelyet bemutathat a LinkedIn-en vagy más közösségi platformokon:
Megerősítő tanulási szakirány: Coursera
Szeretné elsajátítani a megerősítő tanulás alapvető fogalmait az ML kontextusban? Ezt kipróbálhatod Coursera RL tanfolyam amely online elérhető, és önálló tanulási és minősítési lehetőséggel rendelkezik. A tanfolyam akkor lesz megfelelő az Ön számára, ha az alábbi ismereteket hozza magával:
- Programozási ismeretek Pythonban
- Statisztikai alapfogalmak
- A pszeudokódokat és az algoritmusokat Python kódokká alakíthatja
- Két-három éves szoftverfejlesztési tapasztalat
- Számítástechnika szakon másodéves egyetemisták is jelentkezhetnek
A kurzus 4,8 csillagos besorolású, és már több mint 36 000 hallgató iratkozott be a kurzusra különböző időpontokban. Ezenkívül a kurzushoz pénzügyi támogatás jár, feltéve, hogy a jelölt megfelel a Coursera bizonyos alkalmassági feltételeinek.
Végül az Albertai Egyetem Alberta Gépi Intelligencia Intézete kínálja ezt a kurzust (nem jár kredit). A számítástechnika területén tevékenykedő tisztelt professzorok fognak kurzusoktatóként működni. A tanfolyam elvégzése után Coursera bizonyítványt kapsz.
AI megerősítése tanulás Pythonban: Udemy
Ha Ön a pénzügyi piac vagy a digitális marketing iránt érdeklődik, és intelligens szoftvercsomagokat szeretne fejleszteni az említett területekre, akkor ezt meg kell néznie Udemy tanfolyam RL-en. Az RL alapelvein kívül a képzési tartalom arra is felvilágosítást ad, hogyan fejleszthet RL megoldásokat az online hirdetési és tőzsdei kereskedéshez.

Néhány figyelemre méltó téma, amivel a tanfolyam foglalkozik:
- Az RL magas szintű áttekintése
- Dinamikus programozás
- Monet Carlo
- Közelítési módszerek
- Tőzsdei kereskedési projekt RL-vel
Eddig több mint 42 ezer diák vett részt a tanfolyamon. Az online tanulási forrás jelenleg 4,6 csillagos minősítést kapott, ami meglehetősen lenyűgöző. Ezenkívül a kurzus célja a globális hallgatói közösség kiszolgálása, mivel a tanulási tartalom francia, angol, spanyol, német, olasz és portugál nyelven érhető el.
Mély megerősítési tanulás Pythonban: Udemy
Ha kíváncsi vagy és alapvető ismereteid vannak a mélytanulásról és a mesterséges intelligenciáról, akkor kipróbálhatod ezt a haladót RL tanfolyam Pythonban Udemytől. A hallgatók 4,6 csillagos értékelésével ez egy újabb népszerű kurzus az RL tanulására az AI/ML kontextusában.

A kurzus 12 szekcióból áll, és a következő létfontosságú témákat fedi le:
- OpenAI Gym és alapvető RL technikák
- TD lambda
- A3C
- Theano alapismeretek
- Tensorflow alapjai
- Python kódolás kezdőknek
A teljes tanfolyam 10 óra 40 perces elkötelezett befektetést igényel. A szövegeken kívül 79 szakértői előadást is tartalmaz.
Mélyerősítő tanulási szakértő: Udacity
Szeretnél haladó gépi tanulást tanulni az AI/ML világ vezető szereplőitől, mint például az Nvidia Deep Learning Institute és a Unity? Az Udacity segítségével megvalósíthatja álmait. Nézd meg ezt Mélyerősítő tanulás tanfolyamot, hogy ML szakértővé válhasson.

Azonban haladó Python, középfokú statisztikák, valószínűségszámítás, TensorFlow, PyTorch és Keras háttérrel kell rendelkeznie.
A tanfolyam elvégzéséhez akár 4 hónap szorgalmas tanulásra lesz szükség. A kurzus során olyan létfontosságú RL-algoritmusokat tanulhat meg, mint a Deep Deterministic Policy Gradients (DDPG), a Deep Q-Networks (DQN) stb.
Végső szavak
A tanulás megerősítése a mesterséges intelligencia fejlesztésének következő lépése. Az AI-fejlesztő ügynökségek és IT-cégek befektetéseket hajtanak végre ebben a szektorban, hogy megbízható és megbízható mesterségesintelligencia-képzési módszereket hozzanak létre.
Bár az RL sokat fejlődött, több fejlesztési terület van. Például a különálló RL ügynökök nem osztják meg egymással a tudást. Ezért, ha egy alkalmazást autóvezetésre oktat, a tanulási folyamat lelassul. Mivel az RL ügynökök, mint például az objektumészlelés, úthivatkozások stb., nem osztanak meg adatokat.
Lehetőség van arra, hogy kreativitását és ML szakértelmét az ilyen kihívásokba fektesse. Az online kurzusokra való feliratkozás segít továbbfejleszteni tudását a haladó RL módszerekről és azok valós projektekben való alkalmazásairól.
Egy másik kapcsolódó tanulás az Ön számára az AI, a Machine Learning és a Deep Learning közötti különbségek.