Daten sind ein integraler Bestandteil jedes Unternehmens und jeder Organisation. Ihr Wert entfaltet sich jedoch erst, wenn sie korrekt strukturiert und effizient verwaltet werden.
Statistiken zeigen, dass heutzutage 95 % der Unternehmen Schwierigkeiten bei der Handhabung und Strukturierung unstrukturierter Daten haben.
Hier kommt das Data-Mining ins Spiel. Es handelt sich um den Prozess der Entdeckung, Analyse und Extraktion bedeutsamer Muster und wertvoller Erkenntnisse aus großen Mengen unstrukturierter Daten.
Unternehmen nutzen Software, um Muster in großen Datenmengen zu erkennen. Dadurch erhalten sie Einblicke in ihre Kunden und Zielgruppen, was ihnen wiederum ermöglicht, Geschäfts- und Marketingstrategien zur Umsatzsteigerung und Kostensenkung zu entwickeln.
Neben dieser Kernfunktion ist die Erkennung von Betrug und Anomalien eine weitere wichtige Anwendung des Data-Mining.
Dieser Beitrag widmet sich der Anomalieerkennung und untersucht ihre Rolle bei der Prävention von Datenschutzverletzungen und Netzwerkeinbrüchen, um die Datensicherheit zu erhöhen.
Was ist Anomalieerkennung und welche Arten gibt es?
Während sich Data-Mining auf die Suche nach Mustern, Korrelationen und Trends konzentriert, die miteinander in Beziehung stehen, ist es auch ein wirksames Mittel, um Anomalien oder Ausreißer innerhalb eines Netzwerks zu entdecken.
Anomalien im Data-Mining sind Datenpunkte, die sich von anderen Datenpunkten innerhalb des Datensatzes unterscheiden und vom normalen Verhaltensmuster abweichen.
Anomalien lassen sich in verschiedene Kategorien einteilen:
- Veränderungen in Ereignissen: Diese beziehen sich auf abrupte oder systematische Abweichungen vom bisherigen normalen Verhalten.
- Ausreißer: Dabei handelt es sich um kleinere, anomale Muster, die unregelmäßig bei der Datenerfassung auftreten. Diese können weiter in globale, kontextbezogene und kollektive Ausreißer unterteilt werden.
- Drifts: Hierbei handelt es sich um allmähliche, ungerichtete und langfristige Veränderungen im Datensatz.
Die Anomalieerkennung ist somit eine Datenverarbeitungstechnik, die sich als äußerst nützlich erweist, um betrügerische Transaktionen zu identifizieren, Fallstudien mit starken Ungleichgewichten zu bearbeiten und Krankheiten zu diagnostizieren, um robuste datenwissenschaftliche Modelle zu erstellen.
Ein Unternehmen könnte beispielsweise seinen Cashflow analysieren, um ungewöhnliche oder wiederkehrende Transaktionen auf ein unbekanntes Bankkonto zu finden und so Betrug aufzudecken und weitere Ermittlungen einzuleiten.
Vorteile der Anomalieerkennung
Die Identifizierung von Anomalien im Nutzerverhalten trägt zur Verbesserung von Sicherheitssystemen bei und macht diese präziser.
Es werden diverse Informationen analysiert und interpretiert, die von Sicherheitssystemen bereitgestellt werden, um Bedrohungen und potenzielle Risiken innerhalb des Netzwerks zu erkennen.
Hier sind die Vorteile der Anomalieerkennung für Unternehmen:
- Echtzeit-Erkennung von Cybersicherheitsbedrohungen und Datenschutzverletzungen, da Algorithmen der künstlichen Intelligenz (KI) Ihre Daten kontinuierlich auf ungewöhnliches Verhalten hin überprüfen.
- Schnellere und einfachere Verfolgung anomaler Aktivitäten und Muster im Vergleich zur manuellen Anomalieerkennung, was den Aufwand und die Zeit für die Behebung von Bedrohungen reduziert.
- Minimierung von Betriebsrisiken durch die Erkennung von Fehlern, wie plötzliche Leistungseinbußen, bevor sie auftreten.
- Verhinderung größerer geschäftlicher Schäden durch die schnelle Identifizierung von Anomalien, da Unternehmen ohne ein Anomalieerkennungssystem Wochen oder Monate benötigen können, um potenzielle Bedrohungen zu identifizieren.
Die Anomalieerkennung ist daher ein bedeutender Vorteil für Unternehmen, die große Mengen an Kunden- und Geschäftsdaten speichern, um Wachstumspotenziale zu erkennen und Sicherheitsbedrohungen sowie betriebliche Engpässe zu beseitigen.
Techniken der Anomalieerkennung
Die Anomalieerkennung nutzt verschiedene Verfahren und Algorithmen des maschinellen Lernens (ML), um Daten zu überwachen und Bedrohungen zu erkennen.
Hier sind die wichtigsten Techniken zur Anomalieerkennung:
#1. Techniken des maschinellen Lernens
Techniken des maschinellen Lernens verwenden ML-Algorithmen zur Datenanalyse und Anomalieerkennung. Es gibt verschiedene Arten von Algorithmen für maschinelles Lernen, die zur Anomalieerkennung eingesetzt werden, darunter:
- Clustering-Algorithmen
- Klassifizierungsalgorithmen
- Deep-Learning-Algorithmen
Zu den häufig verwendeten ML-Techniken zur Erkennung von Anomalien und Bedrohungen gehören Support Vector Machines (SVMs), K-Means-Clustering und Autoencoder.
#2. Statistische Methoden
Statistische Techniken nutzen statistische Modelle, um ungewöhnliche Muster in Daten zu erkennen. Sie identifizieren Werte, die außerhalb des Bereichs der erwarteten Werte liegen, wie beispielsweise ungewöhnliche Schwankungen in der Leistung einer bestimmten Maschine.
Zu den gängigen Techniken zur statistischen Anomalieerkennung gehören Hypothesentests, IQR, Z-Score, modifizierter Z-Score, Dichteschätzung, Boxplot, Extremwertanalyse und Histogramm.
#3. Data-Mining-Techniken

Data-Mining-Techniken verwenden Datenklassifizierungs- und Clustering-Methoden, um Anomalien innerhalb eines Datensatzes aufzuspüren. Einige gängige Data-Mining-Techniken zur Anomalieerkennung umfassen spektrales Clustering, dichtebasiertes Clustering und Hauptkomponentenanalyse.
Clustering-Data-Mining-Algorithmen werden verwendet, um verschiedene Datenpunkte basierend auf ihrer Ähnlichkeit zu Clustern zu gruppieren und so Datenpunkte sowie Anomalien außerhalb dieser Cluster zu finden.
Klassifizierungsalgorithmen ordnen Datenpunkte hingegen bestimmten vordefinierten Klassen zu und identifizieren Datenpunkte, die nicht zu diesen Klassen gehören.
#4. Regelbasierte Techniken
Wie der Name schon sagt, verwenden regelbasierte Techniken zur Anomalieerkennung eine Reihe vordefinierter Regeln, um Anomalien in Daten zu identifizieren.
Diese Techniken sind vergleichsweise einfacher einzurichten, können jedoch unflexibel sein und sich möglicherweise nicht effizient an veränderliches Datenverhalten und -muster anpassen.
Beispielsweise können Sie ein regelbasiertes System einfach so programmieren, dass Transaktionen über einem bestimmten Geldbetrag als betrügerisch gekennzeichnet werden.
#5. Domänenspezifische Techniken
Domänenspezifische Techniken können zur Identifizierung von Anomalien in spezifischen Datensystemen eingesetzt werden. Sie können bei der Erkennung von Anomalien in bestimmten Domänen zwar sehr effizient sein, in anderen Domänen außerhalb des angegebenen Bereichs jedoch weniger wirksam.
Mit domänenspezifischen Techniken können Sie beispielsweise Techniken entwerfen, die speziell darauf ausgerichtet sind, Anomalien in Finanztransaktionen zu finden. Sie funktionieren jedoch möglicherweise nicht, um Anomalien oder Leistungseinbußen in einer Maschine zu entdecken.
Die Bedeutung des maschinellen Lernens für die Anomalieerkennung
Maschinelles Lernen ist bei der Erkennung von Anomalien äußerst wichtig und hilfreich.
Heutzutage müssen die meisten Unternehmen und Organisationen, die eine Ausreißererkennung benötigen, riesige Datenmengen verarbeiten, von Text, Kundeninformationen und Transaktionen bis hin zu Mediendateien wie Bildern und Videoinhalten.
Es ist praktisch unmöglich, alle Banktransaktionen und Daten, die jede Sekunde generiert werden, manuell zu analysieren, um aussagekräftige Erkenntnisse zu gewinnen. Darüber hinaus stehen viele Unternehmen vor großen Herausforderungen und Schwierigkeiten bei der Strukturierung unstrukturierter Daten und der sinnvollen Anordnung der Daten für die Datenanalyse.
Hier spielen Werkzeuge und Techniken wie maschinelles Lernen (ML) eine entscheidende Rolle bei der Sammlung, Bereinigung, Strukturierung, Organisation, Analyse und Speicherung großer Mengen unstrukturierter Daten.
Techniken und Algorithmen des maschinellen Lernens können große Datensätze verarbeiten und bieten die Flexibilität, verschiedene Techniken und Algorithmen zu nutzen und zu kombinieren, um optimale Ergebnisse zu erzielen.
Zusätzlich dazu trägt maschinelles Lernen dazu bei, die Prozesse der Anomalieerkennung für reale Anwendungen zu rationalisieren und wertvolle Ressourcen zu sparen.
Hier sind einige weitere Vorteile und die Bedeutung des maschinellen Lernens für die Anomalieerkennung:
- Es vereinfacht die Erkennung von Skalierungsanomalien durch die Automatisierung der Identifizierung von Mustern und Anomalien ohne die Notwendigkeit expliziter Programmierung.
- Algorithmen für maschinelles Lernen sind sehr anpassungsfähig an sich ändernde Datensatzmuster, wodurch sie mit der Zeit hochwirksam und robust sind.
- Sie verarbeiten mühelos große und komplexe Datensätze, wodurch die Anomalieerkennung auch bei komplexen Datensätzen effizient bleibt.
- Sie stellen durch die sofortige Erkennung von Anomalien eine frühe Identifizierung sicher, wodurch Zeit und Ressourcen gespart werden.
- Auf maschinellem Lernen basierende Anomalieerkennungssysteme erreichen eine höhere Genauigkeit bei der Anomalieerkennung als herkömmliche Methoden.
Die Anomalieerkennung in Kombination mit maschinellem Lernen trägt somit dazu bei, Anomalien schneller und früher zu identifizieren, um Sicherheitsbedrohungen und böswillige Angriffe zu verhindern.
Algorithmen des maschinellen Lernens zur Anomalieerkennung
Sie können Anomalien und Ausreißer in Daten mit Hilfe verschiedener Data-Mining-Algorithmen zum Klassifizieren, Clustern oder Erlernen von Assoziationsregeln identifizieren.
Diese Data-Mining-Algorithmen lassen sich in der Regel in zwei Kategorien einteilen: überwachte und unüberwachte Lernalgorithmen.
Überwachtes Lernen
Überwachtes Lernen ist eine gängige Art von Lernalgorithmen, zu denen Algorithmen wie Support Vector Machines, logistische und lineare Regression sowie Mehrklassenklassifizierung gehören. Diese Algorithmusart wird mit gekennzeichneten Daten trainiert. Das bedeutet, dass der Trainingsdatensatz sowohl normale Eingabedaten als auch die entsprechenden korrekten Ausgaben oder anomale Beispiele enthält, um ein Vorhersagemodell zu erstellen.
Ihr Ziel ist es daher, auf Grundlage der Muster des Trainingsdatensatzes Ausgabevorhersagen für ungesehene und neue Daten zu treffen. Zu den Anwendungen von überwachten Lernalgorithmen gehören Bild- und Spracherkennung, prädiktive Modellierung und Verarbeitung natürlicher Sprache (NLP).
Unbeaufsichtigtes Lernen
Unüberwachtes Lernen wird nicht mit gekennzeichneten Daten trainiert. Stattdessen deckt es komplizierte Prozesse und zugrunde liegende Datenstrukturen auf, ohne dem Trainingsalgorithmus eine Anleitung zu geben und anstatt spezifische Vorhersagen zu treffen.
Zu den Anwendungen unüberwachter Lernalgorithmen gehören Anomalieerkennung, Dichteschätzung und Datenkomprimierung.
Sehen wir uns nun einige beliebte Algorithmen zur Anomalieerkennung an, die auf maschinellem Lernen basieren.
Lokaler Ausreißerfaktor (LOF)
Local Outlier Factor oder LOF ist ein Anomalieerkennungsalgorithmus, der die lokale Datendichte berücksichtigt, um zu bestimmen, ob ein Datenpunkt eine Anomalie darstellt.
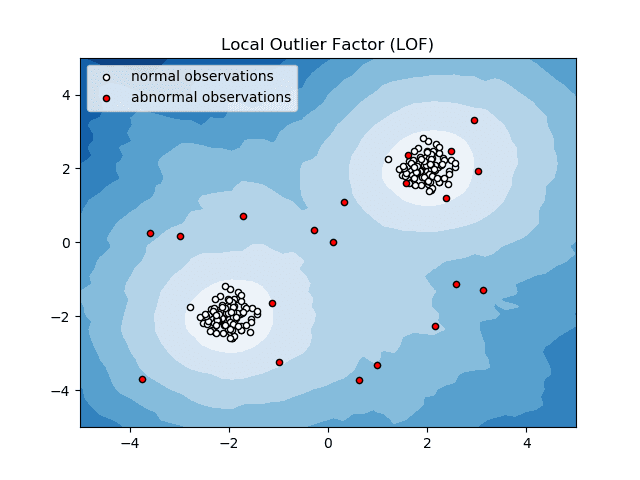
Quelle: scikit-learn.org
Er vergleicht die lokale Dichte eines Elements mit der lokalen Dichte seiner Nachbarn, um Bereiche mit ähnlicher Dichte und Elemente zu analysieren, deren Dichte vergleichsweise geringer ist als die ihrer Nachbarn – also Anomalien oder Ausreißer.
Vereinfacht ausgedrückt: Die Dichte um einen Ausreißer oder ein anomales Element unterscheidet sich von der Dichte um seine Nachbarn. Daher wird dieser Algorithmus auch als dichtebasierter Algorithmus zur Ausreißererkennung bezeichnet.
K-nächste Nachbarn (K-NN)
K-NN ist der einfachste Algorithmus zur Klassifizierung und überwachten Anomalieerkennung, der einfach zu implementieren ist. Er speichert alle verfügbaren Beispiele und Daten und klassifiziert neue Beispiele auf Grundlage der Ähnlichkeiten in den Distanzmetriken.
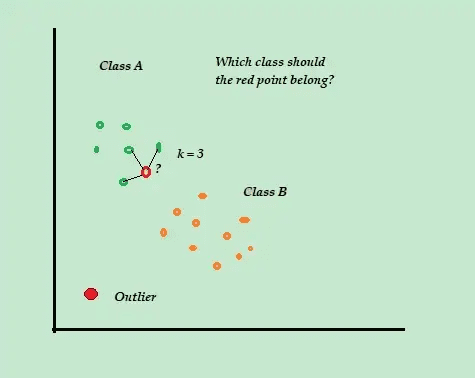
Quelle: Towarddatascience.com
Dieser Klassifizierungsalgorithmus wird auch als Lazy Learner bezeichnet, da er nur die markierten Trainingsdaten speichert – ohne während des Trainingsprozesses etwas anderes zu tun.
Wenn ein neuer, unbeschrifteter Trainingsdatenpunkt eintrifft, betrachtet der Algorithmus die K-nächstgelegenen oder die nächsten Trainingsdatenpunkte, um sie zur Klassifizierung und Bestimmung der Klasse des neuen unbeschrifteten Datenpunkts zu verwenden.
Der K-NN-Algorithmus verwendet die folgenden Erkennungsmethoden, um die nächstgelegenen Datenpunkte zu ermitteln:
- Euklidische Distanz zur Messung des Abstands für kontinuierliche Daten.
- Hamming-Distanz zur Messung der Nähe oder „Ähnlichkeit“ von zwei Textzeichenfolgen bei diskreten Daten.
Stellen Sie sich vor, Ihre Trainingsdatensätze bestehen aus zwei Klassenbezeichnungen, A und B. Wenn ein neuer Datenpunkt eintrifft, berechnet der Algorithmus die Entfernung zwischen dem neuen Datenpunkt und jedem der Datenpunkte im Datensatz und wählt die Punkte aus, die dem neuen Datenpunkt am nächsten liegen.
Angenommen, K=3 und 2 von 3 Datenpunkten sind als A gekennzeichnet, dann wird der neue Datenpunkt als Klasse A gekennzeichnet.
Daher eignet sich der K-NN-Algorithmus am besten für dynamische Umgebungen mit häufigen Datenaktualisierungsanforderungen.
Er ist ein beliebter Algorithmus für die Anomalieerkennung und das Text-Mining mit Anwendungen im Finanzwesen und in Unternehmen zur Aufdeckung betrügerischer Transaktionen und zur Erhöhung der Betrugserkennungsrate.
Support Vector Machine (SVM)
Support Vector Machine ist ein überwachter Anomalieerkennungsalgorithmus, der auf maschinellem Lernen basiert und hauptsächlich für Regressions- und Klassifizierungsprobleme verwendet wird.
Er verwendet eine mehrdimensionale Hyperebene, um Daten in zwei Gruppen (neu und normal) zu unterteilen. Somit fungiert die Hyperebene als Entscheidungsgrenze, die die normalen Datenbeobachtungen und die neuen Daten trennt.
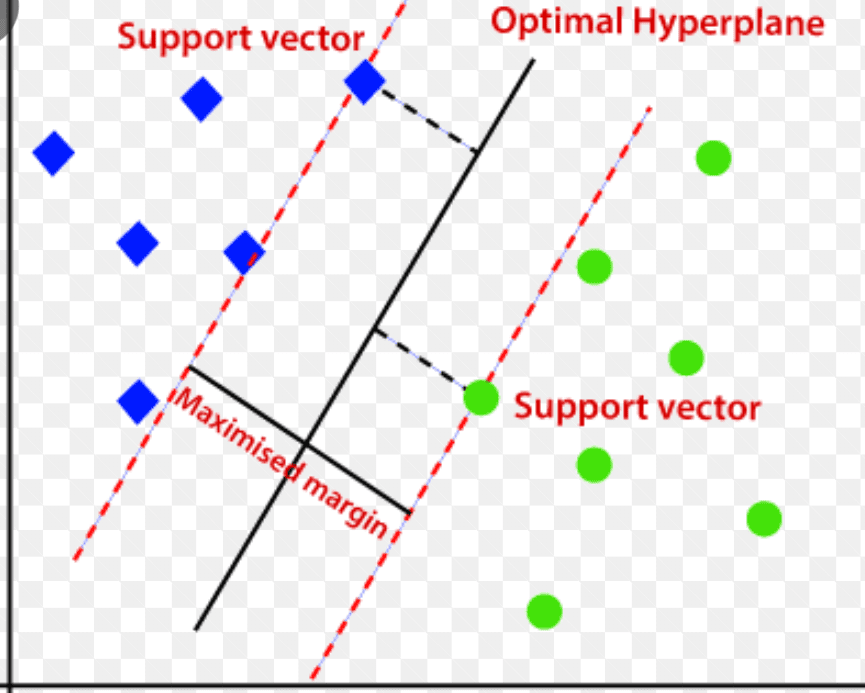
Quelle: www.analyticsvidhya.com
Der Abstand zwischen diesen beiden Datenpunkten wird als Rand bezeichnet.
Da das Ziel darin besteht, den Abstand zwischen den beiden Punkten zu vergrößern, bestimmt SVM die beste oder optimale Hyperebene mit dem maximalen Spielraum, um sicherzustellen, dass der Abstand zwischen den beiden Klassen so groß wie möglich ist.
Im Kontext der Anomalieerkennung berechnet SVM den Abstand der neuen Datenpunktbeobachtung von der Hyperebene, um sie zu klassifizieren.
Wenn die Spanne den festgelegten Schwellenwert überschreitet, wird die neue Beobachtung als Anomalie klassifiziert. Wenn die Spanne gleichzeitig unter dem Schwellenwert liegt, wird die Beobachtung als normal klassifiziert.
Somit sind die SVM-Algorithmen beim Umgang mit hochdimensionalen und komplexen Datensätzen hocheffizient.
Isolationswald
Isolation Forest ist ein unüberwachter Algorithmus zur Erkennung von Anomalien mit maschinellem Lernen, der auf dem Konzept eines Random-Forest-Klassifikators basiert.
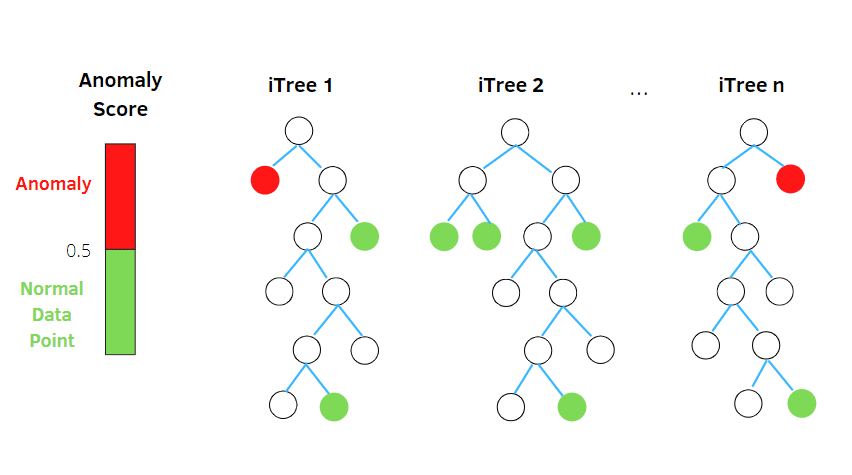
Quelle: betterprogramming.pub
Dieser Algorithmus verarbeitet zufällig unterabgetastete Daten im Datensatz in einer Baumstruktur basierend auf zufälligen Attributen. Es konstruiert mehrere Entscheidungsbäume, um Beobachtungen zu isolieren, und betrachtet eine bestimmte Beobachtung als Anomalie, wenn sie aufgrund ihrer Kontaminationsrate in weniger Bäumen isoliert wird.
Einfach ausgedrückt teilt der Isolation-Forest-Algorithmus also die Datenpunkte in verschiedene Entscheidungsbäume auf und stellt so sicher, dass jede Beobachtung von der anderen isoliert wird.
Anomalien liegen in der Regel abseits des Datenpunkt-Clusters, was es einfacher macht, die Anomalien im Vergleich zu den normalen Datenpunkten zu identifizieren.
Algorithmen für isolierte Gesamtstrukturen können problemlos mit kategorialen und numerischen Daten umgehen. Infolgedessen sind sie schneller zu trainieren und hocheffizient bei der Erkennung von Anomalien in hochdimensionalen und großen Datensätzen.
Bereich zwischen den Quartilen
Der Interquartilbereich oder IQR wird verwendet, um die statistische Variabilität oder Streuung zu messen, um anomale Punkte in den Datensätzen zu finden, indem diese in Quartile unterteilt werden.
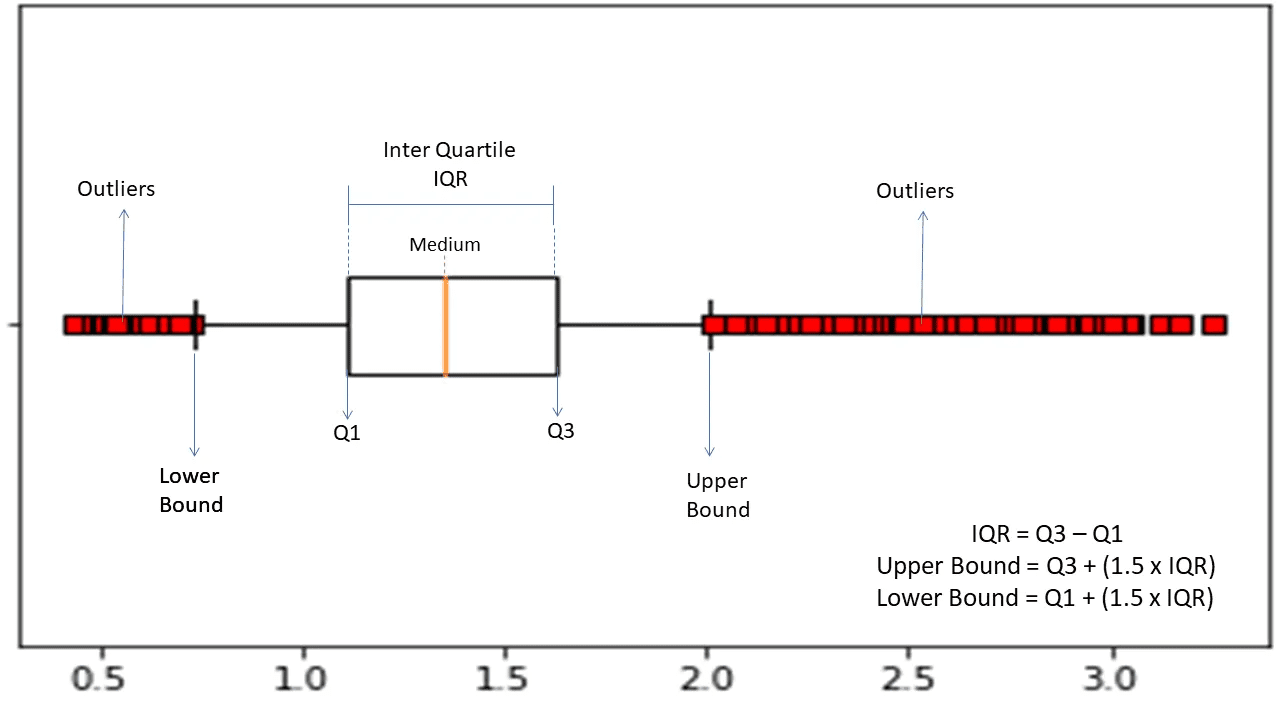
Quelle: morioh.com
Der Algorithmus sortiert die Daten in aufsteigender Reihenfolge und teilt die Menge in vier gleich große Teile. Die Werte, die diese Teile trennen, sind Q1, Q2 und Q3 – erstes, zweites und drittes Quartil.
Hier ist die Perzentilverteilung dieser Quartile:
- Q1 bezeichnet das 25. Perzentil der Daten.
- Q2 bezeichnet das 50. Perzentil der Daten.
- Q3 bezeichnet das 75. Perzentil der Daten.
IQR ist die Differenz zwischen dem dritten (75.) und dem ersten (25.) Perzentildatensatz, was 50 % der Daten entspricht.
Die Verwendung von IQR zur Erkennung von Anomalien erfordert, dass Sie den IQR Ihres Datensatzes berechnen und die unteren und oberen Grenzen der Daten definieren, um Anomalien zu finden.
- Untere Grenze: Q1 – 1,5 * IQR
- Obergrenze: Q3 + 1,5 * IQR
Typischerweise werden Beobachtungen, die außerhalb dieser Grenzen liegen, als Anomalien betrachtet.
Der IQR-Algorithmus ist wirksam für Datensätze mit ungleichmäßig verteilten Daten und bei denen die Verteilung nicht gut verstanden wird.
Abschließende Worte
Cybersicherheitsrisiken und Datenschutzverletzungen werden in den kommenden Jahren voraussichtlich nicht abnehmen – und dieser riskante Bereich wird voraussichtlich auch 2023 weiter wachsen, wobei sich die IoT-Cyberangriffe allein bis 2025 voraussichtlich verdoppeln werden.
Darüber hinaus werden Cyberverbrechen globale Unternehmen und Organisationen bis 2025 schätzungsweise 10,3 Billionen US-Dollar pro Jahr kosten.
Daher nimmt der Bedarf an Anomalieerkennungstechniken ständig zu und ist heute für die Betrugserkennung und die Verhinderung von Netzwerkeinbrüchen unerlässlich.
Dieser Artikel soll Ihnen helfen, zu verstehen, was Anomalien beim Data-Mining sind, welche Arten von Anomalien es gibt und wie Sie mithilfe von ML-basierten Anomalieerkennungstechniken Netzwerkangriffe verhindern können.
Als Nächstes können Sie sich über die Verwirrungsmatrix beim maschinellen Lernen informieren.