Kennen Sie das Hauptschema: Star vs. Snowflake
Ein mehrdimensionales Schema dient als Grundlage für den Aufbau von Data-Warehouse-Systemen. Es wurde speziell entwickelt, um die Anforderungen umfangreicher Datenbanken zu erfüllen, die für analytische Zwecke (OLAP) genutzt werden.
Diese Strukturierungsmethode ermöglicht eine übersichtliche Anordnung von Daten innerhalb einer Datenbank. Dadurch können Benutzer gezielte Fragen zu Geschäfts- und Marktentwicklungen stellen.
Darüber hinaus werden Daten durch ein mehrdimensionales Schema in Form von Datenwürfeln abgebildet. Diese Darstellung erlaubt es, Informationen aus verschiedenen Blickwinkeln und Dimensionen zu betrachten und zu modellieren.
Es existieren hauptsächlich drei Schemaarten, wobei die Unterscheidung zwischen Stern- und Schneeflockenschema oft Verwirrung stiftet und die Auswahl des geeigneten Modells erschwert.
Um diese Verwirrung aufzuklären, werden im Folgenden die Unterschiede zwischen dem Stern- und dem Schneeflockenschema detailliert erörtert. Dabei werden Definitionen, Vorteile, Herausforderungen, grafische Darstellungen und spezifische Merkmale berücksichtigt.
Was genau ist ein mehrdimensionales Schema?
Ein Schema beschreibt die logische Struktur einer gesamten Datenbank oder eines Data Marts. Es beinhaltet die Namen von Datensätzen sowie detaillierte Beschreibungen, einschließlich Aggregaten und zugehörigen Datenelementen.
Während Datenbanken meist ein relationales Modell verwenden, setzen Data-Warehouse-Systeme auf Schema-Modelle.
Mehrdimensionale Schemata können mithilfe der Data Mining Query Language (DMQL) definiert werden.
Zur Definition von Data Marts und Data Warehouses werden zwei Grundelemente genutzt: die Dimensionsdefinition und die Cube-Definition.
Das mehrdimensionale Schema bedient sich unterschiedlicher Modelltypen. Die wichtigsten sind:
- Sternschema
- Schneeflockenschema
- Galaxieschema
Im Folgenden werden die Stern- und Schneeflockenschemata genauer betrachtet.
Stern vs. Schneeflocke: Eine Gegenüberstellung
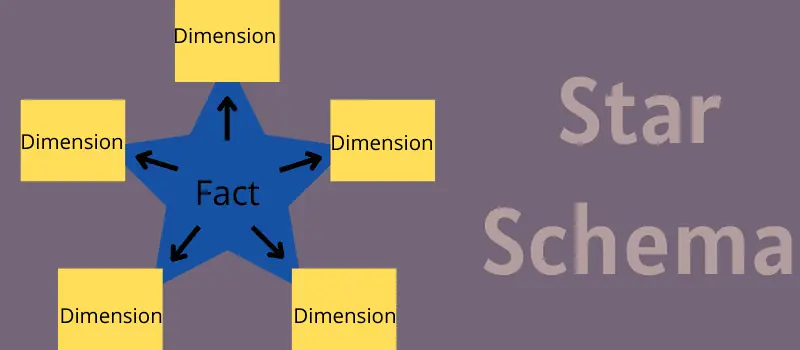
Das Sternschema im Detail
Das Sternschema ist ein Modell für Data Warehousing und Business Intelligence, das auf einer zentralen Faktentabelle zur Speicherung von Mess- und Transaktionsdaten basiert. Diese Tabelle ist mit mehreren kleineren Dimensionstabellen verbunden, die Attribute zu den Geschäftsdaten enthalten.
Die Bezeichnung „Sternschema“ rührt von der Anordnung der Tabellen her. Die Faktentabelle befindet sich im Zentrum, während die Dimensionstabellen wie Strahlen eines Sterns um sie herum angeordnet sind.
Jedes Sternschema besteht aus einer zentralen Faktentabelle und mehreren Dimensionstabellen. Die Faktentabelle enthält messbare, spezifische Daten, die analysiert werden sollen, beispielsweise Leistungsdaten, Finanzinformationen oder Verkaufsaufzeichnungen. Diese können einen Schnappschuss historischer Daten zu einem bestimmten Zeitpunkt oder Transaktionsdaten umfassen.
Das Sternschema gilt als das einfachste und grundlegendste der Data-Warehouse- und Data-Mart-Schemata. Es eignet sich gut für grundlegende Abfragen und unterstützt Business Intelligence, Ad-hoc-Abfragen, Analyseanwendungen sowie Online Analytical Processing (OLAP)-Würfel.
Darüber hinaus ermöglicht das Sternschema das Ausführen von Zählungen, Durchschnittsberechnungen, Summierungen und anderen Aggregationen über große Datenmengen. Benutzer können diese Aggregationen problemlos nach Dimensionen filtern und gruppieren. Beispiele hierfür sind Abfragen wie „Finde alle Verkaufsdaten im Juni“ oder „Analysiere den Gesamtumsatz von Büro XYZ im Jahr 2022“.
Das Schneeflockenschema unter der Lupe
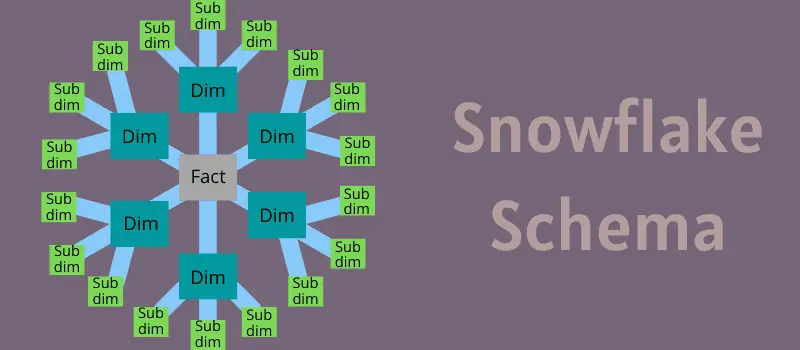
Das Schneeflockenschema ist ein mehrdimensionales Datenmodell, das als Erweiterung des Sternschemas betrachtet werden kann. Es unterscheidet sich dadurch, dass die Dimensionstabellen in Unterdimensionen aufgeteilt sind.
Ein Schema wird als Schneeflockenschema bezeichnet, wenn eine oder mehrere Dimensionstabellen nicht direkt mit der Faktentabelle verbunden sind, sondern über andere Dimensionstabellen verlinkt werden.
Diese Aufteilung, auch als „Snowflaking“ bekannt, normalisiert die Dimensionstabellen eines Sternschemas. Die resultierende Struktur, bei der eine Faktentabelle im Zentrum steht, ähnelt einer Schneeflocke.
Vereinfacht ausgedrückt besteht das Schneeflockenschema aus einer Faktentabelle, die mit Dimensionstabellen verbunden ist, welche wiederum mit weiteren Dimensionstabellen verknüpft sind. Dieses Schema zielt darauf ab, die Leistung von Abfragen zu optimieren.
Das Modell ist ideal für schnelle, flexible Abfragen komplexer Beziehungen und Dimensionen. Es eignet sich besonders für Eins-zu-viele- und Viele-zu-viele-Beziehungen zwischen verschiedenen Dimensionsebenen.
Durch die strikte Einhaltung von Normalisierungsstandards wird eine höhere Speichereffizienz erreicht. Allerdings kann die Performance im Vergleich zu denormalisierten Datenmodellen wie dem Sternschema geringer ausfallen, da Datenredundanz minimiert wird.
Stern vs. Schneeflocke: Die Funktionsweise
Funktionsweise des Sternschemas
Die zentrale Faktentabelle des Sternschemas speichert zwei Arten von Informationen: numerische Werte und Dimensionsattributwerte. Anhand eines Beispiels einer Verkaufsdatenbank werden diese Unterschiede verdeutlicht:
- Numerische Werte sind für jede Zeile und jeden Datenpunkt einzigartig. Sie stehen nicht in direkter Beziehung zu Daten anderer Zeilen. Diese Werte repräsentieren Fakten zu einer bestimmten Transaktion, wie z.B. Gesamtbetrag, Bestellmenge, exakte Uhrzeit, Nettogewinn oder Bestell-ID.
- Dimensionsattributwerte speichern keine direkten Daten, sondern Fremdschlüssel, die auf eine Zeile in einer Dimensionstabelle verweisen. Verschiedene Zeilen der Faktentabelle nutzen diese Informationen, wie z.B. das Datum, die Verkäufer-ID, die Filial-ID oder die Produkt-ID.
Dimensionstabellen speichern ergänzende Informationen zur Faktentabelle. Jede Dimensionstabelle bezieht sich auf eine Spalte der Faktentabelle und speichert zusätzliche Daten zu diesem Wert.
Beispiel: Die Mitarbeitertabelle verwendet die Mitarbeiter-ID als Schlüssel und enthält zusätzliche Informationen wie Name, Geschlecht, Adresse und Telefonnummer. Ebenso speichert eine Produkttabelle Informationen wie Produktname, Farbe, Datum der Markteinführung und Herstellungskosten.
Funktionsweise des Schneeflockenschemas
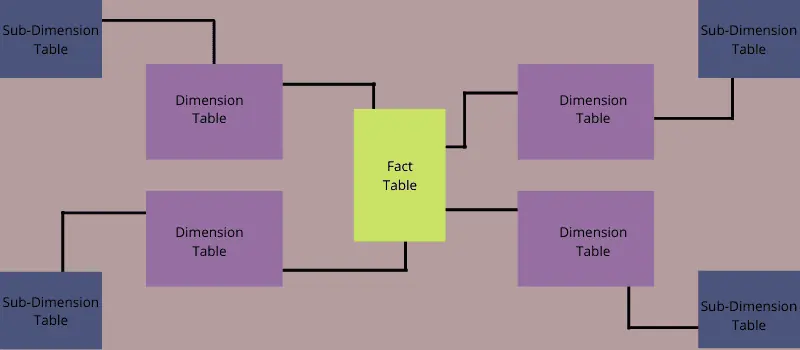
Das Schneeflockenschema ähnelt einer zentralen Box mit Verbindungen zu verschiedenen Punkten. Es wird verwendet, um Data Marts und Data Warehouses zu verwalten.
Im Vergleich zum Sternschema zeichnet sich das Schneeflockenschema durch erweiterte Unterdimensionstabellen aus, die mit den Dimensionstabellen verknüpft sind.
Das Hauptziel dieses Modells ist es, die denormalisierten Informationen des Sternschemas zu normalisieren, um häufige Probleme zu beheben.
Im Kern des Schemas steht eine Faktentabelle, die mit den Informationen in Dimensionstabellen verbunden ist. Diese Tabellen wiederum sind mit Unterdimensionstabellen verbunden, die detaillierte Informationen zu den Dimensionstabellen liefern.
Beispiel: Ein Schneeflockenschema enthält eine Verkaufsfaktentabelle sowie Tabellen für Geschäftsstandorte, Produktlinien, Produktfamilien, Produkte und Zeitdimensionen. Die Marktdimension besteht aus zwei Tabellen: der primären Geschäftstabelle und der Unterdimensionstabelle für den Standort. Die Produktdimension hat drei Unterdimensionstabellen, die Produkt-, Linien- und Familiendaten enthalten.
Stern vs. Schneeflocke: Eigenschaften im Detail
Eigenschaften des Sternschemas
- Das Sternschema kann Daten aus normalisierten Daten extrahieren, um Data-Warehousing-Anforderungen zu erfüllen. Ein eindeutiger Schlüssel wird für jede Faktentabelle generiert, um jede Zeile zu identifizieren.
- Es ermöglicht schnelle Berechnungen und Aggregationen, wie z.B. die erzielten Einnahmen oder die Anzahl der verkauften Artikel am Monatsende. Diese Details können nach Bedarf gefiltert werden.
- Das Schema basiert auf der Messung von Ereignissen mit numerischen Werten, die durch Fremdschlüssel referenziert werden. Es gibt verschiedene Arten von Faktentabellen, die atomare Werte speichern.
- Transaktionsfaktentabellen enthalten Daten zu spezifischen Ereignissen wie Verkäufen oder Feiertagen.
- Snapshot-Faktentabellen enthalten Daten über bestimmte Zeiträume, wie Kontostände am Jahresende oder Quartalszahlen.
- Dimensionstabellen enthalten detaillierte Informationen zu Attributen oder Datensätzen, die in der zentralen Tabelle zu finden sind.
- Benutzer können eigene Tabellen gemäß ihren Bedürfnissen entwerfen.
- Das Sternschema kann verwendet werden, um Snapshot-Tabellen zu sammeln.
Eigenschaften des Schneeflockenschemas
- Das Schneeflockenschema benötigt wenig Speicherplatz.
- Das Modell ist aufgrund der getrennten Haupt- und Unterdimensionstabellen einfach zu implementieren.
- Dimensionstabellen enthalten mindestens zwei Attribute, um Informationen in verschiedenen Granularitäten zu definieren.
- Die Performance ist aufgrund der höheren Anzahl an Tabellen geringer als beim Sternschema.
- Das Schneeflockenschema bietet durch die Normalisierung ein hohes Maß an Datenintegrität und geringe Redundanz.
Stern vs. Schneeflocke: Vorteile

Vorteile des Sternschemas
- Das Sternschema ist das einfachste der Data-Mart-Schemata.
- Es bietet eine einfache Berichtslogik, die dynamisch implementiert wird.
- Es wurde entwickelt, um mithilfe von Fütterungswürfeln, die im Online-Transaktionsprozess angewendet werden, effizient zu arbeiten.
- Das Sternschema verwendet einfache Logik und Abfragen, die sich leicht aus dem Transaktionsprozess extrahieren lassen.
- Es bietet eine verbesserte Performance für Berichtsanwendungen.
- Es ermöglicht die schnelle Wiederherstellung von Daten.
- Gefilterte und ausgewählte Informationen können in verschiedenen Fällen problemlos genutzt werden.
Vorteile des Schneeflockenschemas
- Das Schneeflockenschema verbessert die Abfrageleistung durch einen geringeren Bedarf an Festplattenspeicher.
- Es bietet eine höhere Skalierbarkeit in Bezug auf die Beziehungen zwischen Komponenten und Dimensionsebenen.
- Es ist einfacher zu pflegen.
- Das Schneeflockenschema ermöglicht einen schnellen Datenabruf.
- Es ist ein weit verbreitetes und einfaches Datenschema für Data Warehousing.
- Es trägt zur Verbesserung der Datenqualität bei.
- Die strukturierten Daten reduzieren das Problem der Datenintegrität.
Stern vs. Schneeflocke: Einschränkungen
Einschränkungen des Sternschemas
Das Sternschema ist stark denormalisiert und daher anfälliger für Datenintegritätsprobleme. Wenn die Daten nicht regelmäßig aktualisiert werden, kann der gesamte Prozess zusammenbrechen. Die Sicherheit und der Datenschutz sind ebenfalls begrenzt. Zudem ist das Sternschema weniger flexibel als analytische Modelle und bietet keine effiziente Unterstützung für unterschiedliche Beziehungen.
Einschränkungen des Schneeflockenschemas
Die Haupteinschränkung des Schneeflockenschemas liegt in dem zusätzlichen Wartungsaufwand, der durch die Vielzahl kleiner Dimensionstabellen entsteht. Komplexe Abfragen können die Suche nach den benötigten Daten erschweren. Darüber hinaus kann die Umsetzungszeit einer Anfrage aufgrund der höheren Anzahl an Tabellen länger dauern. Das Modell ist zudem starr und erfordert höhere Wartungskosten.
Stern vs. Schneeflocke: Unterschiede im Überblick
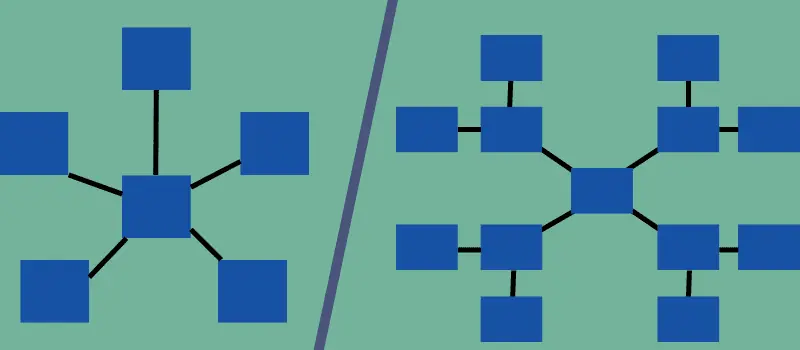
Stern- und Schneeflockenschema sind beides mehrdimensionale Schematypen, weisen jedoch unterschiedliche Strukturen und Eigenschaften auf. Das Sternschema erinnert an einen Stern, während das Schneeflockenschema an eine Schneeflocke ähnelt, worauf auch ihre Namen hindeuten.
Im Sternschema wird eine Beziehung zwischen der zentralen Faktentabelle und den Dimensionstabellen durch einen einzigen Join hergestellt. Im Schneeflockenschema sind hingegen mehrere Joins erforderlich, um eine Verbindung zu den Dimensionstabellen herzustellen.
Das Sternschema wird in der Regel eingesetzt, wenn die Dimensionstabellen weniger Zeilen haben, während das Schneeflockenschema bei größeren Dimensionstabellen Anwendung findet.
Die folgende Tabelle fasst die wichtigsten Unterschiede zwischen den beiden Modellen zusammen und veranschaulicht, wie die Dimensions- und Faktentabellen in den jeweiligen Schemata miteinander verknüpft sind.
| Parameter | Sternschema | Schneeflockenschema |
| Festplattenspeicherplatz | Das Sternschema benötigt mehr Speicherplatz. | Das Schneeflockenschema benötigt weniger Speicherplatz. |
| Datenredundanz | Hohe Datenredundanz. | Geringe Datenredundanz. |
| Normalisierung | Dimensionstabellen sind denormalisiert, d.h. gleiche Werte können innerhalb einer Tabelle wiederholt auftreten. | Dimensionstabellen sind vollständig normalisiert. |
| Abfrageleistung | Abfragen werden schnell ausgeführt, was zu einer besseren Leistung führt. | Abfragen dauern länger als beim Sternschema und sind somit weniger effizient. |
| Abfragekomplexität | Geringe Komplexität. | Höhere Komplexität als beim Sternschema. |
| Wartung | Aufgrund hoher Datenredundanz ist die Wartung etwas schwieriger. | Aufgrund geringer Datenredundanz ist die Wartung und Änderung einfacher. |
| Datenintegrität | Geringere Datenintegrität durch redundante Speicherung und Mehrfachkopien in den Dimensionstabellen. | Hohe Datenintegrität durch vollständige Normalisierung der Dimensionstabellen. |
| Hierarchien | Hierarchien werden in der Dimensionstabelle gespeichert. | Hierarchien sind auf separate Dimensionstabellen aufgeteilt. |
| DB-Design | Einfaches DB-Design. | Sehr komplexes DB-Design. |
| Faktentabelle | Mehrere Dimensionstabellen umgeben eine Faktentabelle. | Eine Faktentabelle ist von Dimensionstabellen und wiederum von Unterdimensionstabellen umgeben. |
| Einrichtung | Einfach zu entwerfen und einzurichten durch direkte Beziehungen. | Komplexere Einrichtung. |
| Cube-Verarbeitung | Schnellere Cube-Verarbeitung. | Etwas langsamere Cube-Verarbeitung durch komplexe Verbindungen. |
| Fremdschlüssel | Minimale Anzahl an Fremdschlüsseln. | Maximale Anzahl an Fremdschlüsseln. |
Fazit
Sowohl das Stern- als auch das Schneeflockenschema sind in verschiedenen Bereichen nützlich. Die Wahl des geeigneten Schemas hängt von den jeweiligen Anforderungen ab.
Das Schneeflockenschema ist eine Erweiterung des Sternschemas, bei der die Dimensionstabellen normalisiert werden.
Das Sternschema zeichnet sich durch ein einfaches Design, schnelle Abfragen und eine einfache Einrichtung aus. Das Schneeflockenschema ist hingegen einfacher zu warten, benötigt weniger Speicherplatz und ist weniger anfällig für Datenintegritätsprobleme.
Das Sternschema ist somit die bessere Wahl, wenn ein einfaches Design, weniger Fremdschlüssel und eine schnelle Cube-Verarbeitung benötigt werden. Wenn jedoch weniger Speicherplatz, geringe Datenredundanz und ein geringer Wartungsaufwand im Vordergrund stehen, kann das Schneeflockenschema die bessere Option sein.
Es ist auch ratsam, einige der besten Lösungen für Graphdatenbanken in Betracht zu ziehen.