Erzielen Sie bessere Ergebnisse mit den richtigen Datenbereinigungsstrategien [+5 Tools]
Sind Sie auf der Suche nach zuverlässigen und konsistenten Daten für Ihre Datenanalysen? Dann sollten Sie diese Strategien zur Datenbereinigung unverzüglich anwenden!
Ihre unternehmerischen Entscheidungen basieren maßgeblich auf Erkenntnissen aus der Datenanalyse. Die Qualität dieser Erkenntnisse, die Sie aus Ihren Datensätzen ziehen, hängt wiederum direkt von der Beschaffenheit der zugrunde liegenden Daten ab. Fehlerhafte, ungenaue, verunreinigte oder inkonsistente Daten stellen eine enorme Herausforderung für die Bereiche Data Science und Datenanalyse dar.
Aus diesem Grund haben Experten spezielle Methoden entwickelt: die Datenbereinigung. Sie schützt Ihr Unternehmen vor datengestützten Entscheidungen, die dem Unternehmen eher schaden als nützen.
Lesen Sie weiter, um mehr über die bewährten Datenbereinigungsstrategien zu erfahren, die von erfolgreichen Datenwissenschaftlern und Analysten eingesetzt werden. Wir zeigen Ihnen auch nützliche Tools, die Ihnen direkt saubere Daten für Ihre Data-Science-Projekte liefern können.
Was versteht man unter Datenbereinigung?
Die Datenqualität ist vielschichtig und lässt sich in fünf Dimensionen einteilen. Die Identifizierung und Korrektur von Fehlern in Ihren Eingabedaten unter Berücksichtigung der Richtlinien für Datenqualität wird als Datenbereinigung bezeichnet.
Diese fünf Dimensionen der Qualitätsparameter sind:
#1. Vollständigkeit
Dieser Parameter stellt sicher, dass die Daten alle notwendigen Angaben enthalten, wie zum Beispiel Kopfzeilen, Zeilen, Spalten und Tabellen, die für ein Data-Science-Projekt benötigt werden.
#2. Genauigkeit
Hier wird bewertet, ob die Daten den tatsächlichen Werten nahekommen. Die Daten sind dann als akkurat zu bezeichnen, wenn bei der Datenerhebung alle statistischen Standards eingehalten wurden.
#3. Gültigkeit
Dieser Parameter stellt sicher, dass die Daten mit den von Ihnen definierten Geschäftsregeln übereinstimmen.
#4. Einheitlichkeit
Dieser Aspekt prüft, ob die Daten ein einheitliches Format aufweisen. Beispielsweise sollten bei einer Erhebung zum Energieverbrauch in den USA alle Angaben in imperialen Einheiten vorliegen. Werden in derselben Erhebung an einigen Stellen metrische Einheiten verwendet, ist die Einheitlichkeit der Daten nicht gegeben.
#5. Konsistenz
Dieser Parameter stellt sicher, dass die Datenwerte über verschiedene Tabellen, Datenmodelle und Datensätze hinweg einheitlich sind. Diese Dimension ist insbesondere dann wichtig, wenn Sie Daten zwischen verschiedenen Systemen übertragen.
Zusammenfassend lässt sich sagen, dass die genannten Qualitätskontrollprozesse auf Ihre Rohdatensätze angewendet werden sollten, um die Daten zu bereinigen, bevor sie in ein Business-Intelligence-Tool eingespeist werden.
Warum ist Datenbereinigung so wichtig?
Ebenso wie Sie kein erfolgreiches Online-Geschäft mit einer schlechten Internetverbindung betreiben können, können Sie keine fundierten Entscheidungen treffen, wenn die Qualität Ihrer Daten unzureichend ist. Wenn Sie versuchen, Geschäftsentscheidungen auf der Grundlage fehlerhafter oder verunreinigter Daten zu treffen, werden Sie mit Umsatzverlusten oder einem schlechten Return on Investment (ROI) konfrontiert sein.
Einem Bericht von Gartner zufolge, der sich mit den Folgen schlechter Datenqualität auseinandersetzt, beläuft sich der durchschnittliche Verlust eines Unternehmens auf 12,9 Millionen US-Dollar. Dieser Verlust entsteht allein durch Entscheidungen, die auf fehlerhaften und ungenauen Daten basieren.
Derselbe Bericht zeigt, dass der US-Wirtschaft durch die Verwendung schlechter Daten jährlich ein Verlust von unglaublichen 3 Billionen US-Dollar entsteht.
Die Schlussfolgerung ist klar: Wenn Sie ein BI-System mit minderwertigen Daten füttern, werden auch die Ergebnisse unbrauchbar sein.
Um finanzielle Verluste zu vermeiden und effektive Geschäftsentscheidungen auf Grundlage von Datenanalysen zu treffen, ist es daher unerlässlich, Ihre Rohdaten vorab zu bereinigen.
Welche Vorteile bietet die Datenbereinigung?
#1. Vermeidung von finanziellen Verlusten
Durch die Bereinigung Ihrer Eingabedaten schützen Sie Ihr Unternehmen vor finanziellen Verlusten, die durch Verstöße gegen Compliance-Regeln oder den Verlust von Kunden entstehen können.
#2. Fundierte Entscheidungen treffen

Hochwertige und relevante Daten liefern wertvolle Erkenntnisse. Diese Erkenntnisse ermöglichen es Ihnen, fundierte Entscheidungen in Bereichen wie Produktmarketing, Vertrieb, Bestandsmanagement und Preisgestaltung zu treffen.
#3. Wettbewerbsvorteile sichern
Indem Sie frühzeitig auf Datenbereinigung setzen, können Sie sich einen Vorteil gegenüber Ihren Wettbewerbern verschaffen und sich als Vorreiter in Ihrer Branche positionieren.
#4. Projekteffizienz steigern
Ein optimierter Datenbereinigungsprozess stärkt das Vertrauen der Teammitglieder. Da die Daten als zuverlässig gelten, können sie sich stärker auf die Datenanalyse konzentrieren.
#5. Ressourcen sparen
Durch das Bereinigen und Ausdünnen von Daten wird die Größe der gesamten Datenbank reduziert. So schaffen Sie Speicherplatz, indem Sie unnötige Daten entfernen.
Strategien zur Datenbereinigung
Standardisierung visueller Daten
Ein Datensatz enthält in der Regel unterschiedliche Zeichen, wie Texte, Zahlen und Symbole. Sie müssen alle Texte mit einem einheitlichen Format für die Groß- und Kleinschreibung versehen. Stellen Sie außerdem sicher, dass die Symbole die richtige Kodierung aufweisen (z.B. Unicode, ASCII).
Beispielsweise steht der großgeschriebene Begriff „Bill“ für einen Personennamen, während eine „Rechnung“ eine Transaktionsquittung ist. Die korrekte Formatierung der Groß- und Kleinschreibung ist daher essenziell.
Entfernung von Duplikaten
Doppelte Daten stören das BI-System und verfälschen die Muster. Deshalb ist es wichtig, doppelte Einträge aus der Eingabedatenbank zu entfernen.
Duplikate entstehen oft durch manuelle Dateneingabeprozesse. Durch die Automatisierung der Rohdateneingabe können Sie Datenreplikationen von Grund auf vermeiden.
Korrektur unerwünschter Ausreißer
Ausreißer sind Datenpunkte, die sich außerhalb des üblichen Datenmusters befinden. Echte Ausreißer sind hilfreich, da sie Datenwissenschaftlern bei der Aufdeckung von Fehlern in Umfragen helfen können. Ausreißer, die durch menschliches Versagen entstanden sind, sind dagegen problematisch.
Sie sollten Datensätze in Diagrammen oder Grafiken visualisieren, um nach Ausreißern zu suchen. Wenn Sie welche finden, untersuchen Sie die Quelle. Liegt ein menschlicher Fehler vor, sollten Sie die Ausreißer entfernen.
Fokus auf strukturierte Daten
Hier geht es hauptsächlich darum, Fehler in Datensätzen zu finden und zu beheben.
Ein Datensatz kann beispielsweise eine Spalte in US-Dollar (USD) enthalten, sowie zahlreiche Spalten in anderen Währungen. Wenn Ihre Daten für ein US-amerikanisches Publikum bestimmt sind, sollten Sie alle anderen Währungen in USD umrechnen. Ersetzen Sie dann alle anderen Währungsangaben durch USD.
Datenscan
Eine umfangreiche Datenbank, die aus einem Data Warehouse heruntergeladen wurde, kann Tausende von Tabellen umfassen. Für Ihr Data-Science-Projekt benötigen Sie wahrscheinlich nicht alle Tabellen.
Nachdem Sie eine Datenbank erhalten haben, müssen Sie ein Skript entwickeln, um die benötigten Tabellen zu lokalisieren. Sind diese identifiziert, können Sie irrelevante Tabellen entfernen und die Größe des Datensatzes reduzieren.
Dies führt letztendlich zu einer schnelleren Erkennung von Datenmustern.
Datenbereinigung in der Cloud
Wenn Ihre Datenbank den „Schema-on-Write“-Ansatz verwendet, sollten Sie sie in „Schema-on-Read“ umwandeln. Dies ermöglicht es, die Daten direkt im Cloud-Speicher zu bereinigen und formatierte, strukturierte und analysereife Daten zu extrahieren.
Übersetzung von Fremdsprachen
Wenn Sie eine weltweite Umfrage durchführen, werden Sie in den Rohdaten mit fremdsprachigen Inhalten konfrontiert werden. Sie müssen alle Zeilen und Spalten, die Fremdsprachen enthalten, ins Deutsche oder eine andere bevorzugte Sprache übersetzen. Hierfür können computergestützte Übersetzungstools (CAT) genutzt werden.
Datenbereinigung Schritt für Schritt
#1. Identifizierung wichtiger Datenfelder
Ein Data Warehouse enthält Terabytes an Datenbanken. Jede Datenbank kann einige bis hin zu Tausenden von Datenspalten umfassen. Sie müssen nun das Projektziel betrachten und entsprechende Daten aus diesen Datenbanken extrahieren.
Wenn Ihr Projekt beispielsweise E-Commerce-Einkaufstrends von deutschen Bürgern untersucht, ist es nicht sinnvoll, Daten zu Offline-Einzelhandelsgeschäften im selben Arbeitsblatt zu erfassen.
#2. Daten strukturieren

Sobald Sie die wichtigen Datenfelder, Spaltenüberschriften und Tabellen aus einer Datenbank ermittelt haben, sollten Sie diese strukturiert zusammenführen.
#3. Duplikate entfernen
Rohdaten aus Data Warehouses enthalten häufig doppelte Einträge. Sie müssen diese Duplikate identifizieren und löschen.
#4. Entfernung von Leerwerten und Leerzeichen
Manche Spaltenüberschriften oder entsprechende Datenfelder können keine Werte enthalten. Sie müssen diese Spaltenüberschriften/Felder entfernen oder leere Werte durch geeignete alphanumerische Werte ersetzen.
#5. Feinformattierung durchführen
Datensätze können unnötige Leerzeichen, Symbole oder Zeichen enthalten. Diese sollten Sie mit Formatierungsfunktionen entfernen, um ein einheitliches Erscheinungsbild hinsichtlich Zellengröße und -spanne zu erzielen.
#6. Prozess standardisieren
Sie sollten eine Standardarbeitsanweisung (SOP) erstellen, anhand derer die Mitglieder des Data-Science-Teams bei der Datenbereinigung vorgehen können. Diese sollte Folgendes umfassen:
- Frequenz der Rohdatenerfassung
- Verantwortliche für Rohdatenspeicherung und -wartung
- Frequenz der Datenbereinigung
- Verantwortliche für saubere Datenspeicherung und -wartung
Hier sind einige gängige Tools, die Sie bei der Datenbereinigung unterstützen können:
WinPure

Wenn Sie nach einer Lösung suchen, mit der Sie Daten präzise und schnell bereinigen können, ist WinPure eine zuverlässige Wahl. Dieses branchenführende Tool bietet eine Datenbereinigungsfunktion für Unternehmen mit herausragender Geschwindigkeit und Präzision.
Es ist sowohl für einzelne Nutzer als auch für Unternehmen konzipiert und daher einfach zu bedienen. Die Software nutzt eine erweiterte Datenprofilierungsfunktion, um Typen, Formate, Integrität und Werte von Daten auf ihre Qualität hin zu analysieren. Die leistungsstarke Matching-Engine findet perfekte Übereinstimmungen mit minimalen Fehlzuordnungen.
WinPure bietet darüber hinaus aussagekräftige Grafiken für alle Daten sowie Gruppenspiele und Nicht-Spiele.
Es fungiert auch als Zusammenführungstool, das doppelte Datensätze zu einem Hauptdatensatz zusammenführt und die jeweils aktuellen Werte beibehält. Darüber hinaus können Sie in diesem Tool Regeln für die Auswahl von Hauptdaten definieren und alle Datensätze sofort entfernen.
OpenRefine
OpenRefine ist ein kostenloses Open-Source-Tool, mit dem Sie Ihre unstrukturierten Daten in ein sauberes Format konvertieren können, das für Webdienste verwendet werden kann. Es nutzt Facetten, um große Datensätze zu bereinigen und arbeitet mit gefilterten Ansichten.
Mithilfe von leistungsstarken Heuristiken kann das Tool ähnliche Werte zusammenführen, um alle Inkonsistenzen zu beseitigen. Es bietet Abgleichsdienste, sodass Benutzer ihre Datensätze mit externen Datenbanken abgleichen können. Zudem können Sie mit diesem Tool bei Bedarf zu älteren Datensatzversionen zurückkehren.
Außerdem können Nutzer die Operationshistorie in einer aktualisierten Version wiederholen. OpenRefine ist eine gute Wahl, wenn Sie Bedenken hinsichtlich der Datensicherheit haben. Ihre Daten werden auf Ihrem Computer bereinigt, wodurch eine Datenmigration in die Cloud entfällt.
Trifacta Designer Cloud

Die Datenbereinigung kann komplex sein, aber Trifacta Designer Cloud erleichtert Ihnen den Prozess. Es verwendet einen neuen Ansatz zur Datenaufbereitung, damit Unternehmen einen maximalen Nutzen daraus ziehen können.
Die benutzerfreundliche Oberfläche ermöglicht es auch technisch weniger versierten Benutzern, Daten für anspruchsvolle Analysen zu bereinigen und aufzubereiten. Unternehmen können jetzt mehr aus ihren Daten machen, indem sie die von Trifacta Designer Cloud bereitgestellten intelligenten Vorschläge auf Basis von ML nutzen.
Zudem müssen sie weniger Zeit in diesen Prozess investieren und dabei weniger Fehler machen. Durch die Reduzierung des Ressourcenverbrauchs können Sie mehr aus der Datenanalyse herausholen.
Cloudingo
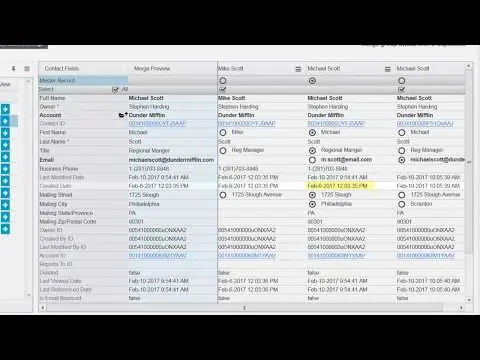
Sind Sie als Salesforce-Nutzer besorgt über die Qualität Ihrer gesammelten Daten? Verwenden Sie Cloudingo, um Ihre Kundendaten zu bereinigen und nur die wirklich notwendigen Informationen zu behalten. Diese Anwendung vereinfacht die Verwaltung von Kundendaten mit Funktionen wie Deduplizierung, Import und Migration.
Sie können hier die Zusammenführung von Datensätzen mit anpassbaren Filtern und Regeln steuern und die Daten standardisieren. Entfernen Sie unnötige und inaktive Daten, aktualisieren Sie fehlende Datenpunkte und stellen Sie die Korrektheit von US-Postadressen sicher.
Darüber hinaus können Unternehmen Cloudingo so planen, dass Daten automatisch dedupliziert werden, sodass Sie jederzeit Zugriff auf saubere Daten haben. Die Datensynchronisation mit Salesforce ist ein weiteres wichtiges Feature dieses Tools. Damit können Sie sogar Salesforce-Daten mit Informationen in einer Tabelle vergleichen.
ZoomInfo
ZoomInfo ist ein Anbieter von Datenbereinigungslösungen, der zur Produktivität und Effektivität Ihres Teams beiträgt. Unternehmen können eine höhere Rentabilität erzielen, da diese Software deduplizierte Daten an CRM- und MAT-Systeme des Unternehmens liefert.
Es vereinfacht das Datenqualitätsmanagement, indem es alle kostspieligen doppelten Daten entfernt. Benutzer können auch ihren CRM- und MAT-Perimeter mit ZoomInfo sichern. Die Software kann Daten innerhalb weniger Minuten mit automatischer Deduplizierung, Abgleich und Normalisierung bereinigen.
Nutzer dieser Anwendung genießen Flexibilität und Kontrolle über die Übereinstimmungskriterien und zusammengeführten Ergebnisse. ZoomInfo hilft Ihnen, ein kostengünstiges Datenspeichersystem aufzubauen, indem es alle Datentypen standardisiert.
Abschließende Worte
Sie sollten die Qualität Ihrer Eingabedaten in Ihren Data-Science-Projekten nicht vernachlässigen. Sie bilden die Grundlage für wichtige Projekte wie Machine Learning (ML), neuronale Netze für KI-basierte Automatisierung usw. Wenn die Datenbasis fehlerhaft ist, sollten Sie sich über die möglichen Konsequenzen solcher Projekte im Klaren sein.
Daher muss Ihr Unternehmen eine bewährte Datenbereinigungsstrategie entwickeln und diese als Standardarbeitsanweisung (SOP) implementieren. Dies wird die Qualität der Eingabedaten nachhaltig verbessern.
Wenn Sie durch Projekte, Marketing und Vertrieb ausreichend beschäftigt sind, ist es ratsam, die Datenbereinigung den Experten zu überlassen. Diese Experten können entweder interne Mitarbeiter oder eines der oben genannten Datenbereinigungstools sein.
Möglicherweise ist für Sie auch ein Service-Blueprint-Diagramm von Interesse, das Ihnen die Implementierung von Datenbereinigungsstrategien erleichtert.