Eine freundliche Einführung in die Datenanalyse in Python
Einführung in die Datenanalyse mit Python und Pandas
Die Popularität von Python im Bereich der Datenwissenschaft hat in den letzten Jahren bemerkenswert zugenommen und setzt ihr stetiges Wachstum fort.
Die Datenwissenschaft ist ein umfangreiches Fachgebiet mit zahlreichen Teilbereichen. Die Datenanalyse ist unbestreitbar einer der wichtigsten. Unabhängig vom jeweiligen Kenntnisstand im Bereich der Datenwissenschaft wird ein Verständnis der Grundlagen immer wichtiger.
Was genau ist Datenanalyse?
Datenanalyse bezeichnet den Prozess der Bereinigung und Umwandlung großer Mengen unstrukturierter oder ungeordneter Daten. Ziel ist es, wertvolle Erkenntnisse und Informationen aus diesen Daten zu gewinnen, die als Grundlage für fundierte Entscheidungen dienen können.
Es gibt eine Vielzahl von Tools für die Datenanalyse, darunter Python, Microsoft Excel, Tableau und SaS. In diesem Artikel liegt unser Schwerpunkt jedoch auf der Durchführung von Datenanalysen mit Python, insbesondere mit der Python-Bibliothek Pandas.
Was ist Pandas?
Pandas ist eine Open-Source-Python-Bibliothek, die sich hervorragend für die Datenmanipulation und -aufbereitung eignet. Sie zeichnet sich durch hohe Geschwindigkeit und Effizienz aus und bietet Tools zum Laden verschiedener Datentypen in den Speicher. Pandas kann zur Umgestaltung, Beschriftung, Indizierung und sogar Gruppierung verschiedenster Datenformate verwendet werden.
Datenstrukturen in Pandas
Pandas bietet drei wesentliche Datenstrukturen:
Die Unterscheidung dieser Strukturen kann man sich am besten so vorstellen, dass eine Struktur mehrere Stapel der jeweils anderen enthält. Ein DataFrame ist also ein Stapel von Serien und ein Panel ist ein Stapel von DataFrames.
- Eine Serie ist ein eindimensionales Array.
- Ein Stapel mehrerer Serien bildet einen zweidimensionalen DataFrame.
- Ein Stapel mehrerer DataFrames resultiert in einem dreidimensionalen Panel.
Die am häufigsten verwendete Datenstruktur ist der zweidimensionale DataFrame, der auch die Standarddarstellung für viele Datensätze ist.
Datenanalyse mit Pandas
Für diesen Artikel ist keine lokale Installation erforderlich. Wir verwenden ein Tool namens Colab, das von Google entwickelt wurde. Es handelt sich um eine Cloud-basierte Python-Umgebung für Datenanalyse, maschinelles Lernen und künstliche Intelligenz. Colab ist ein cloudbasiertes Jupyter-Notebook, das mit fast allen Python-Paketen vorinstalliert ist, die ein Datenwissenschaftler benötigt.
Gehen Sie nun zu https://colab.research.google.com/notebooks/intro.ipynb. Sie sollten die folgende Ansicht erhalten:
Klicken Sie in der linken oberen Navigationsleiste auf "Datei" und wählen Sie dann "Neues Notebook". Daraufhin wird eine neue Jupyter-Notebook-Seite in Ihrem Browser geladen. Zunächst müssen wir Pandas in unsere Arbeitsumgebung importieren. Dies geschieht mit folgendem Code:
import pandas as pdFür diesen Artikel verwenden wir einen Datensatz mit Immobilienpreisen für unsere Datenanalyse. Der verwendete Datensatz ist hier zu finden. Als Erstes laden wir den Datensatz in unsere Umgebung.
Das erledigen wir mit dem folgenden Code in einer neuen Zelle:
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media&token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0', sep=',')Die Funktion .read_csv wird zum Einlesen von CSV-Dateien verwendet. Wir übergeben die sep-Eigenschaft, um anzugeben, dass die CSV-Datei durch Kommas getrennt ist.
Beachten Sie außerdem, dass unsere geladene CSV-Datei in einer Variablen namens df gespeichert wird.
Wir müssen die print()-Funktion in Jupyter Notebook nicht verwenden. Wir können einfach einen Variablennamen in unsere Zelle eingeben, und Jupyter Notebook gibt diesen aus.
Wir können dies testen, indem wir df in eine neue Zelle eingeben und ausführen. Jupyter wird alle Daten in unserem Datensatz als DataFrame ausgeben.
Wir möchten aber nicht immer alle Daten sehen. Manchmal interessieren uns nur die ersten paar Zeilen und ihre Spaltennamen. Wir können die Funktion df.head() verwenden, um die ersten fünf Zeilen auszugeben, und df.tail(), um die letzten fünf Zeilen anzuzeigen. Die Ausgaben sehen so aus:
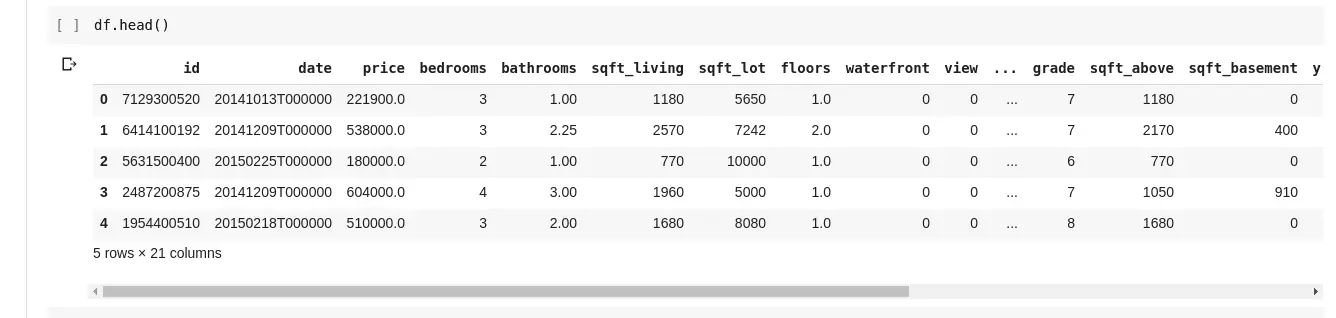
Wir wollen die Beziehungen zwischen verschiedenen Datenzeilen und -spalten untersuchen. Die Funktion .describe() tut genau das.
Die Ausführung von df.describe() ergibt die folgende Ausgabe:
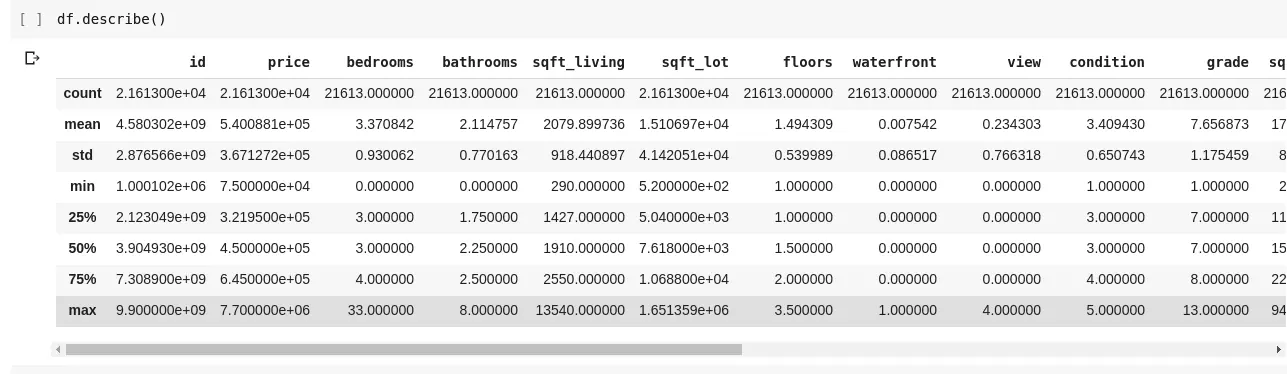
Wie wir sehen, gibt .describe() den Mittelwert, die Standardabweichung, die Minimal- und Maximalwerte sowie die Perzentile jeder Spalte im DataFrame an. Dies ist besonders nützlich.
Wir können auch die Form unseres 2D-DataFrames überprüfen, um zu sehen, wie viele Zeilen und Spalten er hat. Dies geschieht mit df.shape, das ein Tupel im Format (Zeilen, Spalten) zurückgibt.
Die Namen aller Spalten in unserem DataFrame können wir mit df.columns prüfen.
Was passiert, wenn wir nur eine Spalte auswählen und alle darin enthaltenen Daten zurückgeben wollen? Dies funktioniert ähnlich wie bei einem Wörterbuch. Geben Sie den folgenden Code in eine neue Zelle ein und führen Sie ihn aus:
df['price ']Der obige Code gibt die Spalte "price" zurück. Wir können dies weiterverfolgen, indem wir sie als solche in einer neuen Variable speichern:
price = df['price']Nun können wir jede andere Operation ausführen, die mit einem DataFrame für unsere Preisvariable möglich ist, da es sich nur um eine Teilmenge eines tatsächlichen DataFrames handelt. Wir können Aktionen wie df.head(), df.shape() usw. durchführen.
Wir können auch mehrere Spalten auswählen, indem wir eine Liste von Spaltennamen an df übergeben:
data = df[['price ', 'bedrooms']]Der obige Code wählt die Spalten "price" und "bedrooms" aus. Wenn wir data.head() in einer neuen Zelle eingeben, erhalten wir Folgendes:

Die oben genannte Methode zum Auswählen von Spalten gibt alle Zeilenelemente in dieser Spalte zurück. Was ist, wenn wir eine Teilmenge von Zeilen und Spalten aus unserem Datensatz zurückgeben wollen? Dies kann mit .iloc geschehen und wird ähnlich wie bei Python-Listen indiziert. Wir können also Folgendes tun:
df.iloc[50: , 3]Dies gibt die dritte Spalte von der 50. Zeile bis zum Ende zurück. Es ist relativ einfach und funktioniert wie das Slicing von Listen in Python.
Lassen Sie uns nun einige wirklich interessante Dinge tun. Unser Datensatz mit den Hauspreisen enthält eine Spalte, die den Preis eines Hauses angibt, und eine weitere Spalte, die die Anzahl der Schlafzimmer angibt, die dieses bestimmte Haus hat. Der Hauspreis ist ein kontinuierlicher Wert, daher ist es möglich, dass wir nicht zwei Häuser mit dem gleichen Preis haben. Die Anzahl der Schlafzimmer ist jedoch diskret, so dass wir mehrere Häuser mit zwei, drei, vier usw. Schlafzimmern haben können.
Was ist, wenn wir alle Häuser mit der gleichen Anzahl von Schlafzimmern finden und den Durchschnittspreis für jede einzelne Schlafzimmeranzahl ermitteln wollen? Mit Pandas ist das relativ einfach. Es geht so:
df.groupby('bedrooms ')['price '].mean()Der obige Code gruppiert den DataFrame zuerst nach den Datensätzen mit identischer Schlafzimmeranzahl mit der Funktion df.groupby(). Dann wird angewiesen, uns nur die Spalte der Schlafzimmer zu geben, und mit der Funktion .mean() wird der Durchschnitt jedes Hauses im Datensatz ermittelt.
Was ist, wenn wir das Obige visualisieren wollen? Wir wollen überprüfen können, wie der Durchschnittspreis für jede einzelne Schlafzimmeranzahl variiert. Wir müssen den vorherigen Code nur mit einer Funktion .plot() verknüpfen:
df.groupby('bedrooms ')['price '].mean().plot()Wir erhalten eine Ausgabe, die so aussieht:
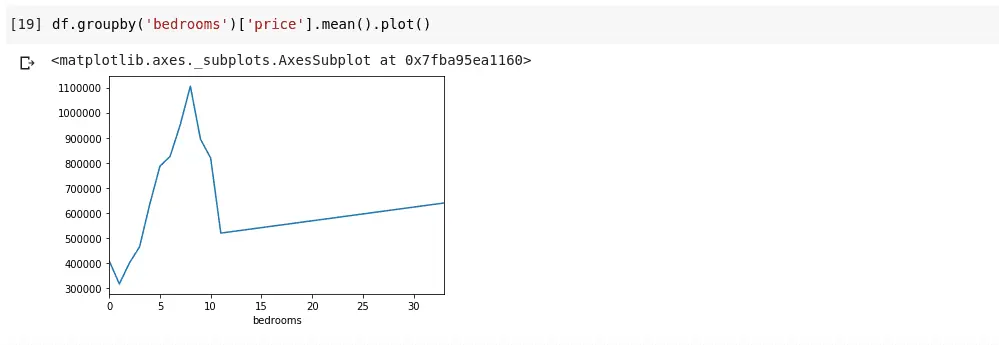
Das Obige zeigt uns einige Trends in den Daten. Auf der horizontalen Achse haben wir eine bestimmte Anzahl von Schlafzimmern (beachten Sie, dass mehr als ein Haus X Schlafzimmer haben kann). Auf der vertikalen Achse haben wir den Durchschnittspreis bezogen auf die entsprechende Anzahl von Schlafzimmern auf der horizontalen Achse. Wir können jetzt sofort erkennen, dass Häuser mit 5 bis 10 Schlafzimmern viel mehr kosten als Häuser mit 3 Schlafzimmern. Es wird auch deutlich, dass Häuser mit etwa 7 oder 8 Schlafzimmern viel mehr kosten als solche mit 15, 20 oder sogar 30 Zimmern.
Informationen wie die oben genannten sind der Grund, warum die Datenanalyse so wichtig ist. Wir können nützliche Erkenntnisse aus den Daten gewinnen, die ohne eine Analyse nicht sofort oder gar nicht erkennbar sind.
Fehlende Daten
Nehmen wir an, ich nehme an einer Umfrage teil, die aus einer Reihe von Fragen besteht. Ich teile einen Link zur Umfrage mit Tausenden von Menschen, damit sie ihr Feedback geben können. Mein eigentliches Ziel ist es, eine Datenanalyse für diese Daten durchzuführen, um einige wertvolle Erkenntnisse zu gewinnen.
Nun kann viel schiefgehen. Einige Umfrageteilnehmer könnten sich unwohl fühlen, einige meiner Fragen zu beantworten, und sie leer lassen. Viele Leute könnten bei einigen Fragen meiner Umfrage dasselbe tun. Dies ist vielleicht kein Problem, aber stellen Sie sich vor, ich würde in meiner Umfrage numerische Daten sammeln und ein Teil der Analyse würde erfordern, dass ich entweder die Summe, den Durchschnitt oder eine andere arithmetische Operation erhalte. Mehrere fehlende Werte würden zu vielen Ungenauigkeiten in meiner Analyse führen. Ich muss einen Weg finden, diese fehlenden Werte zu finden und durch einige Werte zu ersetzen, die ihnen möglichst ähnlich sind.
Pandas stellt uns eine Funktion zur Verfügung, um fehlende Werte in einem DataFrame zu finden: isnull().
Die Funktion isnull() kann folgendermaßen verwendet werden:
df.isnull()Dies gibt einen DataFrame mit booleschen Werten zurück, der uns mitteilt, ob die ursprünglich vorhandenen Daten wirklich fehlten oder fälschlicherweise fehlten. Die Ausgabe würde so aussehen:
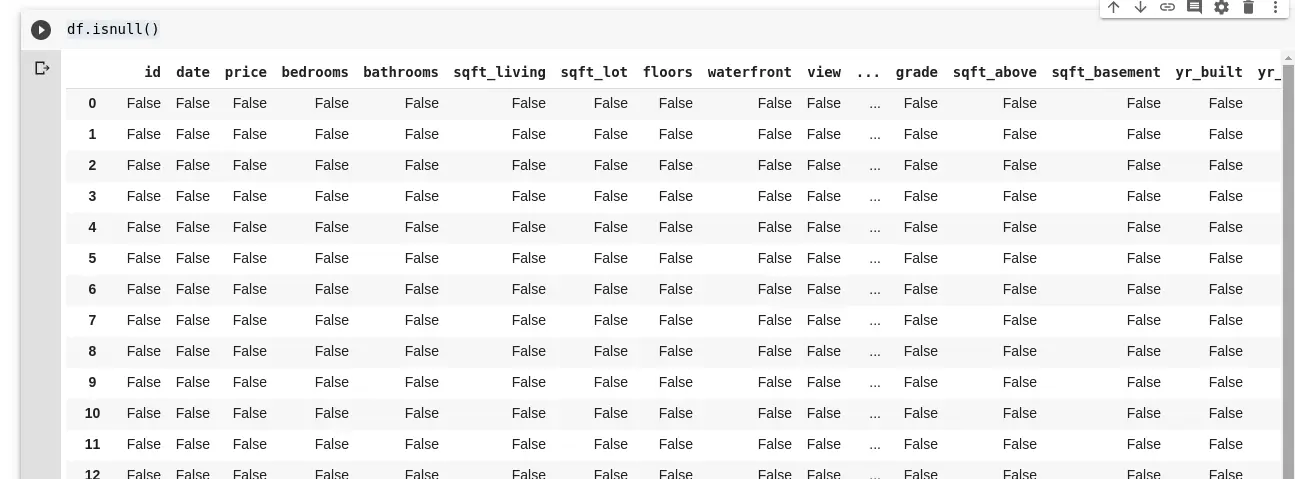
Wir brauchen eine Methode, um all diese fehlenden Werte zu ersetzen. Meistens wird angenommen, dass fehlende Werte null sind. Manchmal können sie als Mittelwert aller anderen Daten genommen werden oder auch als Mittelwert der Daten in der Nähe, je nach dem Datenwissenschaftler und dem Anwendungsfall der analysierten Daten.
Um alle fehlenden Werte in einem DataFrame zu füllen, verwenden wir die Funktion .fillna() wie folgt:
df.fillna(0)Im obigen Code füllen wir alle leeren Daten mit dem Wert Null. Es könnte auch jede andere Zahl angegeben werden.
Die Bedeutung von Daten kann gar nicht genug betont werden. Sie helfen uns, Antworten direkt aus unseren Daten selbst zu erhalten. Es wird gesagt, dass Datenanalyse das neue Öl für digitale Volkswirtschaften ist.
Alle Beispiele in diesem Artikel sind hier zu finden.
Wenn Sie mehr erfahren möchten, besuchen Sie diesen Online-Kurs zur Datenanalyse mit Python und Pandas.
