Eine Einführung in MapReduce in Big Data
MapReduce repräsentiert eine effiziente, beschleunigte und kostengünstigere Herangehensweise zur Entwicklung von Anwendungen.
Dieses Paradigma profitiert von fortschrittlichen Konzepten wie Parallelverarbeitung und Datenlokalität und bietet damit Programmierern und Organisationen vielfältige Vorzüge.
Angesichts der Fülle an Programmiermodellen und Frameworks auf dem Markt gestaltet sich die Auswahl jedoch als herausfordernd.
Speziell im Umgang mit Big Data sind Kompromisse unangebracht. Die Wahl muss auf Technologien fallen, die massive Datenmengen handhaben können.
Hierbei erweist sich MapReduce als exzellente Lösung.
Im Folgenden werde ich die Kernaspekte von MapReduce beleuchten und dessen Nutzen erläutern.
Beginnen wir!
Was ist MapReduce?
MapReduce ist ein Programmiermodell oder ein Software-Framework, das innerhalb des Apache Hadoop-Ökosystems angesiedelt ist. Es dient der Erstellung von Anwendungen, die in der Lage sind, gewaltige Datenmengen parallel auf Tausenden von Knoten (sogenannten Clustern oder Grids) mit Fehlertoleranz und Zuverlässigkeit zu verarbeiten.
Diese Datenverarbeitung geschieht in einer Datenbank oder einem Dateisystem, wo die Daten hinterlegt sind. MapReduce ist kompatibel mit dem Hadoop Distributed File System (HDFS) und kann somit große Datenmengen adressieren und verwalten.
Dieses Framework wurde 2004 von Google initiiert und durch Apache Hadoop populär gemacht. Es fungiert als Verarbeitungsebene oder Engine in Hadoop, auf der MapReduce-Programme ausgeführt werden, die in einer Vielzahl von Sprachen wie Java, C++, Python und Ruby verfasst wurden.
MapReduce-Programme im Cloud-Computing operieren parallel und sind damit ideal für die Durchführung umfangreicher Datenanalysen.
Das Ziel von MapReduce ist die Aufteilung einer Aufgabe in kleinere, handhabbare Teilaufgaben mithilfe der Funktionen „map“ und „reduce“. Es weist jede Aufgabe zu und reduziert sie anschließend auf mehrere, äquivalente Aufgaben, was eine Reduzierung der Verarbeitungszeit und des Overheads im Cluster-Netzwerk bewirkt.
Ein Beispiel: Stellen Sie sich vor, Sie bereiten eine Mahlzeit für viele Gäste zu. Wenn Sie versuchen, alle Gerichte selbst zuzubereiten und jeden einzelnen Schritt zu übernehmen, wird dies hektisch und zeitaufwendig.
Wenn Sie nun einige Freunde oder Kollegen (nicht die Gäste) zur Hilfe rufen und die einzelnen Aufgaben aufteilen, damit jeder gleichzeitig arbeiten kann, wird die Essenszubereitung viel schneller und unkomplizierter. Ihre Gäste werden nicht lange auf ihr Essen warten müssen.
MapReduce funktioniert analog, indem es Aufgaben verteilt und parallel verarbeitet, um eine zügigere und einfachere Methode zur Erledigung einer bestimmten Aufgabe zu ermöglichen.
Mithilfe von Apache Hadoop können Programmierer MapReduce nutzen, um Modelle auf umfangreichen, verteilten Datensätzen auszuführen und anspruchsvolle Techniken des maschinellen Lernens und der Statistik anzuwenden, um Muster zu identifizieren, Vorhersagen zu treffen und Korrelationen aufzudecken.
Funktionsweisen von MapReduce
Einige der Kernfunktionen von MapReduce umfassen:
- Benutzeroberfläche: Eine intuitive Benutzeroberfläche bietet detaillierte Informationen zu jedem Aspekt des Frameworks. Dies erleichtert das Konfigurieren, Anwenden und Optimieren von Aufgaben.
- Payload: Anwendungen nutzen Mapper- und Reducer-Schnittstellen, um die Map- und Reduce-Funktionen zu aktivieren. Der Mapper konvertiert eingegebene Schlüssel-Wert-Paare in Zwischen-Schlüssel-Wert-Paare. Der Reducer reduziert Zwischen-Schlüssel-Wert-Paare mit gleichem Schlüssel auf kleinere Werte. Es werden drei Funktionen ausgeführt: Sortieren, Mischen und Reduzieren.
- Partitionierer: Dieser steuert die Aufteilung der Zwischenausgabe-Schlüssel der Karten.
- Reporter: Diese Funktion dient zur Fortschrittsberichterstattung, Aktualisierung von Zählern und Festlegung von Statusmeldungen.
- Zähler: Hier werden globale Zähler dargestellt, die von einer MapReduce-Anwendung definiert wurden.
- OutputCollector: Diese Funktion sammelt Ausgabedaten von Mapper oder Reducer, nicht Zwischenausgaben.
- RecordWriter: Dieser schreibt die Datenausgabe oder Schlüssel-Wert-Paare in die Ausgabedatei.
- DistributedCache: Dieser verteilt effizient größere, schreibgeschützte Dateien, die anwendungsspezifisch sind.
- Datenkomprimierung: Der Anwendungsentwickler kann sowohl Job-Ausgaben als auch Zwischen-Karten-Ausgaben komprimieren.
- Überspringen fehlerhafter Datensätze: Das Überspringen fehlerhafter Datensätze ist bei der Bearbeitung von Karten-Eingaben möglich. Diese Funktion kann über die Klasse SkipBadRecords gesteuert werden.
- Debugging: Es besteht die Möglichkeit, benutzerdefinierte Skripte auszuführen und das Debugging zu aktivieren. Bei einem Fehler in MapReduce kann das Debug-Skript ausgeführt werden, um die Probleme zu lokalisieren.
MapReduce-Architektur
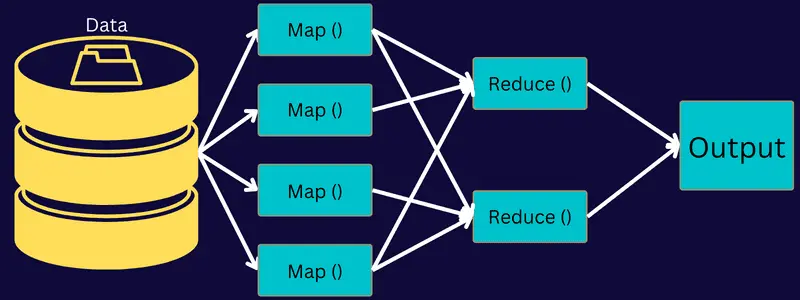
Betrachten wir die Architektur von MapReduce und gehen dabei auf die einzelnen Komponenten ein:
- Job: Ein Job in MapReduce ist die eigentliche Aufgabe, die der MapReduce-Client ausführen möchte. Er setzt sich aus mehreren Teilaufgaben zusammen, die gemeinsam die Endaufgabe formen.
- Job History Server: Dies ist ein Daemon-Prozess, der alle Verlaufsdaten zu einer Anwendung oder Aufgabe speichert, z. B. Protokolle, die vor oder nach der Ausführung eines Jobs generiert wurden.
- Client: Ein Client (Programm oder API) gibt MapReduce einen Auftrag zur Ausführung oder Verarbeitung. Ein oder mehrere Clients können kontinuierlich Aufträge zur Verarbeitung an den MapReduce Manager senden.
- MapReduce Master: Ein MapReduce Master teilt einen Job in mehrere kleinere Einheiten auf, um eine gleichzeitige Abarbeitung der Aufgaben sicherzustellen.
- Job-Teile: Die Teil-Jobs entstehen durch die Zerlegung des Hauptjobs. Sie werden bearbeitet und schlussendlich kombiniert, um die Endergebnisse zu erzielen.
- Eingabedaten: Dies ist der Datensatz, den MapReduce zur Verarbeitung von Aufgaben erhält.
- Ausgabedaten: Das Endergebnis, das nach der Bearbeitung der Aufgabe vorliegt.
Der Prozess in dieser Architektur sieht vor, dass ein Client einen Auftrag an den MapReduce Master sendet, der diesen dann in kleinere, gleichwertige Teile zerlegt. Dadurch kann der Auftrag beschleunigt verarbeitet werden, da kleinere Aufgaben weniger Bearbeitungszeit benötigen als umfangreiche Aufgaben.
Achten Sie darauf, dass die Aufgaben nicht in zu kleine Einheiten aufgeteilt werden, da dies zu einem höheren Verwaltungsaufwand führen und unnötig Zeit kosten kann.
Die Job-Teile werden zur Bearbeitung mit den Aufgaben „Map“ und „Reduce“ freigegeben. Die Map- und Reduce-Aufgaben nutzen ein passendes Programm, das an den jeweiligen Anwendungsfall angepasst ist. Der Programmierer entwickelt den logikbasierten Code, der die Anforderungen erfüllt.
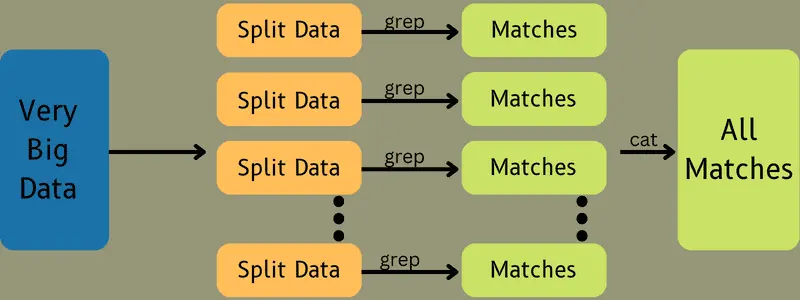
Anschließend werden die Eingabedaten der Map-Aufgabe übergeben, damit diese zügig die Ausgabe als Schlüssel-Wert-Paar generieren kann. Anstatt diese Daten im HDFS zu speichern, wird eine lokale Festplatte genutzt, um eine Replikation auszuschließen.
Sobald die Aufgabe erledigt ist, kann die Ausgabe verworfen werden. Eine Replikation wäre hier überflüssig. Die Ausgabe jeder Map-Aufgabe wird der Reduce-Aufgabe zugeführt, und die Map-Ausgabe wird der Maschine bereitgestellt, die die Reduce-Aufgabe ausführt.
Die Ausgaben werden dann zusammengeführt und der benutzerdefinierten Reduce-Funktion übergeben. Die reduzierte Ausgabe wird anschließend auf dem HDFS gespeichert.
Der gesamte Prozess kann je nach Zielsetzung mehrere Map- und Reduce-Aufgaben für die Datenverarbeitung beinhalten. Die Map- und Reduce-Algorithmen sind so optimiert, dass die zeitliche und räumliche Komplexität minimiert wird.
Da MapReduce hauptsächlich auf Map- und Reduce-Aufgaben basiert, ist es wichtig, diese näher zu verstehen. Betrachten wir daher die Phasen von MapReduce, um einen besseren Einblick zu bekommen.
Phasen von MapReduce
Map
In dieser Phase werden die Eingabedaten den Ausgabe- oder Schlüssel-Wert-Paaren zugewiesen. Der Schlüssel kann sich auf die ID einer Adresse beziehen, während der Wert der eigentliche Inhalt dieser Adresse ist.
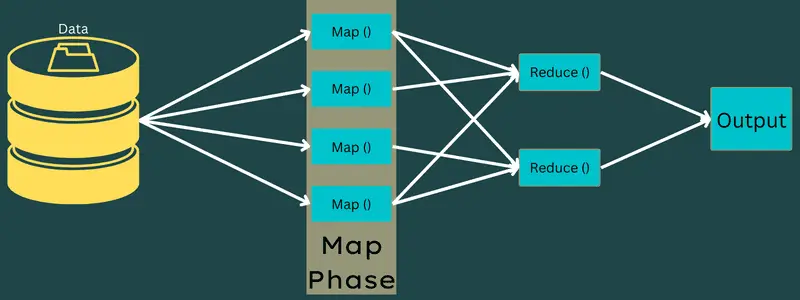
Diese Phase beinhaltet nicht nur eine Aufgabe, sondern zwei: Splits und Mapping. Splits bezieht sich auf die vom Hauptjob abgeteilten Neben- oder Auftragsteile. Diese werden auch Input-Splits genannt. Ein Input-Split kann als Input-Chunk bezeichnet werden, der von einer Map konsumiert wird.
Anschließend folgt die Mapping-Aufgabe. Sie gilt als erste Phase bei der Ausführung eines Map-Reduce-Programms. Hier werden die Daten, die in jeder Teilung enthalten sind, an eine Zuordnungsfunktion weitergegeben, um die Ausgabe zu verarbeiten und zu generieren.
Die Funktion – Map() wird auf den eingegebenen Schlüssel-Wert-Paaren ausgeführt und generiert ein Zwischen-Schlüssel-Wert-Paar. Dieses neue Schlüssel-Wert-Paar dient als Eingabe für die Funktion Reduce() oder Reducer.
Reduce
Die in der Mapping-Phase generierten Zwischen-Schlüssel-Wert-Paare dienen als Eingabe für die Reduce-Funktion oder den Reducer. Ähnlich der Mapping-Phase sind hier zwei Aufgaben beteiligt: Mischen und Reduzieren.
Die erhaltenen Schlüssel-Wert-Paare werden sortiert und gemischt, um dem Reducer zugeführt zu werden. Der Reducer gruppiert oder aggregiert die Daten gemäß ihrem Schlüssel-Wert-Paar basierend auf dem vom Entwickler erstellten Reducer-Algorithmus.
Die Werte aus der Mischphase werden kombiniert, um einen Ausgabewert zurückzugeben. Diese Phase fasst den gesamten Datensatz zusammen.
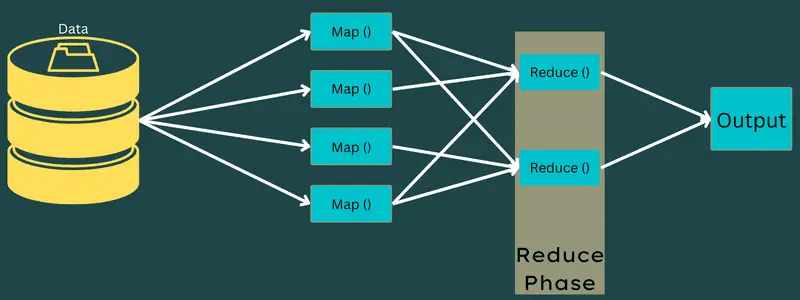
Der gesamte Prozess der Ausführung von Map- und Reduce-Aufgaben wird von bestimmten Entitäten gesteuert. Diese sind:
- Job Tracker: Der Job Tracker fungiert als Master, der für die vollständige Ausführung eines übermittelten Jobs verantwortlich ist. Er verwaltet alle Jobs und Ressourcen innerhalb eines Clusters. Der Job Tracker plant jede Map, die dem Task Tracker zugeordnet wird und auf einem bestimmten Datenknoten ausgeführt wird.
- Mehrere Task Tracker: Task Tracker fungieren als Sklaven, die Aufgaben gemäß den Anweisungen des Job Trackers ausführen. Ein Task Tracker wird auf jedem Knoten im Cluster bereitgestellt und führt dort die Map- und Reduce-Tasks aus.
Die Aufteilung eines Jobs in mehrere Tasks, die auf unterschiedlichen Datenknoten eines Clusters ausgeführt werden, ermöglicht diese Arbeitsweise. Der Job Tracker koordiniert die Aufgaben, indem er sie plant und auf den verschiedenen Datenknoten ausführt. Der Task Tracker, der sich auf jedem Datenknoten befindet, übernimmt die Ausführung der Job-Teile und kümmert sich um jede Aufgabe.
Zusätzlich senden die Task Tracker Fortschrittsberichte an den Job Tracker. Sie senden auch regelmäßig ein „Heartbeat“-Signal, um den Job Tracker über ihren Systemstatus zu informieren. Im Falle eines Fehlers kann der Job Tracker den Job auf einem anderen Task Tracker neu planen.
Ausgabephase: In dieser Phase werden die finalen Schlüssel-Wert-Paare vom Reducer generiert. Ein Ausgabeformatierer kann verwendet werden, um die Schlüssel-Wert-Paare zu übersetzen und sie mithilfe eines Record Writers in eine Datei zu schreiben.
Warum MapReduce nutzen?
Im Folgenden sind einige der Vorteile von MapReduce aufgeführt, die die Gründe für die Verwendung in Big-Data-Anwendungen veranschaulichen:
Parallelverarbeitung

Ein Auftrag kann auf verschiedene Knoten aufgeteilt werden, wobei jeder Knoten gleichzeitig einen Teil des Auftrags in MapReduce bearbeitet. Die Aufteilung großer Aufgaben in kleinere reduziert die Komplexität. Da verschiedene Tasks parallel auf unterschiedlichen Maschinen statt auf einer einzigen Maschine laufen, wird die Verarbeitungszeit deutlich verkürzt.
Datenlokalität
MapReduce ermöglicht es, die Verarbeitungseinheit zu den Daten zu verschieben, nicht umgekehrt.
Früher wurden die Daten zur Verarbeitungseinheit gebracht. Mit dem rasanten Datenwachstum führte dieser Prozess jedoch zu einer Reihe von Herausforderungen. Dazu gehörten höhere Kosten, höherer Zeitaufwand, Belastung des Masterknotens, häufige Ausfälle und eine geringere Netzwerkleistung.
MapReduce löst diese Probleme durch einen umgekehrten Ansatz – die Verarbeitungseinheit wird zu den Daten gebracht. Die Daten werden auf verschiedene Knoten verteilt, wobei jeder Knoten einen Teil der gespeicherten Daten verarbeiten kann.
Dadurch wird eine Kosteneffizienz und eine Reduzierung der Verarbeitungszeit erreicht, da jeder Knoten parallel mit seinem entsprechenden Datenteil arbeitet. Da jeder Knoten nur einen Teil der Daten verarbeitet, wird kein Knoten überlastet.
Sicherheit

Das MapReduce-Modell bietet ein hohes Maß an Sicherheit, schützt die Anwendung vor unautorisierten Zugriffen und erhöht die Clustersicherheit.
Skalierbarkeit und Flexibilität
MapReduce ist ein hochskalierbares Framework. Es erlaubt die Ausführung von Anwendungen auf mehreren Rechnern und die Verarbeitung von Daten mit Tausenden von Terabyte. Es bietet auch die Flexibilität, strukturierte, halbstrukturierte oder unstrukturierte Daten in beliebiger Form oder Größe zu verarbeiten.
Einfachheit
MapReduce-Programme können in verschiedenen Programmiersprachen wie Java, R, Perl, Python usw. geschrieben werden. Dies macht das Lernen und Schreiben von Programmen einfach und ermöglicht es, die eigenen Datenverarbeitungsanforderungen zu erfüllen.
Anwendungsfälle von MapReduce
- Volltextindizierung: MapReduce wird zur Durchführung einer Volltextindizierung verwendet. Der Mapper kann jedes Wort oder jeden Satz in einem einzelnen Dokument abbilden. Der Reducer wird verwendet, um alle abgebildeten Elemente in einen Index zu schreiben.
- Berechnung des Pageranks: Google verwendet MapReduce zur Berechnung des Pageranks.
- Protokollanalyse: MapReduce kann Protokolldateien analysieren. Es kann eine große Protokolldatei in verschiedene Teile oder Splits zerlegen, während der Mapper nach aufgerufenen Webseiten sucht.
Ein Schlüssel-Wert-Paar wird an den Reducer übergeben, sobald eine Webseite im Protokoll entdeckt wird. Hier ist die Webseite der Schlüssel und der Index "1" der Wert. Nach Übergabe des Schlüssel-Wert-Paars an den Reducer werden verschiedene Webseiten aggregiert. Die finale Ausgabe ist die Gesamtzahl der Treffer für jede Webseite.

- Reverse Web-Link Graph: Das Framework wird auch in Reverse Web-Link Graphs eingesetzt. Hier liefert Map() das URL-Ziel und die Quelle und empfängt Eingaben von der Quelle oder Webseite.
Reduce() aggregiert im Anschluss die Liste jeder Quell-URL, die der Ziel-URL zugeordnet ist. Schließlich werden die Quellen und das Ziel ausgegeben.
- Wortzählung: MapReduce wird verwendet, um zu zählen, wie oft ein Wort in einem bestimmten Dokument vorkommt.
- Globale Erwärmung: Organisationen, Regierungen und Unternehmen können MapReduce nutzen, um Probleme im Zusammenhang mit der globalen Erwärmung zu lösen.
Beispielsweise könnte man Daten zur Erhöhung der Meerestemperatur aufgrund der globalen Erwärmung erforschen. Hierfür können Tausende von Datensätzen aus der ganzen Welt gesammelt werden. Die Daten können hohe Temperatur, niedrige Temperatur, Breite, Länge, Datum, Uhrzeit usw. umfassen. Dies erfordert mehrere Map- und Reduce-Aufgaben, um die Ausgabe mit MapReduce zu berechnen.
- Arzneimittelstudien: Traditionell arbeiteten Datenwissenschaftler und Mathematiker zusammen, um ein neues Medikament gegen eine Krankheit zu entwickeln. Mit dem Aufkommen von Algorithmen und MapReduce können IT-Abteilungen in Organisationen problemlos Probleme lösen, die zuvor von Supercomputern, Ph.D. Wissenschaftlern usw. bearbeitet wurden. Nun kann die Wirksamkeit eines Medikaments für eine Patientengruppe untersucht werden.
- Weitere Anwendungen: MapReduce kann sogar gewaltige Datenmengen verarbeiten, die normalerweise nicht in eine relationale Datenbank passen würden. Es nutzt auch Data-Science-Tools und ermöglicht deren Ausführung über unterschiedliche, verteilte Datensätze, was vorher nur auf einem einzelnen Computer möglich war.
Aufgrund seiner Robustheit und Einfachheit findet MapReduce in Militär, Wirtschaft und Wissenschaft Anwendung.
Fazit
MapReduce erweist sich als technologischer Durchbruch. Es ist nicht nur ein schneller und einfacher Prozess, sondern auch kostengünstiger und weniger zeitaufwendig. Angesichts der Vorteile und zunehmenden Nutzung wird es voraussichtlich eine stärkere Akzeptanz in Branchen und Organisationen erfahren.
Zusätzlich können Sie sich über die besten Ressourcen zum Thema Big Data und Hadoop informieren.