Disaster Recovery-Terminologien verstehen – RTO, RPO, Failover, BCP und mehr
Die Bedeutung eines Disaster-Recovery-Plans
Ein Disaster-Recovery-Plan ist eine unerlässliche Maßnahme für jede Organisation, um sich auf unerwartete Ereignisse vorzubereiten. In der IT-Branche beginnt dies mit der Erstellung eines formellen Dokuments, das detaillierte Pläne, Maßnahmen und Verfahren für den Umgang mit Katastrophen und deren Folgen beschreibt.
Eine Katastrophe ist ein plötzliches, unvorhergesehenes Ereignis verschiedenster Art. Sie kann erhebliche Schwierigkeiten für Einzelpersonen und Organisationen verursachen, einschließlich finanzieller Verluste und negativer Auswirkungen auf die Benutzererfahrung.
Bei einem Notfall ist es entscheidend, die Auswirkungen zu minimieren und den Betrieb so schnell wie möglich wiederherzustellen. Ein praktischer Disaster-Recovery-Plan hilft dabei, die Katastrophe einzudämmen oder zu verhindern und die negativen Folgen in Bezug auf Benutzererfahrung, Kosten und Ausfallzeiten zu reduzieren.
Darüber hinaus müssen Pläne, Mitarbeiter, Strategien, Geräte und Systeme bereitstehen, um den Betrieb wieder aufzunehmen. Ein umfassendes Verständnis von Disaster Recovery ist hierfür unerlässlich.
Im Folgenden werden wir die wichtigsten Disaster-Recovery-Terminologien im Detail erläutern, um Ihnen zu helfen, sich effektiv zu schützen und gestärkt aus solchen schwierigen Situationen hervorzugehen.
Was versteht man unter einer Katastrophe?
Eine Katastrophe ist ein unvorhersehbares Ereignis, das jederzeit und überall auftreten kann, auch in der IT-Branche. Sie kann durch natürliche Ursachen oder menschliches Handeln entstehen und den Betriebsablauf eines Unternehmens sowie die gesamte Infrastruktur stören.
Solche Ereignisse wirken sich auf die Organisation selbst, ihre Kunden, Lieferanten, Mitarbeiter und Partner aus. Sie setzen die Organisation unter Druck in Bezug auf Finanzen, Reputation, Kundenvertrauen und Sicherheit.
Deshalb ist eine rechtzeitige Vorbereitung auf solche Szenarien unerlässlich. Dies erfordert die Fähigkeit, alle Abläufe und Daten schnell wiederherzustellen, um den Kunden eine rasche Wiederherstellung des Betriebs zu gewährleisten.
Es gibt viele Arten von Katastrophen, darunter Cyberangriffe, Sabotage, Terroranschläge, Ransomware, physische Bedrohungen, Wirbelstürme, Erdbeben, Brände, Überschwemmungen, Industrieunfälle und Stromausfälle.
Was bedeutet Notfallwiederherstellung?
Notfallwiederherstellung (Disaster Recovery) bezeichnet den Prozess der Wiederherstellung des normalen Betriebs nach einer Katastrophe. Dazu gehört die Wiederherstellung des Zugriffs auf Hardware, Software, Geräte, Konnektivität, Netzwerke, Strom und Daten. Für eine effektive Vorbereitung ist es wichtig, Regeln und Verfahren in einem detaillierten, dokumentierten Prozess festzulegen.
Falls die Einrichtungen einer Organisation zerstört werden, ist es notwendig, die Wiederherstellungsmaßnahmen auf Kommunikation, Transport, Beschaffung, Arbeitsplätze und andere kritische Bereiche auszudehnen.
Warum ist ein Notfallwiederherstellungsplan so wichtig?
Die Entwicklung eines detaillierten Plans zur Wiederherstellung nach Katastrophen, sei es durch natürliche Ursachen oder menschliches Handeln, ist für jedes IT-Unternehmen von großer Bedeutung. Stellen Sie sicher, dass die richtigen Mitarbeiter mit den richtigen Werkzeugen am richtigen Ort sind, um den Plan reibungslos umzusetzen.
Im Folgenden wird näher erläutert, warum Disaster Recovery so wichtig ist:
Schadensbegrenzung
Katastrophen sind unvorhersehbar. Niemand weiß, wann sie eintreten. Eine vorausschauende Vorbereitung ist jedoch entscheidend, um die durch Schäden an der Infrastruktur verursachten Auswirkungen zu begrenzen.
Beispielsweise können in hochwassergefährdeten Gebieten wichtige Dokumente und Geräte in den oberen Stockwerken gelagert werden, um Schäden zu vermeiden.
Ebenso sollten sensible Daten regelmäßig gesichert werden, um sich vor Cyberangriffen zu schützen, die Daten beschädigen oder stehlen könnten.
Wiederherstellung von Diensten
Ein solider Disaster-Recovery-Plan ermöglicht eine schnelle und einfache Wiederherstellung aller Dienste in ihren normalen Zustand. Dies bedeutet, dass kritische Vermögenswerte und Dienste innerhalb kurzer Zeit wiederhergestellt werden können.
Minimierung von Unterbrechungen
Die Zukunft ist ungewiss. Aber mit einem gut ausgearbeiteten Wiederherstellungsplan können Sie die Auswirkungen unvorhergesehener Ereignisse minimieren. Die Infrastruktur kann ihren Betrieb mit minimalen Unterbrechungen fortsetzen.
Training und Vorbereitung

IT-Infrastrukturen umfassen viele Mitarbeiter, die unter einem Dach arbeiten. Alle müssen über die Wiederherstellungsverfahren Bescheid wissen, um im Notfall sofort handeln zu können.
Eine gute Vorbereitung reduziert den Stress aller Beteiligten. Zudem können Mitarbeiter in den notwendigen Maßnahmen bei unvorhergesehenen Ereignissen geschult werden.
Disaster-Recovery-Terminologien
Lassen Sie uns nun die wichtigsten Begriffe der Notfallwiederherstellung erläutern:
RTO
Recovery Time Objective (RTO) ist der Zeitrahmen, den eine Organisation festlegt, um eine Katastrophe zu bewältigen, ohne das finanzielle Wachstum negativ zu beeinflussen. Bei der Festlegung der RTO sollte ein Unternehmen Ausfallzeiten analysieren, die das Unternehmen in verschiedenen Bereichen beeinträchtigen können. RTO hilft bei der Entwicklung von Strategien zur Aufrechterhaltung des Geschäftsbetriebs auch nach einer Katastrophe. Für Kunden, die mit Anwendungsunterbrechungen konfrontiert sind, beantwortet die RTO die Frage, wie schnell die Anwendung wieder verfügbar sein wird.
Beispielsweise sollte ein Online-Transaktionsunternehmen wie PayPal oder Pioneer ein schnelles RTO haben, um seine Dienste nach einem unerwarteten Ereignis schnell wiederherzustellen, um finanzielle Verluste und Datenverluste zu vermeiden.
RPO
Recovery Point Objective (RPO) bezieht sich auf die Menge an Datenverlust, die eine IT-Infrastruktur in Bezug auf Zeit und Informationsmenge akzeptieren kann.
Nehmen wir das Beispiel einer Bankdatenbank, die Transaktionen wie Überweisungen, Terminplanungen und Zahlungen erfasst. Wenn ein Notfall eintritt, sollte die Datenbank idealerweise in Echtzeit wiederhergestellt werden, wodurch der Datenverlust auf Null reduziert wird.
Für einige Unternehmen mag ein Datenverlust von bis zu 24 Stunden akzeptabel sein, doch dies kann für andere katastrophale Folgen haben. Es ist wichtig, die IT-Infrastruktur so zu konfigurieren, dass sie den RPO-Anforderungen entspricht, einschließlich häufigerer Backups und der Integration von Standby-Datenbanken.
Failover
Stellen Sie sich vor, Sie haben eine Reifenpanne während einer langen Autofahrt. Sie greifen zum Ersatzreifen und dem Werkzeug, um den Reifen zu wechseln. So funktioniert Failover.
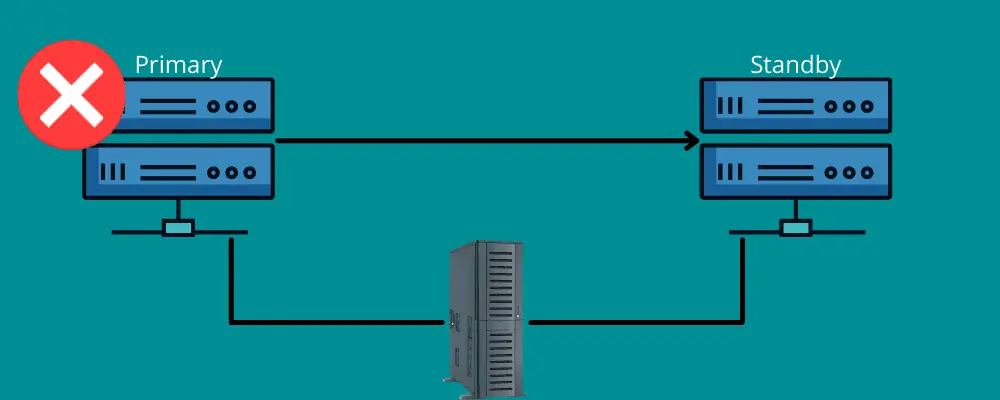
Es bedeutet, dass eine Backup-Verbindung während eines Ausfalls bereitsteht. Failover umfasst Netzwerke und Systeme, die bei einer Katastrophe genutzt werden können, um Informationen an das Wiederherstellungssystem zu übertragen.
Failover stellt sicher, dass alle Dienste auch bei Ausfällen der Infrastruktur oder Hardware reibungslos funktionieren. Dadurch werden Datenverluste und Ausfallzeiten vermieden.
Failover kann manuell oder automatisch erfolgen, wobei die Daten automatisch auf einen Standby-Server verschoben werden.
Failback
Failback ist der Prozess, bei dem die ursprüngliche Produktionsumgebung nach einer Katastrophe wieder an ihren ursprünglichen Standort (System) zurückkehrt. Nach einem Angriff verwenden Unternehmen einen Failover-Prozess, bei dem alle Workloads auf ein VM-Replikat oder ein Backup-System verlagert werden.
Nach der Wiederherstellung ist Failback wichtig, um alle Workloads zurück zu ihren ursprünglichen VMs oder Systemen zu verlagern. Es ist ein Prozess, der die "Rückkehr" nach dem Angriff ermöglicht.
Failback wird auch für die geplante Wartung verwendet. Es ist der zweite Schritt nach einem Failover bei der Wiederherstellung kritischer Daten. Die Einrichtung kann Cloud zu Cloud, On-Premises zu On-Premises, On-Premises zu Cloud oder eine beliebige Kombination davon umfassen.
DR
Disaster Recovery (DR) ist der Prozess, bei dem vorbereitete Pläne eingesetzt werden, um alle Vermögenswerte innerhalb eines bestimmten Zeitrahmens wiederherzustellen.
DR ermöglicht es Unternehmen, nach einem unerwarteten Ereignis schnell zu reagieren und alle Dienste wiederherzustellen. Dazu gehört eine detaillierte Dokumentation mit Anweisungen zur sofortigen Reaktion auf Notfälle.
BCP
Business Continuity Plan (BCP) ist ein umfassender Disaster-Recovery-Plan, mit dem die IT-Infrastruktur Strategien zur Bewältigung von IT-Unterbrechungen durch Server, mobile Geräte, PCs und Netzwerke entwickeln kann.
BCP unterscheidet sich leicht von DR, da er sich auf die Wiederherstellung von Geschäftssoftware und Produktivität konzentriert, um wichtige Geschäftsanforderungen zu erfüllen. BCP beinhaltet die Schaffung eines Wiederherstellungssystems, um Bedrohungen wie Cyberangriffe oder Naturkatastrophen zu bewältigen. Ziel ist es, Vermögenswerte zu sichern und sicherzustellen, dass alle Dienste nach einem Angriff schnell wieder funktionieren.
BCM

Business Continuity Management (BCM) ist ein Risikomanagementprozess, der speziell dazu dient, Geschäftsprozesse vor Bedrohungen zu schützen. Es ist der nächste Schritt von BCP, bei dem Wiederherstellungspläne validiert werden, um sicherzustellen, dass alle Mitarbeiter sofort auf den Plan reagieren und alle wichtigen Daten wiederherstellen können.
BCM dient als Management-Framework zur Identifizierung von Infrastrukturrisiken und stellt sicher, dass das Framework durch regelmäßige Tests effizient funktioniert. Dies verbessert die Vorhersagbarkeit, reduziert Risiken und optimiert Pläne für zukünftige Angriffe.
BIA
Business Impact Analysis (BIA) ist der Prozess der Analyse der Überlebensfähigkeit eines Unternehmens durch die Identifizierung wichtiger Systeme, Abläufe und Prozesse. BIA untersucht die Auswirkungen einer Katastrophe auf das Unternehmen durch Betriebsunterbrechungen.
BIA prognostiziert die Auswirkungen, bevor ein Angriff eintritt, um wichtige Informationen für die Entwicklung leistungsstarker Wiederherstellungsstrategien zu sammeln. Die Analyse identifiziert auch die Kosten, die durch Ausfälle entstehen, wie z.B. Kosten für die Wiederbeschaffung von Geräten, Cashflow-Verluste und Personalkosten.
Bei der Erstellung eines BIA-Berichts müssen wesentliche Unternehmensprozesse, die Auswirkungen von Unterbrechungen, akzeptable Zeiträume, tolerierbare Bereiche und finanzielle Kosten berücksichtigt werden.
Call Tree
Ein Call Tree ist ein System zur Erstellung einer Liste von Mitarbeitern, die während eines Notfalls angerufen werden müssen. Dieses baumartige Verfahren stellt sicher, dass alle Mitarbeiter während einer Bedrohung informiert werden und ihre zugewiesenen Aufgaben zur rechtzeitigen Wiederherstellung der Funktionen und Prozesse erfüllen.
Die regelmäßige Durchführung von Call-Tree-Übungen hilft bei der Vorbereitung der Mitarbeiter und der Überprüfung von Telefonnummern, um zu verhindern, dass das Fehlen oder die Änderung von Daten die Leistung beeinträchtigt. Automatisierung kann diesen Prozess beschleunigen.
Kommandozentrale/Kontrollzentrum
Eine Kommandozentrale/ein Kontrollzentrum ist eine virtuelle oder physische Einrichtung, die während einer Krise die Kontrolle über die Wiederherstellungspläne übernimmt. Es dient als Kommunikationszentrum für Teams, um die Systeme während einer Katastrophe zu verwalten.
Heutzutage sind die Kommandozentralen besser organisiert, um eine schnelle Reaktion zu ermöglichen. Sie leiten die Wiederherstellungsphase ein, sobald eine Katastrophe erkannt wird. Die Kommandozentrale dient auch als zentrale Anlaufstelle für Dienste, Presse, Lieferungen und andere Bedürfnisse und bringt Experten verschiedener Disziplinen zusammen.
Reaktion auf Vorfälle

Incident Response ist der Prozess der Reaktion auf einen Angriff durch definierte Verfahren und geschulte Mitarbeiter, um die Netzwerk- und Datensicherheit in Echtzeit zu gewährleisten.
Ein Unternehmen, das einen Incident-Plan hat, kann seine Daten wirksam vor Bedrohungen schützen. Incident-Response-Spezialisten sind aufmerksam und reagieren auf Vorfälle, indem sie Sicherheitsverletzungen verhindern und sicherstellen, dass bei der Notfallwiederherstellung keine Schritte übersprungen werden.
Hierzu müssen kritische Daten identifiziert und in der Cloud oder an einem externen Standort für eine sichere Wiederherstellung gespeichert werden. Die regelmäßige Aktualisierung der Incident-Response-Pläne ist notwendig, um auf sich verändernde Infrastrukturanforderungen und Cyberbedrohungen reagieren zu können.
Sicherung
Backup-Lösungen ermöglichen es einer IT-Infrastruktur, Kopien von Daten zu erstellen und diese sicher aufzubewahren. Sollte es zu Datenbankbeschädigungen oder versehentlichem Datenverlust kommen, kann das Backup dazu dienen, die Daten sofort wiederherzustellen.

Dateien werden an einem sicheren Ort gespeichert, um einen einfachen Zugriff nach einem Notfall zu ermöglichen. Es ist empfehlenswert, Daten an mehreren Orten zu sichern, um die Wiederherstellung zu ermöglichen, auch wenn ein Standort ausfällt.
Resilienz
Resilienz ist die Fähigkeit von Gemeinschaften, Staaten, Organisationen und Einzelpersonen, einer Katastrophe zu widerstehen, ohne ihre Dienste und Systeme zu gefährden.
Eine Organisation muss in der Lage sein, dem Druck durch Bedrohungen standzuhalten und Verluste durch eine bessere Planung zu minimieren, anstatt auf Hilfe zu warten. Dies ermöglicht es, Katastrophen zu bewältigen und die IT-Infrastruktur effizient wiederherzustellen.
Die wesentlichen Funktionen und Strukturen müssen dabei zu jeder Zeit aufrechterhalten und wiederhergestellt werden. Um katastrophensicher zu sein, ist es notwendig, Risiken zu antizipieren, sich anzupassen, zu teilen und zu lernen, Sektoren zu integrieren und Risikobereiche zu verwalten.
SLA

Ein Service Level Agreement (SLA) ist ein Notfallplan, in dem dem Endbenutzer der Zeitrahmen für die Wiederherstellung der Dienste bei einem Notfall angegeben wird.
Das SLA garantiert Kunden die Sicherheit, dass ihre Daten geschützt sind. Es ist die zentrale Anlaufstelle für alle Anliegen der Endbenutzer.
Jede IT-Infrastruktur sollte Kunden Sicherheit durch SLA geben. Es ist wichtig, dass Sie im Voraus mit den Endbenutzern kommunizieren.
SPOF
Ein Single Point of Failure (SPOF) ist ein Gerät, eine Person, eine Ressource oder eine Anwendung, die mit vielen anderen Systemen oder Anwendungen verbunden ist. Der Ausfall eines SPOF kann alle verbundenen Teile zum Ausfall bringen und den gesamten Prozess und Geschäftsbetrieb beeinträchtigen.
Es ist daher wichtig, eine Strategie zu haben, um mit diesem Problem umzugehen. Der erste Schritt sollte die Identifizierung einzelner Geräte oder Systeme mit den potenziell größten Auswirkungen sein. Führen Sie eine Business-Impact-Analyse durch und erstellen Sie eine Risikobewertung.
Nach der Identifizierung aller SPOFs ist es notwendig, sie anhand der Wiederherstellungsprozesse zu klassifizieren: einfache und direkte Wiederherstellung, schwierige Wiederherstellung mit einem zuverlässigen Prozess oder unmöglicher Wiederherstellung. Nach der Kategorisierung können Sie angemessene Maßnahmen ergreifen.
Systemwiederherstellung
Bei einem Hardwarefehler muss ein Wiederherstellungsprozess gestartet werden, um das betroffene System oder den Server wieder in seinen ursprünglichen Zustand zu versetzen. Die vollständige Systemwiederherstellung erfordert die Verwendung von Wiederherstellungsanforderungen, Backups, Firmware- und Hardwarekompatibilität.
Systemwiederherstellung setzt eine Maschine auf ihre vorherigen oder neuen Einstellungen zurück und entfernt so Viren und Softwarefehler.
Dieser Prozess umfasst die Planung der Wiederherstellung einer IT-Infrastruktur und die Festlegung von Verfahren zur Sicherstellung der Datenverfügbarkeit bei menschlichen oder natürlichen Katastrophen.
Systemwiederherstellung
Die Systemwiederherstellung ist ein Tool zur Wiederherstellung bestimmter Dateien und Informationen in ihren vorherigen Zustand.
Die Systemwiederherstellung kann dazu verwendet werden, Registrierungsschlüssel, Programme, Treiber, Systemdateien und andere Elemente auf ihre früheren Versionen zurückzusetzen, was eine große Hilfe bei vielen Arten von Katastrophen sein kann.
Testplan
Ein Testplan ist ein Dokument, das Informationen zu Teststrategien, Schätzungen, Ressourcen, Fristen, Zielen und Zeitplänen enthält. Es dient als Leitfaden für die Durchführung von Tests, um die Sicherheit von Hardware und Software zu gewährleisten.
Die Tests müssen nach definierten Verfahren und Schritten zur Bewältigung der Nachwirkungen von Katastrophen durchgeführt werden. Führen Sie regelmäßige Tests durch, um sicherzustellen, dass alle Schritte der Wiederherstellungsstrategie durchgeführt werden. Dadurch können Schwachstellen identifiziert werden und die IT-Infrastruktur ist besser für den Notfall gerüstet.
Fazit
Da niemand den Zeitpunkt einer Katastrophe vorhersagen kann, ist die Implementierung angemessener Sicherheitsmaßnahmen für jedes Unternehmen unerlässlich.
Das Verständnis der Disaster-Recovery-Terminologien hilft Ihnen, effektiv auf Angriffe und Katastrophen zu reagieren. Es hilft Ihnen auch bei der Vorbereitung, damit Sie Ihre Infrastruktur vor unerwarteten Ereignissen schützen können. Eine effektive Disaster-Recovery-Strategie kann Millioneneinsparungen bringen und den Verlust des Kundenvertrauens verhindern.