Die wahrscheinlich beste Alternative zur CSV-Speicherung: Parquet-Daten
Alternative zur CSV-Speicherung: Das Parquet-Datenformat
Im Bereich der Datenspeicherung und -verarbeitung stellt Apache Parquet eine signifikante Verbesserung gegenüber traditionellen Methoden wie CSV dar. Parquet zeichnet sich durch seine Fähigkeit aus, komplexe Datentypen effizient zu verarbeiten und ermöglicht eine beschleunigte Datenanalyse. In diesem Artikel untersuchen wir, wie sich das Parquet-Format den stetig wachsenden Anforderungen an die Datenverwaltung in der modernen Welt anpasst.
CSV-Speicherung: Eine Einführung
CSV (Comma Separated Values) ist ein weit verbreitetes Format zum Organisieren von Daten. Die Speicherung von CSV-Daten erfolgt zeilenorientiert, wobei jede Zeile durch Kommas getrennte Werte enthält. CSV-Dateien, mit der Dateiendung .csv, lassen sich mit verschiedenen Anwendungen wie Excel, Google Sheets oder Texteditoren öffnen und bearbeiten. Die Daten sind nach dem Öffnen der Datei direkt sichtbar, was einer der Gründe für ihre ursprüngliche Popularität war.
Trotz seiner Einfachheit stößt die CSV-Speicherung bei der Verarbeitung größerer Datenmengen an ihre Grenzen.
Mit zunehmendem Datenvolumen wird es immer aufwendiger, CSV-Daten abzufragen, zu verwalten und abzurufen.
Hier ein Beispiel für Daten in einer .CSV-Datei:
EmpId,Vorname,Nachname,Abteilung 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Personalwesen 2010052,Bill,Matthew,Architekt 2010079,Jose,Brian,IT 2012120,Adam,James,Lösungen
In Excel dargestellt, ergibt sich eine Zeilen-Spalten-Struktur:
Die Herausforderungen der CSV-Speicherung
Zeilenorientierte Speicherformate wie CSV eignen sich gut für CRUD-Operationen (Create, Update, Delete). Aber was ist mit "Read"?
Stellen Sie sich vor, eine CSV-Datei enthält eine Million Zeilen. Es wäre sehr zeitaufwendig, diese Datei zu öffnen und nach den benötigten Informationen zu suchen. Cloud-Anbieter wie AWS berechnen zudem die Kosten für Datenspeicherung und -abfrage anhand des gescannten Datenvolumens, wodurch CSV-Dateien potenziell teuer in der Handhabung werden können.
Ein weiterer Nachteil von CSV ist das Fehlen einer dedizierten Option zum Speichern von Metadaten, was die Datenanalyse erschwert.
Daher stellt sich die Frage: Welche kostengünstige und leistungsfähige Alternative für CRUD-Operationen gibt es? Lassen Sie uns das Parquet-Datenformat erkunden.
Das Parquet-Datenformat: Eine Alternative
Parquet ist ein Open-Source-Format zur Speicherung von Daten. Es wird häufig in Hadoop- und Spark-Umgebungen verwendet. Parquet-Dateien haben die Endung .parquet.
Parquet ist ein hochstrukturiertes Format, das sich hervorragend zur Optimierung von komplexen Rohdaten eignet, die oft in Data Lakes vorhanden sind. Dies führt zu einer deutlichen Reduzierung der Abfragezeiten.
Durch die Verwendung einer Mischung aus zeilen- und spaltenorientierter (hybrider) Speicherung ermöglicht Parquet eine effiziente Datenspeicherung und schnellen Datenabruf. Die Daten werden sowohl horizontal als auch vertikal partitioniert. Zudem minimiert das Parquet-Format den Parsing-Overhead erheblich.
Dies resultiert in einer Verringerung der gesamten Anzahl von E/A-Operationen und somit einer Kostensenkung.
Parquet speichert auch Metadaten, die Informationen zum Datenschema, der Anzahl der Werte, der Position der Spalten, Minimal- und Maximalwerten, der Anzahl der Zeilengruppen und der Art der Kodierung enthalten. Diese Metadaten sind auf verschiedenen Ebenen in der Datei gespeichert, was den Datenzugriff beschleunigt.
Im Gegensatz zu zeilenbasierten Formaten wie CSV, bei denen der Datenabruf zeitaufwendig ist, da die Abfrage durch jede Zeile navigieren und die jeweiligen Spaltenwerte abrufen muss, ermöglicht Parquet den gleichzeitigen Zugriff auf alle benötigten Spalten.
Zusammenfassend:
- Parquet basiert auf einer Spaltenstruktur zur Datenspeicherung.
- Es ist ein optimiertes Format zur Speicherung komplexer Datenmengen.
- Das Parquet-Format bietet verschiedene Methoden zur Datenkomprimierung und -kodierung.
- Es reduziert die Daten-Scan- und Abfragezeit signifikant und benötigt weniger Speicherplatz als CSV.
- Es minimiert die Anzahl der E/A-Operationen und reduziert somit die Kosten für Speicher und Abfrageausführung.
- Es beinhaltet Metadaten, die das Auffinden von Daten erleichtern.
- Es bietet Open-Source-Unterstützung.
Das Parquet-Datenformat im Detail
Um die Datenspeicherung im Parquet-Format besser zu verstehen, betrachten wir die interne Struktur:
Eine Parquet-Datei kann mehrere horizontale Partitionen enthalten, die als Zeilengruppen bezeichnet werden. Innerhalb jeder Zeilengruppe erfolgt eine vertikale Partitionierung, bei der die Spalten in mehrere Spaltenblöcke aufgeteilt werden. Die eigentlichen Daten werden als Seiten innerhalb dieser Spaltenblöcke gespeichert. Jede Seite enthält kodierte Datenwerte und Metadaten. Darüber hinaus werden die Metadaten für die gesamte Datei im Footer der Datei auf Zeilengruppenebene gespeichert.
Da die Daten in Spaltenblöcken organisiert sind, ist das Hinzufügen neuer Daten einfach, da die neuen Werte in einen neuen Block und eine neue Datei kodiert werden können. Die Metadaten werden dann für die betroffenen Dateien und Zeilengruppen aktualisiert. Parquet ist daher ein flexibles Format.
Parquet unterstützt nativ die Datenkomprimierung durch Seitenkomprimierung und Wörterbuchkodierung. Ein Beispiel für die Wörterbuchkomprimierung:
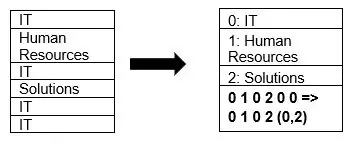
Im obigen Beispiel wird die IT-Abteilung viermal angezeigt. Bei der Speicherung mit Wörterbuchkodierung werden die Daten mit einem anderen, leicht zu speichernden Wert (0,1,2...) zusammen mit der Anzahl der Wiederholungen codiert. So wird "IT" zu 0,2, was Platz spart. Die Abfrage komprimierter Daten benötigt weniger Zeit.
CSV vs. Parquet: Ein Vergleich
Nachdem wir nun einen grundlegenden Einblick in die Formate CSV und Parquet haben, hier ein direkter Vergleich:
| CSV | Parquet |
| Zeilenorientiertes Speicherformat. | Hybrid aus zeilen- und spaltenorientierter Speicherung. |
| Verbraucht viel Speicherplatz, da keine standardmäßige Komprimierung angeboten wird. Beispielsweise benötigt eine 1-TB-Datei auch auf Amazon S3 1 TB Speicherplatz. | Komprimiert Daten beim Speichern und benötigt dadurch weniger Speicherplatz. Eine 1-TB-Datei im Parquet-Format benötigt beispielsweise nur 130 GB Speicherplatz. |
| Die Abfrage ist langsam aufgrund der zeilenbasierten Suche. Für jede Spalte muss jede Datenzeile abgerufen werden. | Die Abfragezeit ist aufgrund der spaltenbasierten Speicherung und der Metadaten etwa 34-mal schneller. |
| Pro Abfrage müssen mehr Daten gescannt werden. | Für die Ausführung der Abfrage werden ca. 99 % weniger Daten gescannt, was die Performance optimiert. |
| Die meisten Speicherdienste werden nach Speicherplatz berechnet, wodurch das CSV-Format hohe Speicherkosten verursacht. | Geringere Speicherkosten, da die Daten in komprimierter Form gespeichert werden. |
| Das Dateischema muss entweder abgeleitet werden (was zu Fehlern führen kann) oder manuell angegeben werden. | Das Dateischema wird in den Metadaten gespeichert. |
| Das Format ist für einfache Datentypen geeignet. | Parquet ist auch für komplexe Typen wie verschachtelte Schemas, Arrays und Wörterbücher geeignet. |
Fazit
Parquet bietet im Vergleich zu CSV klare Vorteile in Bezug auf Kosten, Flexibilität und Leistung. Es ist ein effizienter Mechanismus zur Speicherung und zum Abrufen von Daten, besonders in der Cloud. Alle wichtigen Plattformen wie Azure, AWS und BigQuery unterstützen das Parquet-Format.
