Die 9 besten serverlosen Datenbanken für moderne Anwendungen
Die Wahl der optimalen serverlosen Datenbank, die exakt zu Ihren modernen Anwendungsbedürfnissen passt, ist ein entscheidender Schritt.
Serverlose Datenbanken sind speziell dafür konzipiert, mit variablen und schwer vorhersehbaren Arbeitslasten umzugehen. Viele Unternehmen haben sich daher für serverlose Architekturen entschieden, um moderne, ereignisgesteuerte Systeme zu entwickeln. Dies hat zu einer wachsenden Popularität im Umfeld der serverlosen Technologien geführt.
Einführung in serverlose Datenbanken
Serverless Computing erfordert den Einsatz von serverlosen Datenbanken. Diese Datenbanken sind explizit darauf ausgerichtet, mit dynamischen und unvorhersehbaren Arbeitslasten Schritt zu halten. Was bedeutet das im Detail?
Sie zahlen ausschließlich für die Datenbankressourcen, die tatsächlich in Anspruch genommen werden, und das sekundengenau. Cloud-Datenbanken, wie beispielsweise Amazon Aurora, die mit MySQL und PostgreSQL kompatibel sind, können vollständig verwaltet werden und sind bis zu einer Kapazität von 64 TB skalierbar.
Die Skalierung erfolgt üblicherweise durch die Auswahl der passenden Instanzgröße. Dies funktioniert hervorragend, solange eine vorhersehbare Auslastung, eine konstante Anfragefrequenz und überschaubare Verarbeitungsanforderungen vorliegen.
Schwieriger wird es, die ideale Kapazität zu planen, wenn die Auslastung unberechenbar ist und ein hohes Anfragevolumen nur für wenige Minuten pro Woche oder an bestimmten Tagen anfällt. Eine durchgängige Bezahlung für eine Kapazität, die nur selten vollständig genutzt wird, ist dabei nicht die kosteneffizienteste Lösung.
Hier kommen serverlose Datenbanken ins Spiel, die diese Herausforderungen meistern.
Kernfunktionen serverloser Datenbanken
Hier sind die wichtigsten Eigenschaften von serverlosen Datenbanken:
- Echtzeitzugriff: Der Datenzugriff erfolgt auf granularer Ebene. Die Daten werden automatisch indiziert und sind sofort verfügbar. Dies ermöglicht es Ihnen, Ihre serverlose Datenbank kontinuierlich abzufragen, zu lesen, zu aktualisieren und neue Elemente hinzuzufügen. Darüber hinaus können Sie direkt über Funktionen darauf zugreifen.
- Unbegrenzte Skalierbarkeit: Serverlose Datenbanken lassen sich jederzeit nach Bedarf hoch- oder herunterskalieren. Sie werden automatisch gestartet und wieder heruntergefahren, basierend auf den jeweiligen Anforderungen der Anwendung. Die Recheneinheiten (ACUs im Fall von Aurora Serverless) werden so angepasst, dass sie Abfragen verarbeiten, Daten lesen und in denselben Datencluster schreiben. Diese Automatisierung erlaubt es Ihnen, alle Ihre Funktionen gleichzeitig auszuführen, während die Datenkonsistenz gewährleistet wird.
- Hohe Sicherheit: Moderne Anwendungen sind global mit potenziell böswilligen und nicht vertrauenswürdigen Nutzern konfrontiert. Serverlose Datenbanken stellen sicher, dass jede Anwendung, die mit der Datenbank interagiert, denselben Zugriffskontrollmechanismus durchläuft. Dies reduziert die Angriffsfläche, was ein entscheidender Vorteil für Unternehmen ist.
- Verfügbarkeit: Serverlose Datenbanken tragen zur Reduzierung der Latenz bei. Daten können direkt von ereignisgesteuerten Funktionen und unmittelbar vom Benutzer gelesen werden.
- Schemafreiheit: Dank der Schemafreiheit können Sie jegliche Datenausgabe Ihrer Funktionen verarbeiten. Dieser flexible Ansatz vereinfacht die Integration der serverlosen Datenbank in Ihre Funktionen erheblich. Dies ist ein besonderes Merkmal serverloser Datenbanken.
Lassen Sie uns nun einige der führenden serverlosen Datenbanken für moderne Anwendungen im Detail betrachten.
Fauna
Fauna ist eine verteilte, serverlose Datenbank, die maximale Flexibilität bietet. Sie können diverse Parameter präzise an die Anforderungen Ihres jeweiligen Projekts anpassen. Fauna kann als Schlüssel-Wert-, Graph-, Dokumenten- oder auch als traditionelle relationale Datenbank genutzt werden. Es ist Ihnen überlassen, ob Sie ein Schema erstellen oder Daten schemalos einsetzen möchten.
Fauna ist äußerst vielseitig. Sie kann in der Cloud, lokal oder eingebettet in Ihre Anwendung laufen. Es stehen auch gängige Bereitstellungsoptionen wie Maschinen- oder Docker-Images zur Auswahl. Diese Anwendung arbeitet mit sehr hohen Geschwindigkeiten und ist optimal für ACID-Transaktionen geeignet.
Amazon Aurora
Amazon Aurora ist ein relationaler Datenspeicherdienst, der über die Amazon Cloud zugänglich ist. Dieser Service wird häufig für die Speicherung von Daten verwendet und ermöglicht eine effiziente Datenverwaltung mit geringer Latenz.
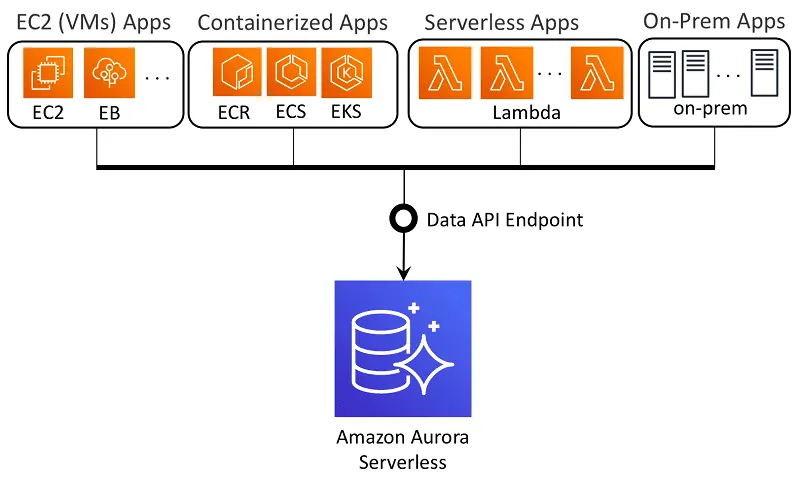
Amazon Aurora ist eine relationale Datenbank, die mit PostgreSQL und MySQL kompatibel ist. Sie kombiniert die Leistungsfähigkeit und Zugänglichkeit von traditionellen Datenbanken mit der Zuverlässigkeit und Benutzerfreundlichkeit kommerzieller Systeme, jedoch zu einem Bruchteil der Kosten. Die Datenreplikation wird durch einen Clustermechanismus in der AWS-Zugriffszone sichergestellt, was die Datenverfügbarkeit erhöht.
Amazon Aurora verfügt über leistungsstarke Subsysteme. Der schnelle, verteilte Speicher wird sowohl von MySQL- als auch von PostgreSQL-Engines verwendet. Aurora beschleunigt den Durchsatz und die Leistung von MySQL im Vergleich zu herkömmlichen Systemen um das Fünf- bzw. Dreifache.
Die Datenbank kann auf bis zu 64 Terabyte skaliert werden und bietet umfangreiche Unterstützung für Unternehmensimplementierungen. Amazon Aurora wird vollständig vom Amazon Relational Database Service (RDS) verwaltet, der administrative Aufgaben wie die Bereitstellung von Hardware, Datenorganisation, Fehlerbehebung, Upgrades und vieles mehr automatisiert.
Bit.io
Mit bit.io können Sie schnell und einfach eine PostgreSQL-Datenbank einrichten. Laden Sie Ihre Daten per Drag-and-Drop in die Datenbank, geben Sie eine URL zu einer Datei an, senden Sie Daten aus R oder Python oder verwenden Sie einen anderen Postgres/HTTP-Client.
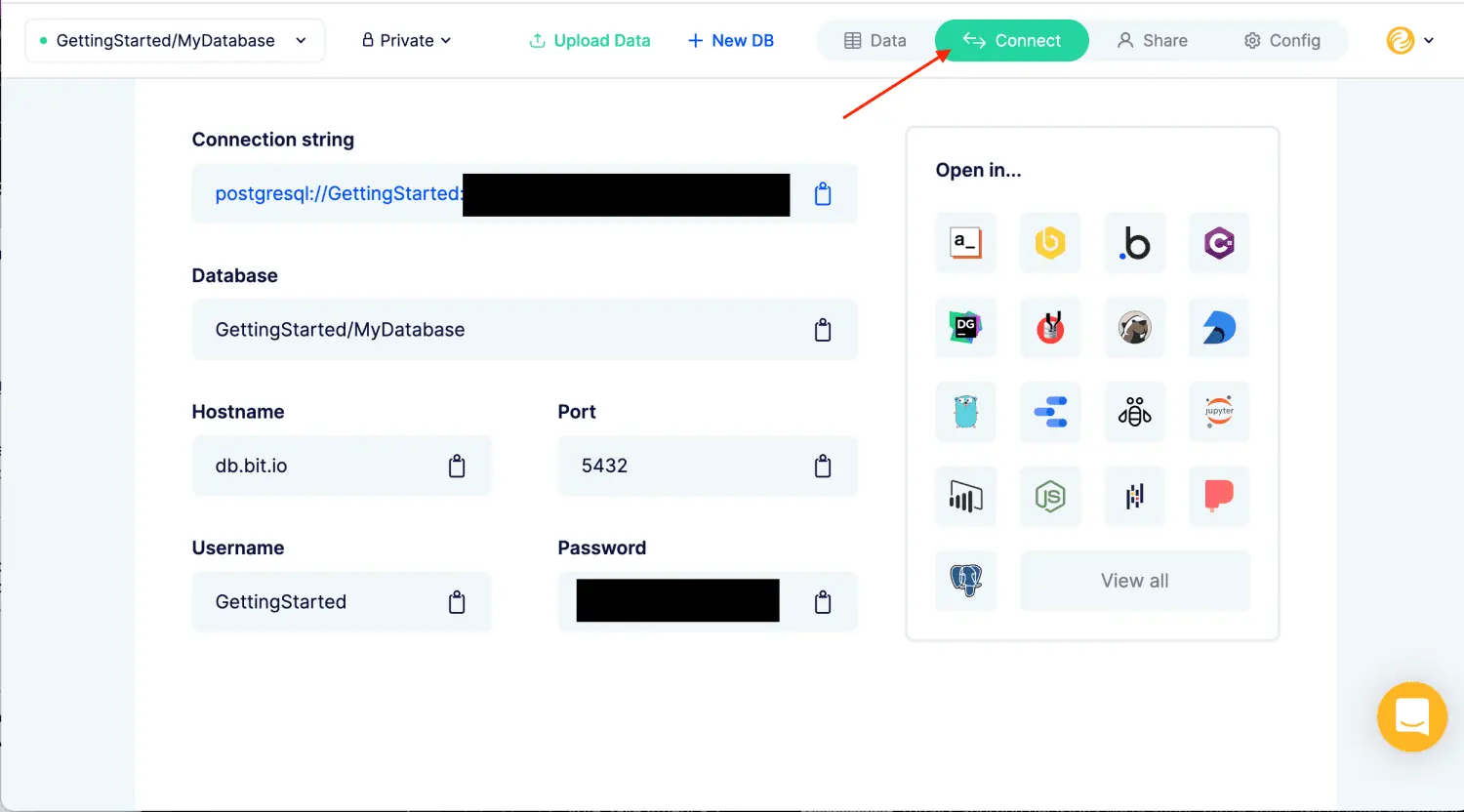
Der SQL-Editor im Browser ermöglicht Ihnen die Arbeit mit Ihren Daten und die Nutzung Ihrer bevorzugten Datenanalysetools, einschließlich SQL-Clients, R- und Python-Notebooks, der Befehlszeile und vielen weiteren Optionen.
bit.io bietet eine vollständig funktionsfähige PostgreSQL-Datenbank, die sich schnell und ohne großen Konfigurationsaufwand nutzen lässt. Zudem ist eine wachsende Anzahl von Datenintegrationen verfügbar. bit.io funktioniert mit jedem Tool, das PostgreSQL unterstützt.
Upstash
Upstash ist eine serverlose Cloud-Speicherdatenbank, entwickelt von Upstash Inc. (einem in Kalifornien ansässigen Unternehmen). Sie kann als Caching-Schicht oder als Datenbank dienen. Sie müssen keine Cluster oder Datenbankserver verwalten, da sie komplett serverlos betrieben wird.
Serverlose Technologien wie Upstash sind besonders nützlich, da sie nur dann Kosten verursachen, wenn sie auch tatsächlich genutzt werden. Upstash ist vielseitig einsetzbar und eignet sich für typische Redis-Anwendungsfälle, wie z.B.:
- Allgemeines Caching
- Session-Caching
- Bestenlisten
- Warteschlangen
- Nutzungsmetriken (Zählungen)
- Inhaltsfilterung
Merkmale
- Speziell für serverlose Umgebungen entwickelt
- Pay-as-you-go-Modell
- Geringe Latenz
- Dauerhafte und schnelle Datenspeicherung
Xata
Xata ist eine serverlose Datenbank mit leistungsfähigen integrierten Such- und Analysefunktionen. Xata verwendet ein relationales Datenbankmodell mit einem strengen Schema (Schema) und unterstützt JSON-ähnliche Objekte. Die Daten werden in Tabellen organisiert, die wiederum in Datenbanken gruppiert sind.
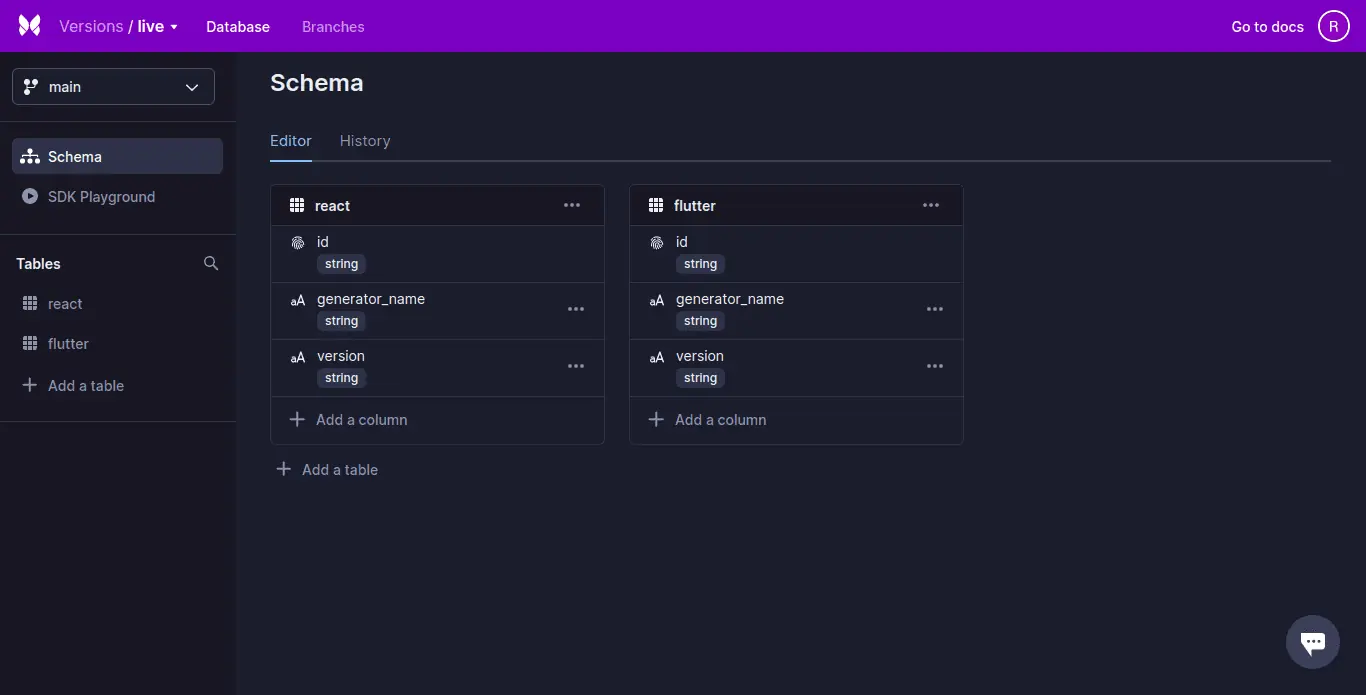
Xata unterstützt umfangreiche Spalten und Beziehungen zwischen Tabellen können mit Hilfe von Link-Spalten (ähnlich Fremdschlüsseln) dargestellt werden.
Xata, ein neuartiger Cloud-Dienst, bietet eine Abstraktionsschicht über mehreren Datenspeichern, um die Entwicklung und den Betrieb von Anwendungen zu vereinfachen. Diese Art von Dienst wird als serverlose Datenplattform bezeichnet. Die Architektur dieses Dienstes kann als Vorlage für eigene Implementierungen dienen und ermöglicht Ihnen, die Vorteile von Xata zu nutzen.
SurrealDB
SurrealDB ist eine innovative NewSQL-Cloud-Datenbank, die für serverlose, Jamstack-, Single-Page-, traditionelle und serverlose Anwendungen geeignet ist. Sie bietet unvergleichliche Flexibilität und ein ausgezeichnetes Preis-Leistungs-Verhältnis. Sie kann lokal, eingebettet, in Edge-Computing-Umgebungen oder in der Cloud eingesetzt werden.
Ihr Team muss keine komplexen Datenbanksprachen beherrschen. Erweiterte Funktionen sind einfach und unkompliziert zugänglich, aber dennoch schnell und leistungsstark. Die Skalierung von Servern, Datenbanken, Load Balancern und API-Endpunkten entfällt.
SurrealDB beseitigt die Komplexität aus Ihrem Stack und ermöglicht die Skalierung durch eine verteilte, hochverfügbare Plattform. Mit der SurrealDB Cloud können Sie Ihre Anwendungen überall bereitstellen.
CosmosDB
Azure Cosmos DB ist eine JSON-basierte, global verteilte Datenbank, die als „Platform as a Service“ (PaaS) in Microsoft Azure verfügbar ist. Sie ermöglicht es Benutzern, Anwendungen in Azure-Rechenzentren automatisch zu erstellen und zu verteilen, ohne dass eine Konfiguration erforderlich ist.
Sie ist Teil von Azure und in allen Regionen verfügbar. Die Daten werden auch über mehrere Rechenzentren im Netzwerk repliziert.
Es stehen viele Schnittstellen zur Verfügung, wobei die SQL-basierte Schnittstelle besonders hervorzuheben ist. CosmosDB ist ideal für Unternehmen, die große Mengen kurzlebiger, kritischer Informationen verarbeiten, abfragen und verwalten möchten.
CockroachDB
CockroachDB ist eine verteilte SQL-Datenbank, die auf einem konsistenten Schlüsselwert- und Transaktionsspeicher aufbaut.
Sie ist in Go geschrieben und vollständig Open Source. Zu den Kernzielen gehören die Unterstützung von ACID-Transaktionen, horizontale Skalierbarkeit und die Ausfallsicherheit. CockroachDB ist darauf ausgelegt, jegliche Art von Ausfällen zu tolerieren, von einem einzelnen Festplattenausfall bis hin zu einer umfassenden Katastrophe, und das ohne manuelles Eingreifen und mit minimalen Latenzunterbrechungen.
CockroachDB ist eine ausgezeichnete Wahl für Anwendungen, die zuverlässige, genaue und jederzeit verfügbare Daten benötigen. Sie können auf die Admin-Benutzeroberfläche unter https://localhost:8080 zugreifen, sobald der Cluster betriebsbereit ist. Dort finden Sie Informationen zur Cluster- und Datenbankkonfiguration und können die Clusterleistung durch die Überwachung von Metriken wie Integrität, Laufzeit, Replikation und Knotendetails optimieren.
PlanetScale
Mit PlanetScale, einer neuen DBaaS-Plattform, können Sie schnell eine Datenbank einrichten, ohne sich um Verbindungsmanagement kümmern zu müssen. PlanetScale-Datenbanken wurden speziell für Entwickler und deren Arbeitsabläufe entwickelt. Sie können eine vollständig verwaltete Datenbank bereitstellen, die die Zuverlässigkeit und Flexibilität von MySQL bietet. Die Datenbanken basieren auf MySQL 8.0.
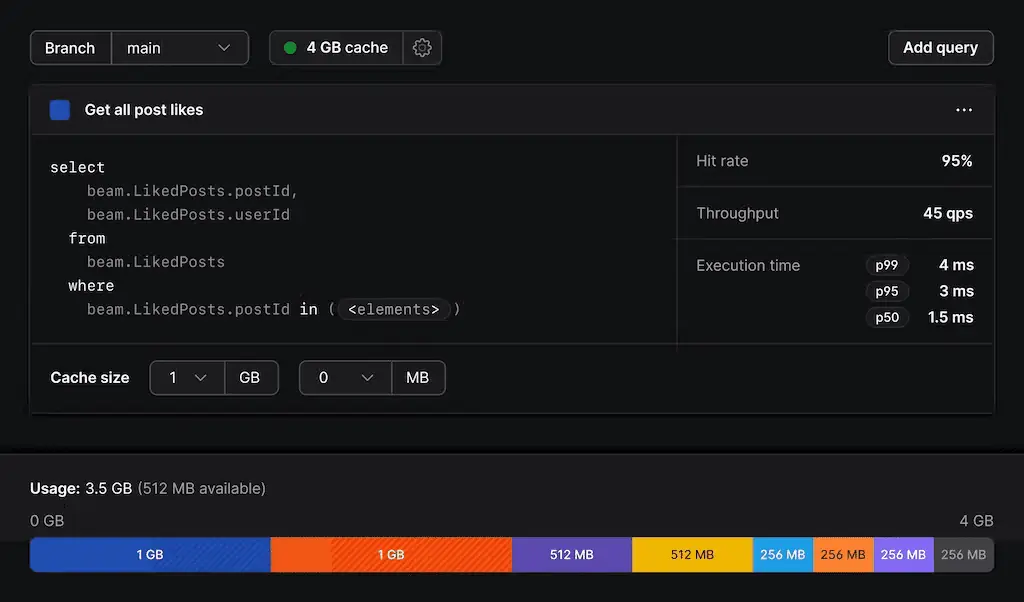
PlanetScale bietet zwei Arten von Datenbankzweigen: Produktion und Entwicklung. Die Verzweigungsfunktion ermöglicht es Ihnen, Ihre Datenbanken wie Code zu behandeln. Sie können einen Branch ausgehend vom Schema Ihrer Produktionsdatenbank erstellen, der dann für isolierte Entwicklungsumgebungen verwendet werden kann.
Zusammenfassung
Das waren die wichtigsten Informationen über die führenden serverlosen Datenbanken für moderne Anwendungen. Serverlose Datenbanken, insbesondere Amazon Aurora Serverless, weisen eine vielversprechende Zukunft auf. Denn diese Technologie ermöglicht es, sich auf das Wesentliche zu konzentrieren, wie Echtzeitzugriff auf Daten, Skalierbarkeit und Sicherheit.
Vielleicht interessieren Sie sich auch für 7 Gründe, warum Serverless Computing eine aufstrebende Technologie ist.
