Die 10 besten Graph-Datenbanklösungen zum Ausprobieren
Graphdatenbanken: Speicherung und effiziente Abfrage komplexer Daten
Graphdatenbanken sind spezialisiert auf die Speicherung und Verarbeitung von stark vernetzten Daten. Sie zeichnen sich durch ihre Effizienz bei der Abfrage komplexer Beziehungen aus. Doch wann ist der Einsatz einer Graphdatenbank wirklich sinnvoll? Dieser Artikel gibt Aufschluss.
Daten werden oft als das "neue Öl" bezeichnet. Der Erfolg eines Unternehmens hängt maßgeblich davon ab, wie effektiv es seine Daten speichert und nutzt. Täglich werden gigantische Datenmengen generiert. Um diese effektiv zu speichern und zu verwalten, sind fehlertolerante Systeme erforderlich. Ursprünglich wurden relationale Datenbanken eingesetzt.
Mit der Zeit haben sich Datenmengen und -arten jedoch stark verändert. Die Notwendigkeit, Video-, Audio- und Bilddaten zu speichern, führte zur Entwicklung von SQL, NoSQL-Datenbanken, Hadoop und eben Graphdatenbanken. Jede dieser Technologien hat ihre spezifischen Anwendungsfälle und verarbeitet unterschiedliche Datenformate. Graphdatenbanken wurden entwickelt, um Operationen mit Daten zu vereinfachen und eine effiziente Speicherung zu ermöglichen.
Grundlagen der Graphdatenbanken
Ein Graph ist eine Datenstruktur, die aus Knoten und Kanten besteht. Eine Datenbank ist eine Sammlung von Tabellen, die Daten und deren Beziehungen speichern. Eine Graphdatenbank speichert Daten als Knoten und die Beziehungen zwischen diesen Daten als Kanten. Sie ist besonders gut geeignet für Echtzeitabfragen und die Verwaltung von Viele-zu-viele-Beziehungen zwischen Entitäten.
Es gibt verschiedene Diagrammdatenmodelle, die bekanntesten sind Eigenschaftsgraphen und RDF-Graphen. Eigenschaftsgraphen werden vorwiegend für Analysen und Abfragen verwendet, während RDF-Graphen zur Datenintegration dienen. Der Hauptunterschied liegt in der Darstellung: RDF-Graphen nutzen Tripel (Subjekt, Prädikat, Objekt), um Beziehungen auszudrücken.
In Graphdatenbanken werden Daten in Knoten gespeichert und die Beziehungen zwischen diesen Daten werden durch Kanten zwischen den Knoten dargestellt. Die Kanten können gerichtet (unidirektional) oder ungerichtet (bidirektional) sein.
Die Verarbeitung von Abfragen erfolgt durch das Durchlaufen des Graphen. Um Abfragen effizient zu beantworten, werden Graph-Traversal-Algorithmen eingesetzt. Diese helfen, Wege zwischen Knoten zu finden, Abstände zu bestimmen, Muster zu identifizieren, Schleifen innerhalb des Graphen zu erkennen und Cluster zu bilden.
Anwendungsbereiche von Graphdatenbanken
Graphdatenbanken finden Anwendung in der Betrugserkennung. Knoten können Personen (mit Namen, Adressen, Geburtsdaten) oder betrügerische Elemente wie IP-Adressen sein. Wenn ein verdächtiger Knoten mit einem nicht verdächtigen interagiert, entstehen Verbindungen, die als potenziell betrügerisch markiert werden.
Social-Media-Plattformen nutzen Graphdatenbanken, um Empfehlungen für Personen, mit denen man sich verbinden könnte, und für relevante Inhalte zu geben. Dies wird durch Graphtraversierung innerhalb der Datenbank ermöglicht.
Auch Netzwerk-Mapping, Infrastrukturmanagement und die Verwaltung von Konfigurationselementen werden mithilfe von Graphdatenbanken effizienter.
Graphdatenbanken vs. relationale Datenbanken
Im Vergleich zu relationalen Datenbanken ersetzen Graphdatenbanken Tabellen mit Zeilen und Spalten durch Knoten und Kanten. Die Beziehungen zwischen Daten werden direkt auf den Kanten gespeichert.
Relationale Datenbanken speichern Beziehungen zwischen Tabellen durch Fremdschlüssel. Das Extrahieren von Daten oder Abfragen ist in Graphdatenbanken einfacher und erfordert keine komplexen Joins wie in relationalen Datenbanken.
Relationale Datenbanken sind ideal für transaktionsbasierte Anwendungsfälle, während Graphdatenbanken besser für beziehungsintensive und datenreiche Anwendungen geeignet sind.
Graphdatenbanken unterstützen strukturierte, halbstrukturierte und unstrukturierte Daten, während relationale Datenbanken ein festes Schema erfordern.
Graphdatenbanken sind flexibel und erfüllen dynamische Anforderungen, während relationale Datenbanken eher für statische und bekannte Probleme verwendet werden.

Im Folgenden werden einige der besten Lösungen für Graphdatenbanken vorgestellt:
Cayley
Cayley ist eine Open-Source-Graphdatenbank unter Apache 2.0 Lizenz. Sie wurde in Go entwickelt und ist für die Arbeit mit verknüpften Daten optimiert. Cayley wurde für den Aufbau von Googles Freebase und dem Knowledge Graph eingesetzt. Es werden mehrere Abfragesprachen unterstützt, darunter MQL und Javascript, und ein Gremlin-basiertes Diagrammobjekt.

Cayley ist benutzerfreundlich, schnell und modular aufgebaut. Es kann verschiedene Backend-Speicher wie LevelDB, MongoDB und Bolt integrieren. Es unterstützt diverse APIs von Drittanbietern in Sprachen wie Java, .NET, Rust, Haskell, Ruby, PHP, Javascript und Clojure. Die Bereitstellung erfolgt über Docker und Kubernetes. Haupteinsatzgebiete von Cayley sind Informationstechnologie, Softwareentwicklung und Finanzdienstleistungen.
Amazon Neptune
Amazon Neptune ist bekannt für seine hervorragende Leistung bei der Verarbeitung von stark vernetzten Datensätzen. Es ist zuverlässig, sicher, vollständig verwaltet und unterstützt offene Graph-APIs. Neptune kann Milliarden von Beziehungen speichern und Daten mit extrem geringer Latenz (wenige Millisekunden) abfragen.
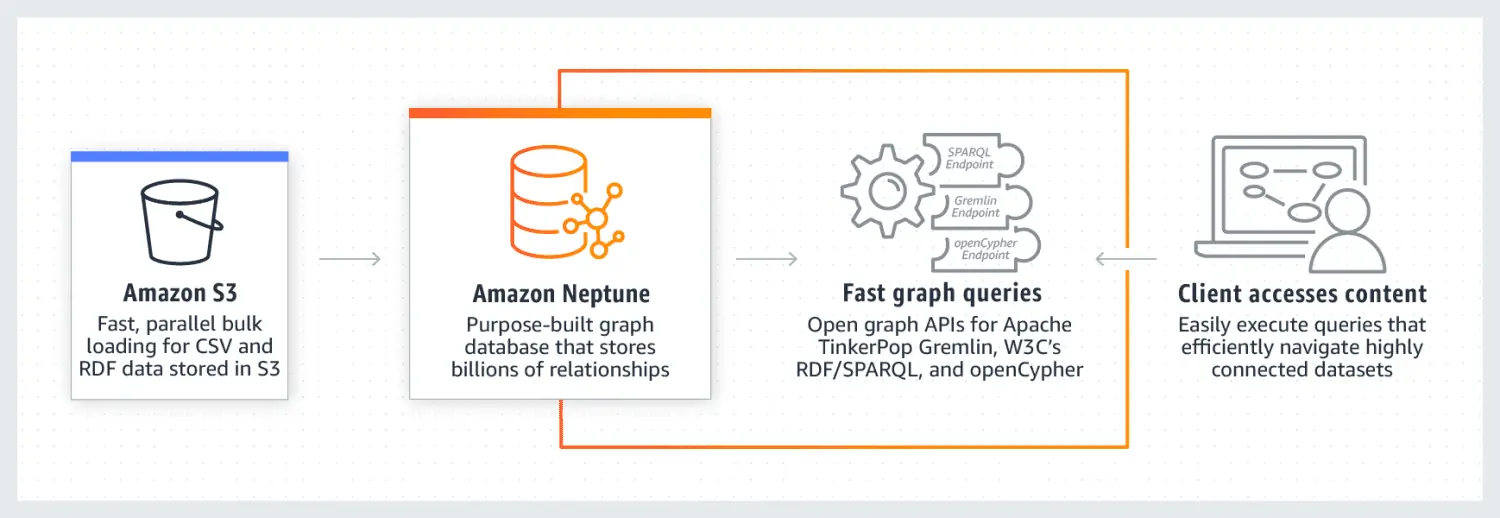
Das Datenmodell von Neptune besteht aus vier Positionen: Subjekt (S), Prädikat (P), Objekt (O) und Graph (G). Diese werden verwendet, um den Quellknoten, den Zielknoten, die Beziehung zwischen ihnen und deren Eigenschaften zu speichern. Neptune nutzt einen Cache, um die Ausführung von Leseabfragen zu beschleunigen. Die Daten werden in Form von DB-Clustern gespeichert, wobei jeder Cluster eine primäre DB-Instanz und Read Replicas enthält. Neptune ist sehr sicher durch IAM-Authentifizierung, SSL-Zertifizierung und Protokollüberwachung. Die Migration von Daten aus anderen Quellen ist unkompliziert. Neptune gewährleistet Ausfallsicherheit durch Replikate und regelmäßige Sicherungen. Bekannte Unternehmen, die Neptune einsetzen, sind Herren, Onedot, Juncture und Hi Platform.
Neo4j
Neo4j ist eine skalierbare, sichere und zuverlässige Graphdatenbank. Entwickelt in Java, nutzt sie Cypher als Abfragesprache. Transaktionen erfolgen über einen HTTP-Endpunkt mit dem Bolt-Protokoll. Neo4j ist bei der Abfragebeantwortung deutlich schneller als relationale Datenbanken. Sie kommt ohne den Overhead komplexer Joins aus und ist besonders leistungsfähig bei großen und stark vernetzten Datensätzen. Neo4j bietet die Vorteile der Diagrammspeicherung kombiniert mit den ACID-Eigenschaften relationaler Datenbanken.

Neo4j unterstützt eine Vielzahl von Sprachen wie Java, .NET, Node.js, Ruby und Python über Treiber. Es wird auch für Graph Data Science-, Analyse- und Machine-Learning-Workflows genutzt. Neo4j Aura DB ist eine fehlertolerante und vollständig verwaltete Cloud-Graphdatenbank. Firmen wie Microsoft, Cisco, Adobe, eBay, IBM und Samsung verwenden Neo4j.
ArangoDB
ArangoDB ist eine Open-Source-Multi-Modell-Datenbank. Dieser Ansatz ermöglicht es Benutzern, Daten in der gewünschten Abfragesprache zu verarbeiten. Knoten und Kanten sind JSON-Dokumente mit eindeutigen IDs. Beziehungen werden durch Kanten dargestellt, die die eindeutigen IDs der verbundenen Knoten speichern. Die gute Leistung ist auf den Hash-Index zurückzuführen.

Traversal, Joins und Suchen in Datenbanken sind optimiert. ArangoDB unterstützt die Entwicklung, Skalierung und Anpassung an verschiedene Architekturen. Sie spielt eine wesentliche Rolle bei komplexen datenwissenschaftlichen Aufgaben wie Merkmalsextraktion und erweiterter Suche. ArangoDB kann in der Cloud betrieben werden und ist mit Mac OS, Linux und Windows kompatibel. LDAP-Authentifizierung, Datenmaskierung und Verschlüsselungsalgorithmen gewährleisten die Sicherheit der Datenbank. ArangoDB wird unter anderem im Risikomanagement, bei der Betrugserkennung, im Netzwerkmanagement und für Empfehlungssysteme eingesetzt. Accenture, Cisco, Dish und VMware sind einige Organisationen, die ArangoDB nutzen.
DataStax
DataStax ist eine NoSQL-Cloud-Datenbank-as-a-Service, basierend auf Apache Cassandra. Sie zeichnet sich durch hohe Skalierbarkeit und eine Cloud-native Architektur aus. Die gespeicherten Dokumente verfügen über einen Index, der das einfache Suchen und schnelle Abrufen von Daten ermöglicht. Shards werden über die indizierten Daten erstellt. DataStax Enterprise-Tools, Kafka und Docker können für den Aufbau von Anwendungen genutzt werden.
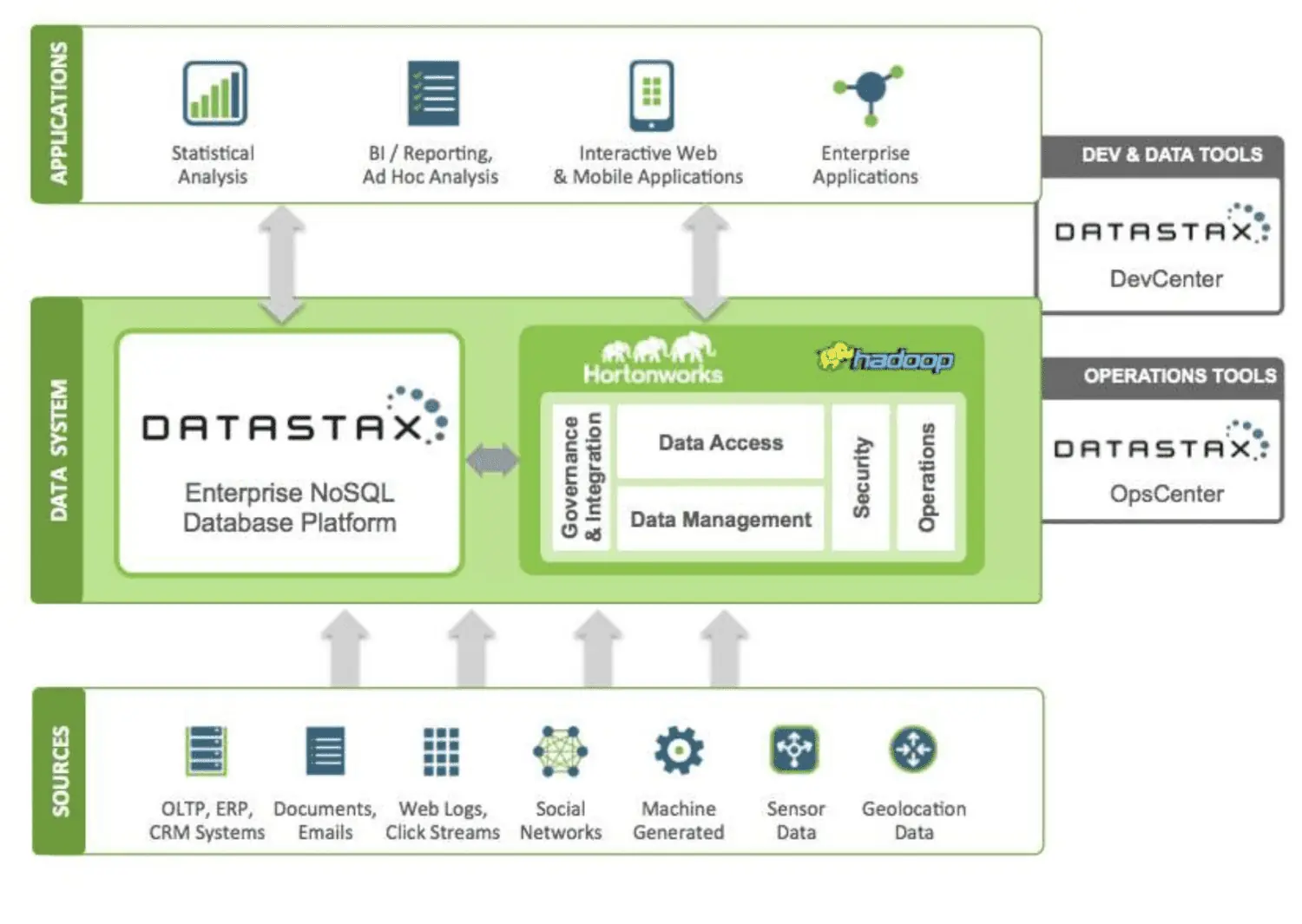
Die aus verschiedenen Quellen gesammelten Daten werden an ein Hadoop-Ökosystem und DataStax gesendet. Hadoop übernimmt die Verwaltung von Sicherheit, Betrieb, Datenzugriff und Verwaltung in Interaktion mit DataStax. Die Daten werden mithilfe von Entwicklungs- und Betriebstools von Datastax verfeinert und für statistische Analysen, Unternehmensanwendungen und Berichte genutzt. Kunden zahlen für ihre Nutzung der Cloud-basierten Lösung, wobei die Preise angemessen sind. Verizon, CapitalOne, TMobile und Overstock sind einige der Unternehmen, die DataStax verwenden.
OrientDB
OrientDB ist eine Multi-Modell-Graphdatenbank in Java, die Daten effizient verwaltet und Visualisierungen erstellt. Die Daten werden als Schlüssel-Wert-Paare, Dokumente und Objektmodelle gespeichert. Die Datenbank besteht aus drei Hauptkomponenten: Graph-Editor, Studio-Abfrage und Befehlszeilenkonsole.
Der Grafikeditor dient zur Visualisierung und Interaktion mit Daten. Das Studio-Abfrageinterface ermöglicht das Ausführen von Abfragen und zeigt die Ergebnisse sofort in Bild- und Tabellenform an. Die Befehlszeilenkonsole dient der Datenabfrage. OrientDB hat eine verteilte Architektur mit mehreren Servern für Lese- und Schreiboperationen. Replikatserver werden für Lese- und Abfrageoperationen eingesetzt. OrientDB unterstützt Indizierung und ist ACID-konform. Comcast Corporation und Blackfriars Group gehören zu den Unternehmen, die OrientDB verwenden.
Dgraph
Dgraph ist eine Cloud-Graphdatenbank mit GraphQL-Unterstützung. Entwickelt in Go, minimiert sie Netzwerkaufrufe und reduziert die Latenz durch die Optimierung der gleichzeitigen Abfrageverarbeitung. Die nahtlose Integration von Dgraph mit GraphQL vereinfacht die Entwicklung von GraphQL-Backend-Anwendungen.
Eine GraphQL-Mutation wird über eine Lambda-Funktion abgewickelt, die mit der Datenbank und einer Datenpipeline interagiert. Dgraph ist horizontal skalierbar und bietet Funktionen wie JWT-basierte Autorisierung, Datenvisualisierung, Cloud-Authentifizierung und Datensicherungen. Intuit, Intel und Factset gehören zu den Unternehmen, die Dgraph nutzen.
Tigergraph
Tigergraph ist eine Eigenschaftsgraphdatenbank, entwickelt in C++. Sie ist hoch skalierbar und führt erweiterte Analysen auf stark vernetzten Daten durch. Tigergraph verwendet eine native Graphstruktur zur Datenspeicherung und eine Graphverarbeitungsengine zur Datenverarbeitung. Die Datenbank speichert Daten auf der Festplatte und im Arbeitsspeicher und nutzt einen CPU-Cache für schnelle Abrufe. Die Map-Reduce-Funktion dient der parallelen Datenverarbeitung.
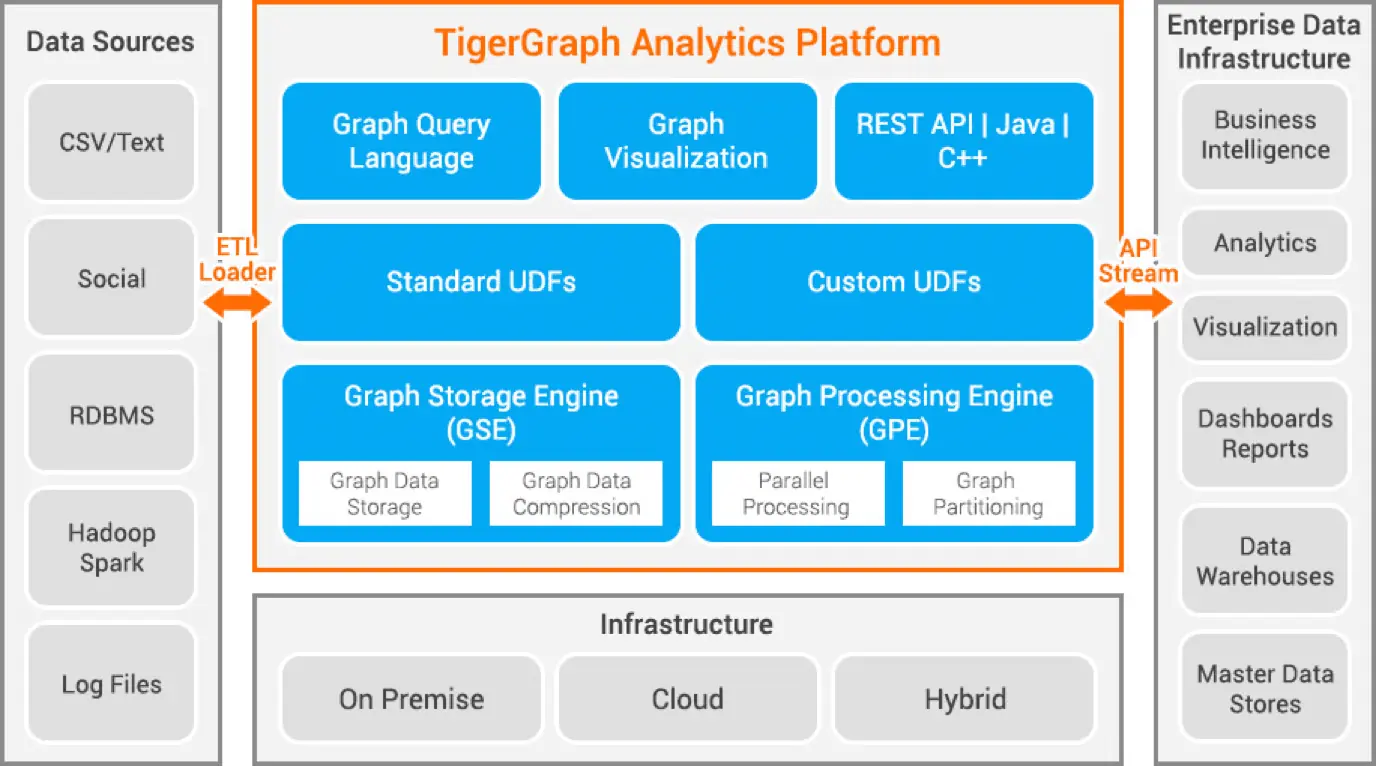
Tigergraph ist extrem schnell und skalierbar. Es führt parallele Berechnungen durch und bietet Echtzeit-Updates. Es verwendet Datenkomprimierungstechniken und komprimiert die Daten um das 10-fache. Die automatische Partitionierung der Daten über mehrere Server spart dem Benutzer Zeit und Aufwand bei der manuellen Fragmentierung. Tigergraph wird zur Betrugserkennung im Haushalt, im Supply-Chain-Management und im Gesundheitswesen eingesetzt. JPMorgan Chase, Intuit und United Health Group verwenden Tigergraph.
AllegroGraph
AllegroGraph nutzt die Entity-Event Knowledge Graph-Technologie für Analysen und Entscheidungen im Zusammenhang mit stark vernetzten, komplexen Daten. Die Daten werden im JSON- und JSON-LD-Format in den Knoten des Diagramms gespeichert. Es verwendet die REST-Protokollarchitektur. AllegroGraph verarbeitet sehr große Datensätze, indem es sie auf der Grundlage bestimmter Kriterien fragmentiert und auf mehrere Wissensdatenbank-Repositories verteilt.
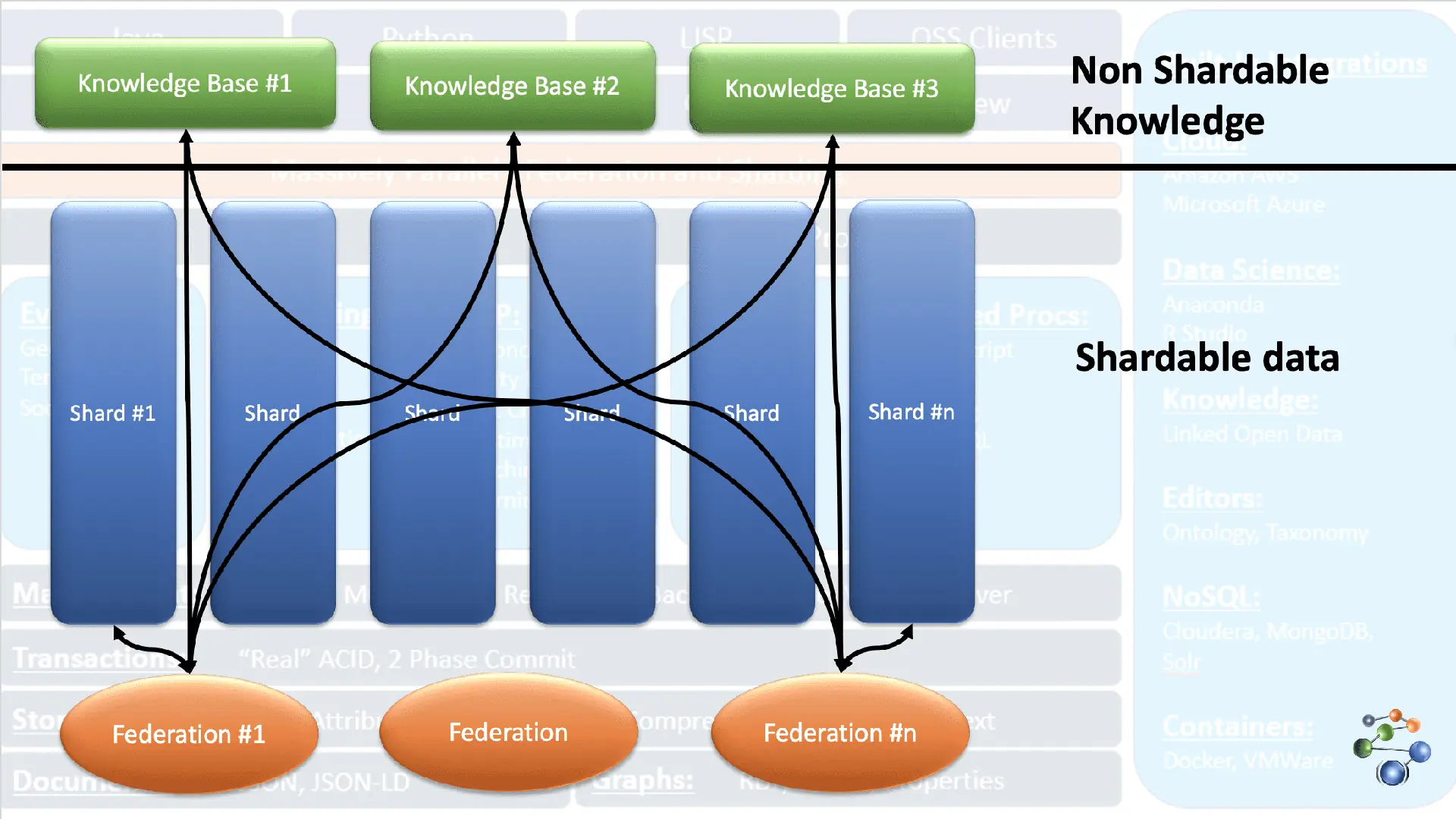
Dies wird durch die FedShard-Funktion ermöglicht. Die Ausführung von Abfragen erfolgt durch die Kombination der Föderationen mit Wissensdatenbank-Repositories. AllegroGraph unterstützt XML-Schematypen und verwendet dreifache Indizes. Sie speichert Geodaten (Breiten- und Längengrade) und zeitliche Daten (Datum, Zeitstempel usw.). Es ist mit Windows, Mac und Linux kompatibel. AllegroGraph wird in der Betrugserkennung, im Gesundheitswesen, bei der Identifizierung von Einheiten und der Risikoprognose verwendet.
Stardog
Stardog ist eine Graphdatenbank, die Graphdaten-Virtualisierung bietet. Daten aus Data Warehouses und Data Lakes werden verknüpft, ohne sie physisch an einen neuen Speicherort zu kopieren. Stardog basiert auf offenen RDF-Standards und unterstützt strukturierte, halbstrukturierte und unstrukturierte Daten. Diese Virtualisierung bietet Flexibilität und macht Stardog zur einzigen Graphdatenbank, die Wissensgraphen und Virtualisierung kombiniert.

Stardog nutzt eine KI-gestützte Inferenz-Engine für die effiziente Verarbeitung und Bereitstellung von Abfrageergebnissen. Es ist eine ACID-konforme Graphdatenbank und unterstützt gleichzeitige Lese- und Schreibvorgänge. Stardog bewältigt komplexe Anfragen durch seine State-of-the-Art-Architektur und bietet Hochverfügbarkeit. Es wird im IT Asset Management, im Datenmanagement und in Analytik eingesetzt. Cisco, eBay, NASA und Finra gehören zu den Unternehmen, die Stardog verwenden.
Abschließende Gedanken
Graphdatenbanken erleichtern die Abfrage von Viele-zu-viele-Beziehungen und ermöglichen eine effiziente Datenspeicherung. Sie sind skalierbar, sicher und können in verschiedene Tools, APIs und Sprachen von Drittanbietern integriert werden. Die Integration in die Cloud hat ihre Leistung in den letzten Jahren optimiert.
Sie vereinfachen komplexe Verknüpfungen in einfache Abfragen, was die Arbeit von Entwicklern erleichtert. Auch datenintensive Aufgaben im Bereich IoT und Big Data werden von Graphdatenbanken gut unterstützt. Diese Technologien werden sich weiterentwickeln und ihre Anwendungsfälle in Zukunft erweitern.