Convolutional Neural Networks (CNNs): Eine Einführung
Konvolutionale neuronale Netze bieten eine verbesserte, skalierbare Lösung für die Objekterkennung und Bildklassifizierung.
Die technologische Welt ist in ständigem Wandel. Begriffe wie Künstliche Intelligenz und Maschinelles Lernen sind allgegenwärtig.
Diese Technologien finden heutzutage in nahezu allen Branchen Anwendung, von Marketing und E-Commerce über Softwareentwicklung bis hin zu Bankwesen, Finanzen und Medizin.
KI und ML sind umfangreiche Forschungsfelder, und es werden stetig Bemühungen unternommen, ihre Anwendungsbereiche zur Bewältigung realer Herausforderungen zu erweitern. Daher gibt es viele Spezialisierungen innerhalb dieser Disziplinen; ML selbst ist ein Teilbereich der KI.
Konvolutionale neuronale Netze sind ein Zweig der KI, der immer mehr an Bedeutung gewinnt.
In diesem Beitrag werde ich erläutern, was CNNs sind, wie sie funktionieren und welchen Nutzen sie in der modernen Welt bieten.
Legen wir direkt los!
Was genau ist ein konvolutionales neuronales Netz?
Ein konvolutionales neuronales Netz (ConvNet oder CNN) ist eine spezielle Art des künstlichen neuronalen Netzes (KNN), das Deep-Learning-Algorithmen verwendet, um Bilddaten zu analysieren, visuelle Elemente zu kategorisieren und Aufgaben der Computer Vision zu bewältigen.
CNNs nutzen Prinzipien der linearen Algebra, wie die Matrixmultiplikation, um Muster in einem Bild zu erkennen. Da diese Prozesse rechenintensiv sind, werden Grafikprozessoren (GPUs) für das Trainieren der Modelle benötigt.
Einfach ausgedrückt, CNNs verwenden Deep-Learning-Algorithmen, um Eingangsdaten wie Bilder zu verarbeiten und verschiedenen Aspekten dieser Bilder Relevanz in Form von Verzerrungen und lernbaren Gewichtungen zuzuordnen. Auf diese Weise können CNNs zwischen verschiedenen Bildern unterscheiden oder sie klassifizieren.
CNNs: Ein kurzer historischer Abriss
Da konvolutionale neuronale Netze eine Unterkategorie künstlicher neuronaler Netze darstellen, ist es wichtig, kurz auf die Geschichte der neuronalen Netze einzugehen.
In der Informatik ist ein neuronales Netz ein Teilbereich des maschinellen Lernens (ML), das Deep-Learning-Algorithmen einsetzt. Es ist inspiriert von der Vernetzung der Neuronen im menschlichen Gehirn. Auch die Struktur des visuellen Kortex diente als Vorbild.
Aus diesem Grund gibt es unterschiedliche Arten von neuronalen oder künstlichen neuronalen Netzen (KNN), die für verschiedene Zwecke eingesetzt werden. Eines davon sind CNNs, die unter anderem für die Bilderkennung und -klassifizierung verwendet werden. Sie wurden in den 1980er Jahren von dem Postdoktoranden Yann LeCun eingeführt.
Die erste Version von CNN, LeNet, benannt nach LeCun, war in der Lage, handgeschriebene Ziffern zu erkennen. Sie wurde in Banken und Postdiensten zum Auslesen von Ziffern auf Schecks und Postleitzahlen auf Umschlägen eingesetzt.
Jedoch fehlte dieser frühen Version die Skalierbarkeit, weshalb CNNs in der künstlichen Intelligenz und der Computer Vision lange Zeit nur wenig genutzt wurden. Außerdem waren erhebliche Rechenressourcen und Datensätze erforderlich, um bei größeren Bildern effizient zu arbeiten.
Im Jahr 2012 erlebte Deep Learning mit AlexNet, das neuronale Netze mit mehreren Schichten verwendet, eine Renaissance. Zu dieser Zeit gab es technologische Fortschritte, große Datensätze und leistungsfähige Computerressourcen, die es ermöglichten, komplexe CNNs zu entwickeln, die in der Lage waren, Computer-Vision-Aufgaben effizient zu bewältigen.
Die Schichten eines CNN
Werfen wir einen Blick auf die verschiedenen Schichten eines CNN. Durch die Erhöhung der Anzahl der Schichten wird die Komplexität eines CNN gesteigert, wodurch es in der Lage ist, immer mehr Aspekte oder Bereiche eines Bildes zu erkennen. Beginnend mit einfachen Merkmalen kann es komplexe Merkmale wie die Form eines Objekts und größere Elemente erkennen, bis es schließlich das gesamte Bild identifizieren kann.
Konvolutionsschicht
Die erste Schicht eines CNN ist die Konvolutionsschicht. Sie ist der grundlegende Baustein von CNNs, in dem die meisten Berechnungen stattfinden. Sie benötigt einige Elemente wie Eingabedaten, eine Feature-Map und einen Filter.
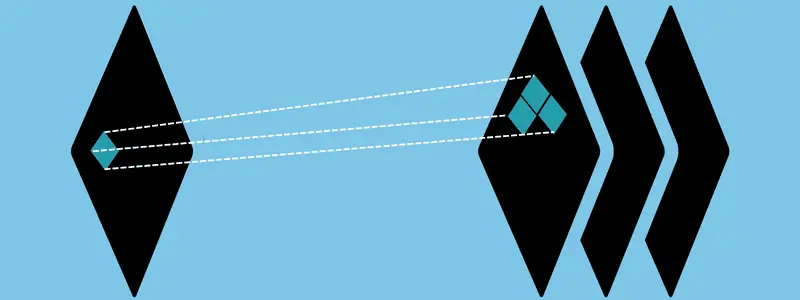
Ein CNN kann auch mehrere Konvolutionsschichten enthalten. Dies führt zu einer hierarchischen CNN-Struktur, da die nachfolgenden Schichten Pixel innerhalb der rezeptiven Felder der vorherigen Schichten visualisieren können. Die Konvolutionsschichten wandeln das Eingabebild in numerische Werte um, wodurch das Netzwerk wertvolle Muster erkennen und extrahieren kann.
Pooling-Schicht
Pooling-Schichten dienen zur Dimensionsreduktion, auch als Downsampling bezeichnet. Sie reduzieren die Anzahl der in den Eingabedaten verwendeten Parameter. Die Pooling-Operation verwendet, ähnlich wie die Konvolutionsschicht, einen Filter, der sich über die Eingabe bewegt, jedoch ohne Gewichte. Der Filter wendet eine gemeinsame Funktion auf die numerischen Werte im rezeptiven Feld an, um das Ergebnis-Array zu befüllen.
Es gibt zwei Arten des Poolings:
- Average Pooling: Hier wird der Durchschnittswert innerhalb des rezeptiven Feldes berechnet, über das der Filter über die Eingabe wandert, und an das Ausgabearray übertragen.
- Max Pooling: Es wählt den Pixel mit dem höchsten Wert aus und überträgt ihn an das Ausgabe-Array, während der Filter über die Eingabe wandert. Max Pooling ist gebräuchlicher als Average Pooling.
Obwohl beim Pooling ein erheblicher Datenverlust auftritt, bietet es dennoch viele Vorteile für CNNs. Es trägt dazu bei, das Risiko der Überanpassung und die Komplexität zu reduzieren und gleichzeitig die Effizienz zu steigern. Es verbessert auch die Stabilität von CNNs.
Vollständig verbundene (FC) Schicht

Wie der Name schon sagt, sind in einer vollständig verbundenen Schicht alle Knoten einer Ausgabeschicht direkt mit allen Knoten der vorherigen Schicht verbunden. Sie klassifiziert ein Bild auf der Grundlage der extrahierten Merkmale der vorherigen Schichten und deren Filter.
FC-Schichten verwenden in der Regel eine Softmax-Aktivierungsfunktion, um Eingaben korrekt zu klassifizieren, im Gegensatz zu ReLu-Funktionen (wie bei Pooling- und Konvolutionsschichten). Dies hilft, eine Wahrscheinlichkeit von entweder 0 oder 1 zu erzeugen.
Wie funktionieren CNNs?
Ein konvolutionales neuronales Netz besteht aus vielen Schichten, sogar hunderten. Diese Schichten lernen, verschiedene Merkmale eines bestimmten Bildes zu identifizieren.
Obwohl CNNs neuronale Netze sind, unterscheidet sich ihre Architektur von einem herkömmlichen KNN.

Letzteres leitet eine Eingabe durch viele verborgene Schichten, um sie zu transformieren, wobei jede Schicht mit einem Satz künstlicher Neuronen gebildet wird und vollständig mit jedem Neuron derselben Schicht verbunden ist. Am Ende befindet sich eine vollständig verbundene oder Ausgabeschicht, um das Ergebnis darzustellen.
CNNs hingegen organisieren die Schichten in drei Dimensionen: Breite, Tiefe und Höhe. Hier verbindet sich eine Neuronenschicht nur mit Neuronen in einem kleinen Bereich, anstatt sich auf jedes einzelne Neuron in der nächsten Schicht zu beziehen. Das Endergebnis wird durch einen einzelnen Vektor mit einem Wahrscheinlichkeitswert dargestellt und hat nur die Tiefendimension.
Sie fragen sich vielleicht, was "Konvolution" in einem CNN bedeutet.
Konvolution bezieht sich auf eine mathematische Operation, bei der zwei Datensätze kombiniert werden. In CNNs wird das Konzept der Konvolution auf Eingabedaten angewendet, um eine Feature-Map zu erstellen, indem die Informationen gefiltert werden.
Dies führt uns zu einigen wichtigen Konzepten und Begriffen, die in CNNs verwendet werden:
- Filter: Auch als Merkmalsdetektor oder Kernel bezeichnet, kann ein Filter eine bestimmte Größe haben, beispielsweise 3x3. Er gleitet über ein Eingabebild, um für jedes Element eine Matrixmultiplikation durchzuführen und so eine Konvolution anzuwenden. Das Anwenden von Filtern auf jedes Trainingsbild mit unterschiedlichen Auflösungen und die Ausgabe des konvolvierten Bildes dient als Eingabe für die nächste Schicht.
- Padding: Es wird verwendet, um eine Eingabematrix bis zu den Rändern der Matrix zu erweitern, indem gefälschte Pixel eingefügt werden. Dies geschieht, um der Tatsache entgegenzuwirken, dass die Konvolution die Matrixgröße verringert. Beispielsweise kann eine 9x9-Matrix nach dem Filtern in eine 3x3-Matrix umgewandelt werden.
- Striding: Wenn Sie eine Ausgabe erhalten möchten, die kleiner als Ihre Eingabe ist, können Sie Striding durchführen. Es ermöglicht, bestimmte Bereiche zu überspringen, während der Filter über das Bild gleitet. Durch das Überspringen von zwei oder drei Pixeln können Sie ein effizienteres Netzwerk erstellen, indem Sie die räumliche Auflösung reduzieren.
- Gewichte und Bias: CNNs haben Gewichte und Bias in ihren Neuronen. Ein Modell kann diese Werte während des Trainings lernen, und die Werte bleiben in einer bestimmten Schicht für alle Neuronen gleich. Dies bedeutet, dass jedes verborgene Neuron dieselben Merkmale in verschiedenen Bereichen eines Bildes erkennt. Dies macht das Netzwerk toleranter gegenüber der Verschiebung von Objekten in einem bestimmten Bild.
- ReLU: Steht für Rectified Linear Unit (ReLu) und wird für ein effektiveres und schnelleres Training verwendet. Negative Werte werden auf 0 abgebildet, während positive Werte beibehalten werden. Es wird auch als Aktivierung bezeichnet, da das Netzwerk nur die aktivierten Bildmerkmale in die nächste Schicht überträgt.
- Rezeptives Feld: In einem neuronalen Netz erhält jedes Neuron Eingaben von verschiedenen Stellen der vorherigen Schicht. In Konvolutionsschichten erhält jedes Neuron Eingaben von einem begrenzten Bereich der vorherigen Schicht, der als rezeptives Feld des Neurons bezeichnet wird. Bei einer FC-Schicht ist die gesamte vorherige Schicht das rezeptive Feld.
Bei realen Berechnungsaufgaben wird die Konvolution in der Regel mit einem 3D-Bild durchgeführt, was einen 3D-Filter erfordert.
Zurück zu CNNs: Sie bestehen aus verschiedenen Teilen oder Knotenschichten. Jede Knotenschicht hat einen Schwellenwert und eine Gewichtung und ist mit einer anderen verbunden. Wenn der Schwellenwert überschritten wird, werden die Daten an die nächste Schicht in diesem Netzwerk weitergeleitet.
Diese Schichten können Operationen ausführen, um die Daten zu verändern und relevante Merkmale zu lernen. Diese Operationen werden in hunderten verschiedener Schichten wiederholt, die fortlaufend andere Merkmale eines Bildes zu erkennen lernen.
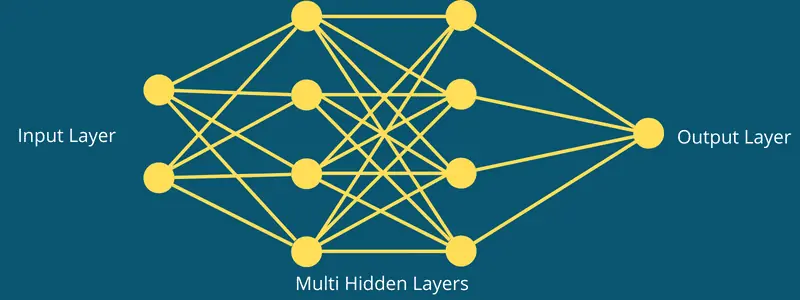
Die Komponenten eines CNN sind:
- Eine Eingabeschicht: Hier erfolgt die Eingabe, beispielsweise ein Bild. Es ist ein 3D-Objekt mit einer definierten Höhe, Breite und Tiefe.
- Eine oder mehrere verborgene Schichten oder Merkmalsextraktionsphasen: Diese Schichten können Konvolutionsschichten, Pooling-Schichten und vollständig verbundene Schichten sein.
- Eine Ausgabeschicht: Hier wird das Ergebnis angezeigt.
Das Durchlaufen eines Bildes durch die Konvolutionsschicht wird in eine Feature-Map oder Aktivierungskarte umgewandelt. Nach der Faltung der Eingabe falten die Schichten das Bild und übergeben das Ergebnis an die nächste Schicht.
Das CNN führt viele Faltungs- und Pooling-Techniken durch, um die Merkmale während der Merkmalsextraktionsphase zu erkennen. Wenn Sie zum Beispiel das Bild einer Katze eingeben, erkennt das CNN ihre vier Beine, ihre Farbe, zwei Augen usw.
Anschließend fungieren vollständig verbundene Schichten in einem CNN als Klassifikator für die extrahierten Merkmale. Basierend auf den Vorhersagen des Deep-Learning-Algorithmus zum Bild liefern die Schichten das Ergebnis.
Vorteile von CNNs

Höhere Präzision
CNNs bieten eine höhere Genauigkeit als herkömmliche neuronale Netze ohne Konvolution. CNNs sind besonders nützlich, wenn die Aufgabe große Datenmengen, Video- und Bilderkennung usw. umfasst. Sie liefern hochpräzise Ergebnisse und Vorhersagen, weshalb ihre Verwendung in verschiedenen Sektoren zunimmt.
Recheneffizienz

CNNs bieten eine höhere Recheneffizienz als andere herkömmliche neuronale Netze. Dies ist auf die Verwendung des Konvolutionsprozesses zurückzuführen. Sie nutzen außerdem Dimensionsreduktion und Parameterfreigabe, um die Modelle schneller und einfacher bereitzustellen. Diese Techniken können auch optimiert werden, um auf verschiedenen Geräten zu funktionieren, sei es Ihr Smartphone oder Laptop.
Feature-Extraktion
CNNs können die Merkmale eines Bildes ohne manuelle Anpassung leicht lernen. Sie können vortrainierte CNNs nutzen und die Gewichte anpassen, indem Sie ihnen neue Daten zuführen. CNNs passen sich neuen Aufgaben nahtlos an.
Anwendungsbereiche von CNNs
CNNs werden in verschiedenen Branchen für viele Anwendungsfälle eingesetzt. Hier sind einige konkrete Anwendungsbeispiele für CNNs:
Bildklassifizierung
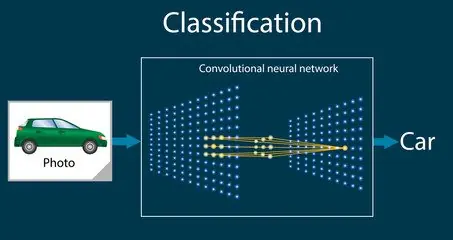
CNNs werden häufig für die Bildklassifizierung eingesetzt. Sie können wertvolle Merkmale erkennen und Objekte in einem bestimmten Bild identifizieren. Daher werden sie in Bereichen wie dem Gesundheitswesen, insbesondere bei MRTs, eingesetzt. Darüber hinaus wird diese Technologie bei der Erkennung handschriftlicher Ziffern verwendet, die zu den frühesten Anwendungsfällen von CNNs in der Computer Vision gehört.
Objekterkennung
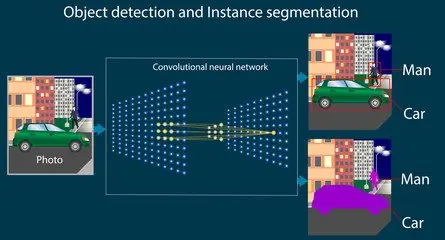
CNNs können Objekte in Bildern in Echtzeit erkennen, kennzeichnen und klassifizieren. Daher findet diese Technologie in automatisierten Fahrzeugen breite Anwendung. Sie ermöglicht Smart Homes und Fußgängern auch die Gesichtserkennung von Fahrzeugbesitzern. Sie wird auch in KI-gestützten Überwachungssystemen zur Objekterkennung und -kennzeichnung verwendet.
Audiovisuelle Abstimmung
Die Unterstützung von CNNs bei der audiovisuellen Abstimmung trägt zur Verbesserung von Video-Streaming-Plattformen wie Netflix, YouTube usw. bei. Sie hilft auch bei der Erfüllung von Benutzeranfragen wie "Liebeslieder von Elton John".
Spracherkennung

Neben Bildern sind CNNs auch bei der Verarbeitung natürlicher Sprache (NLP) und der Spracherkennung hilfreich. Ein konkretes Beispiel dafür ist Google, das CNNs in seinem Spracherkennungssystem einsetzt.
Objektrekonstruktion
CNNs können für die 3D-Modellierung eines realen Objekts in einer digitalen Umgebung verwendet werden. Es ist auch möglich, dass CNN-Modelle ein 3D-Gesichtsmodell anhand eines einzigen Bildes erstellen. Darüber hinaus ist CNN bei der Konstruktion von digitalen Zwillingen in der Biotechnologie, Fertigung, und Architektur nützlich.
Die Anwendung von CNNs in verschiedenen Sektoren umfasst:
- Gesundheitswesen: Computer Vision kann in der Radiologie eingesetzt werden, um Ärzten zu helfen, Krebstumore bei Patienten effizienter zu erkennen.
- Landwirtschaft: Die Netzwerke können Bilder von künstlichen Satelliten wie LSAT verwenden und diese Daten zur Klassifizierung von fruchtbarem Land nutzen. Dies hilft auch bei der Vorhersage der Bodenfruchtbarkeit und bei der Entwicklung einer effektiven Strategie zur Ertragsmaximierung.
- Marketing: Social-Media-Anwendungen können eine Person auf einem Bild vorschlagen, das im Profil einer Person gepostet wurde. Dies hilft Ihnen, Personen in Ihren Fotoalben zu markieren.
- Einzelhandel: E-Commerce-Plattformen können visuelle Suche verwenden, um Marken dabei zu unterstützen, relevante Artikel zu empfehlen, die die Zielkunden wahrscheinlich kaufen möchten.
- Automobil: CNNs werden in der Automobilindustrie eingesetzt, um die Sicherheit von Passagieren und Fahrern zu erhöhen. Dies geschieht mithilfe von Funktionen wie Spurerkennung, Objekterkennung, Bildklassifizierung usw. Dies treibt auch die Weiterentwicklung des autonomen Fahrens voran.
Ressourcen zum Erlernen von CNNs
Coursera:
Coursera bietet einen Kurs zu CNNs an, den Sie belegen können. In diesem Kurs lernen Sie, wie sich Computer Vision im Laufe der Zeit entwickelt hat und welche Anwendungen CNNs in der modernen Welt finden.
Amazon:
Sie können diese Bücher und Vorträge lesen, um mehr über CNNs zu erfahren:
- Neuronale Netze und Deep Learning: Es behandelt Modelle, Algorithmen und die Theorie des Deep Learning und neuronaler Netze.
- A Guide to Convolutional Neural Networks for Computer Vision: In diesem Buch lernen Sie die Anwendungen von CNNs und ihre Konzepte kennen.
- Hands-on Convolutional Neural Networks with Tensorflow: Mit Hilfe dieses Buches können Sie verschiedene Probleme in der Computer Vision mit Python und TensorFlow lösen.
- Angewandtes Deep Learning für Fortgeschrittene: Dieses Buch hilft Ihnen, CNNs, Deep Learning und ihre fortgeschrittenen Anwendungen, einschließlich Objekterkennung, zu verstehen.
- Convolutional Neural Networks and Recurrent Neural Networks: In diesem Buch erfahren Sie mehr über CNNs und RNNs und wie Sie diese Netzwerke aufbauen.
Fazit
Konvolutionale neuronale Netze sind ein aufstrebendes Feld in der künstlichen Intelligenz, dem maschinellen Lernen und dem Deep Learning. Sie haben vielfältige Anwendungen in der heutigen Welt in fast allen Bereichen. Angesichts ihrer wachsenden Bedeutung wird erwartet, dass sie sich weiterentwickeln und bei der Bewältigung realer Probleme noch nützlicher werden.
