
Az évek során a python adattudományi felhasználása hihetetlenül megnőtt, és napról napra növekszik.
Az adattudomány hatalmas tudományterület, rengeteg részterülettel, amelyek közül az adatelemzés vitathatatlanul az egyik legfontosabb ezek közül a területek közül, és függetlenül attól, hogy valaki milyen tudásszinttel rendelkezik adattudományban, egyre fontosabbá vált annak megértése, ill. legalább alapvető ismeretei vannak róla.
Tartalomjegyzék
Mi az adatelemzés?
Az adatelemzés nagy mennyiségű strukturálatlan vagy rendezetlen adat megtisztítása és átalakítása azzal a céllal, hogy ezekről az adatokról olyan kulcsfontosságú betekintést és információt generáljon, amely elősegíti a megalapozott döntések meghozatalát.
Az adatelemzéshez különféle eszközöket használnak, mint például a Python, a Microsoft Excel, a Tableau, az SaS stb., de ebben a cikkben arra összpontosítunk, hogyan történik az adatelemzés a pythonban. Pontosabban, hogyan történik ez egy python könyvtárral Pandák.
Mi az a Pandas?
A Pandas egy nyílt forráskódú Python-könyvtár, amelyet adatkezelésre és vitákra használnak. Gyors és rendkívül hatékony, és számos adat tárolására alkalmas eszközökkel rendelkezik. Használható többféle adatforma átformálására, szelet címkézésére, indexelésére vagy akár csoportosítására is.
Adatstruktúrák a pandákban
A Pandákban 3 adatstruktúra található, nevezetesen;
A legjobb módja annak, hogy megkülönböztessük a hármat, ha úgy látjuk, hogy az egyikben több halom van a másikban. Tehát a DataFrame sorozatok halma, a Panel pedig DataFrame halom.
A sorozat egy egydimenziós tömb
Több sorozatból álló halom kétdimenziós DataFrame-et alkot
A több DataFrame-ből álló halom háromdimenziós panelt alkot
Az adatstruktúra, amellyel a legtöbbet dolgoznánk, a 2-dimenziós DataFrame, amely bizonyos adatkészletek alapértelmezett megjelenítési eszköze is lehet, amellyel találkozhatunk.
Adatelemzés Pandákban
Ehhez a cikkhez nincs szükség telepítésre. nevű eszközt használnánk laboratórium a Google készítette. Ez egy online Python-környezet adatelemzéshez, gépi tanuláshoz és mesterséges intelligenciához. Ez egyszerűen egy felhőalapú Jupyter Notebook, amely szinte minden python-csomaggal előre telepítve érkezik, amelyre adattudósként szüksége lenne.
Most pedig irány https://colab.research.google.com/notebooks/intro.ipynb. Az alábbiakat látnod kell.
A bal felső sarokban kattintson a fájl opcióra, majd az „új jegyzetfüzet” lehetőségre. Egy új Jupyter-jegyzetfüzet-oldal jelenik meg a böngészőben. Az első dolog, amit tennünk kell, az az, hogy pandákat importáljunk a munkakörnyezetünkbe. Ezt a következő kód futtatásával tehetjük meg;
import pandas as pd
Ebben a cikkben egy lakásárak adatkészletet használnánk adatelemzésünkhöz. Az általunk használt adatkészlet megtalálható itt. Az első dolog, amit meg szeretnénk tenni, az az, hogy betöltjük ezt az adatkészletet a környezetünkbe.
Ezt megtehetjük a következő kóddal egy új cellában;
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
A .read_csv akkor használatos, ha egy CSV-fájlt szeretnénk olvasni, és átadtunk egy sep tulajdonságot, amely megmutatja, hogy a CSV-fájl vesszővel tagolt.
Azt is meg kell jegyeznünk, hogy a betöltött CSV fájlunk egy df változóban van tárolva.
Nem kell használnunk a print() függvényt a Jupyter Notebookban. Egyszerűen beírhatunk egy változónevet a cellánkba, és a Jupyter Notebook kinyomtatja helyettünk.
Kipróbálhatjuk úgy, hogy beírjuk a df parancsot egy új cellába, és lefuttatjuk, az adatkészletünkben lévő összes adatot DataFrame-ként nyomtatja ki számunkra.
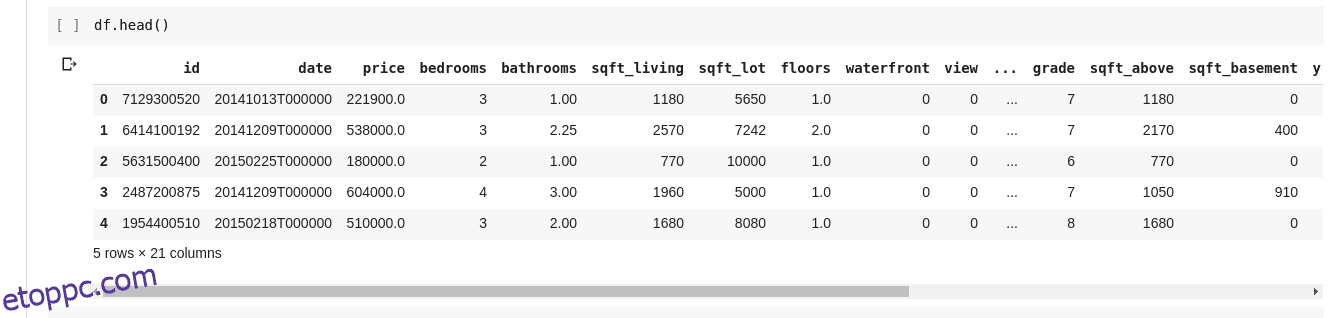
De nem mindig szeretnénk látni az összes adatot, időnként csak az első néhány adatot és azok oszlopnevét szeretnénk látni. Használhatjuk a df.head() függvényt az első öt oszlop kinyomtatására, a df.tail() függvényt pedig az utolsó öt oszlop kinyomtatására. A kettő közül bármelyik kimenete így nézne ki;
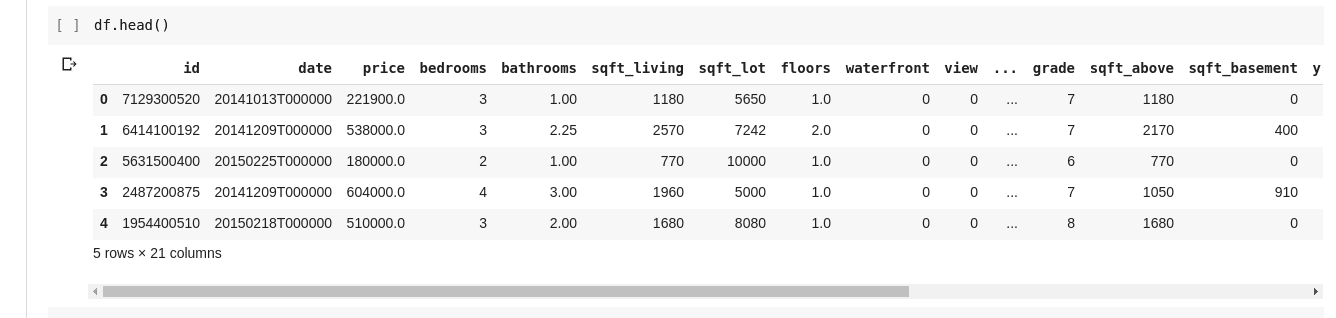
Szeretnénk ellenőrizni, hogy vannak-e kapcsolatok ezen több adatsor és -oszlop között. A .describe() függvény pontosan ezt teszi helyettünk.
A df.describe() futtatása a következő kimenetet adja;
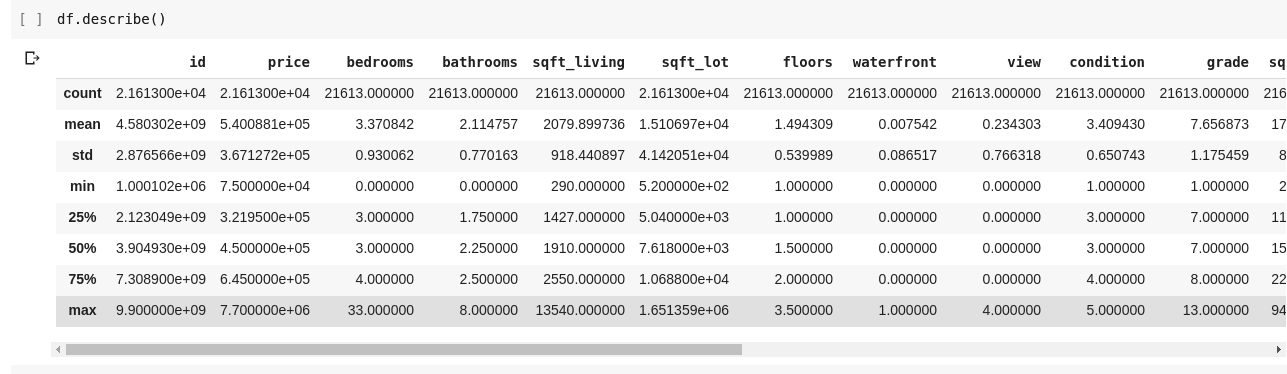
Azonnal láthatjuk, hogy a .describe() megadja a DataFrame minden egyes oszlopának átlagát, szórását, minimális és maximum értékét, százalékos értékét. Ez különösen hasznos.
A 2D DataFrame alakját is ellenőrizhetjük, hogy megtudjuk, hány sorból és oszlopból áll. Ezt megtehetjük a df.shape segítségével, amely egy sort ad vissza formátumban (sorok, oszlopok).
A DataFrame-ünkben lévő összes oszlop nevét is ellenőrizhetjük a df.columns használatával.
Mi a teendő, ha csak egy oszlopot akarunk kijelölni, és abban az összes adatot visszaadni? Ez hasonló módon történik, mint egy szótárban. Írja be a következő kódot egy új cellába, és futtassa
df['price ']
A fenti kód visszaadja az ár oszlopot, tovább mehetünk, ha egy új változóba mentjük, mint olyan
price = df['price']
Mostantól minden más műveletet elvégezhetünk, amelyet egy DataFrame-en végrehajthatunk az árváltozónkon, mivel ez csak egy részhalmaza a tényleges DataFrame-nek. Csinálhatunk például df.head(), df.shape stb.
Több oszlopot is kiválaszthatunk úgy, hogy az oszlopnevek listáját átadjuk a df-nek
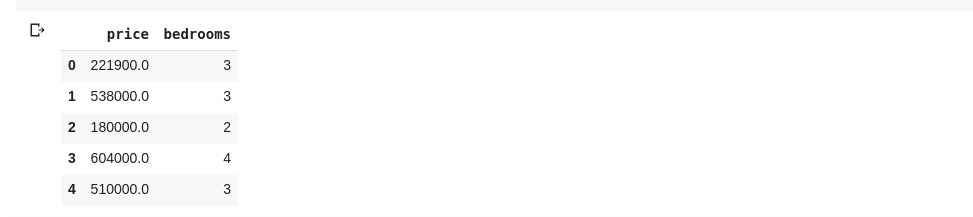
data = df[['price ', 'bedrooms']]
A fenti ‘ár’ és ‘hálószoba’ nevű oszlopokat jelöl ki, ha egy új cellába beírjuk a data.head() parancsot, akkor a következőket kapjuk
Az oszlopok felszeletelésének fenti módja az adott oszlop összes sorelemét adja vissza. Mi van, ha az adatkészletünkből a sorok egy részhalmazát és az oszlopok egy részhalmazát szeretnénk visszaadni? Ez megtehető az .iloc használatával, és a python listákhoz hasonló módon indexelhető. Tehát valami ilyesmit tehetünk
df.iloc[50: , 3]
Ez visszaadja a 3. oszlopot az 50. sortól a végéig. Nagyon ügyes, és pont olyan, mint a python listák szeletelése.
Most csináljunk néhány igazán érdekes dolgot, a lakásárak adatkészletünkben van egy oszlop, amely egy ház árát mutatja meg, egy másik oszlop pedig az adott házban található hálószobák számát. A lakásárak folyamatos érték, így elképzelhető, hogy nincs két azonos árú házunk. De a hálószobák száma kissé diszkrét, így több házunk is lehet, két, három, négy hálószobával, stb.
Mi van, ha az összes házat ugyanannyi hálószobával akarjuk megszerezni, és meg akarjuk találni az egyes különálló hálószobák átlagos árát? Pandáknál ezt viszonylag könnyű megtenni, úgy is meg lehet csinálni;
df.groupby('bedrooms ')['price '].mean()
A fentiek először az azonos hálószobaszámú adatkészletek szerint csoportosítják a DataFrame-et a df.groupby() függvény segítségével, majd azt mondjuk neki, hogy csak a hálószoba oszlopot adja meg, és a .mean() függvény segítségével keresse meg az adatkészletben lévő egyes házak átlagát. .
Mi van, ha a fentieket szeretnénk vizualizálni? Szeretnénk ellenőrizni, hogyan változik az egyes hálószobák átlagos ára? Csak egy .plot() függvényhez kell láncolnunk az előző kódot;
df.groupby('bedrooms ')['price '].mean().plot()
Lesz egy olyan kimenetünk, amely így néz ki;
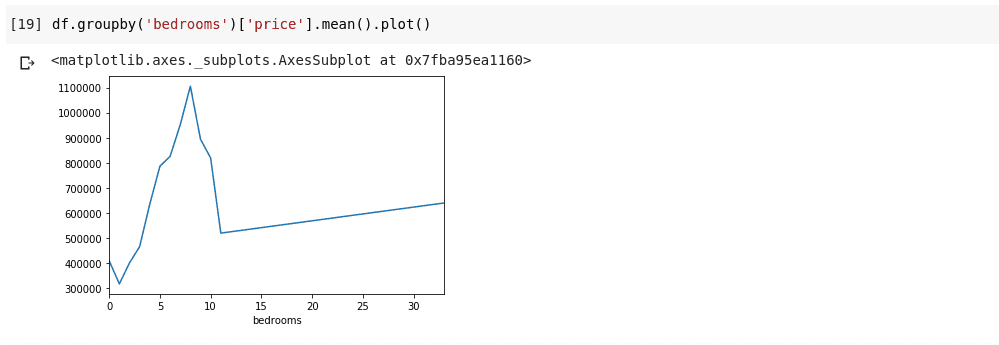
A fentiek az adatok néhány tendenciáját mutatják be. A vízszintes tengelyen jól elkülöníthető számú hálószoba van (megjegyzendő, hogy egynél több házban lehet X számú hálószoba), a függőleges tengelyen a vízszintes hálószoba megfelelő számára vonatkozó árak átlaga. tengely. Most azonnal észrevehetjük, hogy az 5-10 hálószobás házak sokkal többe kerülnek, mint a 3 hálószobás házak. Az is nyilvánvalóvá válik, hogy a 7-8 hálószobás házak sokkal többe kerülnek, mint a 15, 20 vagy akár 30 szobás házak.
A fentiekhez hasonló információk miatt nagyon fontos az adatelemzés, olyan hasznos betekintést tudunk nyerni az adatokból, amelyeket elemzés nélkül nem lehet azonnal észrevenni.
Hiányzó adatok
Tegyük fel, hogy egy felmérésben veszek részt, amely egy sor kérdésből áll. A felmérés linkjét több ezer emberrel osztom meg, hogy visszajelzést adhassanak. Végső célom az, hogy adatelemzést végezzek ezeken az adatokon, hogy néhány kulcsfontosságú betekintést nyerhessek az adatokból.
Most sok minden elromolhat, egyes földmérők kényelmetlenül érzik magukat, ha válaszolnak néhány kérdésemre, és üresen hagyják. Sokan megtehetik ugyanezt a felmérési kérdéseim több részében. Lehet, hogy ez nem tekinthető problémának, de képzeljük el, ha numerikus adatokat gyűjtök a felmérésem során, és az elemzés egy része azt igényelné, hogy megkapjam az összeget, az átlagot vagy más számtani műveletet. Több hiányzó érték sok pontatlansághoz vezetne az elemzésemben, ki kell találnom a módját, hogy megtaláljam és pótolhassam ezeket a hiányzó értékeket néhány olyan értékkel, amely ezek közeli helyettesítője lehet.
A Pandák egy függvényt biztosítanak számunkra, amellyel megkereshetjük a hiányzó értékeket egy DataFrame-ben, az isnull().
Az isnull() függvény önmagában is használható;
df.isnull()
Ez egy logikai értékekből álló DataFrame-et ad vissza, amely megmondja, hogy az eredetileg ott található adatok valóban hiányoznak-e vagy hamisan hiányoztak. A kimenet így nézne ki;
Szükségünk van egy módra, hogy ezeket a hiányzó értékeket pótoljuk, legtöbbször a hiányzó értékek kiválasztása nullának tekinthető. Időnként az összes többi adat átlagának vagy esetleg a körülötte lévő adatok átlagának tekinthető, az adattudóstól és az elemzett adatok felhasználási esetétől függően.
A DataFrame összes hiányzó értékének kitöltéséhez a használt .fillna() függvényt használjuk;
df.fillna(0)
A fentiekben az összes üres adatot nulla értékkel töltjük ki. Bármilyen más szám is lehet, amelyet megadunk.
Az adatok fontosságát nem lehet eléggé hangsúlyozni, ezek segítenek abban, hogy magukból az adatokból kapjunk választ! Az adatelemzés szerintük az új olaj a digitális gazdaságokhoz.
A cikkben szereplő összes példa megtalálható itt.
Ha többet szeretne megtudni, nézze meg Adatelemzés Python és Pandas segítségével online tanfolyam.