

2020. szeptember 1-jén az NVIDIA bemutatta új játék GPU-kínálatát: az Ampere architektúrán alapuló RTX 3000 sorozatot. Megvitatjuk az újdonságokat, a hozzá tartozó AI-alapú szoftvert, és minden olyan részletet, amely igazán fantasztikussá teszi ezt a generációt.
Tartalomjegyzék
Ismerje meg az RTX 3000 sorozatú GPU-kat

Az NVIDIA fő bejelentése a fényes új GPU-k volt, amelyek mindegyike egyedi 8 nm-es gyártási folyamatra épül, és mindegyik jelentős gyorsulást hozott mind a raszterezés, mind a sugárkövetési teljesítmény terén.
A felállás alsó részén ott van a RTX 3070, melynek ára 499 dollár. Kicsit drága az NVIDIA által a kezdeti bejelentéskor bemutatott legolcsóbb kártya, de ha megtudja, hogy felülmúlja a meglévő RTX 2080 Ti kártyát, a csúcskategóriás kártyát, amelyet rendszeresen 1400 dollár felett árulnak, ez abszolút lopás. Az NVIDIA bejelentése után azonban a harmadik felek eladási ára csökkent, és nagy részüket pánikszerűen értékesítették az eBay-en 600 dollár alatt.
A bejelentés óta nincsenek szilárd benchmarkok, így nem világos, hogy a kártya objektíve valóban „jobb”-e, mint egy 2080 Ti, vagy az NVIDIA kicsit csavarja a marketinget. A futtatott benchmarkok 4K-n voltak, és valószínűleg be volt kapcsolva az RTX, ami miatt a különbség nagyobbnak tűnhet, mint a tisztán raszteres játékokban, mivel az Ampere-alapú 3000-es sorozat kétszer jobban teljesít a sugárkövetésben, mint a Turing. De mivel a sugárkövetés ma már nem rontja a teljesítményt, és a konzolok legújabb generációja is támogatja, jelentős értékesítési pont, hogy az ár csaknem harmadáért olyan gyorsan fut, mint az előző generáció zászlóshajója.
Az sem világos, hogy az ár így marad-e. A harmadik féltől származó dizájnok rendszeresen legalább 50 dollárral növelik az árcédulát, és mivel valószínűleg nagy lesz a kereslet, nem lesz meglepő, ha 2020 októberében 600 dollárért adják el.
Közvetlenül e fölött van a RTX 3080 699 dollárért, ami kétszer olyan gyors, mint az RTX 2080, és körülbelül 25-30%-kal gyorsabb, mint a 3080.
Aztán a legfelső végén az új zászlóshajó a RTX 3090, ami komikusan hatalmas. Az NVIDIA jól tudja, és „BFGPU-ként” emlegette, ami a vállalat szerint a „Big Ferocious GPU” rövidítése.

Az NVIDIA nem mutatott be semmilyen közvetlen teljesítménymutatót, de a cég megmutatta, hogy 8K-s játékokat futtat 60 FPS-sel, ami komolyan lenyűgöző. Igaz, az NVIDIA szinte biztosan DLSS-t használ, hogy elérje ezt a célt, de a 8K játék az 8K játék.
Természetesen végül lesz 3060, és a költségvetés-orientált kártyák egyéb változatai, de ezek általában később jönnek be.
Ahhoz, hogy valóban lehűtse a dolgokat, az NVIDIA-nak megújult hűtő kialakításra volt szüksége. A 3080-as teljesítménye 320 watt, ami elég magas, ezért az NVIDIA a dupla ventilátoros kialakítást választotta, de mindkét ventilátor alulra helyezett vwinf helyett az NVIDIA a felső végére, ahova a hátlap általában kerül, egy ventilátort helyezett el. A ventilátor felfelé irányítja a levegőt a CPU-hűtő és a ház teteje felé.

Abból ítélve, hogy a rossz légáramlás mennyiben befolyásolhatja a teljesítményt egy tokban, ez teljesen logikus. Emiatt azonban az áramköri lap nagyon szűk, ami valószínűleg hatással lesz a harmadik fél eladási áraira.
DLSS: Szoftverelőny
A sugárkövetés nem az egyetlen előnye ezeknek az új kártyáknak. Valójában ez az egész egy kis hack – az RTX 2000-es sorozat és a 3000-es sorozat nem sokkal jobb a tényleges sugárkövetésben, mint a régebbi generációs kártyák. A teljes jelenet sugárkövetése a 3D-s szoftverekben, például a Blenderben, képkockánként általában néhány másodpercet vagy akár percet vesz igénybe, így a 10 ezredmásodperc alatti durva erőltetés szóba sem jöhet.
Természetesen létezik dedikált hardver a sugárszámítások futtatásához, az úgynevezett RT magok, de az NVIDIA nagyrészt más megközelítést választott. Az NVIDIA továbbfejlesztette a zajcsillapító algoritmusokat, amelyek lehetővé teszik a GPU-k számára, hogy egy nagyon olcsó egyszeri menetet adjanak le, ami borzasztóan néz ki, és valahogyan – az AI varázslat révén – ezt olyanná alakítsák, amit a játékosok látni akarnak. A hagyományos raszterezésen alapuló technikákkal kombinálva kellemes élményt nyújt, amelyet sugárkövetési effektusok fokoznak.

Ennek érdekében azonban az NVIDIA AI-specifikus feldolgozó magokat, úgynevezett Tensor magokat adott hozzá. Ezek feldolgozzák a gépi tanulási modellek futtatásához szükséges összes matematikát, és ezt nagyon gyorsan megteszik. Ők totál játékváltó a mesterséges intelligencia számára a felhőkiszolgáló térben, mivel az AI-t számos vállalat széles körben használja.
A zajtalanításon túl a Tensor magok fő felhasználási területe a játékosok számára a DLSS, vagyis a mély tanulási szupermintavételezés. Gyenge minőségű keretet vesz fel, és teljes natív minőségre skálázza fel. Ez lényegében azt jelenti, hogy 1080p szintű képkockasebességgel játszhatsz, miközben 4K-s képet nézel.
Ez némileg segíti a sugárkövetési teljesítményt is –benchmarkok a PCMagtól mutasson be egy RTX 2080 Super futóvezérlőt ultra minőségben, minden sugárkövetési beállítással a maximumra állítva. 4K-nál csak 19 FPS-sel küzd, de bekapcsolt DLSS mellett sokkal jobb 54 FPS-t kap. A DLSS ingyenes teljesítmény az NVIDIA számára, amelyet a Turing és Ampere Tensor magjai tesznek lehetővé. Bármelyik játék, amely támogatja ezt és GPU-korlátozott, komoly gyorsulásokat tapasztalhat, pusztán szoftveresen.
A DLSS nem újdonság, és az RTX 2000 sorozat két évvel ezelőtti megjelenésekor jelentették be, mint funkciót. Akkoriban nagyon kevés játék támogatta, mivel az NVIDIA-nak minden egyes játékhoz gépi tanulási modellt kellett betanítania és hangolnia.
Ez idő alatt azonban az NVIDIA teljesen átírta, az új verziót DLSS 2.0-nak nevezte el. Ez egy általános célú API, ami azt jelenti, hogy bármely fejlesztő megvalósíthatja, és a legtöbb nagyobb kiadás már használja. Ahelyett, hogy egy képkockán dolgozna, a TAA-hoz hasonlóan az előző képkockából veszi a mozgásvektor adatokat. Az eredmény sokkal élesebb, mint a DLSS 1.0, és bizonyos esetekben valóban jobban és élesebben néz ki, mint a natív felbontás, így nincs sok ok arra, hogy ne kapcsoljuk be.
Van egy fogás: a jelenetek teljes váltásakor, mint a vágójeleneteknél, a DLSS 2.0-nak a legelső képkockát 50%-os minőségben kell renderelnie, miközben a mozgásvektor adatokra vár. Ez néhány ezredmásodpercig enyhe minőségcsökkenést eredményezhet. De minden megnézett dolog 99%-a megfelelően lesz renderelve, és a legtöbb ember ezt nem veszi észre a gyakorlatban.
Ampere architektúra: mesterséges intelligencia számára készült
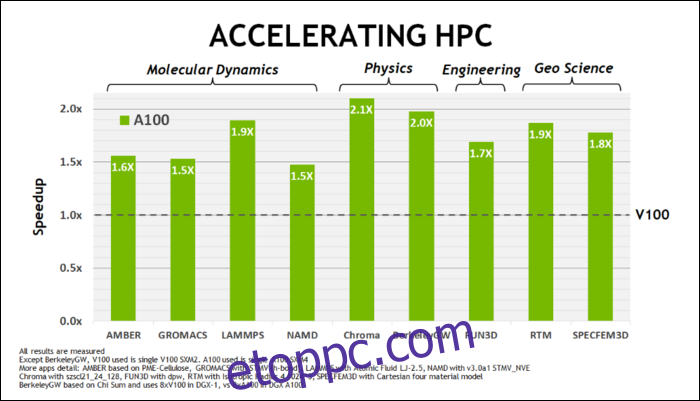
Az Amper gyors. Komolyan gyors, különösen az AI számításoknál. Az RT mag 1,7-szer gyorsabb, mint a Turing, az új Tensor mag pedig 2,7-szer gyorsabb, mint a Turing. A kettő kombinációja igazi generációs ugrás a sugárkövetési teljesítményben.

május elején, Az NVIDIA kiadta az Ampere A100 GPU-t, egy adatközponti GPU, amelyet mesterséges intelligencia futtatására terveztek. Ezzel sokat részleteztek, hogy mi teszi az Ampere-t sokkal gyorsabbá. Adatközponti és nagy teljesítményű számítástechnikai terhelések esetén az Ampere általában körülbelül 1,7-szer gyorsabb, mint a Turing. A mesterséges intelligencia oktatásához akár 6-szor gyorsabb.
Az Ampere segítségével az NVIDIA új számformátumot használ, amely bizonyos munkaterheléseknél az iparági szabványnak megfelelő „Floating-Point 32” vagy FP32 helyettesítésére szolgál. A motorháztető alatt a számítógép által feldolgozott minden szám előre meghatározott számú bitet foglal el a memóriában, legyen az 8 bit, 16 bit, 32, 64 vagy még nagyobb. A nagyobb számokat nehezebb feldolgozni, így ha kisebb méretet is használhat, akkor kevesebbet kell ropogtatnia.
Az FP32 32 bites decimális számot tárol, és 8 bitet használ a szám tartományához (mekkora vagy kicsi lehet), és 23 bitet a pontossághoz. Az NVIDIA azt állítja, hogy ez a 23 precíziós bit nem teljesen szükséges sok mesterséges intelligencia munkaterheléshez, és hasonló eredményeket és sokkal jobb teljesítményt érhet el mindössze 10-ből. A méret 19 bitre való csökkentése 32 helyett nagy különbséget jelent számos számítás során.
Ezt az új formátumot Tensor Float 32-nek hívják, és az A100 Tensor Core-jait a fura méretű formátum kezelésére optimalizálták. A szerszámok zsugorodása és a magszám növekedése mellett így érik el a hatalmas, hatszoros gyorsulást az AI-képzésben.

Az új számformátum mellett az Ampere jelentős teljesítménynövekedést tapasztal bizonyos számítások során, mint például az FP32 és az FP64. Ezek nem jelentenek közvetlenül több FPS-t a laikusok számára, de része annak, ami majdnem háromszor gyorsabbá teszi a Tensor műveleteket.

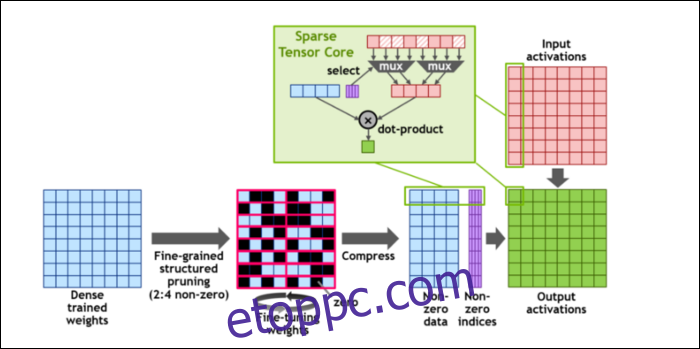
Majd a számítások felgyorsítása érdekében bevezették a fogalmat finomszemcsés szerkezetű ritkaság, ami nagyon divatos szó egy elég egyszerű fogalomra. A neurális hálózatok nagy számlistákkal, úgynevezett súlyokkal működnek, amelyek befolyásolják a végső kimenetet. Minél több számot kell összeroppantani, annál lassabb lesz.
Azonban nem mindegyik szám hasznos. Némelyikük szó szerint nulla, és alapvetően kidobható, ami hatalmas gyorsulásokhoz vezet, ha egyszerre több számot is összepréselhet. A ritkaság lényegében tömöríti a számokat, amivel kevesebb erőfeszítést kell tenni a számításokhoz. Az új „Sparse Tensor Core” tömörített adatokra épül.
A változtatások ellenére az NVIDIA szerint ez egyáltalán nem befolyásolhatja észrevehetően a betanított modellek pontosságát.
A Sparse INT8 számításokhoz, az egyik legkisebb számformátumhoz, egyetlen A100 GPU csúcsteljesítménye meghaladja az 1,25 PetaFLOP-ot, ami elképesztően magas szám. Természetesen ez csak akkor van, ha egy bizonyos típusú számot csikorgat, de ennek ellenére lenyűgöző.