

A cat and tac parancsok megjelenítik a szöveges fájlok tartalmát, de több van bennük, mint amilyennek látszik. Merüljön el egy kicsit mélyebben, és tanuljon meg néhány hatékony Linux parancssori trükköt.
Ez két egyszerű kis parancs, amelyeket gyakran úgy utasítanak el, hogy azok – túl egyszerűek ahhoz, hogy valódi hasznot húzzanak. De ha már ismeri a használatuk különböző módjait, látni fogja, hogy tökéletesen képesek kivenni a rájuk eső részt a nehéz teherbírásból, ha fájlokkal kell dolgozni.
Tartalomjegyzék
A macska parancs
macska szokott vizsgálja meg a szöveges fájlok tartalmát, valamint a fájlok egyes részeinek egyesítése nagyobb fájl létrehozásához.
Egy időben – még a betárcsázós korszakban modem– A bináris fájlokat gyakran több kisebb fájlra bontották, hogy megkönnyítsék a letöltést. Ahelyett, hogy letöltött volna egy nagy fájlt, minden kisebb fájlt visszahúzott. Ha egyetlen fájl letöltése nem sikerült megfelelően, akkor csak azt az egy fájlt kell újra letöltenie.
Természetesen ezután szükség volt egy módra, hogy a kisebb fájlok gyűjteményét visszaállítsa egyetlen működő bináris fájlba. Ezt a folyamatot összefűzésnek nevezték. És innen jött be a macska, és innen kapta a nevét.
A szélessávú és üvegszálas kapcsolatok miatt ez a különleges igény elhalványult – hasonlóan a csikorgó betárcsázó hangokhoz –, tehát mi marad ma a macskának? Valójában elég sok.
Szövegfájl megjelenítése
Ha azt szeretné, hogy a cat listázza a szöveges fájl tartalmát egy terminálablakba, használja a következő parancsot.
Győződjön meg arról, hogy a fájl szöveges fájl. Ha megpróbálja felsorolni egy bináris fájl tartalmát a terminál ablakban, az eredmények megjósolhatatlanok lesznek. Előfordulhat, hogy zárolt terminálmunkamenetet kap, vagy ami még rosszabb.
cat poem1.txt

A poem1.txt fájl tartalma megjelenik a terminál ablakában.
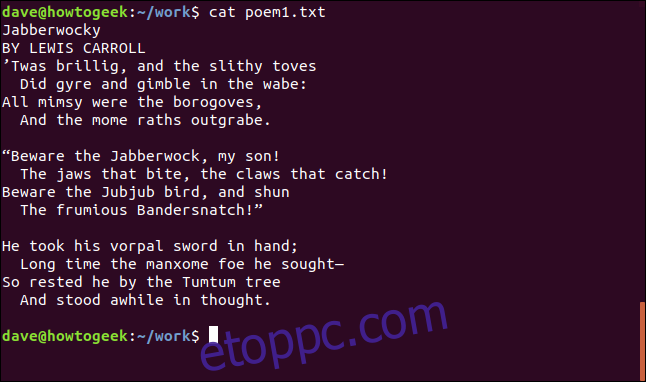
Ez csak a fele a híres versnek. Hol van a többi? Van itt egy másik fájl, a poem2.txt. Egy paranccsal több fájl tartalmát is kilistázhatjuk. Csak annyit kell tennünk, hogy a fájlokat sorrendben listázzuk a parancssorban.
cat poem1.txt poem2.txt

Ez jobban néz ki; most megvan az egész vers.

A macska használata kevesebbel
A vers megvan, de túl gyorsan száguldott el az ablakon ahhoz, hogy elolvassa az első néhány versszakot. A cat kimenetét lecsövezhetjük a lessbe, és a saját tempónkban görgethetjük lefelé a szöveget.
cat poem1.txt poem2.txt | less

Mostantól egy adatfolyamban lépkedhetünk előre és hátra a szövegben, még akkor is, ha két külön szövegfájlban van tárolva.

Sorok számozása egy fájlban
Megszámozhatjuk a fájl sorait, ahogy az megjelenik. Ehhez az -n (szám) opciót használjuk.
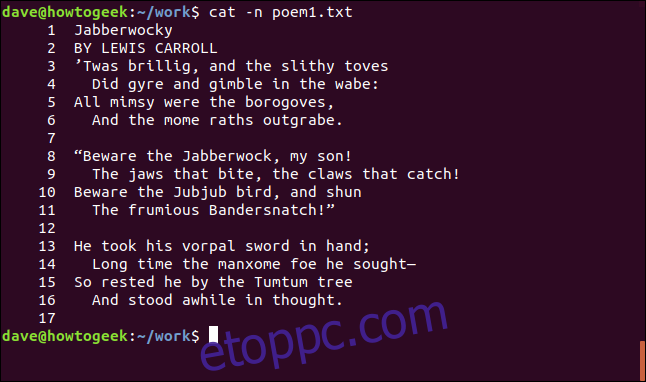
cat -n poem1.txt

A sorok úgy vannak számozva, ahogy a terminál ablakában megjelennek.
Ne számozzon üres sorokat
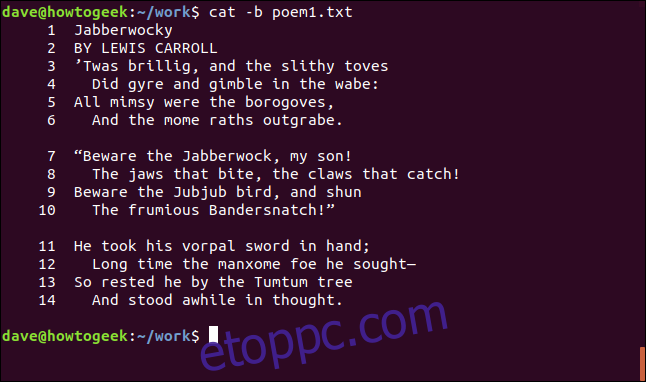
Sikerült a sorokat macskánként számozni, de a versek közötti üres sorokat is számoljuk. A szövegsorok számozásához, de az üres sorok figyelmen kívül hagyásához használja a -b (szám nem üres) kapcsolót.
cat -b poem1.txt

Most a szövegsorok meg vannak számozva, és az üres sorok kimaradnak.
Ne jelenítsen meg több üres sort
Ha egy fájlban vannak egymást követő üres sorok szakaszai, megkérhetjük a cat-ot, hogy egy üres sor kivételével figyelmen kívül hagyja az összes üres sort. Nézd meg ezt a fájlt.

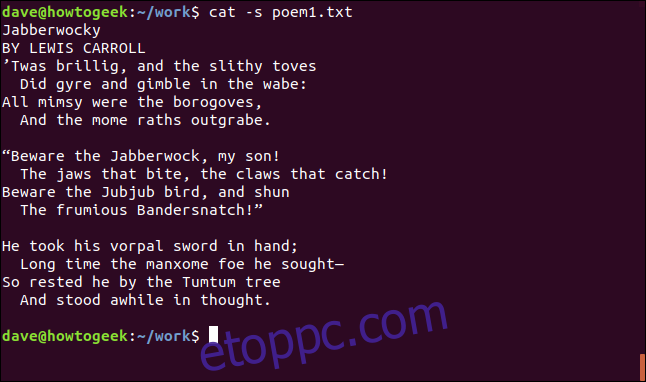
A következő parancs hatására a cat csak egy üres sort jelenít meg minden üres sorból. Ennek eléréséhez a -s (squeeze-blank) opcióra van szükségünk.
cat -s poem1.txt

Ez semmilyen módon nem befolyásolja a fájl tartalmát; csak megváltoztatja a macska a fájl megjelenítési módját.
Lapok megjelenítése
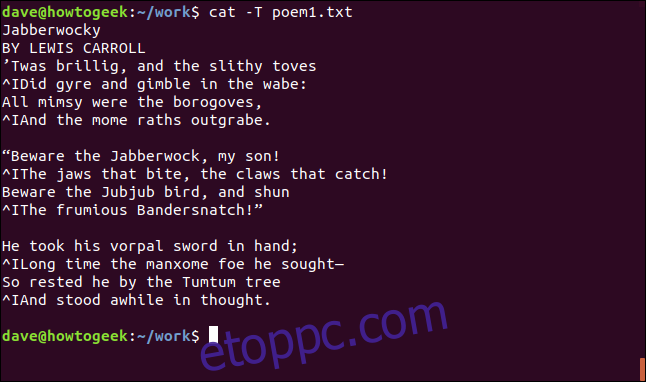
Ha tudni szeretné, hogy a szóközt szóközök vagy tabulátorok okozzák-e, a -T (tabulátorok megjelenítése) opcióval megtudhatja.
cat -T poem1.txt

A tabulátorokat a „^I” karakterek jelölik.
A sorvégek megjelenítése
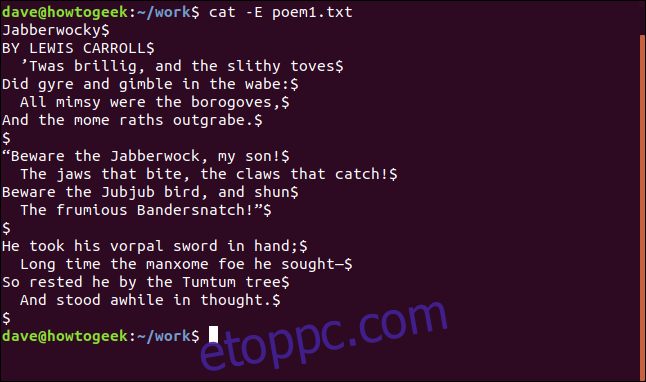
Az -E (show-ends) kapcsolóval ellenőrizheti a szóközöket a végén.
cat -E poem1.txt

A sorok végeit a „$” karakter jelöli.
Fájlok összefűzése
Nincs értelme egy verset két fájlba menteni, mindegyikben egy-egy felével. Csatlakoztassuk őket, és készítsünk egy új fájlt a teljes verssel.
cat poem1.txt poem2.txt > jabberwocky.txt

Új fájlunk a másik két fájl tartalmát tartalmazza.

Szöveg hozzáfűzése egy meglévő fájlhoz
Ez jobb, de valójában nem az egész vers. Az utolsó versszak hiányzik. A Jabberwocky utolsó verse megegyezik az első versszakkal.
Ha megvan az első versszak egy fájlban, akkor ezt hozzáadhatjuk a jabberwocky.txt fájl aljához, és meglesz a teljes vers.
Ebben a következő parancsban a >>-t kell használnunk, nem csak a >-t. Ha egyetlen >-t használunk, felülírjuk a jabberwocky.txt fájlt. Nem akarjuk ezt csinálni. Az aljához szeretnénk szöveget fűzni.
cat first_verse.txt >> jabberwocky.txt

És végül a vers minden része együtt van.
stdin átirányítása
A bevitelt a billentyűzetről átirányíthatja egy fájlba a cat. Minden, amit beír, átirányít a fájlba, amíg meg nem nyomja a Ctrl+D billentyűket. Jegyezzük meg, hogy egyetlen >-t használunk, mert szeretnénk létrehozni a fájlt (vagy felülírni, ha létezik).
cat > my_poem.txt

Ez a hang, mint egy távoli turbina, valószínűleg Lewis Carroll nagy sebességgel forog a sírjában.
A tac parancs
A tac hasonló a cat-hoz, de felsorolja a fájlok tartalmát fordított sorrendben.
Lássuk hát:
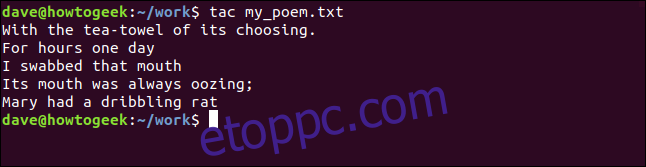
tac my_poem.txt

És a fájl fordított sorrendben jelenik meg a terminál ablakában. Ebben az esetben ennek nincs hatása az irodalmi érdemeire.
A tac használata stdinnel
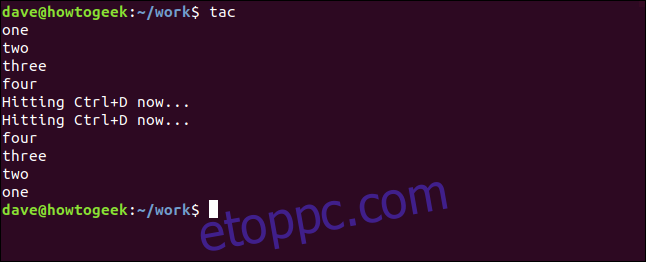
A tac fájlnév nélküli használata azt eredményezi, hogy a billentyűzetről érkező bemeneten fog működni. A Ctrl+D lenyomása leállítja a beviteli fázist, és a tac fordított sorrendben listázza ki, amit beírt.
tac

A Ctrl+D leütésekor a bevitel megfordul, és megjelenik a terminálablakban.
Tac használata naplófájlokkal
Az alacsony színvonalú szalontrükkökön kívül a tac tud valami hasznosat csinálni? Igen, tud. Sok naplófájl hozzáfűzi a legújabb bejegyzéseket a fájl aljához. A tac (és az intuitív módon a head) használatával az utolsó bejegyzést a terminálablakba ugorhatjuk.
A tac-ot használjuk a syslog fájl listázásához fordított sorrendben, és a head-be vezetjük. Ha azt mondjuk a head-nek, hogy csak az első kapott sort nyomtassa ki (ami a tac-nek köszönhetően az utolsó sor a fájlban), a rendszernaplófájl legfrissebb bejegyzését látjuk.
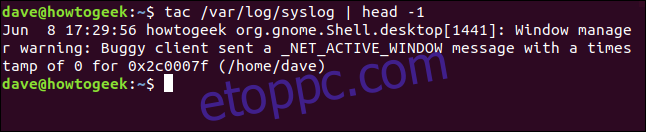
tac /var/log/syslog | head -1

fej kiírja a legfrissebb bejegyzést a syslog fájlból, majd kilép.
Vegye figyelembe, hogy a fej csak egy sort nyomtat – ahogy kértük –, de a sor olyan hosszú, hogy kétszer körbeteker. Ezért úgy néz ki, mint három sor kimenet a terminálablakban.
Tac használata a szövegrekordokkal
Az utolsó trükk, ami a kezében van, gyönyörű.
A tac általában úgy működik szöveges fájlokon, hogy soronként, alulról felfelé halad át rajtuk. A sor olyan karaktersorozat, amelyet egy újsor karakter zár le. De megmondhatjuk a tac-nak, hogy működjön együtt más határolókkal. Ez lehetővé teszi számunkra, hogy a szöveges fájlban lévő adatok „darabjait” adatrekordként kezeljük.
Tegyük fel, hogy van egy naplófájlunk valamilyen programból, amelyet át kell tekintenünk vagy elemeznünk kell. Nézzük meg a formátumát kevesebbel.
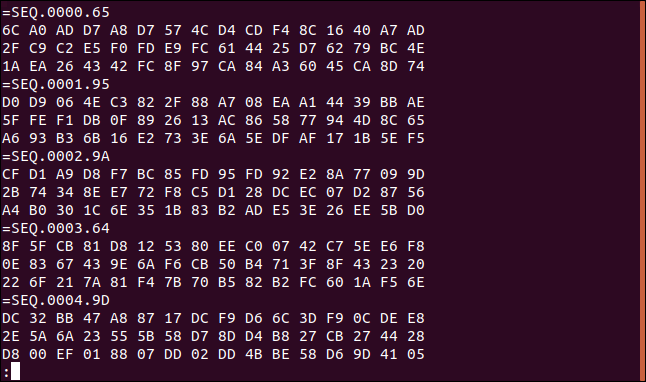
less logfile.dat

Amint látjuk, a fájlnak ismétlődő formátuma van. Három sorból álló sorozatok vannak hexadecimális értékeket. Minden három hexadecimális sorból álló készlet rendelkezik egy címkesorral, amely „=SEQ”-val kezdődik, amelyet egy számsor követ.
Ha a fájl aljára görgetünk, láthatjuk, hogy nagyon sok ilyen rekord van. Az utolsó a 865-ös számot kapta.
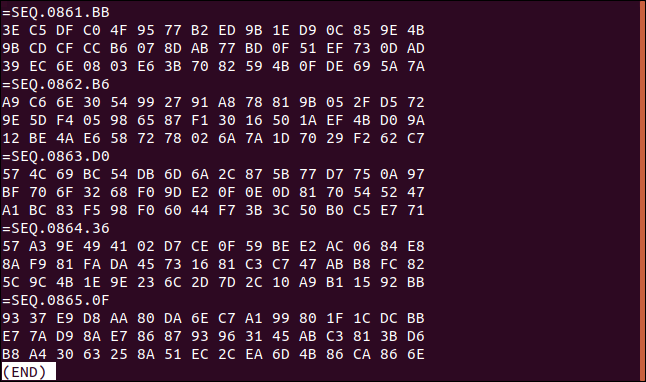
Tegyük fel, hogy bármilyen okból kifolyólag fordított sorrendben, adatrekordonként kell végigdolgoznunk ezt a fájlt. Minden adatrekordban meg kell őrizni a három hexadecimális sor sorsorrendjét.
Jegyezzük meg, hogy a fájl utolsó három sora 93, E7 és B8 hexadecimális értékekkel kezdődik, ebben a sorrendben.
Használjuk a tac-et a fájl megfordításához. Ez egy nagyon hosszú fájl, ezért rövidebbre fogjuk beírni.
tac logfile.dat | less

Ez megfordítja a fájlt, de ez nem a kívánt eredmény. Szeretnénk, ha a fájl megfordulna, de az egyes adatrekordok sorainak az eredeti sorrendben kell lenniük.
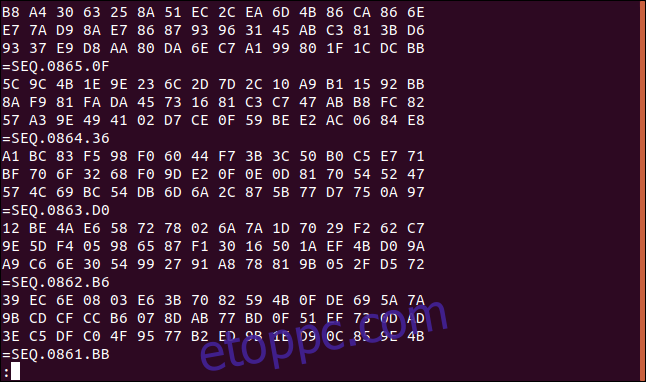
Korábban rögzítettük, hogy a fájl utolsó három sora 93, E7 és B8 hexadecimális értékekkel kezdődik, ebben a sorrendben. A sorok sorrendje megfordult. Ezenkívül a „=SEQ” sorok mostantól minden három hexadecimális sorból álló halmaz alatt vannak.
tac a megmentésre.
tac -b -r -s ^=SEQ.+[0-9]+*$ logfile.dat | less

Bontsuk szét.
Az -s (elválasztó) opció tájékoztatja a tac-et arról, hogy mit akarunk elválasztóként használni a rekordok között. Azt mondja a tac-nek, hogy ne a szokásos újsor karakterét használja, hanem az elválasztónkat használja helyette.
Az -r (regex) kapcsoló arra utasítja a tac-t, hogy az elválasztó karakterláncot a-ként kezelje reguláris kifejezés.
A -b (befor) opció hatására a tac minden rekord előtt, nem pedig utána listázza ki az elválasztót (ez az alapértelmezett elválasztó, az újsor karakter szokásos pozíciója).
Az -s (elválasztó) karakterlánc ^=SEQ.+[0-9]A +*$ megfejtése a következőképpen történik:
A ^ karakter a sor elejét jelöli. Ezt követi a =SEQ.+[0-9]+*$. Ez arra utasítja a tac-ot, hogy keresse meg a „=SEQ” minden előfordulását. egy sor elején, majd egy tetszőleges számsor követi (ezt jelöli [0-9]), és ezt követi bármely más karakterkészlet (*$ jelzéssel).
Szokás szerint az egészet kevesebbre fektetjük.
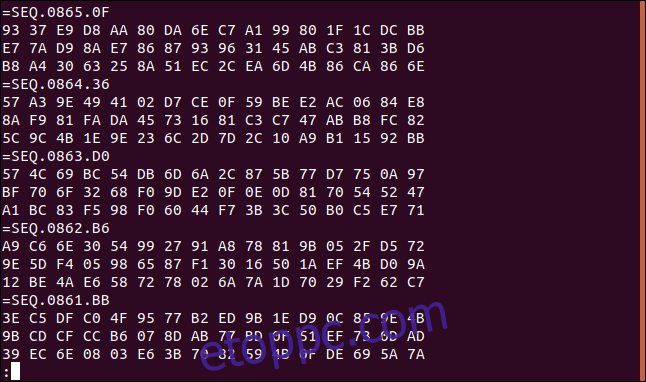
Fájlunk most fordított sorrendben jelenik meg, minden „=SEQ” címkesorral a három hexadecimális adatsor előtt. A hexadecimális értékek három sora az eredeti sorrendben van az egyes adatrekordokon belül.
Ezt egyszerűen ellenőrizhetjük. A hexadecimális szám első három sorának első értéke (amely a fájl megfordítása előtti utolsó három sor volt) megegyezik azokkal az értékekkel, amelyeket korábban vettünk fel: 93, E7 és B8, ebben a sorrendben.
Ez elég trükk a terminálablak egysoros burkolatához.
Mindennek Célja van
A Linux világában még a látszólag legegyszerűbb parancsoknak és segédprogramoknak is lehetnek meglepő és erőteljes tulajdonságaik.
Az egyszerű segédprogramok tervezési filozófiája amelyek egy dolgot jól csinálnak, és amely könnyen együttműködik más segédprogramokkal, furcsa kis parancsokat adott, mint például a tac. Első pillantásra kissé furcsanak tűnik. De amikor a felszín alá pillantasz, egy váratlan erő rejlik, amelyet a maga javára fordíthat.
Vagy, ahogy egy másik filozófia mondja: „Ne vesd meg a kígyót azért, mert nincs szarva, mert ki mondhatja, hogy nem lesz belőle sárkány?”