
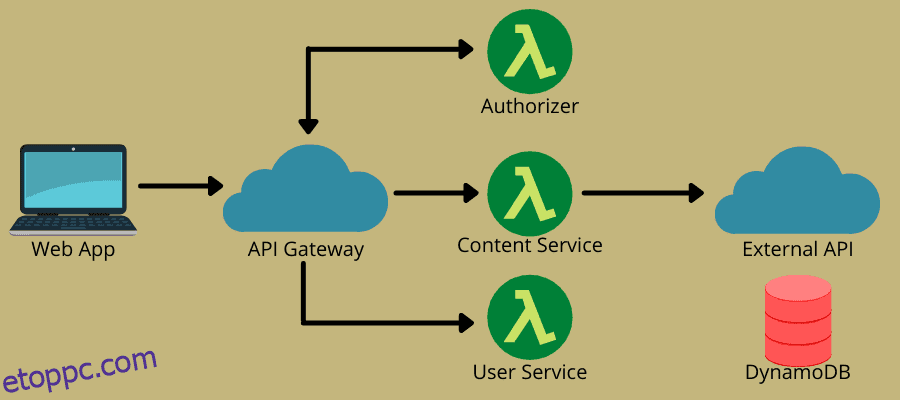
Amikor azt mondjuk, hogy „szerver nélküli” számítástechnika, sokan azt feltételezik, hogy ebben a modellben nincs olyan szerver, amely megkönnyítené a kódvégrehajtást és egyéb fejlesztési feladatokat. Ez egy egyszerű tévhit.
Tehát e mítoszromboló után talán azon gondolkodik, mi a „szerver nélküli” név mögött meghúzódó logika.
Hadd adjak egy tippet: A „nincs kiszolgáló” helyett a „szerver nélküli” kifejezés azt jelenti, HOGYAN kezelik és implementálják a szervereket.
Zavarba ejtően hangzik?
Nos, mindent megtudunk a szerver nélküli és egyéb kapcsolódó kifejezésekről, hogy eloszlassuk a kétségeit. Kezdetben a szerver nélküli egyre híresebb, ahogy beszélünk. Valójában a szerver nélküli piac valószínűleg eléri 7,7 milliárd dollár 2021-ig 1,9 milliárd dollárról 2016-ban.
Tehát beszéljük meg a szerver nélkülit, és próbáljuk meg kitalálni a népszerűsége mögött meghúzódó okot.
Tartalomjegyzék
Mi az a szerver nélküli számítástechnika?
A kiszolgáló nélküli vagy kiszolgáló nélküli számítástechnika egy felhő alapú végrehajtási modell, amelyben a felhőszolgáltatók igény szerinti gépi erőforrásokat biztosítanak, és maguk kezelik a szervereket az ügyfelek vagy a fejlesztők helyett. Ez egy olyan módszer, amely egyesíti a szolgáltatásokat, stratégiákat és gyakorlatokat, hogy segítse a fejlesztőket felhő alapú alkalmazások létrehozásában, lehetővé téve számukra, hogy a szerverkezelés helyett a kódjukra összpontosítsanak.
Az erőforrás-elosztástól, kapacitástervezéstől, kezeléstől, konfigurációtól és méretezéstől a javításokig, frissítésekig, ütemezésig és karbantartásig a felhőszolgáltató (például az AWS vagy a Google Cloud Platform) minden felelősséget magára vállal az általános infrastrukturális feladatok kezeléséért. Ennek eredményeként a fejlesztők erőfeszítéseiket és idejüket folyamataik és alkalmazásaik üzleti logikájára összpontosíthatják.
Ez a kiszolgáló nélküli számítási architektúra soha nem tárol számítási erőforrásokat az illékony memóriában; ehelyett a számítástechnika rövid részekben történik. Tegyük fel, hogy nem használ egy alkalmazást, akkor nem lesz hozzárendelve erőforrás. Ezért Ön azért fizet, hogy ténylegesen milyen erőforrást használ fel az alkalmazásokban.
A szerver nélküli modell létrehozásának fő célja a kód üzembe helyezési folyamatának egyszerűsítése a termelésben. Sokszor olyan hagyományos stílusokkal is működik, mint a mikroszolgáltatások. A szerver nélküli rendszer üzembe helyezése után az általa működtetett alkalmazások gyorsan reagálnak az igényekre, és szükség szerint automatikusan fel- vagy leskáláznak.
A kiszolgáló nélküli számítástechnika eseményvezérelt modellt használ a méretezési követelmények meghatározására. Így a fejlesztőknek többé nem kell előre látniuk az alkalmazás használatát annak eldöntéséhez, hogy hány szerverre vagy sávszélességre van szükségük. Előzetes foglalás nélkül igényelhet több szervert és sávszélességet a növekvő igények alapján, vagy gond nélkül, bármikor lecsökkentheti.
Hogyan fejlődött a szerver nélküli?
A hagyományos rendszernek az alkalmazások fejlesztési folyamata és telepítése során a skálázhatósággal és agilitással kapcsolatos kihívások voltak. Ahogy a minőségi alkalmazások iránti igény megnőtt a gyors piacra kerüléssel, egyre inkább felmerült az igény egy jobb rendszerre, amely nagyobb skálázhatóságot és mozgékonyságot kínál. Ez a felhőalapú számítástechnika és a szerver nélküli modellek fejlődését eredményezte.
A szerver nélküli modell különböző szakaszokban fejlődött, a monolittól a mikroszolgáltatásokon át a szerver nélküli architektúráig vagy a Function-as-a-Service (FaaS)ig.
- A monolitikus architektúra a szoftverfejlesztés hagyományos egységes megközelítése. Ez egy szorosan összekapcsolt modell, ahol minden komponens és annak alkomponensei kódot fordítanak vagy hajtanak végre. Ha egy szolgáltatás hibás, a teljes alkalmazáskiszolgáló és a rajta futó szolgáltatások leállhatnak.
- A mikroszolgáltatási architektúra kisebb szolgáltatások gyűjteménye egy nagy, egyetlen alkalmazáson belül, amelyeket önállóan telepítenek egy adott funkció végrehajtására. Lehetővé teszi a gyors, nagyszabású alkalmazások kézbesítését, rugalmasságot biztosítva a fejlesztőknek az Infrastructure-as-a-Service (IaaS) és a Platform as a Service (PaaS) használatával. A PaaS és az IaaS közötti választás azonban kihívást jelent ebben a modellben.
- A kiszolgáló nélküli architektúra a számítási felhővel együtt fejlődött, és nagyobb skálázhatóságot és üzleti agilitást kínál. Az IaaS és a PaaS helyett a FaaS-t és a Backend-as-a-Service-t (BaaS) használja. Itt szükség szerint telepítik az alkalmazásokat a hozzájuk tartozó erőforrásokkal együtt. Nem kell kezelnie a szervert, és leállíthatja a fizetést, ha a kód végrehajtása befejeződik.
A szerver nélküli számítástechnika jellemzői
A szerver nélküli számítástechnika néhány attribútuma a következő:
- A legtöbb kiszolgáló nélküli alkalmazást egyedi funkciók és kis kódegységek alkotják.
- Csak igény szerint futtatja a kódot, általában állapot nélküli szoftvertárolóban, és zökkenőmentesen skálázódik az igények alapján.
- Nincs szükség szerverkezelésre az ügyfelek részéről.
- Eseményalapú végrehajtást biztosít, ahol a számítógépes környezet akkor jön létre, amikor egy funkció aktiválódik vagy egy esemény érkezik a kérés végrehajtásához.
- Rugalmas méretezhetőség, így könnyedén fel- vagy leméretezhet. A kód végrehajtása után az infrastruktúra leáll, és a költség megtakarítható. Hasonlóképpen, amikor a függvény végrehajtása folytatódik, szükség szerint végtelenül felnagyíthatja.
- A felügyelt felhőszolgáltatások segítségével olyan összetett feladatokat is kezelhet, mint a fájltárolás, a sorba állítás, az adatbázisok stb.
Hogyan működik a szerver nélküli?
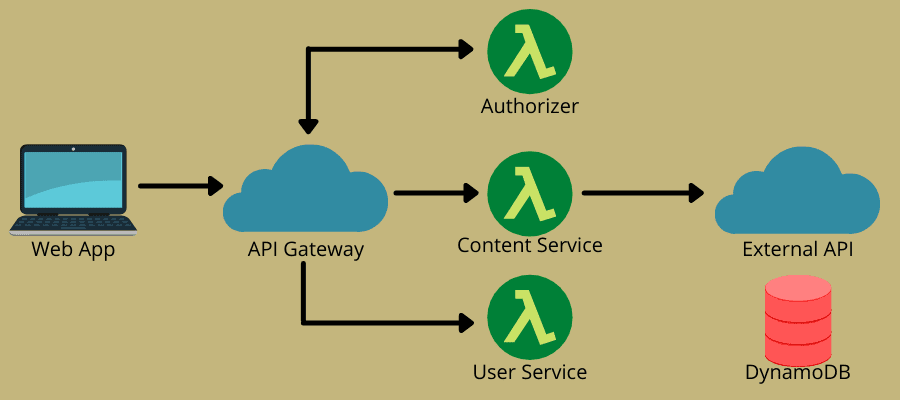
A kiszolgáló nélküli architektúra két fő ötletet ötvöz – Function-as-a-Service (FaaS) és Backend-as-a-Service (BaaS). Inkább a FaaS-en alapul, amely lehetővé teszi a felhőszolgáltatások kódvégrehajtását anélkül, hogy teljesen kiépített példányokra lenne szükség. A FaaS állapot nélküli, eseményvezérelt, méretezhető és szerveroldali funkciókból áll, amelyeket a felhőszolgáltatások teljes mértékben felügyelnek.
A modell lehetővé teszi a DevOps csapatok számára, hogy üzleti logikájukra összpontosítva kódot írjanak. Ezután meghatároznak egy eseményt, amely elindíthatja a függvényt, például HTTP-kéréseket, végrehajtásra. Következésképpen a felhőszolgáltató végrehajtja a funkciót, és elküldi az eredményeket a felhasználók által megtekinthető alkalmazásoknak.
Ily módon a kiszolgáló nélküli modell költséghatékonyságot és kényelmet kínál az automatikus skálázás, az igény szerinti és a felosztó-kirovó szolgáltatásokkal. Ezért manapság sok vállalkozás és DevOps-csapat kiszolgáló nélkülivé válik.
Ki használ szerver nélkülit és miért?
A szerver nélküli a szoftverfejlesztés legfeltörekvőbb technológiái közé tartozik. Ez a jövőben megszüntetheti az infrastruktúra-kezelési és -ellátási igényeket.
Ez hasznos:
- Azok a szervezetek, amelyek nagyobb skálázhatóságra és rugalmasságra vágynak az alkalmazások jobb tesztelhetőségével, kiszolgáló nélküliek lehetnek.
- Fejlesztők, akik agilis és nagy teljesítményű alkalmazások létrehozásával csökkenteni szeretnék a piacra jutás idejét
- Vállalatok, amelyeknek nincs szükségük arra, hogy a szervereik folyamatosan működjenek. Szükség esetén a költségek megtakarítása érdekében meghívhatnak modul alapú funkciókat alkalmazások segítségével.
- Olyan szervezetek, amelyek hatékony felhőalapú alkalmazásokat szeretnének építeni, és egyszerűsíteni szeretnének a felhőalapú migrációt
- A késleltetés csökkentésének módjait kereső fejlesztők hozzáférést kínálhatnak a felhasználóknak bizonyos funkciókhoz vagy alkalmazásokhoz.
- Az a vállalat, amely nem rendelkezik elegendő erőforrással az IT-infrastruktúra karbantartásának és összetettségének kezelésére, kiszolgáló nélküli számítástechnikát alkalmazhat, hogy automatikusan megoldja a problémákat, és nincs szükség karbantartásra.
A szerver nélküli modell néhány jelentős felhasználója a Slack, a Coca-Cola, a NetFlix stb.
Egyedi tulajdonságainak köszönhetően a szerver nélküli modell számos felhasználási esetre alkalmas, mint pl.
- Webes alkalmazások: Ezzel a modellel, amely gyorsan reagál a felhasználói igényekre, gyors és méretezhető webalkalmazásokat készíthet. Ideális állapot nélküli alkalmazások létrehozásához, amelyeket azonnal elindíthat, és olyan alkalmazásokat, amelyek képesek kielégíteni a felhasználói igények előre nem látható, ritkán előforduló megugrását.
- API-háttérrendszerek: A kiszolgáló nélküli platformokon bármely funkció könnyen átalakítható HTTP-végpontokká, amelyek készen állnak az ügyfelek általi használatra. Ezeket a funkciókat vagy műveleteket webes műveleteknek nevezzük, ha engedélyezve vannak az interneten. És ha ezek engedélyezve vannak, a funkciók teljes értékű API-ba való összeállítása egyszerűvé válik. Egy tisztességes API-átjárót is használhat, hogy nagyobb biztonságot, tartománytámogatást, sebességkorlátozást és OAuth-támogatást biztosítson.
- Mikroszolgáltatások: A kiszolgáló nélkülit széles körben használják a mikroszolgáltatási modellben, amely olyan kis szolgáltatások létrehozására összpontosít, amelyek egyetlen funkciót képesek ellátni és API-k segítségével kommunikálni egymással.
Bár a mikroszolgáltatások szoftverkonténerek és PaaS használatával is létrehozhatók, a kiszolgáló nélküli megoldás hatékonyabb. Lehetővé teszi a kisebb kódsorokat, amelyek egy dolgot hajtanak végre, és gyors hozzáférést, automatikus skálázást és rugalmas árazást kínálnak, amely nem számít fel díjat az ügyfeleknek, ha az erőforrásokat nem használják. - Adatfeldolgozás: A szerver nélküli kiválóan alkalmas videókat, hangot, képeket és strukturált szöveget tartalmazó adatok kezelésére. Különféle feladatokhoz is előnyös, mint például az adatok ellenőrzése, átalakítása, dúsítása, tisztítása, hangnormalizálása és PDF feldolgozása. Használhatja képfeldolgozáshoz, amely magában foglalja az élesítést, az elforgatást, a miniatűrök generálását és a zajcsökkentést. A szerver nélküli adatfeldolgozás egyéb felhasználási lehetőségei a videó átkódolás és az optikai karakterfelismerés (OCR).
- Adatfolyam/kötegelt feldolgozás: Hatékony adatfolyam-alkalmazásokat és adatfolyamokat hozhat létre a FaaS és az Apache Kafka adatbázis használatával. A szerver nélküli modell különféle adatfolyam-feldolgozásokhoz illeszkedik, beleértve az alkalmazásnaplók adatait, az IoT-érzékelőket, az üzleti logikát és a pénzügyi piacot.
- Párhuzamos számítás: A szerver nélküli kiválóan alkalmas a párhuzamos számításokhoz kapcsolódó feladatokhoz, ahol minden feladat párhuzamosan fut egy adott feladat végrehajtása érdekében. Tartalmazhat adatkeresést, feldolgozást, térképműveleteket, webkaparást, genomfeldolgozást, hiperparaméter-hangolást stb.
- Egyéb felhasználási területek: A Serverless különféle alkalmazásokhoz is használható, mint például az ügyfélkapcsolat-kezeléshez (CRM), a pénzügyekhez, a chatbotokhoz, valamint az üzleti intelligencia és analitika, hogy csak néhányat említsünk.
Megjegyzés: A szerver nélküli előfordulhat, hogy bizonyos esetekben nem ideális. Például a kiszámítható és szinte állandó munkaterhelésű nagy alkalmazások jobban profitálhatnak a hagyományos rendszerarchitektúrából. Választhatnak dedikált szervereket, akár felügyelt, akár önállóan. Ezenkívül, ha szervezete teljes hagyományos beállításokkal rendelkezik régi rendszerekkel és alkalmazásokkal, akkor költséges és kihívást jelenthet egy teljesen új és más architektúrára való átállás.
A szerver nélküli számítástechnika előnyei és hátrányai
Minden éremnek két oldala van, és a szerver nélküli architektúrának is. Különböző paraméterek alapján van néhány előnye és hátránya is. Tehát mielőtt továbblépne, fontos, hogy mindkét oldalt ismerje, hogy eldönthesse, jobb lenne-e a szervezete számára vagy sem.
Előnyök 👍
Íme a szerver nélküli architektúra néhány előnye:
Költséghatékony
A kiszolgáló nélküli költséghatékonyabb megoldást kínál, mint a szerverek vásárlása vagy bérlése, ahol akkor is fizet az erőforrásokért, ha nem használja azokat.
A szerver nélküli felosztó-kirovó modellt alkalmaz, ahol csak a felhasznált erőforrásokért kell fizetni. A kiszolgáló nélküli szolgáltató csak a lefoglalt memóriáért és a kód futtatásához szükséges időért számít fel díjat anélkül, hogy a tétlenség miatti költségek merülnének fel.
Ennek eredményeként megtakaríthatja az olyan feladatok üzemeltetési költségeit, mint a telepítés, licencek, karbantartás, javítás, támogatás stb. Szerverhardver nélkül megtakaríthatja a munkaerőköltségeket.
Skálázhatóság
A kiszolgáló nélküli rendszerek magas szintű skálázhatóságot kínálnak, mivel az igényeknek megfelelően bármikor felfelé vagy lefelé méretezhet. Emiatt „rugalmasnak” is nevezik őket.
Itt a fejlesztőknek nincs szükségük külön időre az automatikus skálázási rendszerek vagy szabályzatok beállítására vagy hangolására. Az Ön által választott felhőszolgáltató felelős mindezek kezeléséért. Ezenkívül a kis csapatokból álló fejlesztők maguk is futtathatják kódjukat anélkül, hogy támogató mérnökökre vagy infrastruktúrára lenne szükségük.
Csökkentett késleltetés
Mivel az alkalmazások nem egyetlen forráskiszolgálón vannak tárolva, a kódot bárhonnan futtathatja. Ha a választott felhőszolgáltató támogatja, akkor az alkalmazásfunkciókat a végfelhasználókhoz közeli szerveren futtathatja. Ezért a felhasználói kérések és a szerver közötti kisebb távolság miatt kevesebb késleltetéssel jár.
Termelékenység
A kiszolgáló nélküli modell segít javítani a fejlesztők termelékenységét, mivel nem kell kezelniük a szerverkezelést. Ezenkívül nem kell a HTTP-kérések vagy a kódjuk többszálú kezelésének közvetlen kezelésére gondolniuk.
Ennek eredményeként leegyszerűsíti a háttérfejlesztést, mindezt a FaaS-nek köszönhetően, ahol a közzétett kód eseményvezérelt függvények. Mindezek időt takarítanak meg, amelyet a kód és az alkalmazás fejlesztésére fordíthatnak.
Gyorsabb alkalmazástelepítés
Szerver nélküli esetén a fejlesztők nem hajtanak végre háttérkonfigurációt, és nem töltenek fel kódot a kiszolgálóra az alkalmazásverzió üzembe helyezéséhez. Gyorsan feltölthetik a kódot bitenként, hogy új termékeket adhassanak ki.
Rugalmasak arra is, hogy egyszerre telepítsék a kódot, vagy egymás után működjenek, mivel ez nem egy monolitikus architektúra. Ezenkívül gyorsan javíthat, frissíthet, funkciókat adhat hozzá, vagy kijavíthatja a hibákat egy alkalmazásból.
További előnyök közé tartozik a környezetbarát számítástechnika az igény szerinti szerverekkel történő csökkentett energiafogyasztás miatt, a beépített integrációkkal könnyebbé váló alkalmazás készítése, a gyorsabb piacra kerülés stb.
Hátrányok 👎
Most pedig nézzük a szerver nélküli számítástechnika hátrányait:
Teljesítmény
Előfordulhat, hogy a ritkábban használt kiszolgáló nélküli kódok válaszideje nagyobb, mint a dedikált kiszolgálókon, szoftvertárolókon vagy virtuális gépeken (VM) folyamatosan futó kódoknál. Ez azért van így, mert több időre lehet szükség az újrakezdéshez és extra késleltetés létrehozásához.
Nehéz a hibakeresés és a tesztelés
Tudnia kell, hogyan működik a kód, miután telepítette. Ehhez tesztelni kell, ami szerver nélküli környezetben kihívást jelent. Ezenkívül, mivel a fejlesztők nem látják az egyes háttérfolyamatokat, és az alkalmazások kisebb funkciókra vannak osztva, a hibakeresés bonyolulttá válik.
Biztonsági kérdések
Egyre nőnek az új és fejlett kiberbiztonsági aggodalmak. A felhőszolgáltató biztonságát azonban nem lehet teljesen megismerni vagy mérni. Ha tehát a teljes háttérrendszert az alkalmazásokban tárolt érzékeny adatokkal kezelik, az kockázatos.
Nem alkalmas hosszan tartó alkalmazási folyamatokhoz
A szerver nélküli költséghatékony, de nem minden alkalmazástípushoz. Ha olyan alkalmazással rendelkezik, amely hosszú ideig futó folyamatokkal rendelkezik, a futtatásának költsége az idő és a lefoglalt erőforrások alapján nagyon magas lehet. Ebben az időben érdemes egy dedikált szervertárhelyet választani.
A kiszolgáló nélküli megoldás egyéb hátrányai az egyik szállítóról a másikra való váltás nehézségei és az adatvédelmi problémák.
A kiszolgáló nélküli architektúrában fontos terminológiák
A szerver nélküli soha nem teljes anélkül, hogy ne beszéljünk néhány kulcsfontosságú terminológiáról. A FaaS és a BaaS a két legjelentősebb ötlet, amely a ma ismert szerver nélküli evolúciójához vezetett. A szerver nélküli rendszer felépítéséhez pedig szükség van egy adatbázisra, tárolórendszerre, technológiai veremre, keretrendszerre és így tovább. Szóval beszéljünk egy kicsit róluk.
Szolgáltatásként funkcionál (FaaS)
A FaaS központi ötlet a kiszolgáló nélküli környezetben, és úgy működik, mint annak részhalmaza. Ez az eseményvezérelt kódvégrehajtási modell (kérésre válaszul futó alkalmazások) lehetővé teszi, hogy szoftvertárolókban telepített logikát írjon, igény szerint végrehajtva, és egy felhőplatform kezeli.
Ha összehasonlítja a BaaS-szel, a FaaS nagyobb szabályozást kínál a fejlesztőknek az egyéni alkalmazások létrehozásában, ahelyett, hogy az előre elkészített kódot tartalmazó könyvtáraktól függne.
A kódot telepítő szoftvertárolók állapot nélküliek az adatintegráció egyszerűsítése érdekében, és a kód rövidebb ideig fut. Ezenkívül a fejlesztők a kiszolgáló nélküli alkalmazásokat a FaaS használatával API-kon keresztül hívhatják meg, amelyeket a felhőszolgáltatók API-átjárón keresztül kezelnek.
Backend-as-a-Service (BaaS)
A BaaS hasonló a FaaS-hez, mert mindkettőnek szüksége van egy harmadik féltől származó szolgáltatóra. Ebben a modellben a felhőszolgáltató háttérszolgáltatásokat nyújt, például adattárolást, hogy segítse a fejlesztőket, hogy a frontend kód megírására összpontosítsanak. Előfordulhat azonban, hogy a BaaS-alkalmazások nem eseményvezéreltek, és nem futnak a szélén, mint a kiszolgáló nélküli alkalmazások esetében.
A BaaS jó példája az AWS Lambda. A fejlesztők kiszolgáló nélküli kódot használnak a Lambdával ellátott tárolókban, amely útmutatást ad a kód elküldése során. Ezenkívül automatizálja a kódnak a szoftvertárolókba való bevitelét, és felügyelt szolgáltatást kínál.
Szerver nélküli verem
A többi szoftvertechnológiához hasonlóan a kiszolgáló nélküli architektúrához is tartozik technológiai köteg. Különféle összetevőket egyesít, amelyek elengedhetetlenek egy szerver nélküli rendszer vagy alkalmazás létrehozásához.
A szerver nélküli verem a következőket tartalmazza:
- Programozási nyelv: Az a programozási nyelv, amelyen a fejlesztők megírják a kódot. A gyártótól függően választhat a Java, JavaScript, Python, C#, Go, Node.js, F# stb. közül.
- Szerver nélküli keretrendszer: A keretrendszer biztosítja a kód vázát vagy struktúráját. Rengeteg kiszolgáló nélküli keretrendszer áll rendelkezésre az induláshoz. Lehetővé teszi a kód felépítését, csomagolását és fordítását, és végül a felhőalapú telepítést. A kiszolgáló nélküli keretrendszerek felgyorsítják a kódolási folyamatot és leegyszerűsítik a méretezést csökkentett konfigurációs idővel. Szerver keretrendszerekre példa az Apex, az AWS Serverless Application Model stb.
- Szerver nélküli adatbázisok: A kód eléréséhez szükséges adatok tárolására szolgál. Szükségesek a triggerek funkcióival való interakcióhoz is. Ezek az adatbázisok kiszolgáló nélküli függvényekként viselkednek, de korlátlan ideig tárolják az adatokat. A kiszolgáló nélküli adatbázisok példái a DynamoDB, az Azure Cosmos DB, az Aurora Serverless és a Cloud Firestore.
- Triggerek készlete: Segítenek elindítani a kódvégrehajtást, például a HTTP-kéréseket
- Szoftverkonténerek: Felhatalmazza a szerver nélküli modellt, és konténeres mikroszolgáltatásokat kínálnak bonyolultság nélkül. Emellett a kód tárházaként is működnek, és megkönnyítik a fejlesztők számára a kód írását több platformra, például asztali számítógépre vagy iOS-re.
- API-átjárók: A webes műveletek proxyjaként működnek. HTTP-útválasztást, sebességkorlátozást, API-használati és válasznaplók megtekintését, ügyfél-azonosítót stb. kínálnak.
Hogyan valósítsuk meg és optimalizáljuk a szerver nélküli modellt?
A szerver nélkülivé válás jelentős változásokat fog okozni az alkalmazások, a technológia, a költségek, a biztonság és az előnyök tekintetében.
Tegyük fel, hogy Ön egy induló vagy kisvállalkozás. Ebben az esetben felgyorsítja a piacra jutás idejét, és segít a frissítések gyors leküldésében az egyszerűsített teszteléssel, hibakereséssel, visszajelzések gyűjtésével, a problémák megoldásával és még sok mással, hogy kifinomult alkalmazásokat kínálhasson a felhasználóknak.
Ha Ön egy nagyobb szervezet, akkor olyan előnyökkel jár, mint a nagyobb skálázhatóság a felhasználói igények kielégítése érdekében, de ez jelentős költségbefektetést igényel.
Ezért a legjobb, ha felméri a szerver nélküli előnyöket és hátrányokat kifejezetten az Ön vállalkozásának típusa és igényei szerint, majd folytatja. És ha komolyan gondolja, kezdje ezzel:
- Az Ön igényeinek megértése és a megfelelő szerver nélküli technológiai verem meghatározása
- Válasszon egy szerver nélküli szállítót, például a Google Cloud Functions, az Azure Functions, az AWS Lambda stb.
- Erősítse csapatát hatékony eszközökkel a rendszer teljesítményének és funkcióinak nyomon követésére. Ügyeljen a kérések teljes számára, a fojtószelepekre, a hibaszámokra, a sikerarányokra, a kérések időtartamára és a várakozási időre.
Szerver nélküli eladók

Számos szerver nélküli szállító vagy felhőszolgáltató található a piacon, amelyek közül választhat. Néhány a legjobbak közül:
- AWS Lambda: Tökéletes olyan szervezetek számára, amelyek már kihasználják az AWS szolgáltatásokat. Integrálódik a tárolási, streamelési és adatbázis-szolgáltatások széles skálájával.
- Microsoft Azure Functions: Ha Visual Studio Code-ot használ, próbálkozzon vele. Zökkenőmentesen működik a DevOps és az Azure Pipelines for CI/CD-vel. Támogatja a tartós funkciókat is az állapottartó funkciókhoz, és integrált felügyeletet kínál.
- Google Cloud Functions: Ha Google-szolgáltatásokat használ, akkor jó. Támogatja a JS, Go és Python alkalmazásokat, lehetővé teszi a funkciók Google Asszisztensből vagy GCP-ből történő indítását, és beépített skálázást kínál.
- IBM Cloud Functions: Ha egy Apache OpenWhisk alapú szerver nélküli modellt szeretne választani, az IBM Cloud Functions az Ön számára készült. Kiváló teljesítményfigyelést, eseményindítót tartalmaz REST API-ból vagy IBM felhőszolgáltatásokból, és integrálódik az IBM API Gateway-jével a végpontok kezeléséhez.
- Knative: Ha szolgáltatásokat futtat a Kubernetes-en, menjen hozzá. Ezt támogatja a Google, a Red Hat, az IBM stb.
- Cloudflare Workers: Jó a nagy válaszkészséget igénylő alkalmazásokhoz, különösen a JavaScript-alkalmazásokhoz. Támogatja a Workers KV-t az adattároláshoz és a WebAssembly-t, hogy segítsen több nyelv fordításában és szállításában. A 193 adatközpontból álló magas elosztási hálózat emellett javítja a késleltetést és a válaszkészséget.
Következtetés: A szerver nélküli jövője
A kiszolgáló nélküli számítástechnika a nagymértékben méretezhető alkalmazások iránti növekvő kereslet mellett fejlődik. Emellett számos előnnyel jár, amelyeket a számítási felhő kínál, például nagyobb kényelmet, költséghatékonyságot, nagyobb termelékenységet és még sok mást.
Egy O’Reilly felmérésa válaszadók 40%-a olyan cégeknél dolgozik, amelyek elfogadták a szerver nélküli architektúrát.
Bár a kiszolgáló nélkülinek még vannak bizonyos aggályai, például a hidegindítások miatti késleltetés, a tesztelés, a hibakeresés stb., a felhőszolgáltatók dolgoznak ezeken. Hamarosan megjelenhet a kiszolgáló nélküli szolgáltatások kifinomultabb formája, több előnnyel és megoldott problémákkal. Ezért a szerver nélküli modell népszerűsége és használata a jövőben várhatóan növekedni fog.
Ez is érdekelheti: 7 Ways Serverless Computing egy feltörekvő technológia