Dieser Beitrag beleuchtet einige der herausragendsten Python-Bibliotheken, die für Fachleute im Bereich der Datenwissenschaft und des maschinellen Lernens von Bedeutung sind.
Python hat sich als bevorzugte Sprache in diesen beiden Disziplinen etabliert, insbesondere aufgrund der umfangreichen Sammlung an Bibliotheken.
Die Vielseitigkeit von Python-Bibliotheken erstreckt sich auf Bereiche wie Daten-I/O, Datenanalyse und andere Datenverarbeitungsaufgaben. Diese Funktionen sind entscheidend für Datenwissenschaftler und Experten für maschinelles Lernen, die Daten manipulieren und analysieren.
Was sind Python-Bibliotheken?
Eine Python-Bibliothek ist im Grunde eine umfassende Zusammenstellung vordefinierter Module. Diese Module enthalten vorkompilierten Code, einschließlich Klassen und Methoden, was die Notwendigkeit eliminiert, dass Entwickler Code von Grund auf neu erstellen müssen.
Die Rolle von Python in Datenwissenschaft und maschinellem Lernen
Python zeichnet sich durch seine exzellenten Bibliotheken aus, die speziell für maschinelles Lernen und Datenwissenschaft entwickelt wurden.
Die klare Syntax von Python ermöglicht die effiziente Implementierung komplexer Algorithmen des maschinellen Lernens. Die leicht verständliche Syntax erleichtert zudem das Erlernen und den Einstieg in die Materie.
Darüber hinaus unterstützt Python eine schnelle Prototypentwicklung und das effiziente Testen von Anwendungen.
Die große und aktive Python-Community ist eine wertvolle Ressource für Datenwissenschaftler, die schnell Antworten und Lösungen auf ihre Fragen finden können.
Welchen Nutzen haben Python-Bibliotheken?
Python-Bibliotheken sind grundlegend für die Erstellung von Anwendungen und Modellen im Bereich des maschinellen Lernens und der Datenwissenschaft.
Sie fördern die Wiederverwendung von Code erheblich. Anstatt das Rad neu zu erfinden, können Entwickler einfach die benötigten Bibliotheken importieren, um bestimmte Funktionen in ihren Programmen zu implementieren.
Python-Bibliotheken für maschinelles Lernen und Datenwissenschaft
Experten in der Datenwissenschaft empfehlen verschiedene Python-Bibliotheken, mit denen sich jeder, der sich mit Datenwissenschaft beschäftigt, vertraut machen sollte. Je nach Anwendungsbereich setzen Experten für maschinelles Lernen und Datenwissenschaft verschiedene Python-Bibliotheken ein, die in Kategorien eingeteilt sind, um Modelle zu erstellen, Daten zu extrahieren, zu verarbeiten und zu visualisieren.
Dieser Artikel stellt einige der am häufigsten verwendeten Python-Bibliotheken in den Bereichen Datenwissenschaft und maschinelles Lernen vor.
Werfen wir nun einen Blick darauf.
NumPy
Die Python-Bibliothek NumPy (Numerical Python) wurde mit optimiertem C-Code erstellt. Datenwissenschaftler bevorzugen sie wegen ihrer leistungsfähigen Funktionen für mathematische und wissenschaftliche Berechnungen.
Funktionen
- NumPy zeichnet sich durch eine leicht verständliche Syntax aus, die es erfahrenen Programmierern einfach macht.
- Die Bibliothek ist dank des optimierten C-Codes äußerst leistungsfähig.
- Sie bietet numerische Rechenwerkzeuge, einschließlich Fourier-Transformationen, lineare Algebra und Zufallszahlengeneratoren.
- NumPy ist Open Source, was viele Beiträge von der Entwickler-Community ermöglicht.
NumPy bietet weitere Funktionen wie die Vektorisierung von mathematischen Operationen, Indexierung und grundlegende Konzepte für die Implementierung von Arrays und Matrizen.
Pandas
Pandas ist eine bekannte Bibliothek für maschinelles Lernen, die fortschrittliche Datenstrukturen und Werkzeuge zur Analyse großer Datensätze bereitstellt. Mit wenigen Befehlen kann diese Bibliothek komplexe Datenoperationen ausführen.
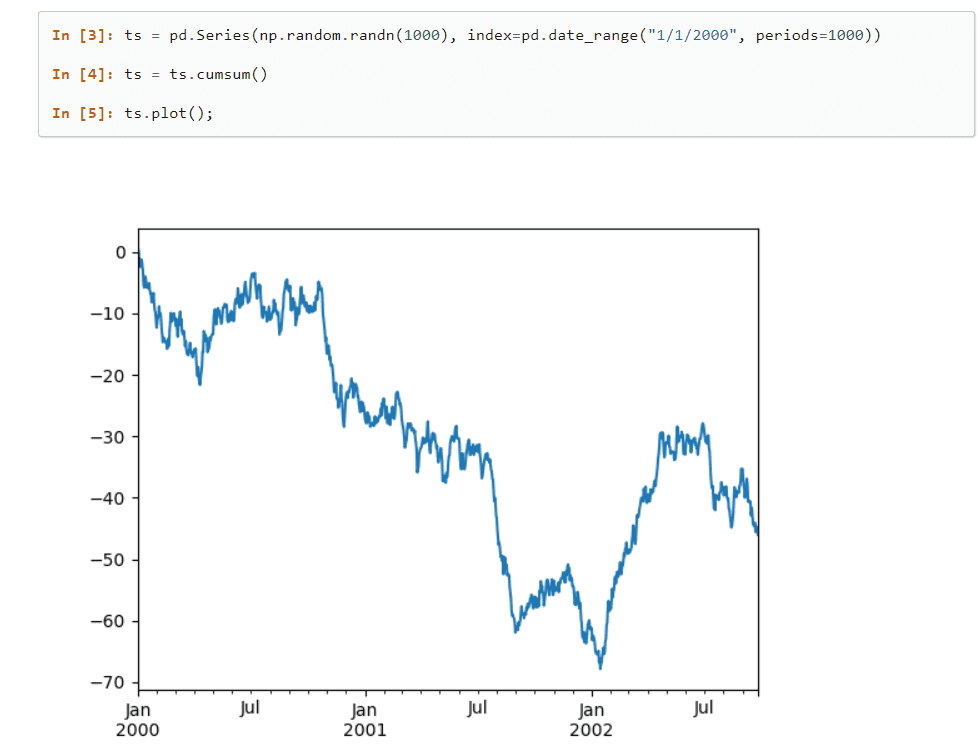
Zahlreiche integrierte Methoden zur Gruppierung, Indizierung, Abrufung, Aufteilung, Umstrukturierung und Filterung von Daten, bevor sie in ein- oder mehrdimensionale Tabellen eingefügt werden, zeichnen diese Bibliothek aus.
Kernfunktionen der Pandas-Bibliothek
- Pandas vereinfacht das Beschriften von Daten in Tabellen und richtet Daten automatisch aus und indiziert sie.
- Die Bibliothek kann Datenformate wie JSON und CSV schnell laden und speichern.
Pandas ist äußerst effizient in Bezug auf Datenanalyse und Flexibilität.
Matplotlib
Die grafische Python-Bibliothek Matplotlib 2D verarbeitet mühelos Daten aus verschiedenen Quellen. Die erzeugten Visualisierungen sind statisch, animiert und interaktiv. Benutzer können hineinzoomen, was die Bibliothek effizient für Visualisierungen und das Erstellen von Diagrammen macht. Darüber hinaus ermöglicht sie die Anpassung von Layout und visuellen Stilen.
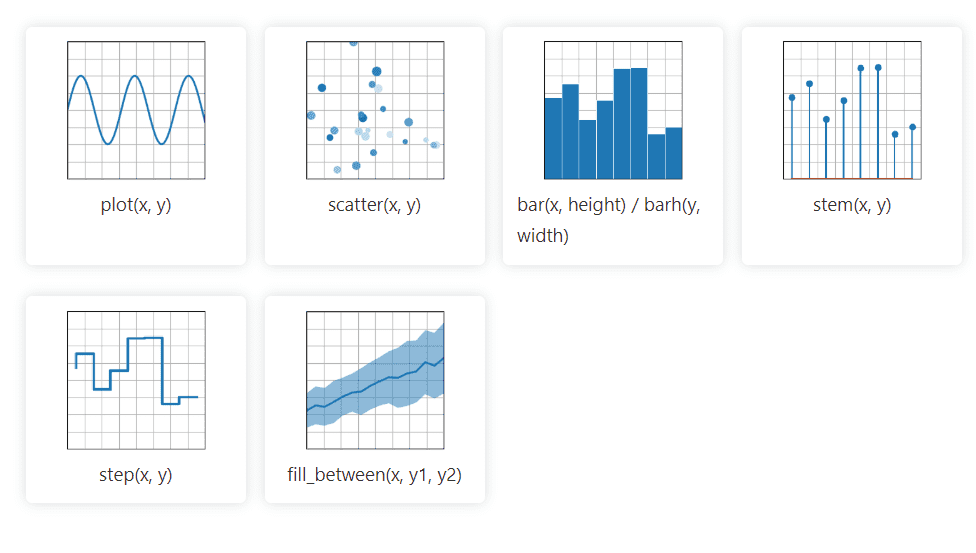
Die Open-Source-Dokumentation bietet eine umfassende Sammlung an Tools für die Implementierung.
Matplotlib importiert Hilfsklassen für Jahr, Monat, Tag und Woche, was die effiziente Bearbeitung von Zeitreihendaten ermöglicht.
Scikit-learn
Wenn Sie eine Bibliothek suchen, die Ihnen bei der Bearbeitung komplexer Daten hilft, ist Scikit-learn eine hervorragende Wahl. Diese Bibliothek wird von Experten für maschinelles Lernen häufig verwendet. Sie ist mit Bibliotheken wie NumPy, SciPy und matplotlib verbunden. Scikit-learn bietet sowohl überwachte als auch unüberwachte Lernalgorithmen, die in der Produktion eingesetzt werden können.

Funktionen der Scikit-learn Python-Bibliothek
- Identifizierung von Objektkategorien, z.B. durch Algorithmen wie SVM und Random Forest in Anwendungen wie der Bilderkennung.
- Vorhersage eines kontinuierlichen Attributwerts, der ein Objekt über eine Aufgabe namens Regression verknüpft.
- Merkmalsextraktion.
- Dimensionsreduktion, bei der die Anzahl der betrachteten Zufallsvariablen reduziert wird.
- Gruppierung ähnlicher Objekte zu Mengen.
Die Scikit-learn-Bibliothek ist effizient für die Merkmalsextraktion aus Text- und Bilddatensätzen. Darüber hinaus ist es möglich, die Genauigkeit von überwachten Modellen anhand unsichtbarer Daten zu überprüfen. Die Vielzahl verfügbarer Algorithmen ermöglicht Data Mining und andere Aufgaben des maschinellen Lernens.
SciPy
SciPy (Scientific Python) ist eine Bibliothek für maschinelles Lernen, die Module für mathematische Funktionen und Algorithmen bereitstellt. Die Algorithmen sind für das Lösen algebraischer Gleichungen, Interpolation, Optimierung, Statistik und Integration konzipiert.
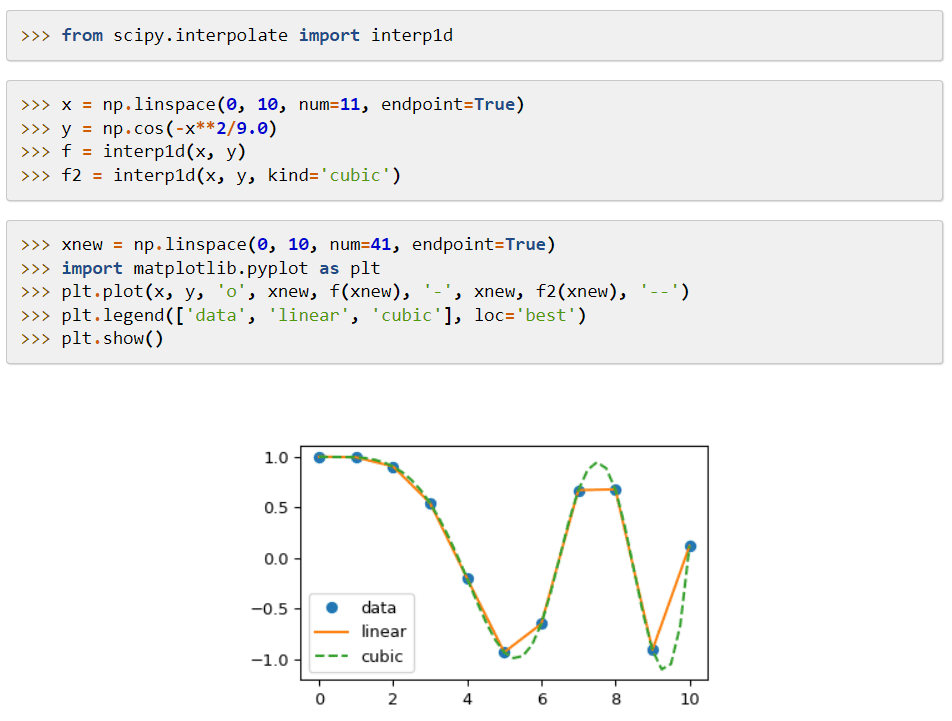
Das Hauptmerkmal ist die Erweiterung von NumPy, die Werkzeuge zum Lösen mathematischer Funktionen und Datenstrukturen wie Sparse-Matrizen bereitstellt.
SciPy verwendet Befehle und Klassen auf hoher Ebene zur Manipulation und Visualisierung von Daten. Seine Datenverarbeitungs- und Prototypensysteme machen es zu einem noch effektiveren Werkzeug.
Darüber hinaus ermöglicht die High-Level-Syntax von SciPy die einfache Nutzung für Programmierer aller Erfahrungsstufen.
Der einzige Nachteil von SciPy ist der alleinige Fokus auf numerische Objekte und Algorithmen. Es bietet keine Plotfunktion.
PyTorch
Diese vielseitige Bibliothek für maschinelles Lernen implementiert Tensorberechnungen mit GPU-Beschleunigung, dynamische Berechnungsdiagramme und automatische Gradientenberechnungen. Die PyTorch-Bibliothek basiert auf der Torch-Bibliothek, einer Open-Source-Bibliothek für maschinelles Lernen, die in C entwickelt wurde.

Hauptmerkmale:
- Unterstützung für eine nahtlose Entwicklung und Skalierung durch hervorragende Unterstützung auf wichtigen Cloud-Plattformen.
- Ein robustes Ökosystem aus Tools und Bibliotheken unterstützt die Entwicklung von Computer Vision und anderen Bereichen wie der Verarbeitung natürlicher Sprache (NLP).
- Nahtloser Übergang zwischen Eager- und Grafikmodus mit Torch Script, während TorchServe die Produktionsphasen beschleunigt.
- Das verteilte Torch-Backend ermöglicht verteiltes Training und Leistungsoptimierung in Forschung und Produktion.
PyTorch eignet sich besonders gut für die Entwicklung von NLP-Anwendungen.
Keras
Keras ist eine Open-Source-Python-Bibliothek für maschinelles Lernen, die für das Experimentieren mit tiefen neuronalen Netzen verwendet wird.
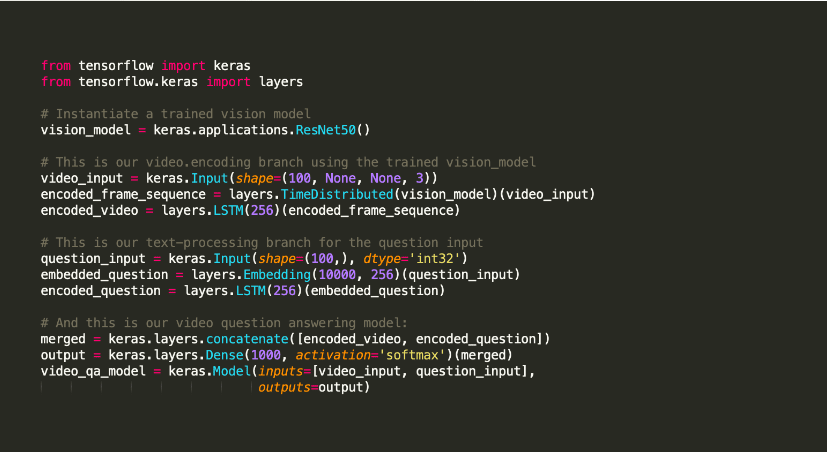
Die Bibliothek ist bekannt für ihre Dienstprogramme, die Aufgaben wie die Kompilierung von Modellen und die Visualisierung von Diagrammen unterstützen. Sie nutzt Tensorflow als Backend, kann aber auch mit Theano oder neuronalen Netzen wie CNTK verwendet werden. Diese Backend-Infrastruktur hilft beim Erstellen von Berechnungsgraphen für die Implementierung von Operationen.
Hauptmerkmale der Bibliothek
- Keras kann sowohl auf der CPU als auch auf der GPU effizient ausgeführt werden.
- Das Debuggen ist in Keras einfacher, da die Bibliothek auf Python basiert.
- Keras ist modular aufgebaut und daher ausdrucksstark und anpassungsfähig.
- Keras-Module können direkt in JavaScript exportiert und im Browser ausgeführt werden.
Zu den Anwendungen von Keras gehören neuronale Netzwerkbausteine wie Ebenen und Ziele sowie Tools für die Arbeit mit Bild- und Textdaten.
Seaborn
Seaborn ist ein weiteres wertvolles Tool für die Visualisierung statistischer Daten.
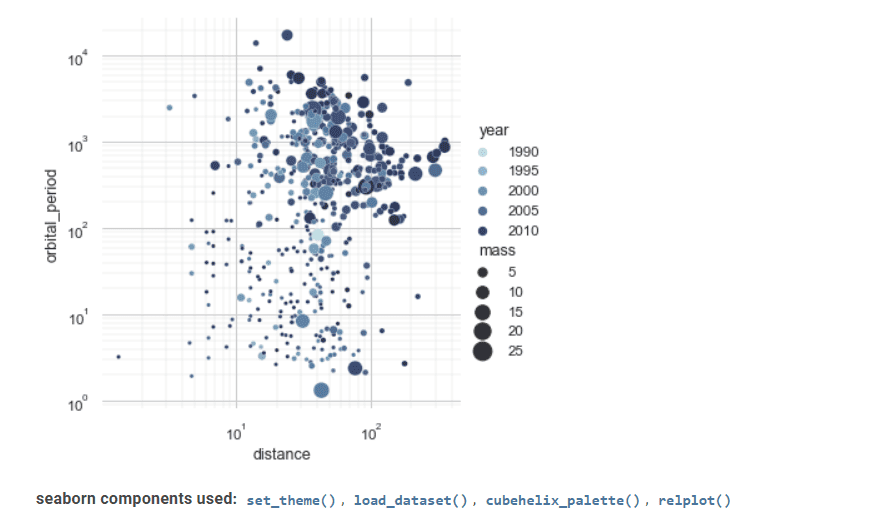
Die fortschrittliche Schnittstelle ermöglicht die Erstellung attraktiver und informativer statistischer Grafiken.
Plotly
Plotly ist ein webbasiertes 3D-Visualisierungstool, das auf der Plotly JS-Bibliothek aufbaut. Es bietet umfangreiche Unterstützung für verschiedene Diagrammtypen wie Liniendiagramme, Streudiagramme und Boxplots.
Plotly wird zur Erstellung webbasierter Datenvisualisierungen in Jupyter-Notebooks verwendet.
Plotly ist für die Visualisierung geeignet, da es mithilfe des Hover-Tools auf Ausreißer oder Auffälligkeiten in Grafiken aufmerksam machen kann. Die Diagramme sind anpassbar.
Die Dokumentation von Plotly ist jedoch veraltet, was die Nutzung erschweren kann. Außerdem gibt es viele Tools, die ein Benutzer erlernen muss, was schwierig sein kann.
Funktionen der Plotly-Python-Bibliothek
- Die verfügbaren 3D-Diagramme ermöglichen mehrere Interaktionspunkte.
- Die Bibliothek hat eine vereinfachte Syntax.
- Der Code kann geschützt und Punkte können dennoch geteilt werden.
SimpleITK
SimpleITK ist eine Bildanalysebibliothek, die eine Schnittstelle zu Insight Toolkit (ITK) bereitstellt. Sie basiert auf C++ und ist Open Source.
Funktionen der SimpleITK-Bibliothek
- Die Bilddatei-I/O unterstützt bis zu 20 Bilddateiformate wie JPG, PNG und DICOM.
- Die Bibliothek bietet zahlreiche Filter für Bildsegmentierungs-Workflows wie Otsu, Level Sets und Watersheds.
- Sie interpretiert Bilder als räumliche Objekte und nicht als Anordnung von Pixeln.
Die einfache Schnittstelle ist in verschiedenen Programmiersprachen wie R, C#, C++, Java und Python verfügbar.
Statsmodels
Statsmodels schätzt statistische Modelle, implementiert statistische Tests und analysiert statistische Daten mithilfe von Klassen und Funktionen.
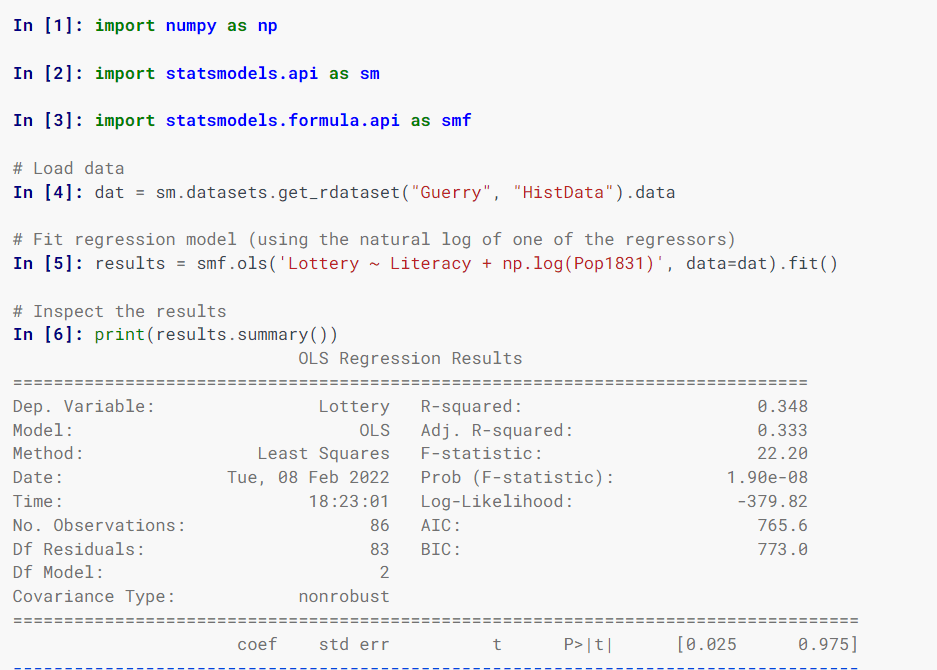
Bei der Modellspezifikation werden Formeln im R-Stil, NumPy-Arrays und Pandas-Datenrahmen verwendet.
Scrapy
Dieses Open-Source-Paket ist ein Tool für das Abrufen (Scraping) und Crawlen von Daten von Websites. Es ist asynchron und daher relativ schnell. Scrapy ist effizient durch seine Architektur und Funktionen.
Andererseits unterscheidet sich die Installation für verschiedene Betriebssysteme. Zudem kann Scrapy nicht auf Websites verwendet werden, die auf JS basieren. Es funktioniert nur mit Python 2.7 oder höheren Versionen.
Experten für Datenwissenschaft setzen es für Data Mining und automatisiertes Testen ein.
Funktionen
- Scrapy kann Feeds in JSON, CSV und XML exportieren und in mehreren Backends speichern.
- Es verfügt über integrierte Funktionen zum Sammeln und Extrahieren von Daten aus HTML/XML-Quellen.
- Scrapy kann mit einer definierten API erweitert werden.
Pillow
Pillow ist eine Python-Imaging-Bibliothek zur Manipulation und Verarbeitung von Bildern.
Sie erweitert die Bildverarbeitungsfunktionen des Python-Interpreters, unterstützt verschiedene Dateiformate und bietet eine hervorragende interne Darstellung.
Dank Pillow kann problemlos auf Daten zugegriffen werden, die in einfachen Dateiformaten gespeichert sind.
Fazit
Dies fasst unsere Diskussion über einige der besten Python-Bibliotheken für Datenwissenschaftler und Experten für maschinelles Lernen zusammen.
Wie dieser Artikel zeigt, bietet Python zahlreiche hilfreiche Pakete für maschinelles Lernen und Datenwissenschaft. Es gibt noch viele weitere Python-Bibliotheken für andere Bereiche.
Vielleicht möchten Sie auch mehr über einige der besten Data-Science-Notebooks erfahren.
Viel Spaß beim Lernen!