

Az adatok egyre fontosabbá váltak a gépi tanulási modellek felépítésében, az alkalmazások tesztelésében és az üzleti betekintésben.
A számos adatszolgáltatási előírás betartása érdekében azonban gyakran letétbe helyezik és szigorúan védik. Az ilyen adatokhoz való hozzáférés hónapokig tarthat, amíg megkapja a szükséges aláírásokat. Alternatív megoldásként a vállalkozások szintetikus adatokat is használhatnak.
Tartalomjegyzék
Mi az a szintetikus adat?
Fotó: Twinify
A szintetikus adatok mesterségesen előállított adatok, amelyek statisztikailag hasonlítanak a régi adatkészletre. Használható valós adatokkal AI modellek támogatására és fejlesztésére, vagy teljesen helyettesíthető.
Mivel nem tartozik egyetlen érintetthez sem, és nem tartalmaz személyazonosításra alkalmas adatokat vagy érzékeny adatokat, például társadalombiztosítási számokat, a valós termelési adatok magánélet védelmét szolgáló alternatívájaként használható.
A valós és a szintetikus adatok közötti különbségek
- A legdöntőbb különbség a kétféle adat előállítási módjában van. A valós adatok valós alanyoktól származnak, akiknek adatait felmérések során gyűjtötték, vagy amikor az Ön alkalmazását használták. Másrészt a szintetikus adatokat mesterségesen állítják elő, de még mindig hasonlítanak az eredeti adatkészletre.
- A második különbség a valós és szintetikus adatokat érintő adatvédelmi szabályozásban rejlik. Valós adatok esetén az alanyoknak tudniuk kell, hogy milyen adatokat gyűjtenek róluk, és miért gyűjtik azokat, és ezek felhasználásának korlátai vannak. Ezek a szabályozások azonban már nem vonatkoznak a szintetikus adatokra, mivel az adatok nem rendelhetők alanyhoz, és nem tartalmaznak személyes információkat.
- A harmadik különbség a rendelkezésre álló adatok mennyiségében van. Valós adatokkal csak annyi lehet, amennyit a felhasználók adnak. Másrészt annyi szintetikus adatot generálhat, amennyit csak akar.
Miért érdemes megfontolni a szintetikus adatok használatát?
- Viszonylag olcsóbb előállítani, mert sokkal nagyobb adatkészleteket hozhat létre, amelyek hasonlítanak a már meglévő kisebb adatkészlethez. Ez azt jelenti, hogy a gépi tanulási modelljei több adattal rendelkeznek a betanításhoz.
- A generált adatok automatikusan felcímkézésre és tisztításra kerülnek. Ez azt jelenti, hogy nem kell időt töltenie az adatok gépi tanuláshoz vagy elemzéshez való előkészítésének időigényes munkájával.
- Nincsenek adatvédelmi problémák, mivel az adatok nem személyazonosításra alkalmasak, és nem tartoznak az érintetthez. Ez azt jelenti, hogy szabadon használhatja és megoszthatja.
- Leküzdheti a mesterséges intelligencia elfogultságát, ha gondoskodik a kisebbségi osztályok megfelelő képviseletéről. Ez segít tisztességes és felelős AI felépítésében.
Szintetikus adatok generálása
Míg a generálási folyamat a használt eszköztől függően változik, általában a folyamat egy generátor csatlakoztatásával kezdődik egy meglévő adatkészlethez. Ezt követően azonosítja a személyazonosításra alkalmas mezőket az adatkészletében, és felcímkézi őket a kizárás vagy az elhomályosítás érdekében.
A generátor ezután elkezdi azonosítani a fennmaradó oszlopok adattípusait és az oszlopok statisztikai mintáit. Ettől kezdve annyi szintetikus adatot generálhat, amennyire szüksége van.
Általában összehasonlíthatja a generált adatokat az eredeti adatkészlettel, hogy megtudja, mennyire hasonlítanak a szintetikus adatok a valós adatokra.
Most megvizsgáljuk a szintetikus adatgenerálás eszközeit a gépi tanulási modellek betanításához.
Leginkább AI

A mesterséges intelligencia többnyire mesterséges intelligencia által működtetett szintetikus adatgenerátorral rendelkezik, amely tanul az eredeti adatkészlet statisztikai mintáiból. Az AI ezután kitalált karaktereket generál, amelyek megfelelnek a tanult mintáknak.
A Mostly AI segítségével teljes adatbázisokat hozhat létre hivatkozási integritással. Mindenféle adatot szintetizálhat, hogy jobb AI-modelleket készítsen.
Szintetizált.io

A Synthesized.io-t vezető vállalatok használják mesterséges intelligencia kezdeményezéseikhez. A synthesize.io használatához meg kell adnia az adatkövetelményeket egy YAML konfigurációs fájlban.
Ezután létrehoz egy feladatot, és egy adatfolyam részeként futtatja. Rendelkezik egy nagyon nagyvonalú ingyenes szinttel is, amely lehetővé teszi a kísérletezést és annak megállapítását, hogy megfelel-e adatigényeinek.
YData

Az YData segítségével táblázatos, idősoros, tranzakciós, többtáblás és relációs adatokat hozhat létre. Ez lehetővé teszi az adatgyűjtéssel, -megosztással és -minőséggel kapcsolatos problémák elkerülését.
AI-val és SDK-val érkezik a platformjukkal való interakcióhoz. Ezenkívül bőséges ingyenes szinttel rendelkeznek, amelyet a termék bemutatására használhatnak.
Gretel AI

A Gretel AI API-kat kínál korlátlan mennyiségű szintetikus adat generálására. A Gretel rendelkezik egy nyílt forráskódú adatgenerátorral, amelyet telepíthet és használhat.
Alternatív megoldásként használhatja a REST API-t vagy CLI-t, ami költséggel jár. Árazásuk azonban ésszerű, és a vállalkozás méretéhez igazodik.
Copulák
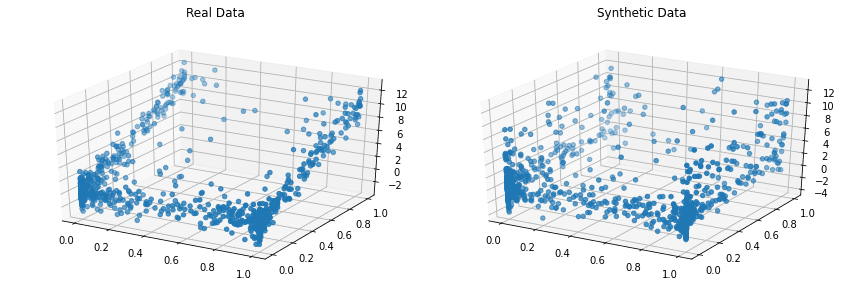
A Copulas egy nyílt forráskódú Python-könyvtár többváltozós eloszlások modellezésére kopulafüggvények segítségével, és szintetikus adatok előállítására, amelyek ugyanazokat a statisztikai tulajdonságokat követik.
A projekt 2018-ban indult az MIT-nél a Synthetic Data Vault Project részeként.
CTGAN
A CTGAN olyan generátorokból áll, amelyek képesek tanulni egytáblás valós adatokból, és szintetikus adatokat generálni az azonosított mintákból.
Nyílt forráskódú Python-könyvtárként van megvalósítva. A CTGAN a Copulas-szal együtt a Synthetic Data Vault Project része.
DoppelGANger
A DoppelGANger a Generative Adversarial Networks nyílt forráskódú megvalósítása szintetikus adatok generálására.
A DoppelGANger hasznos idősoros adatok generálására, és olyan vállalatok használják, mint például a Gretel AI. A Python könyvtár ingyenesen elérhető és nyílt forráskódú.
Szint

A Synth egy nyílt forráskódú adatgenerátor, amely segít valósághű adatok létrehozásában az Ön specifikációi szerint, elrejtheti a személyazonosításra alkalmas információkat, és tesztadatokat fejleszthet alkalmazásaihoz.
A Synth segítségével valós idejű sorozatokat és relációs adatokat generálhat gépi tanulási igényeihez. A Synth emellett adatbázis-agnosztikus, így használhatja SQL és NoSQL adatbázisaival.
SDV.dev
Az SDV a Synthetic Data Vault rövidítése. Az SDV.dev egy szoftverprojekt, amely 2016-ban kezdődött az MIT-nél, és különböző eszközöket hozott létre szintetikus adatok generálására.
Ezek az eszközök közé tartozik a Copulas, a CTGAN, a DeepEcho és az RDT. Ezek az eszközök nyílt forráskódú Python-könyvtárakként vannak megvalósítva, amelyeket könnyen használhat.
Tofu
A Tofu egy nyílt forráskódú Python könyvtár szintetikus adatok generálására az Egyesült Királyság biobanki adatai alapján. A korábban említett eszközökkel ellentétben, amelyek segítségével bármilyen adatot generálhat a meglévő adatkészlete alapján, a Tofu olyan adatokat generál, amelyek csak a biobank adataira hasonlítanak.
A UK Biobank egy tanulmány 500 000, az Egyesült Királyságból származó középkorú felnőtt fenotípusos és genotípusos jellemzőiről.
Twinify
A Twinify egy szoftvercsomag, amelyet könyvtárként vagy parancssori eszközként használnak az érzékeny adatok ikerpárosítására azáltal, hogy azonos statisztikai eloszlású szintetikus adatokat állítanak elő.

A Twinify használatához a valós adatokat CSV-fájlként kell megadnia, és az adatokból tanulva olyan modellt hoz létre, amely szintetikus adatok generálására használható. Használata teljesen ingyenes.
Datanamic
A Datanamic segítségével tesztadatokat készíthet adatvezérelt és gépi tanulási alkalmazásokhoz. Adatokat generál olyan oszlopjellemzők alapján, mint az e-mail cím, név és telefonszám.
A Datanamic adatgenerátorok testreszabhatók, és támogatják a legtöbb adatbázist, mint például az Oracle, MySQL, MySQL Server, MS Access és Postgres. Támogatja és biztosítja a hivatkozási integritást a generált adatokban.
Benerator
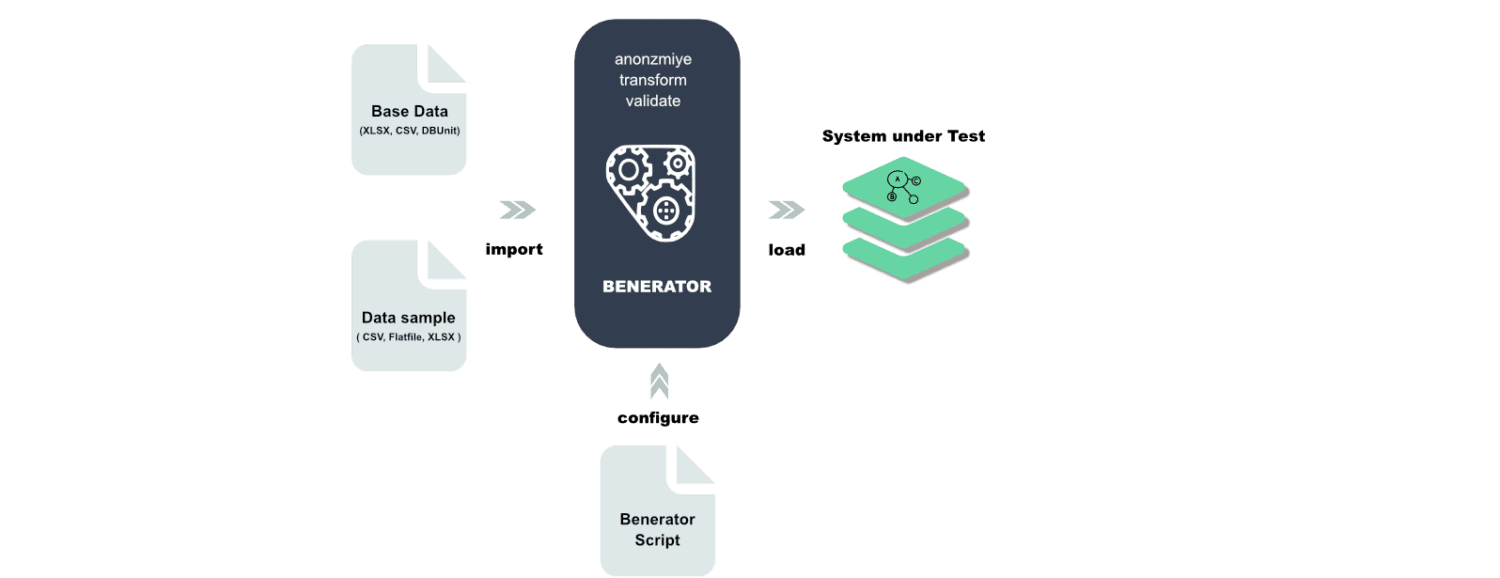
A Benerator egy szoftver az adatok homályosítására, generálására és tesztelési és képzési célú migrációjára. A Benerator segítségével XML-lel (Extensible Markup Language) írja le az adatokat, és a parancssori eszközzel állítja elő.
Nem fejlesztők számára készült, és több milliárd adatsort generálhat vele. A Benerator ingyenes és nyílt forráskódú.
Végső szavak
A Gartner becslései szerint 2030-ra több szintetikus adatot használnak majd fel a gépi tanuláshoz, mint amennyi valós.
Nem nehéz megérteni, hogy miért, tekintettel a valós adatok felhasználásának költségeire és adatvédelmi aggályaira. Ezért szükséges, hogy a vállalkozások megismerjék a szintetikus adatokat és a különböző eszközöket, amelyek segítik őket az előállításukban.
Ezután tekintse meg a szintetikus megfigyelőeszközöket online vállalkozása számára.